Certains l'ont acclamé comme le moment le plus « ouvert » d'OpenAI. En dotant Codex d'une prise permettant de changer facilement de modèle, l'entreprise a comblé elle-même le fossé qui protégeait son propre modèle. Quel est son but ?
Du jour au lendemain, l'agent de programmation intelligent Codex d'OpenAI ne reconnaît plus uniquement le GPT maison, mais s'ouvre à tous les modèles open source.
La communauté des développeurs a été la première à percevoir ce signal.
Un développeur a découvert, dans la configuration de l'interface en ligne de commande (CLI) et du kit de développement logiciel (SDK) de Codex, un mode open source inconnu (OSS mode), également appelé par l'entreprise « fournisseur local » (local providers).
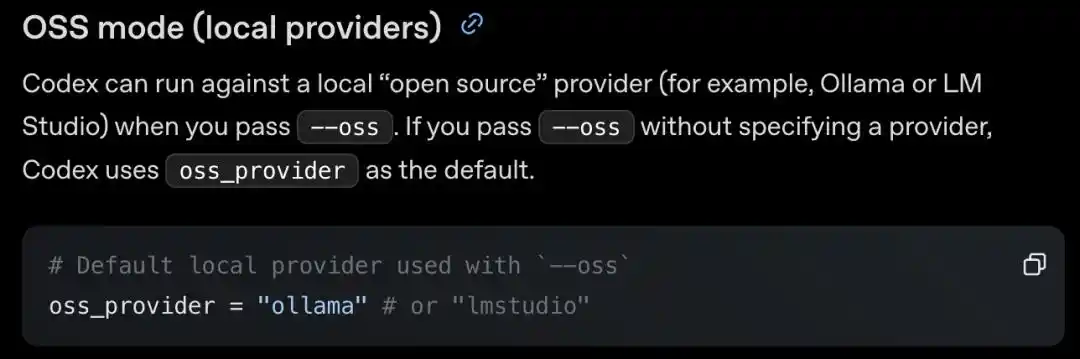
Il suffit d'ajouter un --oss dans la ligne de commande pour exécuter des modèles open source en local ; pour en utiliser d'autres, il faut simplement modifier un champ.
Il faut savoir que dans le passé, OpenAI était presque synonyme de « fermeture », Codex ne reconnaissant que le GPT de l'entreprise.
Mais maintenant, c'est différent : avec une simple ligne de configuration, on peut basculer vers des services de modèles locaux comme Ollama, LM Studio, etc.
