TL;DR
Un schéma estimatif qui décompose l'abonnement mensuel américain Claude Pro d'environ 20 $ entre l'entreprise de modèles, le cloud/calcul, l'amortissement du GPU, l'électricité et la chaîne d'approvisionnement amène les investisseurs à reconsidérer comment évaluer les revenus des applications d'IA.
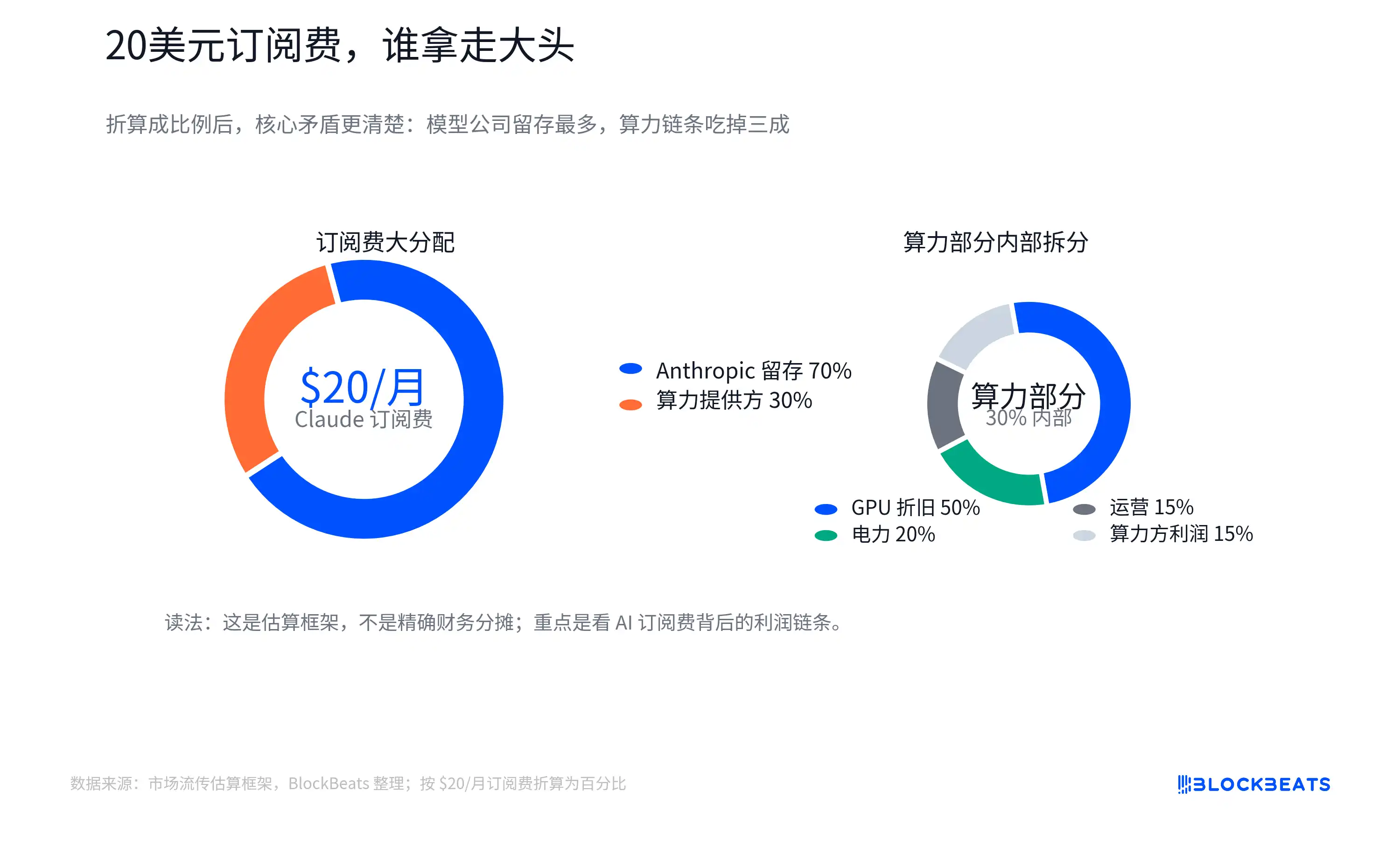
Ce schéma ne représente pas les données officielles de partage des revenus d'Anthropic, d'Amazon Web Services ou de NVIDIA, et ne doit pas être considéré comme le bilan réel d'une entreprise. Sa valeur réside dans la mise en lumière d'une question plus fondamentale : quelle partie des frais d'abonnement payés par l'utilisateur pour une application d'IA peut se transformer en marge brute logicielle, comme dans le SaaS traditionnel ?
