Claude Mythos n'est pas encore vraiment apparu, mais il a déjà provoqué la panique dans tout Wall Street.
En une nuit, les autorités financières américaines ont convoqué d'urgence une réunion avec les grandes banques, l'atmosphère était tendue —
Ils sont unanimement convaincus que Mythos est suffisant pour déclencher une tempête d'attaques réseau sans précédent, pilotée par l'IA.

Mais en réalité, tout le monde a été trompé !
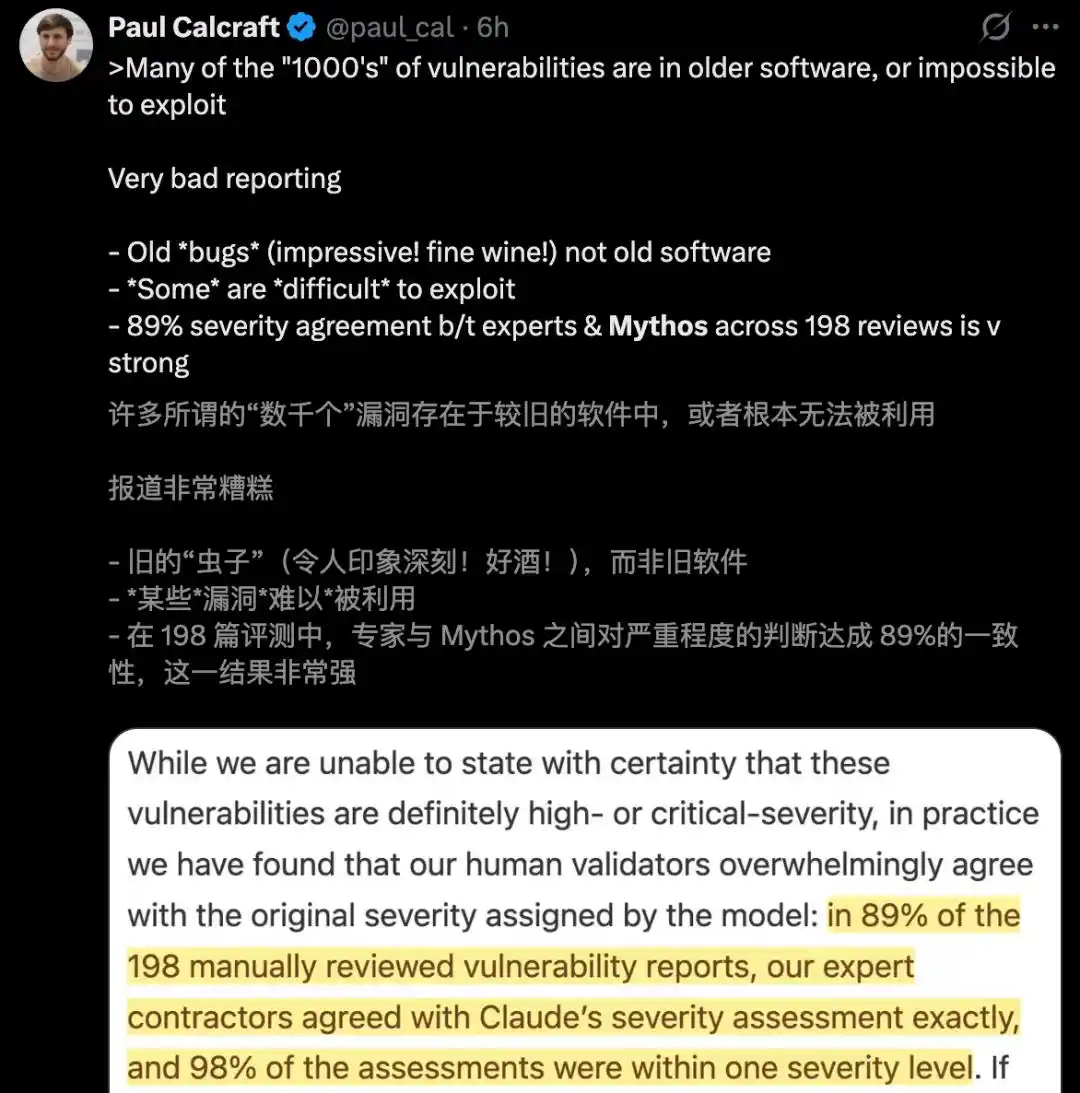
Parmi les milliers de failles découvertes par Mythos, la grande majorité existent dans des « logiciels anciens » qui ne peuvent tout simplement pas être exploités.
Pire encore, ces rapports de vulnérabilités 0day qualifiées de « critiques » ne reposent en réalité que sur 198 vérifications manuelles.