La nouvelle a rapidement fait grand bruit dans le cercle des développeurs.
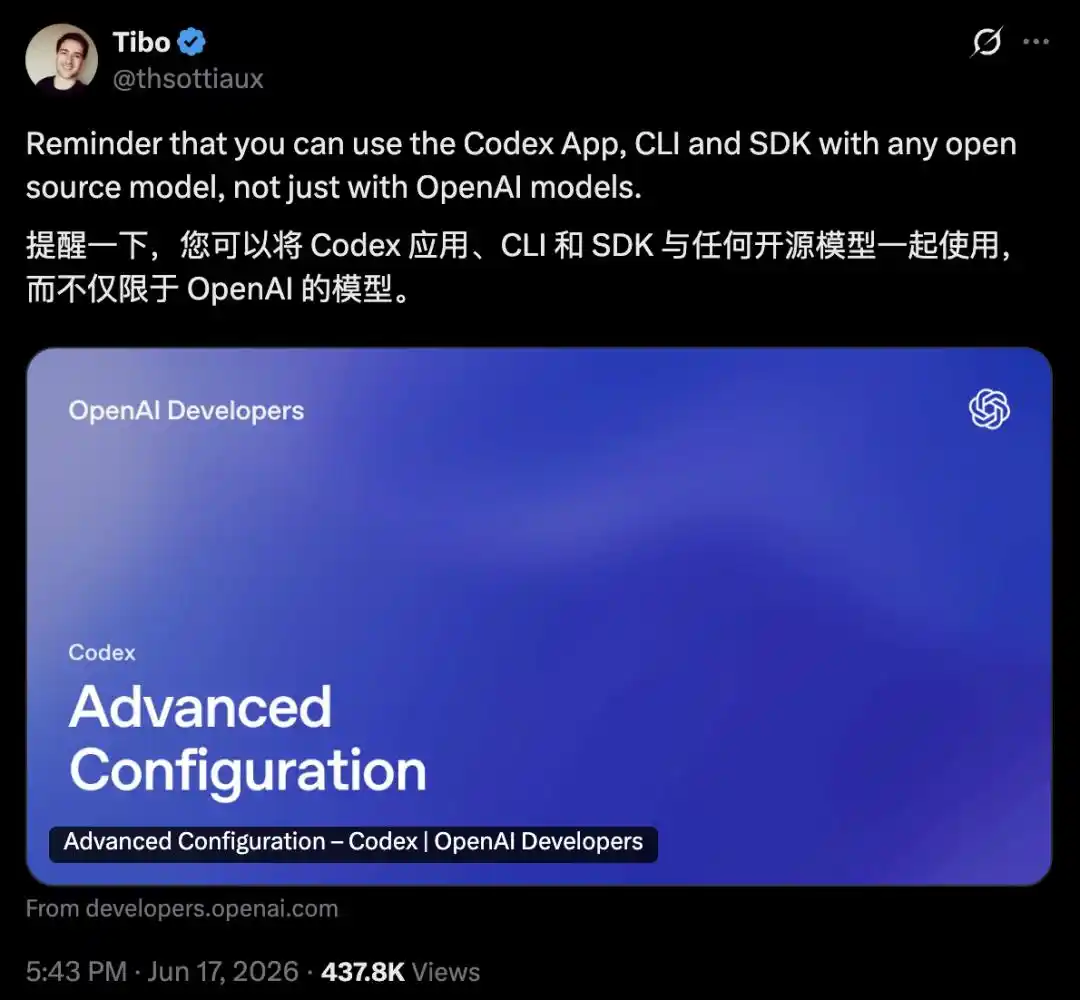
Tibo, le responsable de l'équipe Codex d'OpenAI, n'a pas manqué de le rappeler personnellement sur X :
L'application, la CLI et le SDK de Codex peuvent être utilisés avec n'importe quel modèle open source, pas seulement avec ceux d'OpenAI.
Ce rappel a rapidement été partagé par Thomas Wolf, co-fondateur de Hugging Face, avec cette réflexion : Je viens seulement d'apprendre aujourd'hui que des modèles open source pouvaient être utilisés dans Codex.

Certains internautes ont salué cela comme potentiellement la fois la plus « ouverte » de l'histoire d'OpenAI, un événement considérable.

La communauté a été encore plus rapide dans ses actions.
À peine la documentation officielle publiée, des développeurs ont immédiatement tenté d'intégrer certains modèles open source et ont même commencé à discuter de solutions hybrides plus économes en tokens.
Mais certains se sont rapidement heurtés à des obstacles.
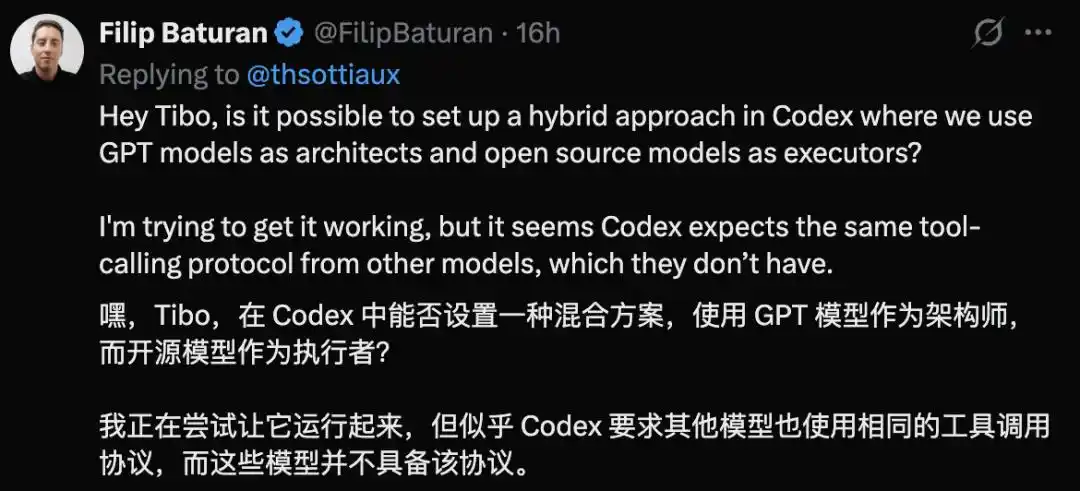
Le développeur Filip Baturan a voulu créer un système hybride dans Codex : utiliser GPT pour la planification, puis un modèle open source comme exécutant.
