L'IA ressemble de plus en plus à l'humain, obligeant ce dernier à prouver qu'il n'est pas une IA.
Rien que ce mois-ci, deux événements ont secoué le milieu littéraire.
Le premier : une nouvelle primée par le Commonwealth Short Story Prize a été jugée "100% générée par IA" par un outil de détection tiers. Les organisateurs ont utilisé Claude pour vérifier, mais n'ont pas obtenu de résultat similaire.
Le second : le nouveau roman d'un lauréat du prix Nobel de littérature, avant même sa sortie, a été soupçonné d'avoir été écrit par une IA.
L'IA devient de plus en plus puissante, et il est de plus en plus difficile de distinguer à l'œil nu les textes, images et vidéos. Mais parallèlement, les outils de jugement dont disposent les humains ne sont pas aussi fiables.
Dès lors, un nouvel ordre est apparu.
Les lauréats de prix littéraires doivent expliquer leurs œuvres, les auteurs Nobel leurs méthodes de création, les illustrateurs doivent enregistrer leur écran, faire des lives, montrer leurs calques, et les blogueurs ordinaires peuvent se voir accusés dans les commentaires d'avoir un "trop-plein de goût d'IA".
Autrefois, la machine s'efforçait de passer le test de Turing, prouvant qu'elle ressemblait à l'humain.
Aujourd'hui, de plus en plus de gens participent à un test de Turing inversé : prouver qu'ils ne sont pas des machines.
01
Même les lauréats du prix Nobel de littérature n'échappent pas à la 'détection d'IA'
En mai dernier, une nouvelle primée par le Commonwealth Short Story Prize a provoqué une grande controverse sur la "détection d'IA".
En cause, la nouvelle de l'auteur trinidadien Jamir Nazir.
Cette œuvre a remporté le prix régional Caraïbes du Commonwealth Short Story Prize 2026 et a été publiée dans le magazine littéraire Granta. Très vite, des lecteurs et des professionnels ont commencé à douter, trouvant dans le langage de la nouvelle des traces évidentes d'IA : métaphores hétéroclites, phrases trop régulières, figures de style semblant générées en série.

Ensuite, l'outil de détection d'IA Pangram a rendu un verdict apparemment très clair : 100% généré par IA.
Le chiffre de 100% semblait être une preuve irréfutable, mais il n'est pas immédiatement devenu une sentence.
La Commonwealth Foundation a indiqué que tous les auteurs sélectionnés avaient confirmé ne pas avoir utilisé d'assistance par IA ; Granta ne pouvait pas non plus, sur la base d'un seul résultat de détection, conclure à une infraction de l'auteur.

Les choses sont alors entrées dans une phase extrêmement absurde. Le magazine Granta a tenté de vérifier cette nouvelle avec Claude, demandant à une autre IA de juger si elle avait été écrite par une IA.
Résultat : Claude n'a pas fourni de réponse définitive. Autrement dit, l'œuvre que Pangram avait catégoriquement jugée "100% générée par IA", Claude a déclaré ne pas pouvoir la déterminer.
La lauréate du prix Nobel de littérature Olga Tokarczuk a récemment été confrontée à une controverse similaire.
L'origine de l'affaire remonte à une interview où elle a expliqué utiliser l'IA pour l'aider dans la conception, la collecte de documentation, les recherches préliminaires et la vérification des faits.

Cette déclaration a rapidement suscité des discussions. Le problème, c'est que Tokarczuk s'apprêtait à publier un nouveau livre, et tout le monde s'est mis à spéculer sur le fait que son nouveau roman aurait été écrit par une IA.
Par la suite, Tokarczuk a dû clarifier publiquement que son nouveau livre en polonais, prévu pour l'automne 2026, n'était pas écrit par une IA ou par quelqu'un d'autre. Elle a insisté sur le fait qu'elle écrivait seule depuis des décennies.
Au fond, l'IA devient effectivement de plus en plus forte, et la détection d'IA devient de plus en plus difficile.
Fin de l'année dernière, le New Yorker a publié un article expérimental. Des chercheurs ont utilisé les œuvres de plusieurs auteurs pour affiner des modèles, permettant à l'IA d'apprendre et d'imiter leur style personnel.