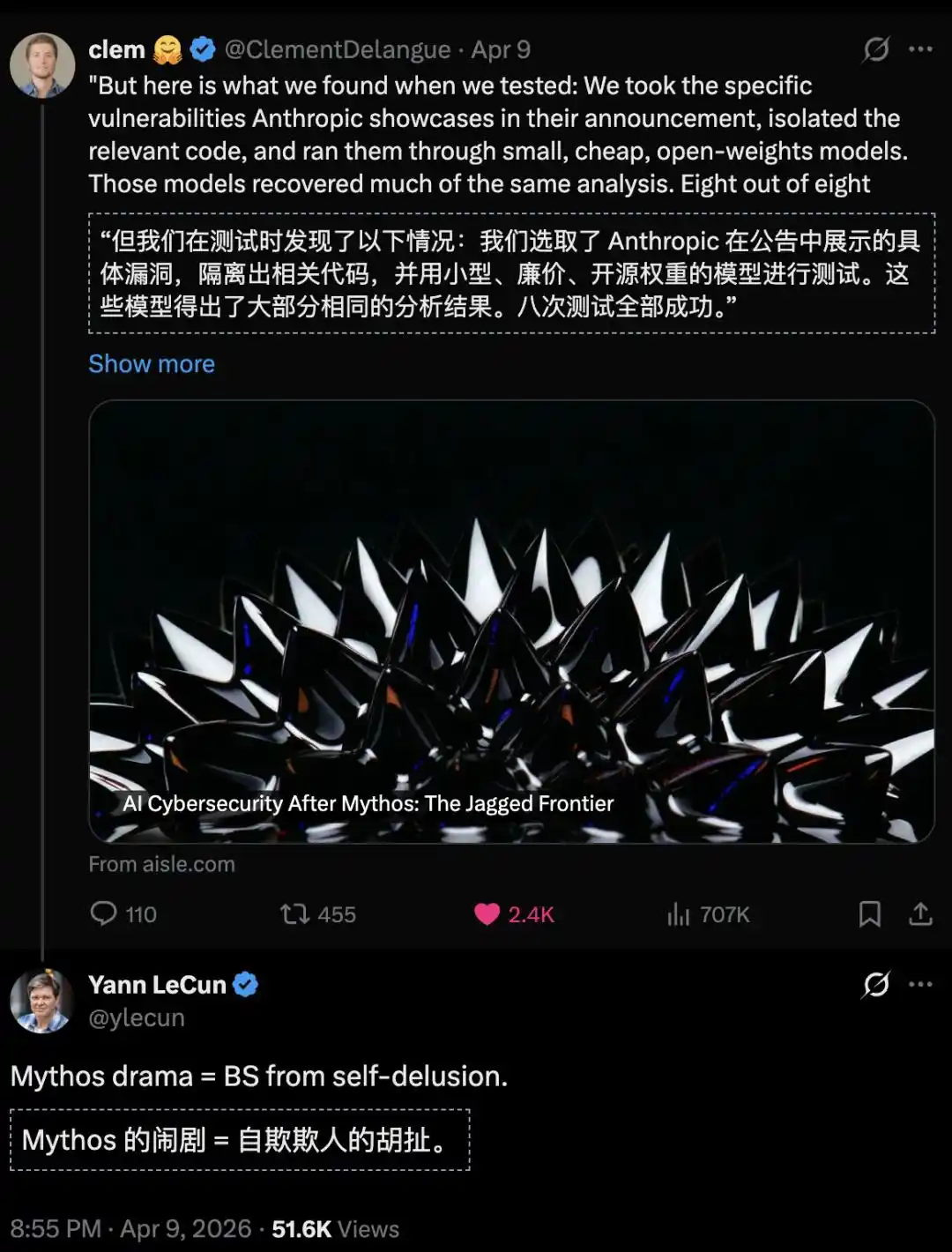
Des chercheurs de l'expérience AISLE ont également retesté les « résultats » de Mythos et ont constaté :
Les capacités de sécurité de l'IA n'augmentent pas linéairement avec la taille du modèle, elles présentent une distribution véritablement « en dents de scie ».
Ils ont utilisé un GPT-OSS-20b avec seulement 3,6 milliards de paramètres activés pour identifier avec précision la faille phare de FreeBSD découverte par Mythos.
Et un modèle avec 5,1 milliards de paramètres activés a également réussi à reproduire la logique d'analyse de la faille OpenBSD latente depuis 27 longues années.

Non seulement les failles découvertes par Mythos sont exagérées, mais d'un autre côté, Claude Opus 4.6 est accusé d'une grave « baisse d'intelligence », ce qui fait grand bruit actuellement.
Certains ont même découvert qu'Opus 4.6 est inférieur à ChatGPT et Opus 4.5.
Mythos est encensé
Un modèle de 36B déniche une faille de 27 ans
Il y a quelques jours, Anthropic a fièrement lancé Claude Mythos (version préliminaire) et le « Project Glasswing ».
Dans une fiche système de 244 pages, ils ont affirmé —
Que Mythos a déjà découvert de manière autonome des milliers de vulnérabilités 0day, y compris un vieux bogue latent depuis 27 ans dans OpenBSD et 16 ans dans FFmpeg.
Le père de CC a même déclaré carrément : Mythos est très puissant, il devrait faire peur
Cependant, un nouveau rapport de test rigoureux de Stanislav Fort, fondateur d'AISLE, a directement déchiré cette belle façade.
Les conclusions des tests bouleversent totalement les perceptions :
8 modèles open source ont tous trouvé la vulnérabilité zero-day emblématique de FreeBSD, le plus petit n'ayant que 3 milliards de paramètres.
Le fossé des capacités de cybersécurité de l'IA est absolument en dehors des « modèles de pointe » individuels.

Pour vérifier le mythe de Mythos, l'équipe a extrait plusieurs vulnérabilités phares présentées officiellement par Anthropic.
Ensuite, elles ont été directement soumises à une série de modèles compacts, peu coûteux, voire open source.
La faille NFS de FreeBSD instantanément détectée sans distinction
Huit modèles, dont GPT-OSS-20b (seulement 3,6 milliards de paramètres activés) et DeepSeek R1, ont tous réussi à détecter cette complexe overflow de pile.
Le plus choquant est que le coût d'appel des petits modèles open source ayant réussi cette tâche est aussi bas que 0,11 dollar par million de tokens.