Cependant, après avoir testé, il a constaté que Codex exige que les modèles connectés utilisent le même protocole d'appel d'outils, ce qui n'est pas forcément le cas des modèles open source.
D'un côté, des acclamations pour la « plus grande ouverture de l'histoire », de l'autre, des protocoles incompatibles.
Cette fois, jusqu'où va l'ouverture d'OpenAI ?
Comment les modèles open source sont-ils intégrés à Codex ?
Cette ouverture de Codex par OpenAI ne concerne pas essentiellement l'ouverture des modèles eux-mêmes, mais l'ouverture de la « couche d'accès aux modèles ».
Autrement dit, elle n'ouvre pas le modèle GPT, mais ajoute à Codex une « couche d'interface de modèle amovible ».
Cette capacité est réalisée par une configuration appelée fournisseurs de modèles (model_providers).
Les développeurs peuvent enregistrer plusieurs « fournisseurs de modèles » dans le fichier de configuration, chacun contenant quatre types d'informations :
L'adresse d'accès (base_url), le protocole de communication (wire_api), la méthode d'authentification (env_key), et la correspondance des modèles (model).
Au démarrage, Codex sélectionne le fournisseur de modèles correspondant en fonction de la configuration, acheminant ainsi les requêtes vers différents services de modèles, y compris les modèles propres à OpenAI, les modèles Ollama locaux ou des API tierces comme DeepSeek.
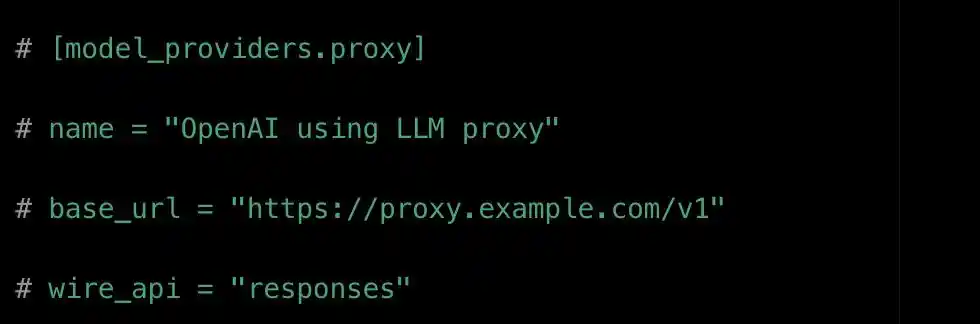
Exemple de configuration model_providers de Codex. base_url est l'adresse du modèle, tandis que le champ de protocole wire_api n'accepte qu'une seule valeur : responses.
Mistral, les proxys créés par les entreprises, les relais tiers, peuvent tous être intégrés à Codex de cette manière.
Un internaute a résumé les points forts de cette capacité ainsi : ne pas être lié à un seul fournisseur, basculer selon les besoins, la confidentialité et les coûts dépendent de vous.
Encore plus pratique, vous pouvez enregistrer tous ces paramètres en tant que « profil de configuration », et lors du débogage, il suffit de cliquer sur son nom dans la ligne de commande pour basculer vers celui que vous souhaitez utiliser.
Par rapport à la configuration manuelle ci-dessus, il existe un interrupteur plus direct : --oss. Avec ce paramètre, Codex se connecte directement aux services de modèles open source locaux.
Par défaut, il y en a deux : Ollama et LM Studio. Le premier est l'outil le plus populaire pour exécuter des grands modèles en local, le second est une alternative de bureau avec interface graphique.
