Article rédigé par : 0xSammy (Khala Research)
Compilé par : AIdidiaoJP, Foresight News
Le marché actuel de l'inférence IA ne ressemble plus à un simple marché de services cloud, mais plutôt à une partie d'échecs « risquée ». Chaque fournisseur se bat pour des territoires différents : les hyperscalers contrôlent le continent des entreprises, les routeurs tiennent les routes commerciales, et les réseaux décentralisés se battent farouchement en première ligne ouverte.
Le cœur du précédent cycle IA était l'entraînement des modèles, mais il devient de plus en plus évident que l'inférence contient une énorme valeur économique. Beaucoup entendent peut-être le terme « inférence » pour la première fois, alors de quoi s'agit-il exactement ?
L'entraînement crée des modèles IA, tandis que l'inférence est le processus par lequel le modèle génère une réponse lorsque quelqu'un lui pose une question ou lui donne une tâche.
Panorama du marché de l'inférence IA
La phase d'entraînement fait la une car elle sous-tend les sorties impressionnantes. Mais en réalité, l'inférence capture actuellement la majeure partie de la valeur économique - chaque prompt, boucle d'agent, génération d'image, exécution de transaction, appel d'outil et édition de code doit s'exécuter quelque part.
Les routeurs sont le véritable goulet d'étranglement
Dans une partie d'échecs « risquée », les territoires les plus précieux sont souvent les goulets d'étranglement étroits qui déterminent le prochain mouvement des armées. Dans le marché de l'inférence, les routeurs jouent exactement le même rôle. Positionnés entre la demande et l'offre, ils décident où chaque requête est acheminée et quel fournisseur est rémunéré.
Un exemple typique est OpenRouter, dont le protocole a traité 4700 billions de tokens la semaine dernière.
Cette activité économique ne montre aucun signe de ralentissement, surtout avec des billions d'agents sur le point de se déployer.
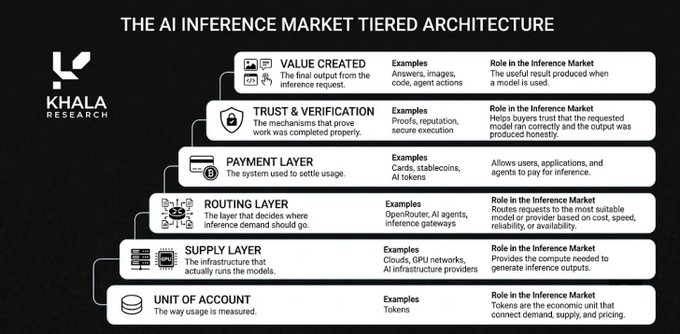
De quoi a donc besoin un marché complet de l'inférence ? Les éléments clés incluent :
- Le token devient l'unité de compte
- OpenRouter devient rapidement la couche d'échange centrale, avec 4700 billions de tokens utilisés la semaine dernière via son marché de LLM.
- Côté offre spécialisée : Fireworks, Together, Replicate, Baseten, Groq et les grands hyperscalers.
- Réseaux IA crypto : des projets comme Chutes, Akash, io.net, Nosana, Targon, Venice, NuNet, construisent la version sous-jacente sans autorisation.
Il ne faut pas considérer tous ces fournisseurs comme étant en compétition sur le même marché – ce n'est pas du tout le cas.
Les fournisseurs traditionnels vendent la fiabilité, l'expérience développeur et les processus d'approvisionnement d'entreprise.
Les réseaux IA crypto mettent en avant une offre moins chère, l'accès ouvert, la confidentialité, la vérifiabilité et de nouvelles boucles d'incitation.
L'événement récent où Anthropic a interdit l'utilisation de son modèle Mythos (Fable 5) aux utilisateurs hors des États-Unis a rappelé à beaucoup les risques de dépendre excessivement à un seul modèle propriétaire de pointe.
Il est intéressant de noter que les deux mondes commencent à se chevaucher : confidentialité, calcul confidentiel ou paiements natifs pour agents (Venice et Targon excellent dans ce domaine).
Comment envisager le marché de la puissance de calcul IA
Une meilleure perspective consiste à diviser le marché en deux grands camps : traditionnel et crypto.