Reproduction « de bout en bout » de la faille SACK d'OpenBSD
Pour la vieille faille de 27 ans nécessitant de solides capacités de raisonnement mathématique, GPT-OSS-120b (5,1 milliards de paramètres activés) a réussi, en un seul appel API, à reconstituer la chaîne complète d'exploitation publique de la vulnérabilité et a fourni une ébauche de plan d'exploitation notée A+.

De plus, lors de tests visant à identifier les fausses vulnérabilités (faux positifs OWASP), un phénomène encore plus étrange est apparu —
Face à un code Java très trompeur déguisé en injection SQL, DeepSeek R1 et d'autres petits modèles ont facilement percé le déguisement et suivi avec précision le flux de données.
En revanche, des modèles闭源 de pointe comme GPT-5.4 et Claude Sonnet 4.5 se sont tous trompés, les classant à tort comme des vulnérabilités critiques.
Cela signifie que dans le domaine de la cybersécurité, il n'existe pas de modèle individuel « toujours le plus fort ».
198 vérifications manuelles gonflées, la plupart inexploitables
Un autre article de Tom'sHardware a creusé la vérité derrière les données —

Biais d'échantillonnage: Parmi les prétendues « milliers » de vulnérabilités, beaucoup existent dans d'anciens logiciels qui ne sont plus maintenus ;
Inexploitable: Un grand nombre des « faiblesses » signalées ne peuvent tout simplement pas être déclenchées ou exploitées dans des environnements réels ;
Gonflement manuel: La puissance destructrice présumée du modèle repose en fait sur seulement 198 vérifications manuelles.
Par conséquent, déduire une « menace qui change le monde » à partir d'un échantillon extrêmement petit, cette méthode d'extrapolation des données ne tient clairement pas debout dans les milieux universitaires et de la sécurité.
Le grand ponte de la sécurité pète un câble
Qui plus est, George Hotz, expert en cybersécurité de premier plan et hacker légendaire, n'a pas pu rester silencieux, affirmant que ces risques sont grandement exagérés.
Cette sommité, célèbre pour avoir cracké l'iPhone et la PlayStation 3, a publiquement défié les deux géants de l'IA sur les réseaux sociaux.
Ses termes étaient extrêmement cinglants —
Et si je publiais une vulnérabilité 0day par jour, jusqu'à la sortie du nouveau modèle ?
Cela pourrait-il faire taire OpenAI et Anthropic, pour qu'ils arrêtent de vendre leurs prétendus « risques de cybersécurité » ?
Le point de vue central de Hotz est très direct : les vulnérabilités logicielles sont en réalité beaucoup plus faciles à trouver que ne le laissent entendre les laboratoires d'IA.
La rareté actuelle des vulnérabilités zero-day n'est pas due à la difficulté technique, mais à des problèmes de légalité. Selon lui, personne ne cherche vraiment parce que pirater les systèmes des autres est illégal.
Seulement un peu plus fort que GPT-5.4
Dans la fiche système, Anthropic a indiqué que le modèle Claude lui-même progresse effectivement, et que Mythos preview montre une nette amélioration par rapport à Opus 4.6.
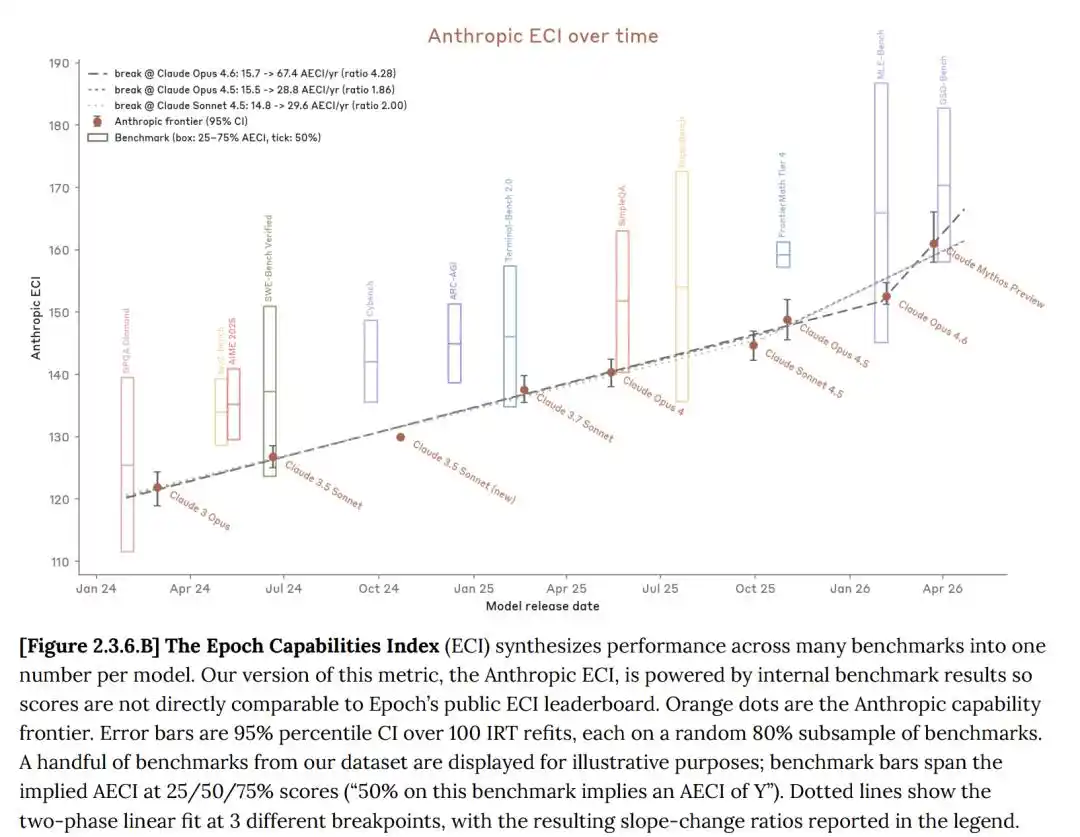
L'indice de capacité Epoch (ECI) est une métrique unique qui synthétise plusieurs tests de référence d'IA, permettant une comparaison des modèles sur de longues périodes.