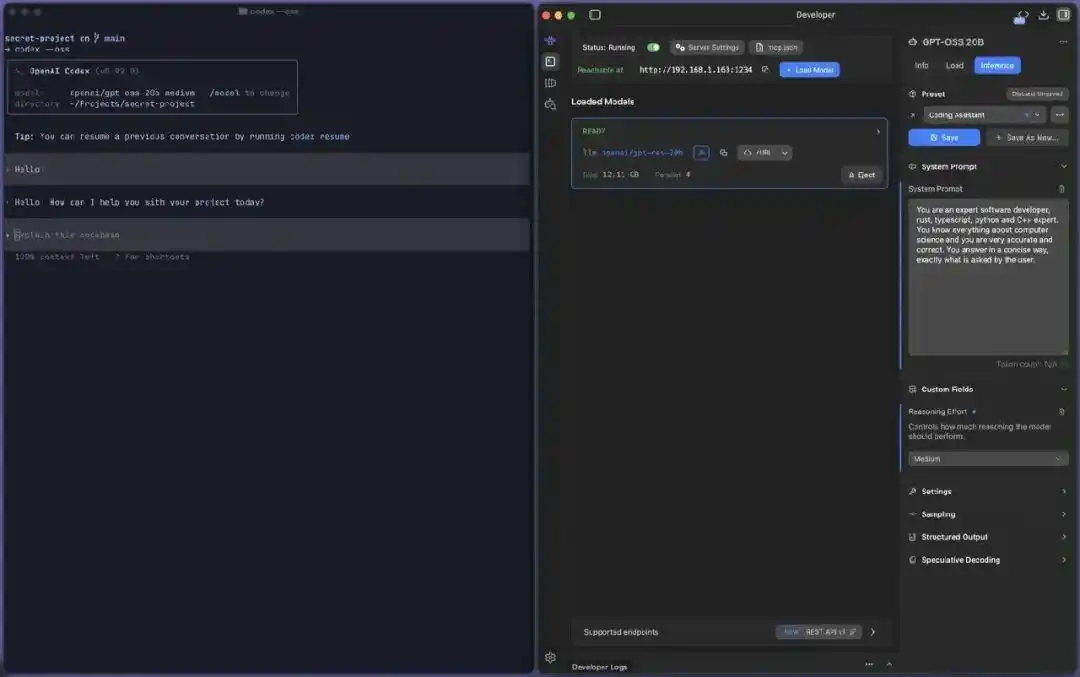
Capture d'écran pratique de Codex --oss connecté à un modèle local : à gauche, Codex CLI (v0.92.0) utilise --oss pour appeler le modèle local ; à droite, LM Studio charge openai/gpt-oss-20b (12.11 GB) sur le port local 1234 et fournit un service, tout en local et hors ligne.
Cela signifie qu'en configurant les services de modèles locaux et les autorisations réseau, vous pouvez permettre à Codex d'effectuer la génération de code et le raisonnement sur votre machine, réalisant ainsi, dans une certaine mesure, un fonctionnement hors ligne et un traitement local.
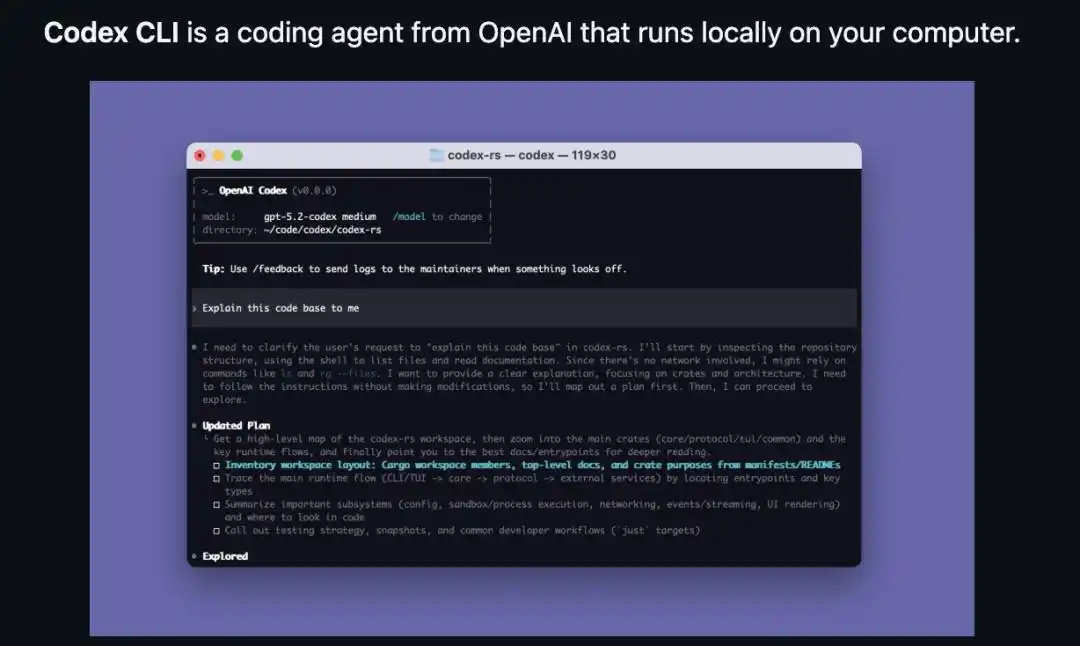
Interface CLI de Codex : Dans les informations de démarrage, la ligne model indique le modèle actuel (gpt-5.2-codex), suivie de « /model to change ». Une simple commande permet de changer de modèle, et l'agent intelligent fonctionne entièrement sur la machine locale.
Cependant, l'installation d'une prise ne signifie pas que tout appareil électrique branché fonctionnera.
Les modèles connectés doivent généralement être compatibles avec le format d'interface des complétions de dialogue (Chat Completions) ; quant à des capacités plus complexes comme l'appel d'outils (function calling), l'entreprise ne garantit pas qu'elles fonctionnent complètement, il faut les tester un par un.
Précisément parce que les protocoles ne correspondent souvent pas, la communauté doit encore écrire elle-même des outils de routage pour effectuer la traduction au milieu, et toutes ces solutions sont actuellement explorées par la communauté, OpenAI ne les a pas encore officiellement validées.
Mélange de GPT et de modèles open source
Travailler ensemble dans Codex
Alors qu'OpenAI venait tout juste d'ouvrir une brèche, la communauté s'était déjà mise à s'amuser avec enthousiasme.
La raison est simple : Codex est pratique, mais utiliser les modèles d'OpenAI avec une facturation au token est trop cher.