La vision de valorisation du SaaS traditionnel est claire. Une fois le logiciel développé, la vente d'un compte supplémentaire génère généralement des coûts marginaux faibles ; les entreprises de logiciel purs et matures affichent souvent des marges brutes supérieures à 70%, voire 80%. Les investisseurs acceptent des multiples élevés car les marges bénéficiaires ont le potentiel de s'améliorer avec l'augmentation du chiffre d'affaires.
Le problème des applications d'IA est que chaque requête de l'utilisateur - qu'il s'agisse de poser une question, d'écrire du code, d'analyser un fichier ou d'appeler un agent - consomme du temps GPU, de l'électricité, de la bande passante mémoire et des ressources cloud. En surface, c'est un abonnement fixe, mais en coulisses, il y a une chaîne de coûts qui varie avec l'utilisation. Les utilisateurs légers peuvent être très rentables, tandis que pour les utilisateurs intensifs exécutant des tâches en continu dans les limites de leur forfait ou d'outils associés, les coûts peuvent augmenter rapidement.
Ainsi, l'objectif du schéma de décomposition des 20 $ n'est pas de déterminer précisément combien chaque entreprise prélève, mais de remettre en question l'idée que « les revenus d'une application d'IA sont naturellement équivalents à des revenus SaaS ». Pour justifier une valorisation élevée, une entreprise d'IA doit non seulement prouver que les utilisateurs sont prêts à payer, mais aussi que la marge brute pondérée par le volume d'utilisation peut s'améliorer de manière durable.
Derrière les frais d'abonnement se cache une chaîne de coûts d'inférence
La plus grande différence entre un abonnement à l'IA et un abonnement logiciel classique réside dans le fait que le coût marginal « par utilisation » n'est plus proche de zéro.
Dans le SaaS traditionnel, lorsqu'une équipe ouvre un compte supplémentaire, le fournisseur supporte également des coûts de serveurs, de support client et de bande passante, mais ces coûts n'augmentent généralement pas linéairement avec chaque clic. Les coûts réellement élevés sont ceux de la R&D préalable, des ventes et de l'acquisition de clients. Une fois le produit mis à l'échelle, une part substantielle du revenu supplémentaire peut être conservée.