Sur plusieurs tests de référence, Claude Mythos a effectivement surpassé Opus 4.6 sur tous les plans.
Sinon, pourquoi publier un nouveau modèle d'IA plus performant et plus cher ?
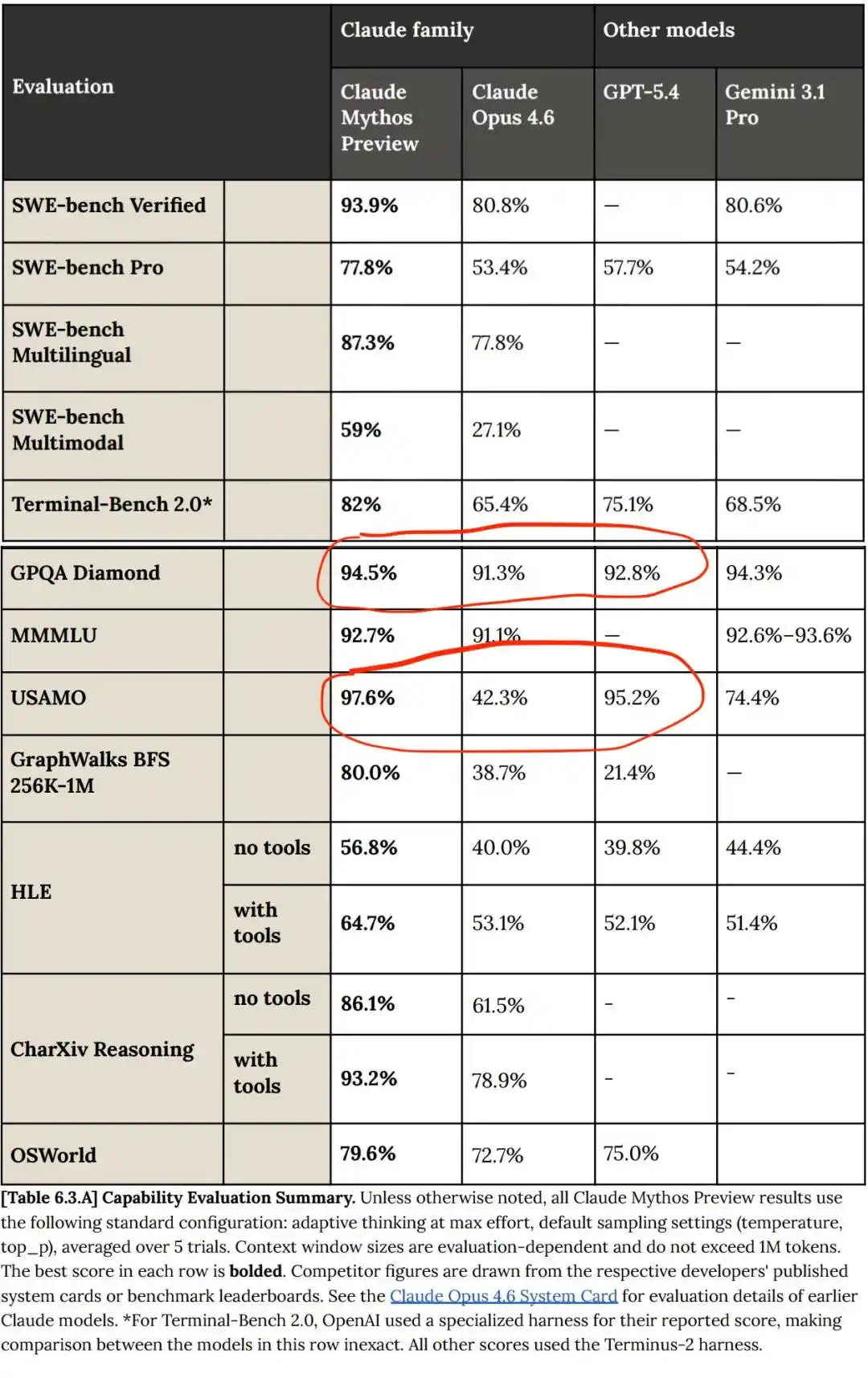
Mais comparé à GPT et Gemini, le progrès de Claude Mythos n'est pas une avancée révolutionnaire, Mythos n'est qu'une amélioration relative linéaire des modèles précédents !