Dans l'expérience, des étudiants en création littéraire, sans être informés, ont lu des textes humains et des textes générés par IA, et ont indiqué lequel ils préféraient. Résultat : dans près des deux tiers des cas, ils ont préféré la version générée par IA.
C'est encore plus problématique que "l'IA peut écrire des romans".
Vauhini Vara, auteur pour le New Yorker, écrit également dans l'article que des amis et des lecteurs professionnels ont pris des phrases générées par IA pour son propre style, et ont critiqué des passages qu'elle avait réellement écrits en disant qu'ils "ressemblaient à de l'IA".
02
Les illustrateurs qui 'prouvent leur innocence' en enregistrant tout en vidéo sont au bord des larmes
L'"effet de vallée de l'étrange" ne se limite pas à une entité ressemblant vaguement à un humain. Lorsque les textes, images et vidéos produits par l'IA se rapprochent de plus en plus de l'humain, jusqu'à conquérir le "style", la dimension la plus humaine, une crise existentielle chez l'humain est inévitable.
C'est l'une des motivations centrales de la popularité actuelle des "accusations gratuites d'IA".
En d'autres termes, on peut comprendre que les gens "détectent l'IA", car cela cache en réalité une certaine peur : est-ce un humain ? Est-ce une IA ? Qui suis-je ? Qui sommes-nous ?
Mais être compréhensible ne signifie pas être juste. La "détection d'IA" cause des problèmes aux créateurs de divers domaines, leur imposant un coût supplémentaire de "prouver leur innocence" en plus de leur travail de création.
En matière d'impact de l'IA, le milieu du dessin n'est pas étranger. Nous avons discuté il y a plusieurs années déjà de l'impact de l'IA sur le dessin et de la résistance de nombreux illustrateurs face à l'IA.
Cependant, aujourd'hui, les problèmes auxquels sont confrontés les illustrateurs ne se limitent plus à devoir éviter que l'IA assimile leurs œuvres, mais aussi à voir leurs créations manuelles être "détectées comme de l'IA".
En cherchant "UP dessin prouver" sur les réseaux sociaux, on trouve de nombreux cas.
Certains illustrateurs, après avoir été "détectés comme de l'IA", enregistrent leur écran pour montrer tous leurs calques, prouvant ainsi que l'œuvre est de leur main.
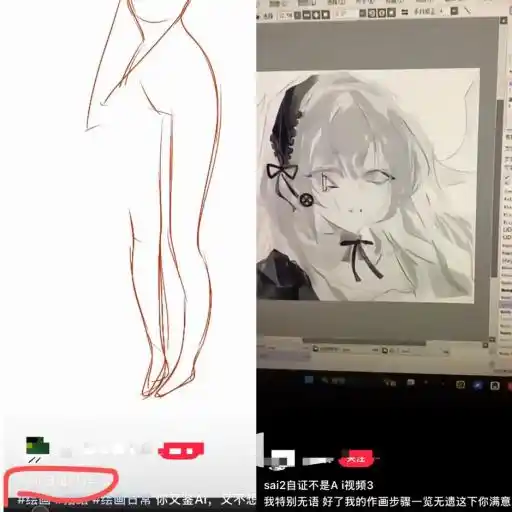
Mais souvent, cela ne suffit pas.
Une amie illustratrice nous a expliqué que de nombreux illustrateurs enregistrent désormais l'intégralité de leur processus de dessin en vidéo, pour éviter de ne pas pouvoir se justifier en cas d'"accusation d'IA". C'est actuellement la méthode la plus sûre.