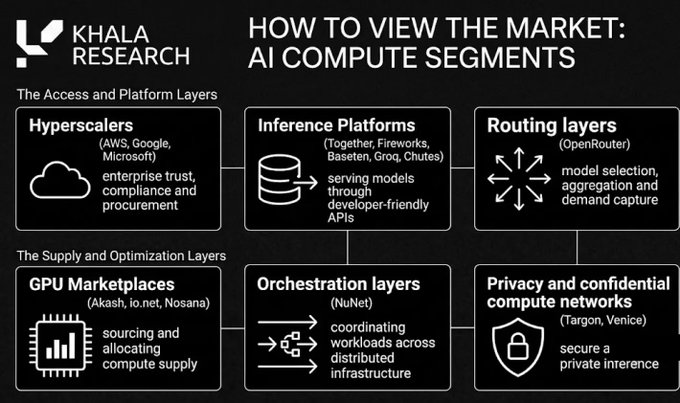
Le côté traditionnel vend la fiabilité, l'expérience développeur et l'approvisionnement d'entreprise.
Les réseaux crypto sont principalement en compétition sur l'accès ouvert, une offre à coût inférieur, la confidentialité, la vérifiabilité et de nouveaux mécanismes d'incitation, pour coordonner le capital de manière transparente à l'échelle mondiale.
Pourquoi l'inférence est le véritable marché de l'IA
La couche modèle reste importante, mais la qualité des modèles se comprime à une vitesse qui dépasse les attentes. Les modèles open source atteignent 90 à 95 % de la qualité des modèles de pointe, pour seulement 10 % de leur coût (par exemple, GLM-5.2 de Z.ai).
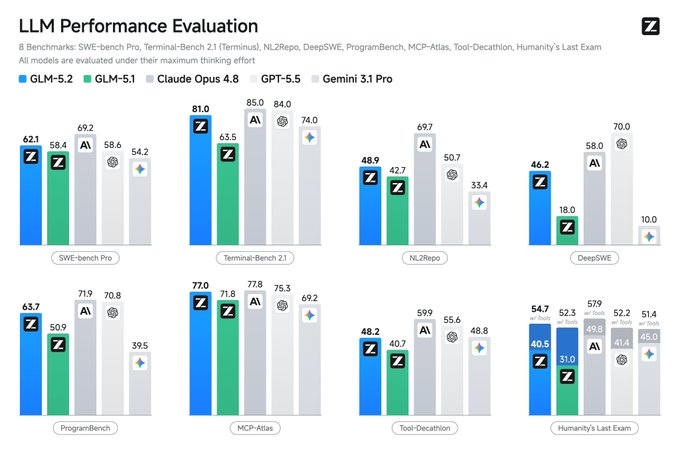
Les modèles open source itèrent continuellement, les laboratoires chinois continuent de faire baisser les prix. Les modèles de pointe maintiennent encore une prime, mais en dessous, la concurrence sur les prix des tokens est déjà féroce.
C'est précisément pourquoi la couche de routage devient cruciale : le même modèle open source peut être proposé par cinq fournisseurs différents à cinq prix différents. Les développeurs ne veulent pas coder en dur un point de terminaison pour toujours, ils ont besoin d'un routeur.
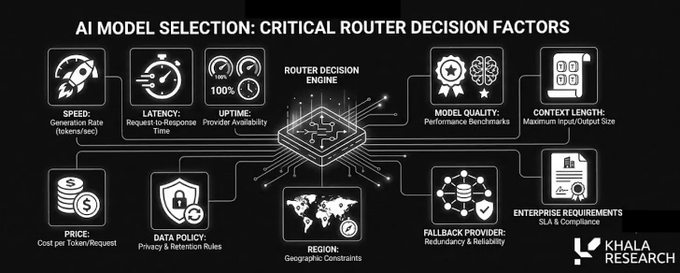
Un routeur peut choisir en fonction du prix, de la latence, de la confidentialité, de la fiabilité et de nombreux autres facteurs.