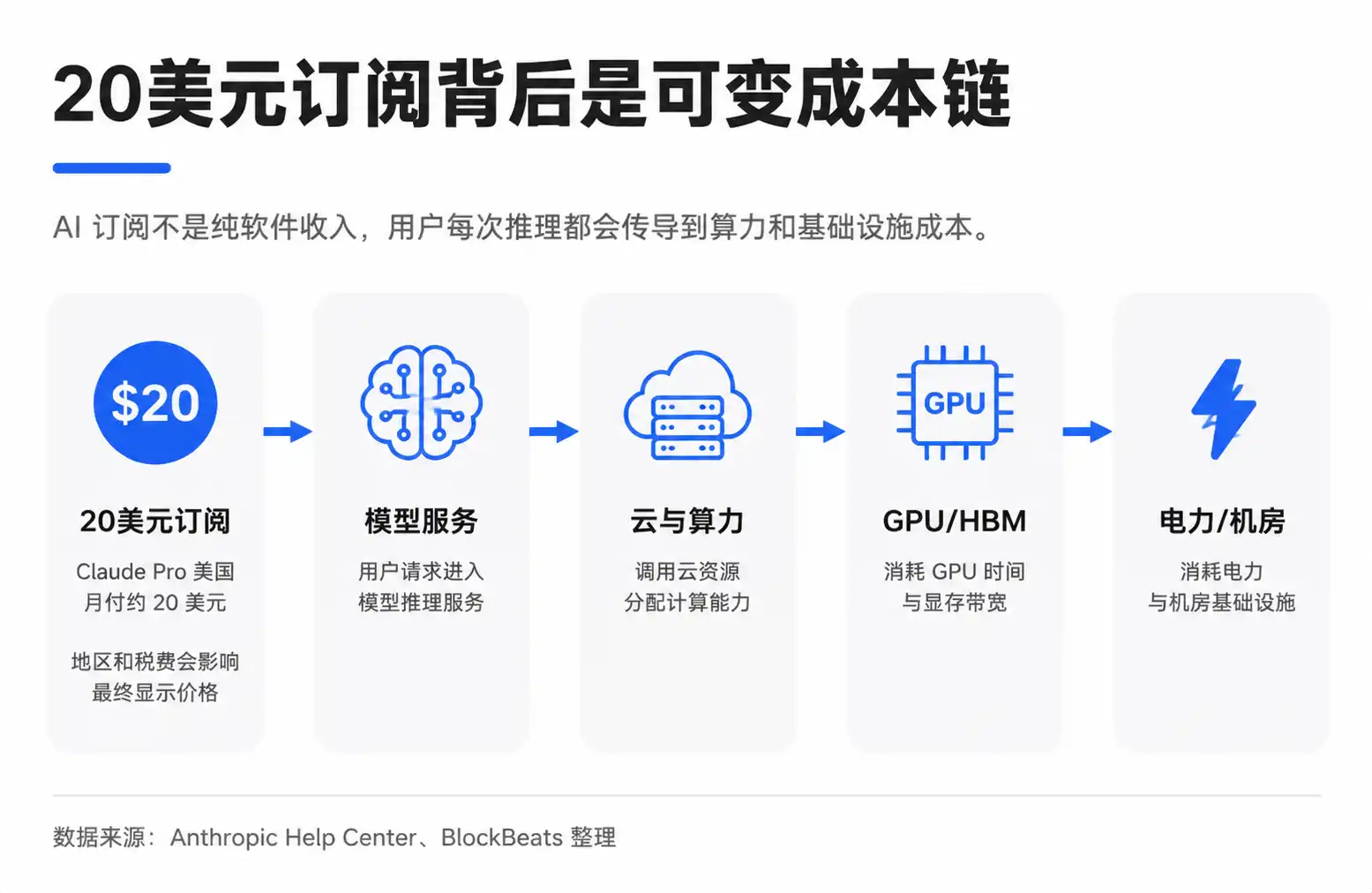
Les produits de grands modèles sont différents. L'utilisateur saisit une question, le modèle génère une réponse : ce processus s'appelle l'inférence, c'est-à-dire le calcul effectif lorsque le modèle est appelé par l'utilisateur. Le token est l'unité de base pour mesurer la lecture/écriture de texte par le modèle. Plus l'utilisateur pose de questions, plus le contexte est long et plus le contenu généré est complexe, plus la consommation de tokens et de puissance de calcul est importante.
Cela crée une contradiction entre l'abonnement fixe et les coûts variables. L'abonnement mensuel Claude Pro est d'environ 20 $ aux États-Unis, un prix qui peut varier selon la région, les taxes et les ajustements d'Anthropic. L'utilisateur voit un prix fixe, mais l'entreprise de modèles fait face à des comportements d'utilisation très variés. Certains se contentent d'écrire des e-mails et de rechercher des informations, tandis que d'autres traitent de longs documents, exécutent des tâches de codage ou utilisent des processus d'automatisation plus complexes.
Le schéma de décomposition circulant sur le marché tente de rendre cela concret : sur 20 $, une partie revient à l'entreprise de modèles, une autre partie paie les fournisseurs de cloud et de puissance de calcul. Les coûts de calcul incluent l'électricité, l'exploitation-maintenance et l'amortissement des GPU. L'achat des GPU remonte ensuite la chaîne vers NVIDIA, TSMC, les fournisseurs de HBM (mémoire à large bande passante), les fabricants de modules optiques, les ODM et les entreprises liées à l'électricité.
Ici, « l'amortissement du GPU » peut être compris comme le fait que le coût élevé du GPU n'est pas imputé en une fois, mais est réparti progressivement dans le service d'IA selon sa durée d'utilisation, son intensité d'utilisation ou les règles comptables. La répartition réelle est influencée par les limites des forfaits, la proportion d'utilisateurs légers et intensifs, les prix de facturation interne des fournisseurs cloud, les remises sur la capacité réservée, le taux d'utilisation des GPU et la durée d'amortissement. Le coût moyen n'est pas égal au coût marginal.