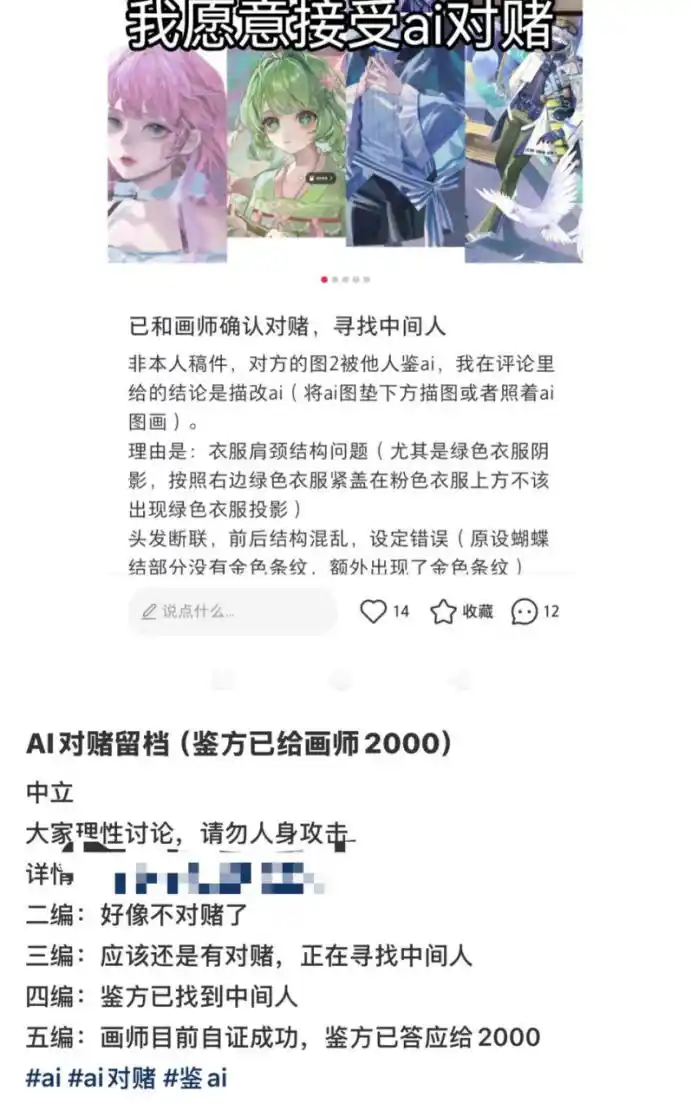
S'il n'y a pas d'enregistrement vidéo, ou s'il y a une "preuve" vidéo mais que des doutes persistent quant à un "tracé par calque", alors il y a une étape suivante : le pari.
Oui, dans le milieu du dessin, à cause de l'IA, des paris se sont développés entre la partie qui "détecte l'IA" et celle qui en est "accusée". Dans un cas que nous avons vu, la personne ayant posté le message a avancé plusieurs arguments comme "des cheveux disjoints", "une structure du cou et des épaules problématique", etc., pour suspecter que l'œuvre d'un illustrateur était en réalité un tracé ou une copie par-dessus une image d'IA.
Les deux parties ont parié 2000 yuans, et finalement l'illustrateur a "prouvé son innocence", la personne ayant posté le message a dû payer 2000 yuans à l'illustrateur.
Généralement, la phase de "preuve" dans un "pari" consiste à convenir d'un horaire pour un live de dessin. De plus, le live nécessite plusieurs angles de caméra, par exemple un angle montrant le processus sur l'écran, et un autre enregistrant l'illustrateur en train de dessiner, pour éviter toute "substitution".
Dans de nombreux posts d'"auto-justification" d'illustrateurs, on sent une émotion de résignation. Ils expriment souvent des sentiments du type "finalement, c'est mon tour", et jurent que "c'est la première et la dernière fois que je me justifie".
Ainsi, d'un côté, ils détestent les "accusations gratuites d'IA", et de l'autre, quand c'est vraiment leur tour, ils doivent "prouver leur innocence", ce qui est vraiment pénible.
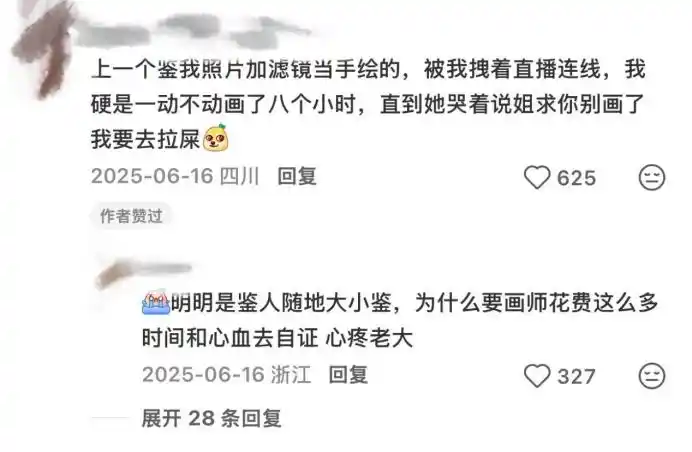
Y a-t-il des cas où la "détection d'IA" a réussi et l'illustrateur a échoué à "se justifier" ? Oui. Mais cela ne rend pas pour autant le comportement de "détection d'IA" plus légitime. Après tout, le coût de "détecter l'IA" est quasiment nul.