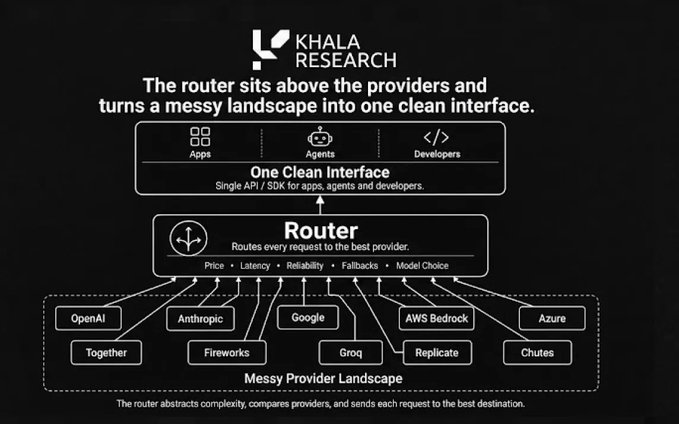
Il se situe au-dessus de tous les fournisseurs, transformant un paysage chaotique en une interface propre et unifiée.
C'est ce qu'OpenRouter fait bien, et cela explique pourquoi les fonds de capital-risque ont investi 113 millions de dollars dans un tour de financement série B récent pour saisir cette opportunité de routage.
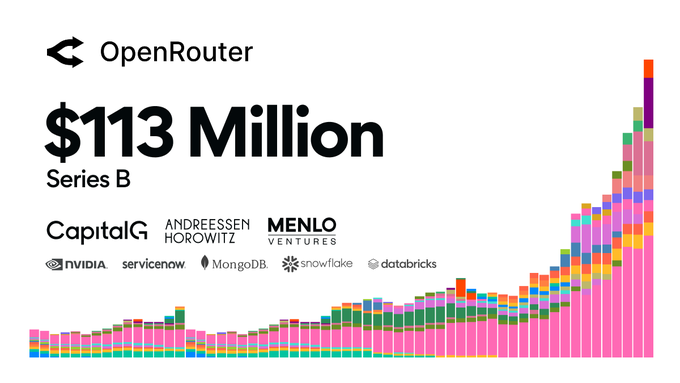
OpenRouter devient rapidement l'interface du marché : une seule clé pour accéder à des centaines de modèles sur de multiples fournisseurs. La vraie valeur ne réside pas dans la liste des modèles, mais dans le fait qu'une même requête peut être acheminée vers le fournisseur le plus adapté à la tâche.
Cela commence à ressembler au marché de l'énergie : les utilisateurs ne se soucient pas de savoir quelle centrale électrique a produit l'électricité, ils veulent juste que la lumière s'allume, que le prix soit équitable et que le système soit stable.
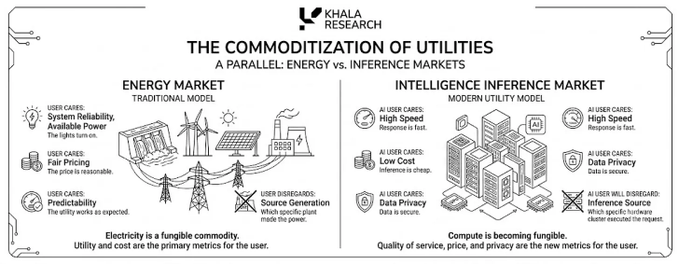
Les utilisateurs d'IA penseront de plus en plus ainsi – ils ne se soucient pas de savoir quel cluster de GPU a servi ce token, ils veulent juste une réponse rapide, peu coûteuse, privée et fiable.
Fournisseurs d'inférence traditionnels

Le côté traditionnel se différencie en quatre catégories :
i) Hyperscalers : AWS, Google, Microsoft
Ils contrôlent les « continents fortifiés ». Ils ne gagnent pas parce qu'ils sont toujours les moins chers, mais parce qu'ils contrôlent déjà les processus d'approvisionnement d'entreprise, de conformité, d'identité, de sécurité et de facturation. Attaquer de front cette position coûte très cher.