Ce sur quoi les investisseurs doivent vraiment se concentrer est la tendance : les entreprises d'applications d'IA ne peuvent pas se contenter de divulguer la croissance de leurs revenus, elles doivent aussi expliquer si les coûts de calcul sous-jacents à cette croissance augmentent au même rythme. Si l'expansion du volume d'utilisation est plus rapide que l'amélioration de l'efficacité des modèles, plus les revenus d'abonnement sont élevés, plus la pression sur la marge brute peut devenir évidente. Ce n'est que si l'amélioration de l'efficacité est suffisamment rapide que les entreprises de modèles auront une chance de se rapprocher à nouveau de la structure bénéficiaire des éditeurs de logiciels.
L'infrastructure perçoit d'abord des revenus plus certains
À ce stade, la croissance du volume d'utilisation de l'IA alimente plus directement l'infrastructure que la couche applicative dans son ensemble.
Que l'utilisateur utilise un modèle dans Claude, ChatGPT, Gemini ou un agent interne d'entreprise, l'inférence finit par reposer sur la puissance de calcul, l'électricité, la mémoire et le réseau. La couche applicative peut connaître des changements de produits, mais la consommation de ressources de base est plus rigide. Tant que le volume d'utilisation de l'IA continue d'augmenter, les dépenses en capital cloud, les achats de GPU, la demande en HBM et la consommation électrique des centres de données seront stimulés.
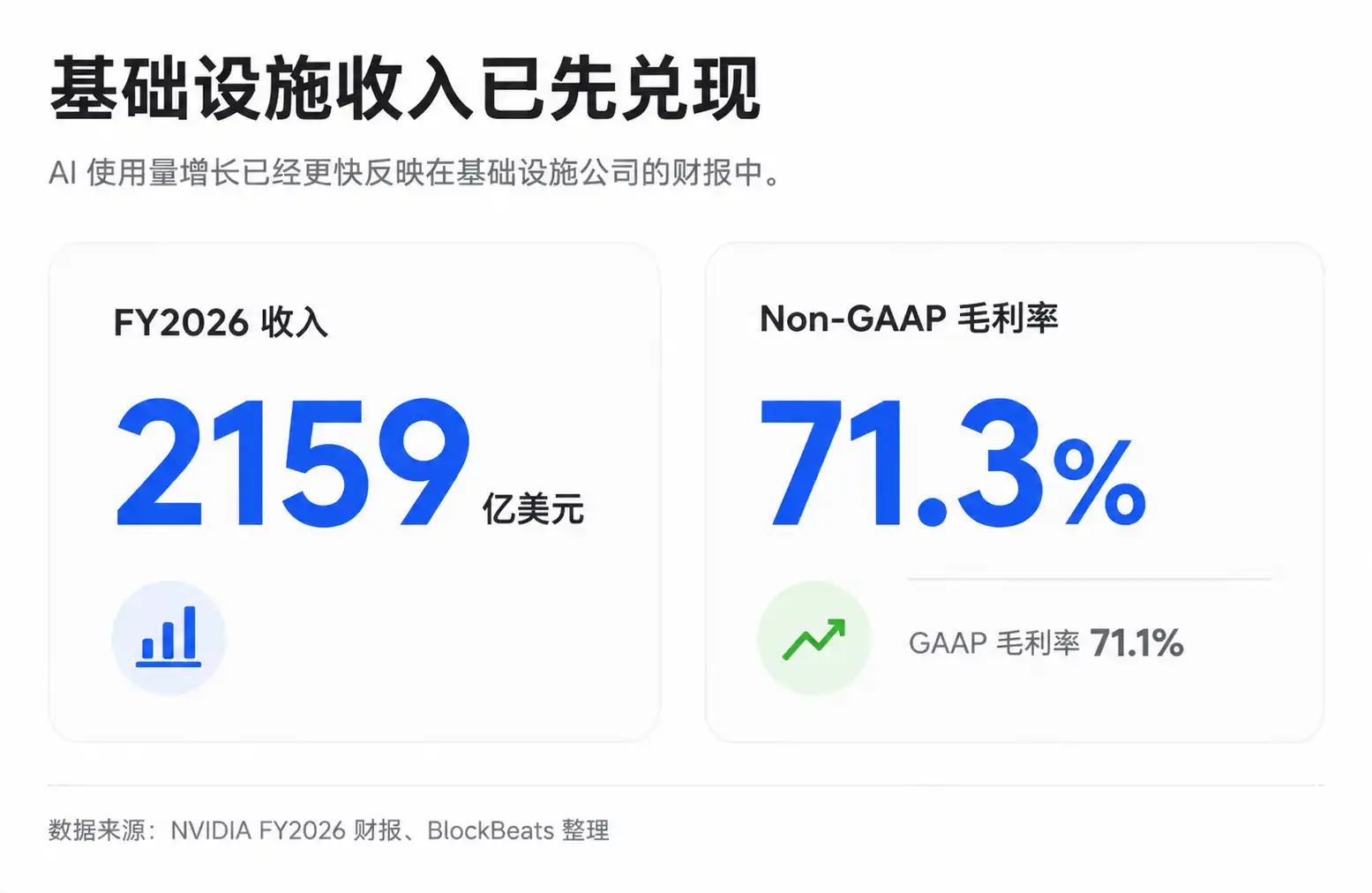
C'est également la raison pour laquelle la chaîne d'infrastructure, avec NVIDIA, TSMC, SK Hynix, etc., continue d'être réévaluée par le marché. La marge brute globale de NVIDIA est restée à un niveau élevé ces dernières années, environ 71,1 % (GAAP) et 71,3 % (non-GAAP) pour l'exercice 2026, et les prévisions pour les trimestres suivants restent élevées. Il convient de noter que certains trimestres peuvent être affectés par des charges spécifiques, et les résultats financiers publics ne permettent pas toujours de décomposer directement la structure réelle de la marge brute des centres de données d'IA, mais le pouvoir de fixation des prix des infrastructures rares est déjà reflété dans les performances.
Le HBM est un maillon typique de cette chaîne. Il ne s'agit pas d'une mémoire ordinaire, mais d'un composant clé des accélérateurs d'IA qui supporte les calculs à haut débit. Avec l'augmentation de la taille des modèles, de la longueur du contexte et des besoins en inférence simultanée, la dépendance des puces d'IA à la mémoire à large bande passante s'accroît. Les estimations de la chaîne d'approvisionnement montrent que la part du HBM dans le coût des nouvelles puces d'IA augmente, ce qui explique aussi pourquoi SK Hynix, Samsung, Micron sont reprixés dans ce cycle d'IA.