Et les méthodes de "détection d'IA" sont encore plus grossières : à l'œil nu.
Ici, il faut mentionner une anecdote récente. Un utilisateur de X a posté une image, disant qu'il s'agissait d'une "image de style Monet" générée par IA, et a demandé aux gens d'"expliquer le plus en détail possible pourquoi elle était inférieure à un vrai Monet".

Le post a atteint 7 millions de vues, et de nombreuses personnes dans les commentaires se sont sérieusement mises à "détecter l'IA", disant qu'il manquait de profondeur, que les couleurs n'étaient pas homogènes, qu'il n'y avait pas d'âme humaine, que la composition était inférieure à l'original, et certains ont même analysé avec force détails le coup de pinceau et le sens de l'espace.

Le retournement de situation : l'image était en réalité une vraie toile de Monet.
03
Qui a le dernier mot dans la 'détection d'IA' ?
Il s'agit donc en réalité de la contradiction entre la peur que l'IA ressemble de plus en plus à l'humain et l'absence de moyens parfaits pour la "détecter".
La grossièreté des moyens de "détection d'IA" est un autre facteur important qui plonge les créateurs collectivement dans l'obligation de "prouver leur innocence".
Outre la méthode de "détection à l'œil nu", comme mentionné précédemment avec l'œuvre du lauréat du concours littéraire, un autre moyen principal de "détecter l'IA" est l'outil de détection tiers Pangram.
Les outils de détection d'IA sont couramment utilisés dans le domaine textuel, ce qui peut créer l'illusion qu'ils donnent un pourcentage, comme "80% généré par IA", "100% généré par IA". Ce chiffre semble être une conclusion, voire une sorte d'expertise technique.

Mais la détection de texte n'a rien à voir avec un test ADN. Elle juge en réalité "à quoi ressemble statistiquement ce texte".
L'outil de détection d'IA, lui aussi, regarde 'si cela ressemble à quelque chose écrit par une IA'.
Pangram explique sur son site que son détecteur d'IA utilise le traitement du langage naturel et de grandes quantités de données d'écriture humaine et d'écriture par IA pour analyser la structure, le style et les modèles sémantiques des textes d'IA. Le rapport technique de Pangram indique également que son cœur est un classifieur de réseau neuronal basé sur Transformer, dont l'objectif d'entraînement est justement de distinguer les textes produits par des grands modèles de langage de ceux écrits par des humains.
Autrement dit, ce type d'outil ne consiste pas à prendre un article et à consulter une "base de données de textes d'IA" pour voir s'il correspond à un échantillon connu.
Cela ressemble plus à une reconnaissance de modèles. Le choix du vocabulaire, le rythme des phrases, l'agencement de la structure, les modes de connexion sémantique de ce texte sont-ils plus proches des textes humains qu'il a vus, ou plus proches des textes d'IA qu'il a vus ?
Ce qui est plus problématique, c'est qu'il y a trop de cas particuliers. Si un article est écrit en première version par un humain, puis retouché avec quelques phrases par IA, comment le comptabiliser ? Si c'est une IA qui génère le plan, et qu'un humain réécrit l'intégralité du texte, comment le comptabiliser ? Si des documents en anglais sont traduits en chinois par une IA, puis modifiés manuellement par l'auteur, l'outil de détection peut-il encore juger ? Si un étudiant dont la langue maternelle n'est pas l'anglais écrit de manière plus régulière, plus stéréotypée, sera-t-il plus facilement faussement accusé ?
Dans le domaine du dessin, c'est pareil. Certains illustrateurs se lamentent — oui, il y a effectivement un problème de structure, mais c'est parce que ma technique a encore besoin de s'améliorer, pas parce que c'est un dessin d'IA !
En 2023, des chercheurs de l'université de Stanford ont testé 7 détecteurs de texte d'IA.