Ils gagnent grâce à la confiance des entreprises. Les grandes entreprises n'achètent pas seulement des tokens, mais aussi la conformité, la sécurité, la facilité d'approvisionnement et la responsabilité en cas de problème.
ii) Marchés de routage : OpenRouter et diverses passerelles IA
Les routeurs se situent au-dessus des fournisseurs de modèles, envoyant chaque requête vers la meilleure option. Alors que le leadership des modèles change chaque semaine, coder en dur un seul modèle semble de plus en plus fragile. L'IA a besoin d'agrégateurs, tout comme dans l'espace crypto.
iii) Service de modèles open source optimisés : Together, Fireworks, Baseten, Groq
Ce ne sont pas seulement des API bon marché, mais des entreprises d'infrastructure de performance axées sur la vitesse, le traitement par lots, la mise à l'échelle, le fine-tuning, les points de terminaison personnalisés et le support de production.
iv) Marchés de modèles : Replicate et plateformes similaires comme Hugging Face
L'inférence va bien au-delà du chat. Les images, la vidéo, la voix, les embeddings, les modèles robotiques, la simulation et les agents multimodaux nécessitent tous l'exécution de modèles. Les marchés rendent accessibles les besoins en modèles de longue traîne.
Fournisseurs d'inférence IA crypto
Les réseaux décentralisés sont les « territoires de guérilla ».
Les réseaux d'inférence crypto n'essaient pas de dépenser plus d'argent sur le champ de bataille principal d'AWS. Ils ouvrent de nouveaux fronts : modèles sans censure, offre GPU moins chère, inférence privée, paiements natifs pour agents, et charges de travail ne nécessitant pas la fiabilité au niveau des hyperscalers.
Le côté crypto est souvent simplement étiqueté comme « puissance de calcul décentralisée », ce qui est trop vague. Il existe au moins cinq orientations différentes :
- Réseaux d'inférence sans serveur
- Marchés GPU décentralisés
- Réseaux de calcul confidentiel
- Applications et passerelles IA privées
- Couche d'orchestration
Ils ne doivent pas être analysés de manière équivalente.
i) Chutes : inférence native crypto
@chutes_ai est mieux compris comme une plateforme d'inférence décentralisée, et non comme un simple marché de GPU.
L'essentiel est que les développeurs ne veulent pas louer de GPU ou gérer l'infrastructure, ils veulent un point de terminaison qui fonctionne. Chutes sert des modèles open source via une API familière, en utilisant une offre GPU décentralisée en coulisses.
La question clé est de savoir s'il peut transformer l'utilisation de pointe en demande payante et récurrente. Des tokens bon marché sont utiles, mais seulement si les développeurs font confiance à son temps de disponibilité, sa latence et sa fiabilité.
Son revenu par trillion de tokens continue d'augmenter, montrant un potentiel de rentabilité/viabilité durable.
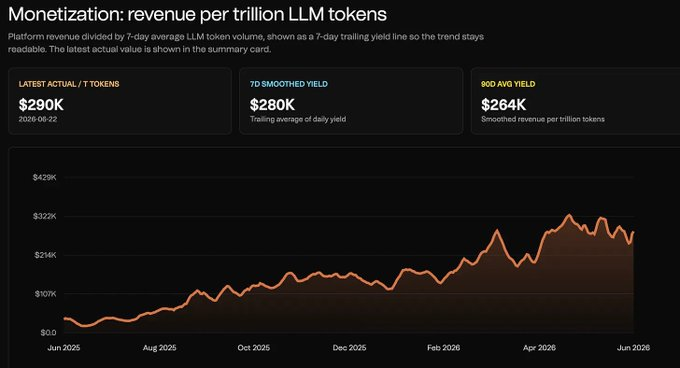
ii) Akash : couche d'enchères GPU
@akashnet est un marché de cloud décentralisé.
Les utilisateurs définissent la puissance de calcul nécessaire, les fournisseurs enchérissent pour fournir, les charges de travail s'exécutent via des baux. C'est plus un marché de puissance de calcul qu'un routeur d'inférence direct.
Il convient le mieux aux charges de travail sensibles au prix, tolérantes aux fluctuations d'infrastructure et ne nécessitant pas d'intégration profonde avec AWS/Azure/Google Cloud. Ses frais ont une certaine corrélation avec le prix du jeton et tendent à la hausse.
iii) io.net : cloud GPU décentralisé
@ionet s'apparente davantage à un fournisseur de cloud GPU décentralisé.
L'argument principal est l'accès à une offre GPU distribuée à moindre coût et avec une configuration plus rapide, adaptée aux équipes IA ayant besoin de puissance de calcul mais ne souhaitant pas s'engager sur des contrats cloud à long terme ou accepter les tarifs des hyperscalers.
