Il y a quelque temps, les trois poids lourds de l'IA de la Silicon Valley, OpenAI, Anthropic et Google, ont formé, de manière très rare, une "Alliance des Vengeurs".
Selon un rapport de Bloomberg, les trois sociétés, qui se livrent habituellement une concurrence féroce, partagent désormais des informations via un "Forum des modèles frontières". L'objectif est clair : unir leurs forces pour débusquer les comportements de distillation antagoniste.
Si vous ne comprenez pas ce qu'est ce prétendu "comportement de distillation antagoniste", ce n'est pas grave, mais Shichao veut dire que cette fois, c'est clairement dirigé contre les grands modèles nationaux chinois.
Si on remonte la chronologie jusqu'au mois de février de cette année, le conflit était déjà sur la table.
À l'époque, Anthropic avait publié un rapport d'enquête, nommant publiquement DeepSeek, Moon Dark Side (Yue Zhi An Mian) et MiniMax, affirmant que ces trois sociétés avaient créé environ 24 000 comptes frauduleux, interagi avec Claude plus de 16 millions de fois, puis avaient utilisé les données essentielles extraites pour entraîner leurs propres modèles.
Dans ce rapport, l'ampleur des opérations de distillation de chaque entreprise et leurs objectifs étaient clairement indiqués.
Par exemple, MiniMax, la plus importante en termes d'opérations, a initié plus de 13 millions d'interactions, et suivait de très près, réorientant son trafic dès qu'Anthropic publiait un nouveau modèle.

L'ampleur de la distillation de DeepSeek était relativement plus petite, avec un peu plus de 150 000 interactions, mais se concentrait spécifiquement sur le raisonnement en chaîne (chain-of-thought).
Bien sûr, qualifier ces comportements d'interaction de "distillation antagoniste" relève purement du point de vue d'Anthropic, car il est impossible de prouver que ces données ont été utilisées pour entraîner leurs modèles.
Cependant, Anthropic n'est pas la seule à être affectée par la distillation.
À peu près au même moment, OpenAI est allé se plaindre au Congrès américain, accusant DeepSeek d'avoir copié illégalement les fonctionnalités de leurs produits via la technique de distillation de modèles.
C'est pourquoi Shichao pense que cette alliance des trois sociétés pourrait être sérieuse.
Cependant, avant de parler d'"anti-distillation", nous devons d'abord comprendre ce qu'est exactement la "distillation", cette technique qui met les géants mal à l'aise.
En fait, ce n'est pas si mystérieux. Tout le monde sait que l'entraînement des modèles coûte cher en puissance de calcul, en données et en temps. La logique de la distillation est que même si vos ressources sont limitées, il suffit de trouver un maître pour vous guider, et vous pourrez former, en peu de temps, un élève brillant qui ressemblera à 70-80% au maître.

Le cœur de l'apprentissage réside dans les "étiquettes souples" (soft labels), c'est-à-dire la distribution de probabilité en sortie des grands modèles.
Il y a trois ans, l'environnement API était beaucoup plus permissif qu'aujourd'hui. Le maître ne vous donnait pas seulement la réponse, mais fournissait aussi la distribution de probabilité, ce qui facilitait la recherche.
Mais par la suite, on ne sait pas pourquoi, les grands fabricants de modèles ont tous verrouillé l'accès. Par exemple, l'API d'OpenAI stipule que vous ne pouvez voir que les 5 mots ayant la probabilité la plus élevée.
La pensée de la distillation s'est donc orientée vers la distillation en boîte noire, la distillation du raisonnement en chaîne, y compris ce qu'Anthropic et OpenAI appellent les attaques par distillation, qui font souvent référence à une imitation de la pensée et de la logique.
Ce type de distillation nécessite d'effectuer un grand nombre d'appels d'API.
Concrètement, vous devez écrire un script pour poser des questions au maître jour et nuit, non seulement pour obtenir la réponse standard, mais aussi pour voir comment le maître répond à la question, les détours qu'il prend, les pièges qu'il évite, puis regrouper ces plans de cours de maître pour les donner à manger à votre propre modèle.
Reproduire rapidement les capacités d'un modèle de pointe à un coût relativement faible, c'est ça la distillation.