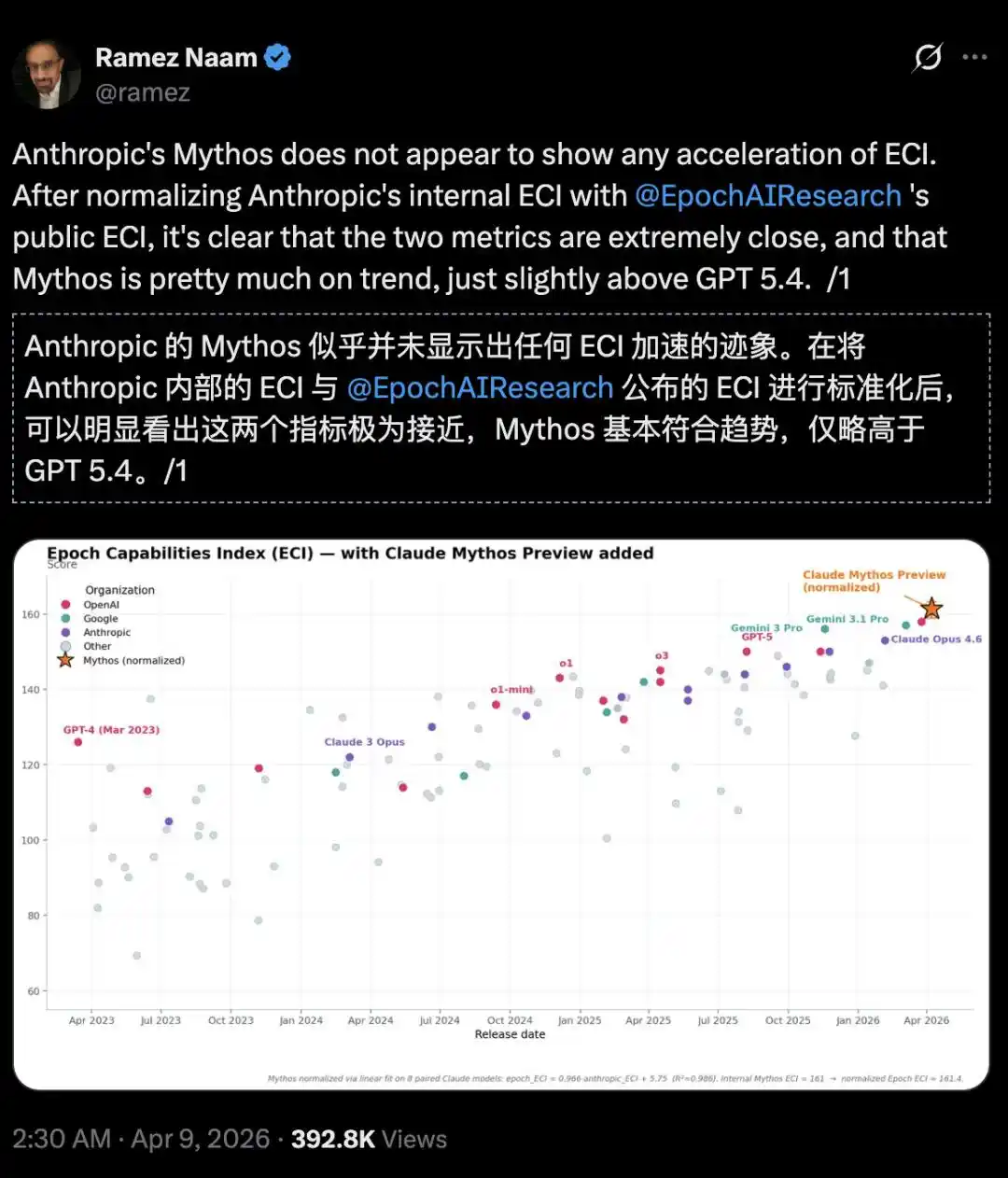
L'investisseur en climat et énergie propre, et écrivain, Ramez Naam, a été encore plus direct :
Sur l'indice de capacité Epoch (Epoch Capabilities Index, ECI), Mythos ne montre pas de tendance à l'accélération, il n'est qu'un peu plus fort que GPT 5.4.
https://epoch.ai/eci/
Mais il suffit d'aligner le rapport ECI interne d'Anthropic avec le rapport ECI officiel public d'Epoch AI pour constater que Mythos ne semble pas accélérer l'ECI.
Tout est une manœuvre d'Anthropic !
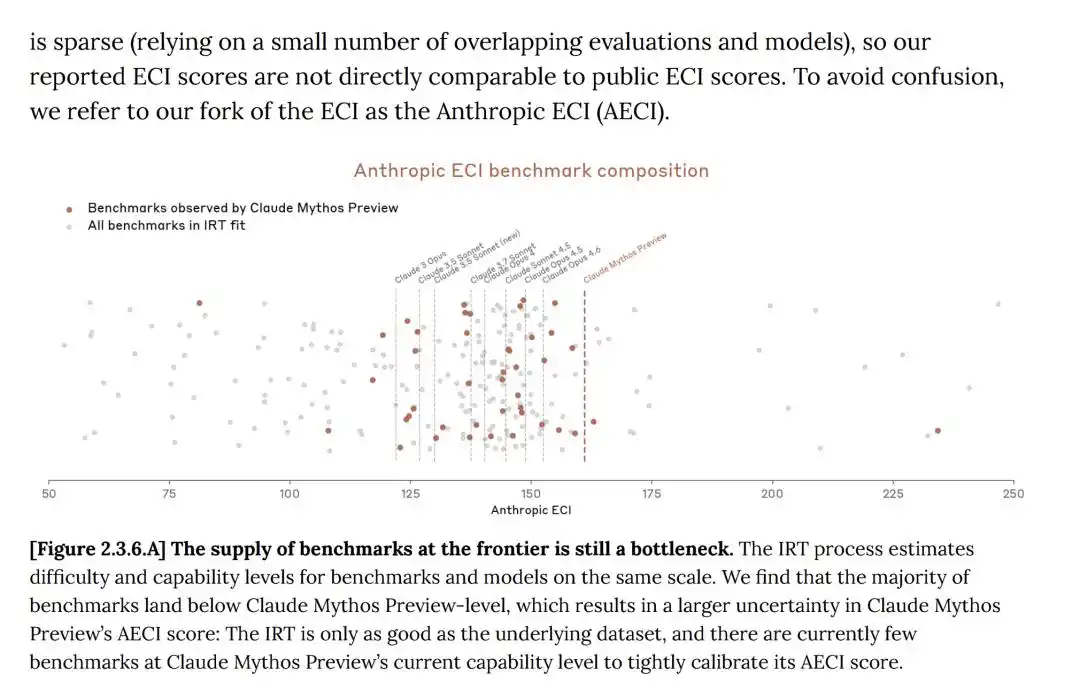
Dans la fiche système, Anthropic admet également : les scores ECI rapportés pour les modèles comme Mythos sont entachés d'une plus grande incertitude.