Le défi réside dans l'exécution : vérification matérielle, fiabilité, planification, support et performances constantes. L'accès brut aux GPU a de la valeur, mais la couche à marge plus élevée reste le routage, la gestion de l'inférence et l'orchestration.
io.net a connu des performances remarquables au cours des 30 derniers jours, avec des revenus annualisés de 12,3 millions de dollars.
iv) Targon : calcul confidentiel
@TargonCompute (construit par @manifoldlabs) se concentre sur le calcul confidentiel pour les charges de travail IA.
Le problème qu'il résout est évident : de nombreux utilisateurs ne veulent pas exécuter des invites, modèles ou données sensibles sur une infrastructure gérée par des tiers inconnus.
Targon fournit une exécution protégée via des environnements d'exécution de confiance, des machines virtuelles chiffrées, des attestations à distance et une infrastructure GPU confidentielle. En termes simples, il prouve que la charge de travail s'exécute dans un environnement sécurisé et réduit ce que l'opérateur peut voir.
Cela est particulièrement pertinent pour l'inférence privée dans des domaines comme la finance, la santé et l'IA d'entreprise. Le calcul confidentiel n'est pas magique, il déplace la confiance vers le matériel, le micrologiciel et les systèmes d'attestation.
L'année dernière, le protocole a rapporté des revenus annualisés de 10,4 millions de dollars et a co-écrit un article de recherche avec Intel sur la « puissance de calcul décentralisée sur du matériel non fiable ».

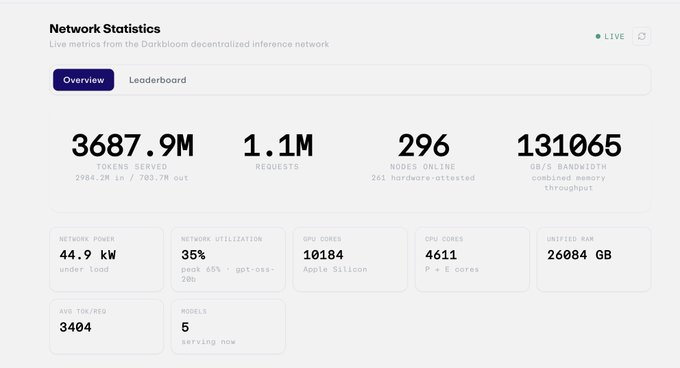
v) Darkbloom : inférence privée sur Mac inactifs
Darkbloom (construit par @eigenlabs) prend une voie différente.
Au lieu de répartir de grands modèles sur des GPU aléatoires, il transforme les Mac Apple Silicon inactifs en un réseau d'inférence privé. Les modèles s'exécutent localement sur le Mac, les requêtes sont chiffrées et acheminées vers des fournisseurs vérifiés.
L'argument est la confidentialité et le coût, et non la maximisation des performances des modèles de pointe.
Cela est utile car « aucun nœud ne possède le modèle complet » ne signifie pas automatiquement que l'invite est privée. Darkbloom cible plus explicitement les problèmes de confidentialité, mais doit encore prouver l'échelle de l'offre, les performances et la confiance des développeurs.
Actuellement, le réseau compte 300 machines, ayant servi 20 milliards de tokens et 1 million de requêtes.
vi) Venice : inférence privée grand public
@AskVenice occupe une position différente des réseaux comme Akash ou io.net. Il ressemble davantage à une application IA privée et une passerelle d'inférence, plutôt qu'à un marché de GPU principal.
Le débit de sa passerelle atteint 85 milliards de tokens par jour (selon @ErikVoorhees).
La plupart des utilisateurs veulent un produit IA qui respecte la vie privée, donne accès à des modèles puissants et ne collecte pas massivement de données.
Venice enveloppe l'idée d'infrastructure dans une expérience orientée consommateur, centrée sur les invites privées, les modèles open source, l'accès sans censure, les fonctionnalités API et la puissance de calcul tokenisée via VVV et DIEM.
Le composant DIEM est particulièrement intéressant, car il pointe vers une idée plus large d'économie d'agents : donner un accès quotidien à 1 dollar de puissance de calcul. Le marché a récemment attribué un prix intéressant à ce concept.