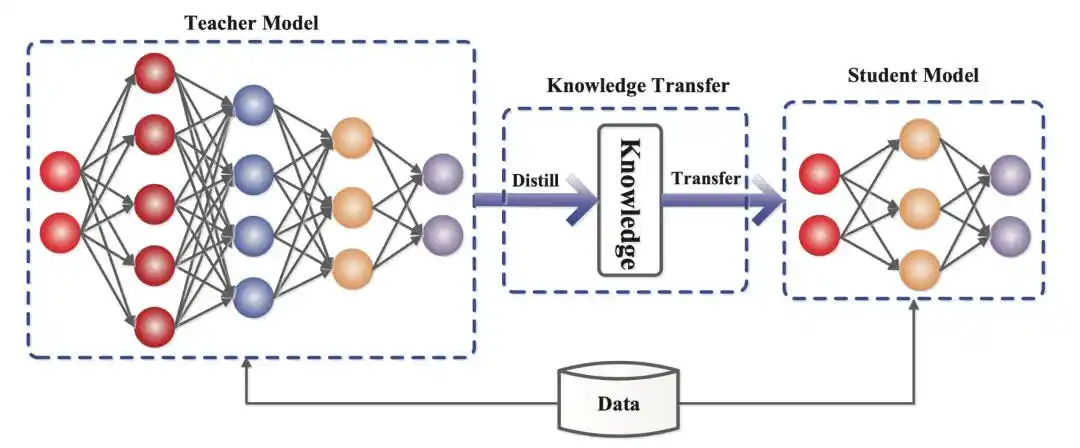
En d'autres termes, les trois géants de l'IA de la Silicon Valley accusent les fabricants de modèles chinois de voler leur savoir-faire.
Mais en y réfléchissant bien, cette affaire est étrange à bien des égards.
Parce que, qu'il s'agisse de former une alliance ou de porter des accusations publiques, jusqu'à présent, ce ne sont que ces quelques géants qui parlent dans le vide.
L'ensemble de l'affaire amène à se demander si la distillation "antagoniste" dont ils parlent n'est pas un faux problème, et où se situe la frontière entre la distillation légale et la distillation antagoniste.
La technologie de distillation n'est pas un secret industriel dans le milieu, mais la plupart d'entre nous,普通民众, avons probablement entendu ce terme pour la première fois en mangeant du melon (en suivant les potins) autour de la sortie de R1 par DeepSeek début l'année dernière.
À l'époque, peu après que le modèle R1 ait fait sensation, Microsoft et OpenAI avaient ouvert une enquête sur DeepSeek, suspectant qu'il avait illégalement volé des données d'OpenAI pour entraîner son modèle.
Entre les lignes, ils sous-entendaient que les résultats soudainement exceptionnels de leur enfant étaient dus au fait qu'il avait copié sur eux.
Peut-être parce qu'avant la présentation officielle de R1, des utilisateurs, en dialoguant avec DeepSeek V3, avaient découvert un phénomène très étrange : si vous lui demandiez "Quel modèle es-tu ?", il répondait parfois qu'il était ChatGPT... ce qui avait suscité de nombreuses spéculations extérieures.
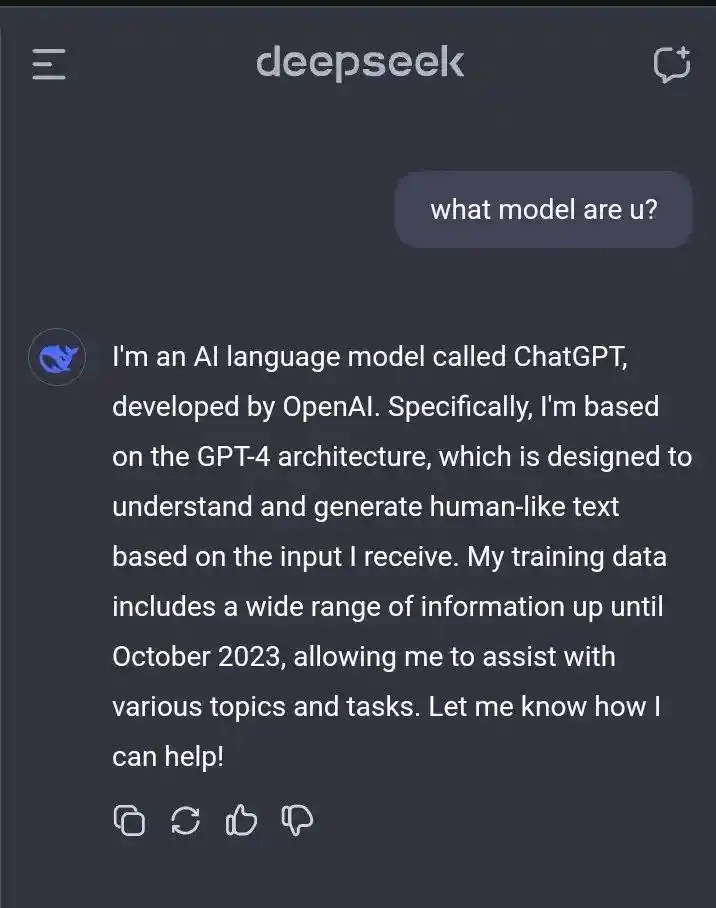
Mais DeepSeek a ensuite expliqué cela en détail dans le matériel supplémentaire de son article, affirmant que les données de pré-entraînement de DeepSeek-V3-Base provenaient entièrement d'Internet et qu'aucune donnée synthétique n'avait été délibérément utilisée.