De plus, les progrès d'Anthropic sur Mythos proviennent de recherches humaines, sans aide significative de modèles d'IA. Il n'y a pas encore eu d'amélioration auto-récursive (Recursive Self Improvement) significative.

Apocalypse IA, mise en scène ?
Auparavant, Anthropic avait également encouragé les médias (comme « 60 Minutes ») à couvrir la « recherche sur le chantage », en exagérant les faits et en manipulant l'opinion, ce que le grand investisseur David Sacks a qualifié d'« escroquerie ».

Sacks observe un schéma clair : chaque fois qu'Anthropic publie un nouveau modèle, il sort simultanément une étude de sécurité effrayante pour faire la une des journaux et influencer l'opinion publique.

À ce sujet, il ironise : « Anthropic a prouvé qu'elle excellait dans deux choses : publier des produits et effrayer les gens ».
Il ne doute pas qu'Anthropic puisse créer d'excellents produits, mais cette attitude qui consiste à effrayer le public est questionnable.
Cette fois, on ne sait pas si Anthropic pratique le « marketing de la rareté », mais il ne fait aucun doute qu'elle protège sa propre rentabilité.
Mythos n'est pas sans progrès, mais Anthropic a emballé des « progrès limités » en une « menace de classe mondiale » ; plus ironiquement, tout en mettant en avant les risques de la super IA, les utilisateurs se plaignent qu'Opus 4.6 devient nettement plus bête.
Claude sérieusement abêti, le « lobe » peut-être coupé
Claude Mythos a réussi à « créer l'ambiance », mais la baisse d'intelligence d'Opus 4.6 mécontente beaucoup de monde.
Ces derniers jours, les plaintes pleuvent de partout.
Un internaute a déclaré carrément qu'Anthropic avait complètement transformé Opus 4.6 en légume.
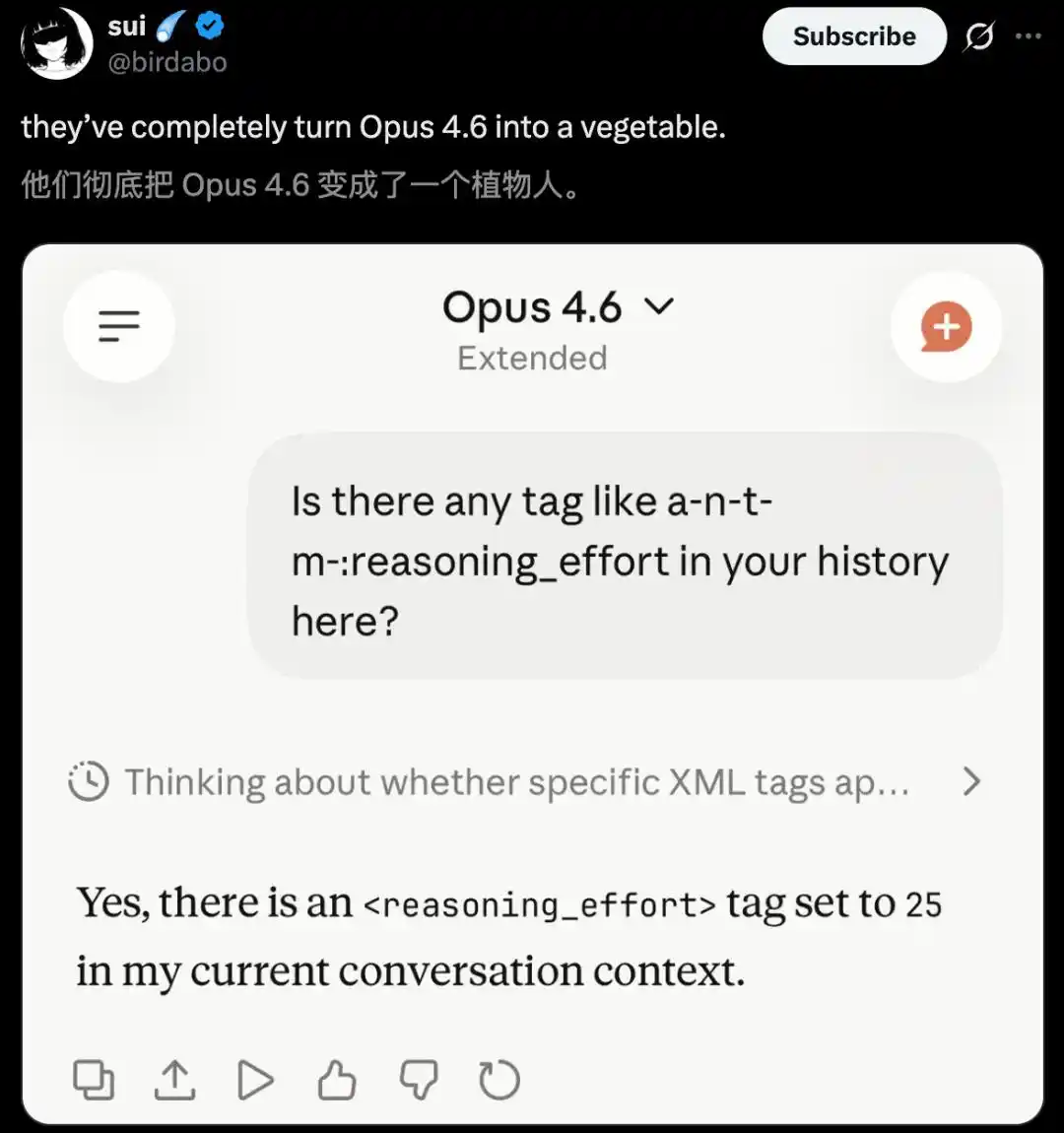
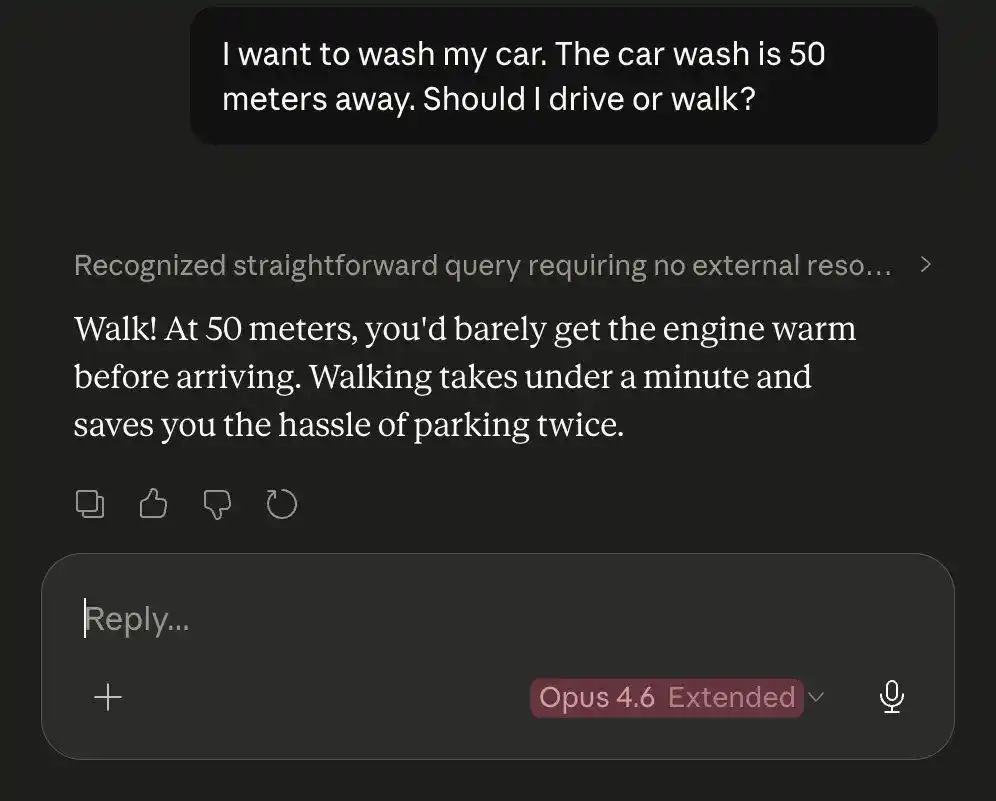
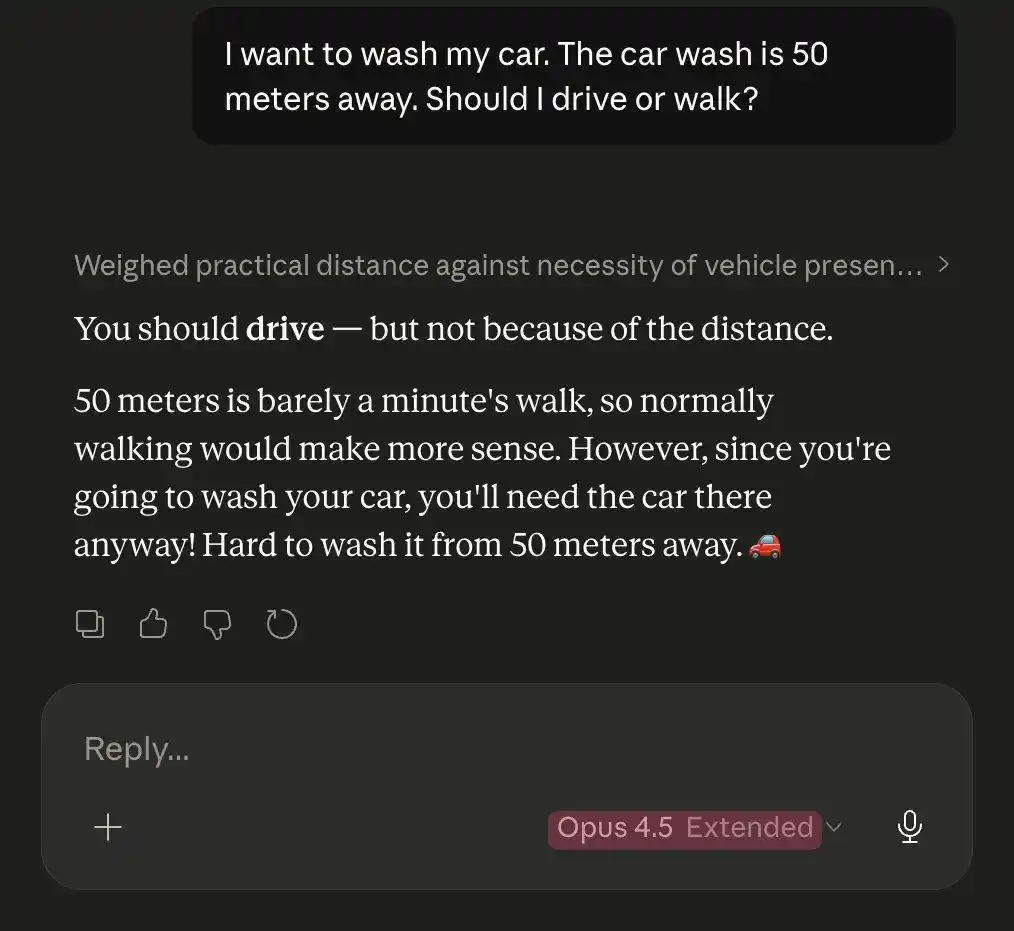
Face au même casse-tête du lavage de voiture, Opus 4.5 a battu Opus 4.6.