Si un agent a besoin d'un accès continu à l'inférence, les crédits de puissance de calcul commencent à ressembler à des actifs natifs pour agents, et un marché secondaire entier peut être construit autour.
Un agent qui peut directement détenir et dépenser des droits de puissance de calcul est plus pratique qu'un agent qui dépend d'un humain rechargant régulièrement une carte de crédit.
Cela met en lumière une thèse plus profonde de l'IA crypto : les agents finiront par avoir besoin d'accéder à des fonds, une identité, une mémoire et de la puissance de calcul, et les systèmes crypto fournissent un cadre pour la programmation de ces ressources.
Venice ne rivalise pas directement avec OpenRouter sur la largeur des modèles, mais sur la confidentialité, l'accès et la puissance de calcul tokenisée. C'est une niche légitime, mais la question clé est de savoir si la demande pour un produit IA privé sera suffisamment grande pour soutenir un modèle de jeton au-delà du cycle narratif actuel. Mon jugement est qu'avec la prolifération de l'IA, le récit sur la confidentialité ne fera que se renforcer.
vii) NuNet : orchestration de puissance de calcul distribuée
@nunet_global est souvent classé parmi les projets de puissance de calcul décentralisée, mais un cadre plus utile est « l'orchestration ».
L'orchestration implique de faire correspondre les charges de travail aux ressources de puissance de calcul les plus adaptées et de coordonner l'exécution entre différentes machines, environnements et emplacements.
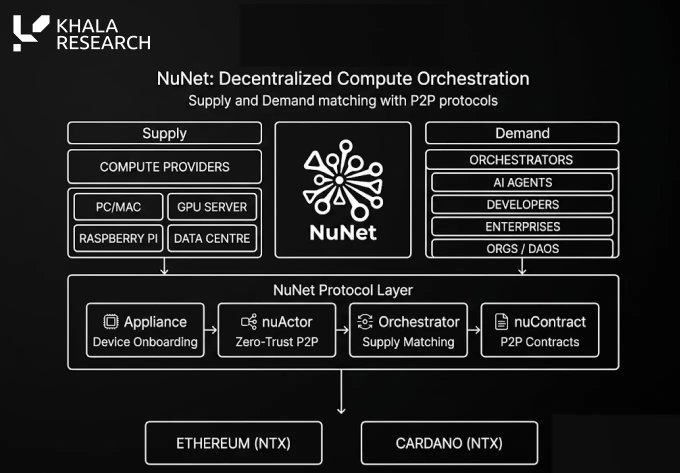
Cela devient de plus en plus important à mesure que l'IA dépasse l'infrastructure cloud centralisée.
Les futurs systèmes d'IA fonctionneront probablement à travers des GPU cloud, des appareils périphériques, des serveurs locaux, des robots, des téléphones, des capteurs et des réseaux de fournisseurs décentralisés.
Un robot d'entrepôt ne peut peut-être pas attendre une réponse API inter-régions ; un drone ne peut pas supposer une connexion parfaite à tout moment ; un robot en milieu sauvage doit exécuter des inférences localement lorsque le réseau est peu fiable.
Par conséquent, l'orchestration devient une catégorie distincte et significative.
Le défi pour NuNet est de savoir s'il peut transformer ce problème de coordination en un réseau économique fonctionnel avec une offre, une demande et une adoption suffisantes par les développeurs.
viii) OpenServ : orchestration d'agents, pas seulement d'inférence
@openservai est mieux compris comme une plateforme d'infrastructure et d'orchestration d'agents, plutôt qu'un réseau d'inférence décentralisé.
Cela est important, car les agents sont l'une des sources de demande d'inférence les plus claires pour l'avenir. Un chatbot ordinaire n'appelle peut-être le modèle qu'une seule fois, tandis qu'un agent appellera le modèle à plusieurs reprises : inférence, utilisation d'outils, vérification de la sortie, appel d'un autre modèle, action, puis boucle.
Cela crée une forte demande d'inférence, ce qui a déjà attiré l'attention dans l'espace crypto.