L'électricité et les centres de données passent également du statut de coût de fond à celui de thème d'investissement principal. La consommation d'énergie d'une simple requête textuelle n'est peut-être pas énorme, mais les agents complexes, les longs contextes, la génération de code et les tâches multi-tours amplifient la quantité de calcul. Pour les fournisseurs de cloud et les opérateurs de centres de données, l'enjeu n'est pas la consommation d'une requête unique, mais le fait que lorsque des volumes massifs de requêtes d'inférence se produisent en continu, le taux d'utilisation des clusters, le prix de l'électricité, le refroidissement, la capacité des salles de serveurs et l'accès au réseau électrique deviennent tous des facteurs de coût et des goulots d'étranglement.
L'avantage du côté infrastructure est que la validation des performances est plus rapide. Les dépenses en capital liées à l'IA des fournisseurs cloud ont déjà eu lieu, les revenus et la marge brute de NVIDIA apparaissent dans ses résultats, et les commandes et prix des fabricants de HBM se reflètent également plus rapidement dans leurs comptes de résultats. La couche applicative des modèles négocie davantage sur des attentes futures : taux de conversion aux abonnements, taux de pénétration en entreprise, revenus d'API et libération des bénéfices futurs une fois la courbe des coûts descendue.
L'amélioration de l'efficacité reste l'argument central des optimistes
Les investisseurs en logiciel et les optimistes de l'IA ne sont pas sans réplique. Le point central des partisans de l'efficacité est que le coût élevé actuel de l'inférence n'est qu'un phénomène de la phase initiale, et que l'optimisation des modèles, la mise en cache, les petits modèles, les puces propriétaires et un taux d'utilisation des clusters plus élevé feront continuellement baisser le coût unitaire. Si la baisse des coûts est suffisamment rapide, les applications d'IA pourraient encore revenir à la logique de marge brute élevée des logiciels.
Cette objection a des bases réelles. Certains modèles dominants ont vu leur prix unitaire baisser significativement pour des capacités équivalentes ou supérieures. OpenAI a indiqué que le coût par token de GPT-4o mini avait chuté de 99 % par rapport à l'ancien text-davinci-003. Le rythme n'est pas complètement uniforme selon les entreprises, Anthropic récemment a davantage proposé des mises à niveau au même prix et une stratification des modèles, mais la direction de l'industrie reste d'offrir plus de puissance à un coût moindre.