C'est pourquoi de nombreux développeurs se tournent vers les modèles open source.
DeepSeek est l'un des modèles open source les plus familiers pour de nombreux développeurs chinois. Une question naturelle se pose : Codex peut-il utiliser directement DeepSeek ?
La réponse de CC Switch est : oui, mais pas directement, il faut une couche « intermédiaire » supplémentaire.
Tutoriel de la communauté CC Switch : « Exécuter DeepSeek avec un routage local dans Codex »
Son tutoriel communautaire « Exécuter DeepSeek avec un routage local dans Codex » indique que la raison en est que la nouvelle version de Codex est principalement basée sur l'API Responses d'OpenAI, tandis que DeepSeek et la plupart des interfaces de modèles open source restent principalement basées sur Chat Completions.
Ces deux ensembles d'interfaces ne sont pas entièrement cohérents en termes de structure de requête, de méthode de sortie en flux, et de mécanisme d'appel d'outils.
Par conséquent, si vous entrez directement l'adresse de DeepSeek dans Codex, cela ne fonctionnera pas correctement. Les cas courants sont une incompatibilité des paramètres de requête ou des résultats renvoyés impossibles à analyser, entraînant un échec de l'appel ou une sortie anormale, et pas simplement un « échec de connexion ».
La solution de la communauté est d'ajouter une couche de « routage » local ou de « convertisseur de protocole » au milieu.
Le processus de base est le suivant :
1. Codex envoie une requête selon l'API Responses ;
2. La couche de routage la convertit au format Chat Completions ;
3. La transmet à des modèles open source comme DeepSeek ;
4. Reconvertisse les résultats renvoyés au format Responses que Codex peut reconnaître.
Des capacités similaires ne sont pas fournies uniquement par CC Switch.
LiteLLM, claude-code-router, ainsi que divers services proxy créés par des développeurs, résolvent essentiellement le même problème : permettre à différents modèles d'interagir via une norme d'interface unifiée.