Ils ont sélectionné 91 essais rédigés par des étudiants non anglophones pour le TOEFL — ces essais provenaient du corpus officiel de l'examen TOEFL, étant eux-mêmes écrits à la main par des étudiants dans des conditions réelles d'examen, il était donc certain qu'ils n'étaient pas générés par IA.
Résultat : 89 d'entre eux ont été marqués comme générés par IA par au moins un détecteur ; le taux moyen de fausses alertes atteignait 61,22 % ; et 18 essais ont été unanimement jugés comme générés par IA par les 7 détecteurs. Autrement dit, ces étudiants écrivaient dans une langue étrangère, mais parce que leur expression était plus régulière, plus proche de modèles, les outils les ont pris pour des machines.
Bien sûr, les outils de détection de 2023, 2024 ne peuvent être simplement assimilés à ceux d'aujourd'hui. Ces dernières années, les détecteurs commerciaux ont effectivement évolué, et les performances de certains nouveaux outils dans des tests spécifiques se sont nettement améliorées.
Mais le problème n'est pas résolu.
Les "erreurs de jugement" n'ont pas été totalement éliminées, laissant une marge au conflit.
Après tout, ce que l'outil fournit est une probabilité, mais lorsqu'elle s'applique à une personne, cela devient une accusation.
04
Et les fameux 'filigranes' ?
Une question plus importante : les entreprises d'IA ne devraient-elles pas faire du "marquage de source" ?
Mettre un "filigrane" natif sur tous les contenus d'IA, indélébile, ne résoudrait-il pas le problème de l'identification ?
Beaucoup, en entendant "filigrane", pensent encore au logo dans un coin de l'image, à l'identifiant de plateforme sur la vidéo, ou aux mots "Généré par IA".
Mais les filigranes d'IA d'aujourd'hui ne sont plus seulement ce genre de marques visibles à l'œil nu.
L'industrie adopte globalement deux types d'approches : l'une concerne les métadonnées, comme C2PA et Content Credentials, qui équivalent à attacher une "carte d'identité" au contenu numérique, enregistrant quel outil l'a généré, quand, quelles modifications il a subies ;
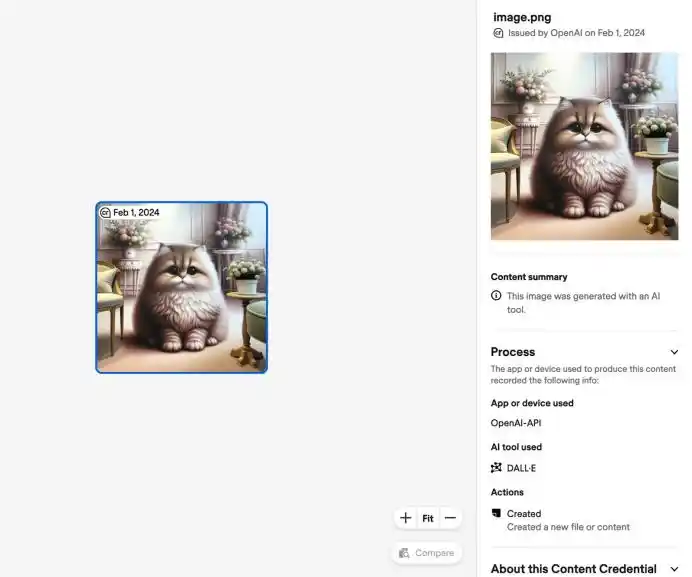
L'autre concerne le filigrane invisible, intégrant dans l'image, l'audio, la vidéo, voire le texte, des signaux imperceptibles à l'œil humain mais identifiables par une machine.
Dans le domaine de l'image et de la vidéo, ces solutions commencent à être déployées.
Le SynthID de Google DeepMind peut intégrer un filigrane invisible dans les contenus générés par des outils comme Imagen, Veo, Lyria, Gemini, etc.
Meta a indiqué que les images générées ou éditées par Meta AI recevraient un filigrane visible, un filigrane invisible et des métadonnées ; OpenAI a également ajouté des justificatifs de contenu C2PA aux images générées par DALL·E 3 et ChatGPT, et a ensuite introduit le filigrane invisible SynthID. Adobe, Microsoft, Google, Meta, OpenAI et d'autres entreprises participent également à l'écosystème C2PA et Content Credentials.