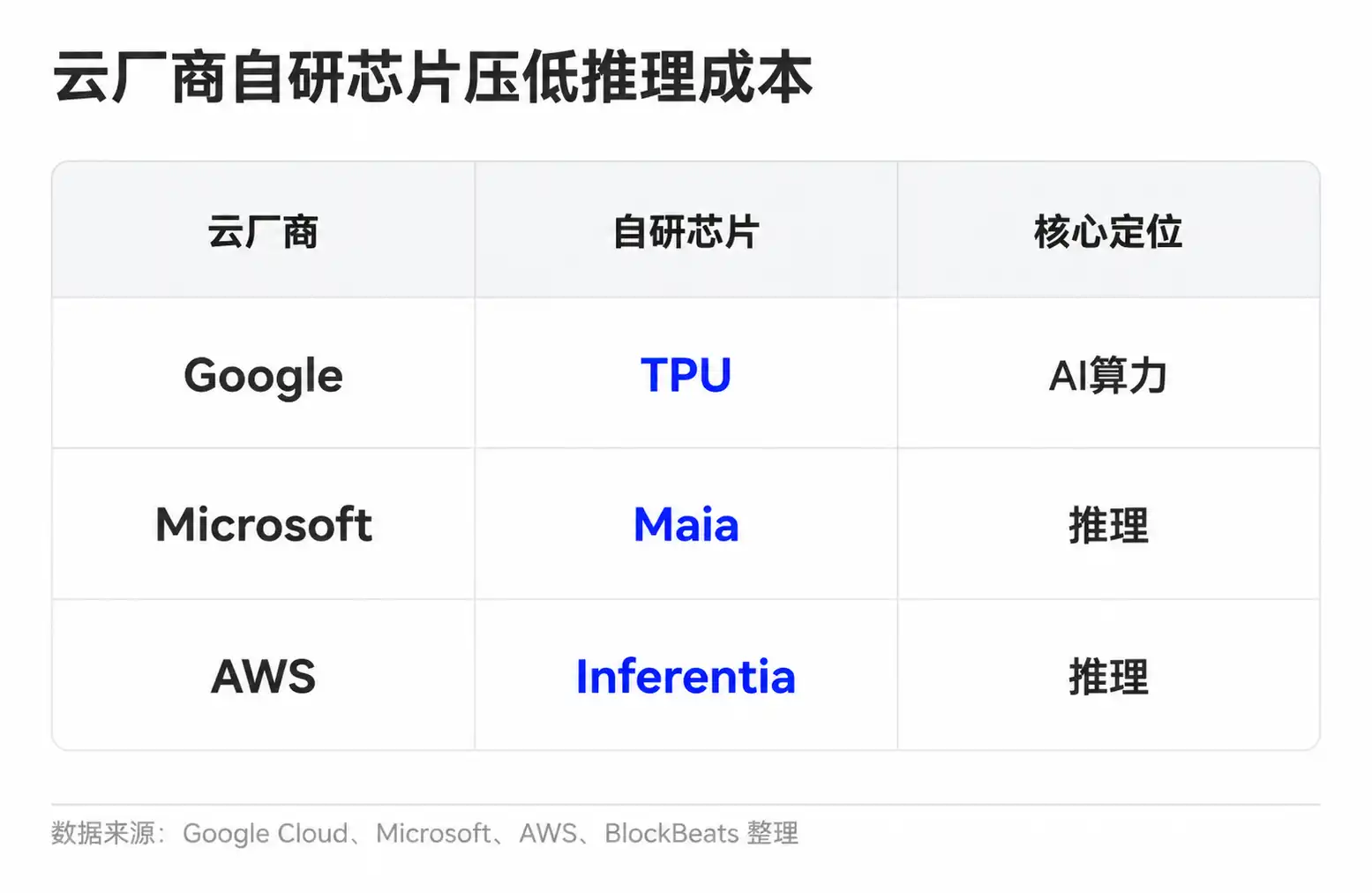
Les entreprises de modèles ont également plusieurs moyens d'améliorer leur économie unitaire. Confier les tâches simples à de petits modèles, réutiliser les requêtes courantes via la mise en cache, dédier les contextes longs et les tâches complexes à des modèles plus puissants. Les fournisseurs de cloud, quant à eux, réduisent le coût unitaire du calcul grâce à des puces propriétaires et à l'ordonnancement des clusters. Google a ses TPU, Microsoft a lancé Maia pour l'inférence, Amazon progresse également avec Trainium et Inferentia.