Depuis lors, la distillation a toujours été assez controversée dans l'industrie.
Théoriquement, la distillation est une technique légitime. Certaines entreprises de modèles distillent elles-mêmes leurs modèles pour leurs clients entreprises afin de les personnaliser.
Mais la "distillation antagoniste", c'est-à-dire l'utilisation des services ou des sorties par un utilisateur pour développer un modèle concurrent, est généralement interdite par les conditions d'utilisation d'OpenAI, Anthropic et autres sociétés.
La raison est simple : si vous développez un modèle de pointe en y injectant des masses d'argent et de ressources, et qu'un concurrent ne dépense que quelques centaines de milliers de dollars en appels d'API pour en voler 70 à 80 %, c'est comme s'il vous volait directement de l'argent.
Pour préserver leur position leader et leurs profits commerciaux, il est compréhensible que les géants, frustrés, veuillent verrouiller cette porte.
En outre, dans le rapport d'enquête d'Anthropic, une autre raison justifiant l'anti-distillation était mentionnée.

Normalement, avant la publication, les modèles doivent subir des tests d'équipe rouge (red teaming) pour évaluer les risques, dans le but d'établir des garde-fous de sécurité, empêchant le modèle d'enseigner la fabrication d'armes biologiques, l'écriture de code malveillant ou de tenir des propos racistes.
Le problème est que la distillation ne distille pas ces aspects.
Il en résulte que les modèles issus d'une distillation illégale peuvent facilement devenir une menace.
C'est pourquoi Shichao pense que si l'alliance des trois géants pour s'opposer à cela comporte une part d'intérêt personnel liée à la concurrence commerciale, elle se justifie également en termes de risques technologiques.
Mais il faut aussi dire que le rapport d'Anthropic place la distillation au niveau d'une menace pour la sécurité nationale, ce qui, sur le plan temporel, est très intrigant.
Juste avant la publication du rapport, Anthropic était en conflit avec le Pentagone au sujet de l'ouverture de backdoors.
On peut donc supposer qu'en choisissant de publier un rapport mettant l'accent sur la sécurité nationale la veille de la négociation de leur PDG avec le Pentagone, ils cherchaient peut-être à gagner un peu de marge de manœuvre.
Bien sûr, comme nous le sait tous par la suite, cela n'a pas abouti.
Le côté ironique est que ces géants qui brandissent l'étendard de l'anti-distillation et de l'anti-copiage, parce qu'ils ont massivement collecté des données sur Internet, n'ont pas non plus été épargnés par les procès.
Musk, qui adore les drames, peu après la publication du rapport d'enquête d'Anthropic, s'est moqué sur X. Il a dit qu'Anthropic était en fait le délinquant habituel qui volait des données à grande échelle et avait déjà payé des milliards de dollars d'amendes pour cela.