OpenServ est donc pertinent pour le marché de l'inférence du côté de la demande, plutôt que de l'offre. Si la plateforme peut devenir un endroit utile où les développeurs construisent, déploient et orchestrent des agents, elle deviendra naturellement la couche qui achemine l'inférence vers différents fournisseurs en coulisses.
La question clé est de savoir si OpenServ peut devenir une véritable couche d'exécution d'agents, ou n'est qu'un autre marché d'agents avec un jeton.
Après plusieurs échanges avec l'équipe, je pense que ses capacités vont au-delà de la seconde option, son cadre d'inférence a montré des performances de référence notables, et sa feuille de route comprend même ses propres modèles propriétaires.
Si OpenServ peut maîtriser le flux de travail opérationnel des agents, l'inférence devient une entrée pour la plateforme, et non le produit principal.
Dans un monde d'agents, la couche la plus précieuse sera celle où les agents passent le plus de temps et de ressources continuellement.
ix) Dolphin AI : inférence décentralisée pilotée par les produits
@dphnAI est intéressant car il a commencé par la demande de modèles, plutôt que par le marché de GPU.
La famille de modèles Dolphin a déjà la réputation de modèles open source sans censure, ce qui donne au réseau une raison d'être plus claire.
C'est important, car de nombreux projets d'inférence décentralisée sont axés sur l'offre : « Nous avons des GPU, qui va les acheter maintenant ? »
Dolphin fait l'inverse : partir d'un ensemble de modèles que les gens veulent déjà utiliser, puis construire un réseau d'inférence décentralisé autour de cette demande.
Son architecture est souvent appelée peer-to-pool : les propriétaires de GPU contribuent de la capacité à un pool de modèles spécifique, plutôt que chaque acheteur louant directement un nœud spécifique. Les requêtes sont acheminées vers le pool, et les nœuds disponibles les traitent.
Ceci est une meilleure conception pour une offre consommateurs peu fiable. Si quelqu'un contribue un GPU de jeu inactif, il ne restera peut-être pas toujours en ligne ; un pool de modèles peut absorber cette volatilité plus naturellement qu'un marché de location en pair à pair.
Plus intéressant encore est la vérification. Dolphin promeut des « preuves de poids en temps réel ». En termes simples, il s'agit de vérifier si les poids du modèle réellement chargés pendant le service correspondent au modèle que le nœud prétend exécuter.
C'est important, car la tricherie est l'un des problèmes les plus difficiles de l'inférence décentralisée. Un nœud peut prétendre exécuter un modèle coûteux, mais servir secrètement une version plus petite, moins chère ou quantifiée du modèle. Si le réseau ne peut pas le détecter, tout le marché perd en crédibilité.
x) c0mpute : inférence distribuée pour les agents
@c0mputeAI mérite d'être suivi car il tente de résoudre l'un des problèmes les plus difficiles de l'inférence décentralisée : exécuter de grands modèles sur des GPU dispersés sur l'internet ouvert.
Son moteur Shard répartit le modèle sur plusieurs machines, plutôt que de demander à un serveur géant d'héberger le modèle complet. Cela est particulièrement pertinent pour les modèles open source de pointe qui pourraient être trop grands ou restreints pour passer par les voies d'hébergement classiques.
Le lien avec @virtuals_io est un angle de demande clé. Virtuals construit une économie d'agents, et les agents sont de gros utilisateurs d'inférence : ils planifient, appellent des outils, font des transactions, vérifient les résultats et bouclent. Cela crée une demande pour une inférence bon marché, ouverte et résistante à la censure.
La mise en garde est que cela en est encore à un stade précoce. c0mpute doit prouver ses performances sous une charge réelle, la fiabilité des nœuds, la vérification et la confidentialité des invites.
Mais la direction est importante : un marché de GPU vend l'accès à la puissance de calcul ; c0mpute tente de distribuer le modèle lui-même.
Inférence traditionnelle vs crypto
Les deux coexisteront, chacun ayant des avantages distincts évidents et compréhensibles.

Sur quoi se concentrer
Volume de tokens payants
Le marché devrait s'éloigner des statistiques brutes de traitement de tokens, à moins que ces tokens ne génèrent des revenus. L'activité en niveau gratuit et l'utilisation subventionnée peuvent créer des chiffres impressionnants, mais ne prouvent pas une réelle adéquation produit-marché.