Cela montre que les entreprises d'IA savent également que se fier uniquement au jugement à l'œil nu "si cela ressemble à de l'IA" est insuffisant. Elles essaient déjà d'utiliser les métadonnées, les justificatifs de contenu, les filigranes invisibles et les étiquettes de plateforme pour laisser un signal de source lisible par machine sur les contenus générés par IA.
Mais ces solutions ne sont pas parfaites. Les métadonnées peuvent être perdues lors d'une capture d'écran, d'une compression, d'un transfert, d'un nouveau téléchargement ; les filigranes visibles peuvent être recadrés ou masqués ; les filigranes invisibles sont plus résistants, mais peuvent également être affaiblis par un traitement ultérieur, une perturbation ou une régénération.
Plus crucial encore, ces solutions ne peuvent généralement identifier que les contenus intégrés au système correspondant et conservant la marque correspondante. Autrement dit, le SynthID de Google identifie principalement les contenus portant SynthID, les justificatifs de contenu d'OpenAI indiquent principalement que le contenu provient du système OpenAI. Dès que le contenu provient d'un modèle non intégré au marquage, ou après de multiples transferts, la chaîne de provenance peut être rompue.
Pour le texte, le problème est plus complexe.
Le texte peut bien sûr également recevoir un filigrane. Son principe est de modifier discrètement, lors de la génération de texte par le modèle, la probabilité de choix de certains mots, de sorte que le texte final présente un modèle statistique imperceptible à l'œil humain mais identifiable par un détecteur. En bref, c'est faire en sorte que l'IA laisse son "empreinte lexicale".
Google a déjà rendu public SynthID-Text, affirmant qu'il peut intégrer un filigrane dans les textes générés par Gemini. OpenAI est également très attendu sur cette question. En juillet 2023, OpenAI, Google, Meta, Amazon, Anthropic, Microsoft et d'autres entreprises ont pris des engagements volontaires, déclarant qu'elles développeraient des mécanismes pour aider les utilisateurs à identifier les contenus générés par IA, y compris les filigranes et le marquage de la source.
Mais plusieurs années ont passé, les solutions de marquage pour l'image, l'audio, la vidéo progressent, tandis que le texte n'a toujours pas de réponse générique, claire, activée par défaut et accessible au public.
OpenAI avait lancé en 2023 un classificateur de texte d'IA (AI Text Classifier) pour juger si un texte était généré par IA, mais avait prévenu dès son lancement de ne pas s'en servir comme unique base de décision.
Six mois plus tard, OpenAI l'a retiré en raison d'un taux de précision trop faible.
En 2024, le Wall Street Journal a rapporté qu'OpenAI avait en interne développé un outil de filigrane textuel, efficace à 99,9 % sur des textes suffisamment longs générés par ChatGPT. Mais OpenAI n'a finalement pas publié cet outil.
La raison n'est pas uniquement technique. Le rapport mentionne qu'OpenAI craignait que le filigrane textuel ne provoque un rejet des utilisateurs, n'affecte l'utilisation du produit, et ne stigmatise davantage les utilisateurs non anglophones.
De plus, une enquête a montré que près de 30 % des utilisateurs de ChatGPT déclaraient qu'ils pourraient réduire leur utilisation si un filigrane textuel était activé.
En fin de compte, pour en revenir à la tension entre la "détection d'IA" et la "preuve d'innocence", toutes les solutions de filigrane mentionnées ci-dessus ne peuvent encore garantir une efficacité à toute épreuve.
Les humains ont un dicton : "à mesure que le bien progresse, le mal progresse encore plus", et un autre : "à chaque politique, sa contre-mesure". Tant que les humains croiront en ces deux dictons, la "détection d'IA" ne s'arrêtera pas.
Peut-être qu'un jour, la "participation de l'IA" deviendra l'état par défaut, que l'"originalité humaine" deviendra exceptionnellement rare, et cette grande tension entre "détection d'IA" et "preuve d'innocence" perdra alors son sens.
Cet article provient du compte WeChat public "Face à l'IA" (ID : faceaibang), auteur : Petit Canine Dorée, éditeur : Wang Jing