Si l'on ne considère que le progrès technique, la marge bénéficiaire des applications d'IA a effectivement une marge d'amélioration. Une inférence moins chère, un meilleur routage des modèles, une plus forte capacité de compression peuvent toutes permettre à un même abonnement de 20 $ de supporter un volume d'utilisation plus important. Les utilisateurs légers, les forfaits d'entreprise à prix élevé, la tarification différenciée des API et des limites d'utilisation plus strictes peuvent également améliorer l'économie unitaire globale.
La difficulté réside dans le fait que la baisse des coûts n'est pas la seule variable. Les applications d'IA évoluent du simple chat vers des charges de travail plus lourdes. Autrefois, les utilisateurs se contentaient peut-être de questions-réponses et de reformulation de texte ; aujourd'hui, de plus en plus de demandes proviennent d'agents de code, du traitement de longs documents, de la génération vidéo et multimodale, des processus d'automatisation d'entreprise. Ces scénarios ont une valeur plus élevée, mais aussi une consommation plus élevée. Plus le modèle est utile, plus les utilisateurs sont susceptibles de lui confier des tâches plus complexes et plus longues.
Le désaccord devient ainsi plus concret : la vitesse de baisse du coût de l'inférence peut-elle dépasser la croissance du volume d'utilisation et de la complexité des tâches ? Si le coût unitaire baisse rapidement, mais que la consommation moyenne des utilisateurs augmente encore plus vite, la marge brute pondérée des entreprises de modèles restera sous pression. À l'inverse, si le routage des modèles, la mise en cache, les puces propriétaires et la stratification des prix sont suffisamment efficaces, l'abonnement à l'IA pourrait progressivement se débarrasser de ses caractéristiques de coût élevé actuelles.
Le nombre d'abonnés n'est pas la marge brute
Le schéma de décomposition des 20 $ ne doit pas être interprété comme une fin en soi. Il ressemble davantage à un rappel de valorisation à l'étape actuelle : alors que le marché ne dispose pas encore de données suffisamment transparentes sur la marge brute des entreprises de modèles, les investisseurs doivent appliquer une décote à l'hypothèse selon laquelle « une application d'IA est naturellement égale à du SaaS ».
Pour les entreprises de modèles non cotées comme OpenAI ou Anthropic, les investisseurs externes ont du mal à voir le bilan complet. Les documents de financement, les divulgations des partenaires, la structure des coûts cloud, les prix des forfaits entreprise, la part des revenus d'API et les limites d'utilisation deviennent tous des indices de jugement. Les données vraiment précieuses ne sont pas le nombre d'utilisateurs payants, mais la proportion d'utilisateurs légers et intensifs, la volonté des clients entreprise de payer un prix plus élevé pour une utilisation intensive, l'évolution des coûts de facturation cloud, et la mesure dans laquelle la baisse du coût unitaire de l'inférence se répercute sur la marge brute de l'entreprise.
La validation par la chaîne des sociétés cotées apparaîtra plus rapidement dans les résultats financiers. La marge brute globale et la croissance des revenus des centres de données de NVIDIA, la demande en procédés avancés et en packaging de TSMC, les prix et marges bénéficiaires des fabricants de HBM, l'intensité des dépenses en capital des fournisseurs cloud continueront de refléter si le volume d'utilisation de l'IA se transmet toujours au segment infrastructure. Si ces indicateurs restent solides, tandis que la couche applicative des modèles manque de preuves d'amélioration de la marge brute, le marché continuera d'accorder une prime de valorisation plus certaine à l'infrastructure.
En fin de compte, pour retrouver un ancrage de valorisation plus élevé, les entreprises de modèles devront prouver non seulement que les utilisateurs sont prêts à payer 20 $, mais aussi qu'après une utilisation intensive, ces frais d'abonnement peuvent laisser une marge brute suffisante. Le prochain cycle de divergence sur la valorisation ne portera probablement pas sur les chiffres d'ARR mis en avant, mais sur la possibilité de concilier simultanément les coûts d'inférence, les limites des forfaits et les prix payés par les entreprises.