La demande d'inférence payante est la métrique clé – elle est plus durable et peut soutenir la viabilité à long terme.
ii) Revenu par GPU
Les réseaux de puissance de calcul décentralisés ne sont durables que si la valeur gagnée par les GPU au sein du réseau est supérieure à celle de l'extérieur. Si les émissions sont la principale raison de la participation des fournisseurs, l'offre disparaîtra une fois que les incitations diminueront. Les fournisseurs de GPU calculent le coût d'opportunité.
iii) Intégration des routeurs : distribution
La distribution est souvent plus importante que l'infrastructure elle-même.
Les intégrations OpenRouter, les agents de codage, les portefeuilles, les points de terminaison de paiement, les outils de développement et les applications grand public sont toutes des sources potentielles de demande.
Les points de terminaison de paiement sont des canaux par lesquels les logiciels peuvent payer directement pour des services via une API.
iv) Vérification
La tricherie GPU, la fausse capacité et les fournisseurs peu fiables restent des risques réels.
Les réseaux ont besoin d'une vérification matérielle robuste, d'un trafic chiffré, de systèmes de réputation et de sanctions significatives contre les mauvais comportements.
v) Garanties de confidentialité
L'inférence privée reste l'une des meilleures opportunités pour l'IA crypto, mais les garanties doivent être réelles. Le marketing de la confidentialité est facile ; l'exécution sécurisée, l'architecture locale prioritaire, la minimisation des données et l'infrastructure auditables sont bien plus difficiles.
vi) Capture de valeur du jeton
Les modèles de jeton les plus forts lieront directement la demande à une utilisation réelle de l'inférence. Cela peut impliquer des rachats, des brûlures, des exigences de jalonnement, des droits de puissance de calcul ou des mécanismes liés aux revenus.
Compter uniquement sur le récit général de l'IA ne suffira probablement pas à long terme.
Conclusions principales
Le jeu final est le contrôle de la demande
Dans une partie d'échecs « risquée », posséder simplement des territoires épars ne suffit pas. Il faut des zones connectées, des routes de renfort et des lignes d'approvisionnement durables.
Il en va de même sur le marché de l'inférence. Les gagnants contrôleront la demande, le routage, la vérification et le règlement ; posséder simplement des GPU ne suffit pas.
Le marché de l'inférence fait commencer l'IA à ressembler à un système financier :
- Chaque token généré porte un coût,
- Chaque point de terminaison comporte une marge,
- Chaque boucle d'agent crée de la demande,
- Chaque routeur agit comme un teneur de marché,
- Chaque réseau GPU devient une source d'offre...
Les fournisseurs traditionnels dominent actuellement la couche d'expérience développeur et de confiance des entreprises.
Les réseaux IA crypto explorent une autre frontière : offre sans autorisation, inférence privée, puissance de calcul vérifiable, accès tokenisé et paiements natifs pour agents (sans restriction KYC).
À court terme, les gagnants ne seront probablement pas les réseaux les plus décentralisés, mais plutôt ceux qui rendent l'inférence décentralisée banale et fiable – via des points de terminaison rapides, une documentation solide, un temps de disponibilité fiable, une tarification transparente, une offre vérifiée et une demande payante réelle.
Chutes reste l'un des projets à suivre de près, car il est le plus proche de transformer la puissance de calcul soutenue par Bittensor en un marché d'inférence fonctionnel, plutôt qu'un simple récit sur les GPU. Il en va de même pour « Darkbloom » d'Eigen Labs.
Akash et io.net représentent les challengers côté offre, Targon représente la thèse du calcul confidentiel, Venice représente la couche de demande d'IA privée, NuNet représente l'orchestration d'un avenir plus distribué de la puissance de calcul.
La thèse plus large :
« Les modèles d'IA pourraient devenir de plus en plus des produits de base, mais le marché de l'inférence ne suivra probablement pas la même trajectoire. »
La plus grande valeur reviendra aux entités qui acheminent le travail, vérifient le travail, règlent le travail et capturent la demande.
C'est précisément là que pourrait se trouver la prochaine opportunité d'IA crypto... du moins jusqu'à ce que l'IA physique devienne compétente dans la société.