Cette fois, OpenAI a ouvert une porte, mais pour une mise en œuvre réelle, la communauté doit encore « ajouter des briques et des tuiles » elle-même.
Derrière tout cela, il y a une pratique de jeu de routage hybride.
Par exemple, laisser GPT s'occuper de la planification : décomposer les tâches, concevoir l'architecture, comprendre ce qu'il faut faire. Laisser les modèles open source s'occuper de l'exécution : transformer le plan en code exécutable, modifier des fichiers en masse.
Avec un tel mélange, pour la même tâche, le coût peut être réduit de plus de moitié.
En plus d'être plus économique, en configurant Codex avec des modèles open source locaux, pas une seule ligne de code ne quitte votre propre ordinateur.
Pour les développeurs individuels qui ne veulent pas télécharger leurs projets privés sur le cloud et ne veulent pas non plus payer continuellement pour une API, cette tentation n'est pas du tout petite.
La guerre des modèles est terminée
La guerre des interfaces a commencé
Ces dernières années, tout le monde pensait que la barrière était le modèle. Celui qui avait le plus de paramètres, les meilleurs scores aux benchmarks, les réponses les plus intelligentes, gagnait.
Mais cette fois, OpenAI a transformé cette couche de Codex en une interface amovible, et sa valeur commence également à se déplacer vers l'entrée de l'écosystème.
Le calcul d'OpenAI est probablement de passer d'un vendeur de modèles à un joueur vendant une plateforme et un cadre : changez de modèle comme vous voulez, mais l'outil doit être le mien.
Celui qui occupe l'entrée que les développeurs ouvrent chaque jour, détient la distribution et s'assoit au cœur de l'écosystème.
Ce n'est pas la première fois qu'OpenAI déploie des stratégies dans l'écosystème open source.
Bien qu'elle n'ait pas publié de grand modèle de langage à poids ouvert depuis GPT-2 en 2019, face au développement rapide de l'écosystème open source (comme les modèles Llama, DeepSeek, etc.), elle a tout de même relancé la série de modèles à poids ouvert gpt-oss en août 2025.

Ces modèles ont ensuite été rapidement intégrés et pris en charge par la chaîne d'outils de la communauté (comme Ollama, LM Studio, etc.), qui sont précisément ceux que Codex --oss connecte et supporte par défaut aujourd'hui.
Au niveau de la configuration, OpenAI a effectivement ouvert la capacité d'intégration des modèles, permettant l'intégration de modèles tiers via une couche d'abstraction des fournisseurs de modèles, mais tous les modèles ne peuvent pas être utilisés directement ; ils doivent être conformes à son protocole d'interface ou passer par une couche d'adaptation pour conversion.
Au niveau du protocole, elle conserve une contrainte clé : utiliser l'API Responses comme norme d'interaction principale, tout en permettant, via une couche de compatibilité, de supporter d'autres interfaces de modèles comme Chat Completions.
Cela signifie que quel que soit le modèle intégré, il doit s'aligner sur la structure de requête et de réponse définie par OpenAI ; ce qu'elle veut finalement, c'est garder la norme d'interface entre ses mains.
Sous cet angle, cette couche de protocole d'interface, autrefois facilement négligée, devient un nouveau point de concurrence.
Peut-être qu'OpenAI souhaite cette fois, avec un simple interrupteur de configuration apparemment insignifiant, déclencher une guerre pour l'entrée de la programmation IA, ce qui signifie que sa prochaine confrontation avec Anthropic ne se situera plus au niveau des modèles.
Pour les développeurs qui ouvrent Codex chaque jour, c'est un avantage concret : pouvoir exécuter des modèles open source, économiser des tokens, et travailler localement et hors ligne.
Mais plus on l'utilise avec aisance, plus on l'utilise en profondeur, plus on devient dépendant de cette entrée.
Références :
https://x.com/thsottiaux/status/2067181377028538431
https://developers.openai.com/codex/config-advanced#oss-mode-local-providers
https://www.ccswitch.io/en/tutorials/codex-deepseek-routing-guide
Cet article provient du compte WeChat public « Nouvelle Intelligence Artificielle », auteur : Révélation de l'ASI, éditeur : Yuanyu