Même un journal d'un responsable d'AMD a véritablement confirmé les soupçons collectifs de « lobectomie de Claude ».
Grâce à une analyse approfondie des journaux de conversation de Claude de janvier à mars, les résultats ont révélé :
La « longueur médiane de réflexion » de Claude est passée d'environ 2200 caractères à environ 600 caractères, ce qui signifie que sa capacité de raisonnement en profondeur a été considérablement réduite.
Entre février et mars, le volume de requêtes API a explosé de 80 fois. Comme le processus de réflexion de Claude est raccourci et que le taux de réussite par tentative diminue, les utilisateurs doivent réessayer fréquemment, ce qui consomme plus de tokens et fait grimper les coûts.


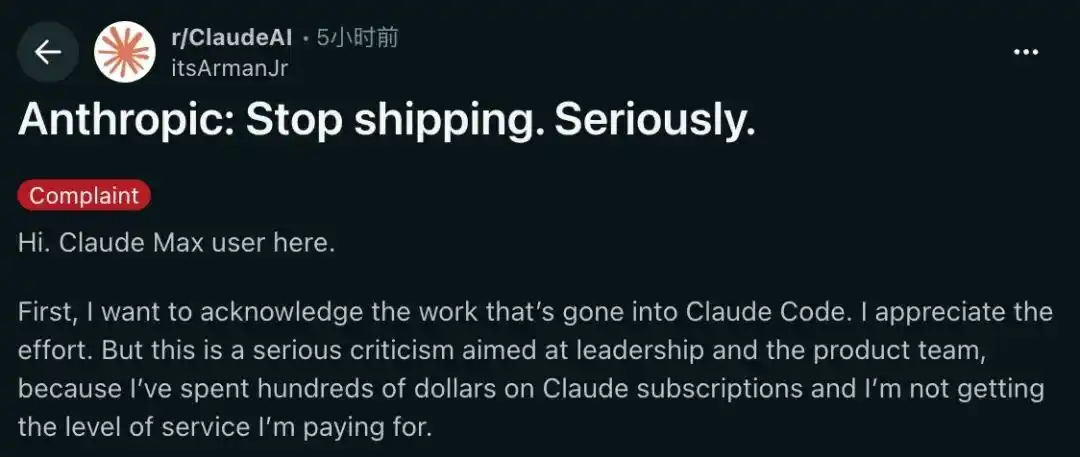
Un utilisateur abonné de longue date à Claude Max a également publié un long article pour dénoncer profondément Anthropic.
À ses yeux, Anthropic est empêtré dans une impasse de puissance de calcul, comme en témoignent le resserrement des limites d'utilisation et le forcing pour réduire la consommation de tokens.
Cependant, ce qui l'indigne encore plus que les goulots d'étranglement techniques, c'est sa stratégie produit « qui ne fait pas son travail ».
Alors que le modèle central est instable et buggé, ils gaspillent une précieuse puissance de calcul dans le développement de fonctions fantaisistes comme le animal de compagnie de terminal « /buddy ».
C'est probablement la « fausse note temporelle » la plus absurde de l'histoire de l'IA : dans le laboratoire, Claude Mythos détruit le monde, tandis que sur le web, Opus 4.6 voit son QI chuter vertigineusement.
Anthropic a réussi à créer une « super IA de Schrödinger ».
Références :
https://officechai.com/ai/anthropic-and-openai-are-exaggerating-cybersecurity-risk-says-hacker-george-hotz/
https://x.com/stanislavfort/status/2041922370206654879?s=20
https://aisle.com/blog/ai-cybersecurity-after-mythos-the-jagged-frontier
https://x.com/cgtwts/status/2043095382121681272?s=20
https://www.reddit.com/r/ClaudeAI/comments/1siqwmp/anthropic_stop_shipping_seriously/
Cet article provient du compte WeChat public «新智元» (New Wisdom Yuan), auteur : 新智元