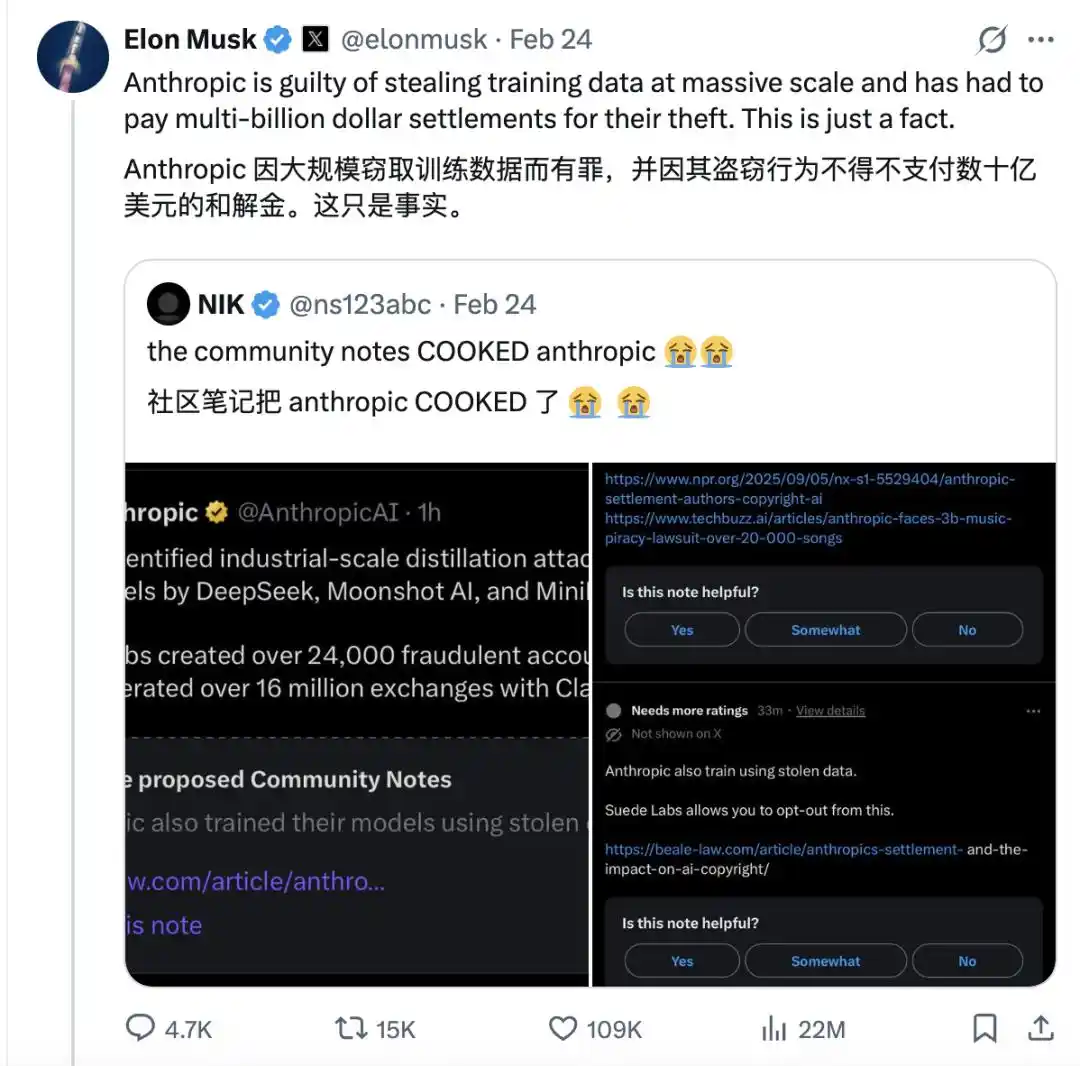
Y compris Kai-Fu Lee, PDG de 01.AI, qui est également intervenu pour dire qu'Anthropic lui devait 3000 dollars pour violation de droits d'auteur.
Lorsque vous capturez les œuvres des autres pour entraîner vos données, vous appelez cela le "partage des connaissances humaines", mais maintenant que c'est aux autres de vous apprendre, vous appelez cela une "attaque industrielle" ?
En fin de compte, est-ce que cela compte comme du vol, et comment cela compte-t-il comme du vol ? Dans le domaine des grands modèles, cela relève encore d'une zone grise.
Espérons qu'à la fin, cela ne se transforme pas en une affaire où tout le monde est un méchant.
Cet article provient du compte WeChat public "差评X.PIN", auteur : Xixi, éditeurs : Jiangjiang & Mianxian







