Par | Lettres AI
À chaque publication d'un modèle de pointe, la communauté de l'IA fixe quelques bulletins de notes familiers.
MMLU-Pro, MMMU, MMMU-Pro… Ces noms peuvent paraître étrangers aux utilisateurs ordinaires, mais pour les entreprises de modèles et les chercheurs, ils sont presque devenus des « matières standard ». GPT, Claude, Gemini, Llama, Qwen, DeepSeek et d'autres rendent constamment leurs copies sur ces référentiels.
« C'est à l'épreuve qu'on juge un cheval ou un âne », la performance des modèles repose souvent sur ces scores pour être prouvée.
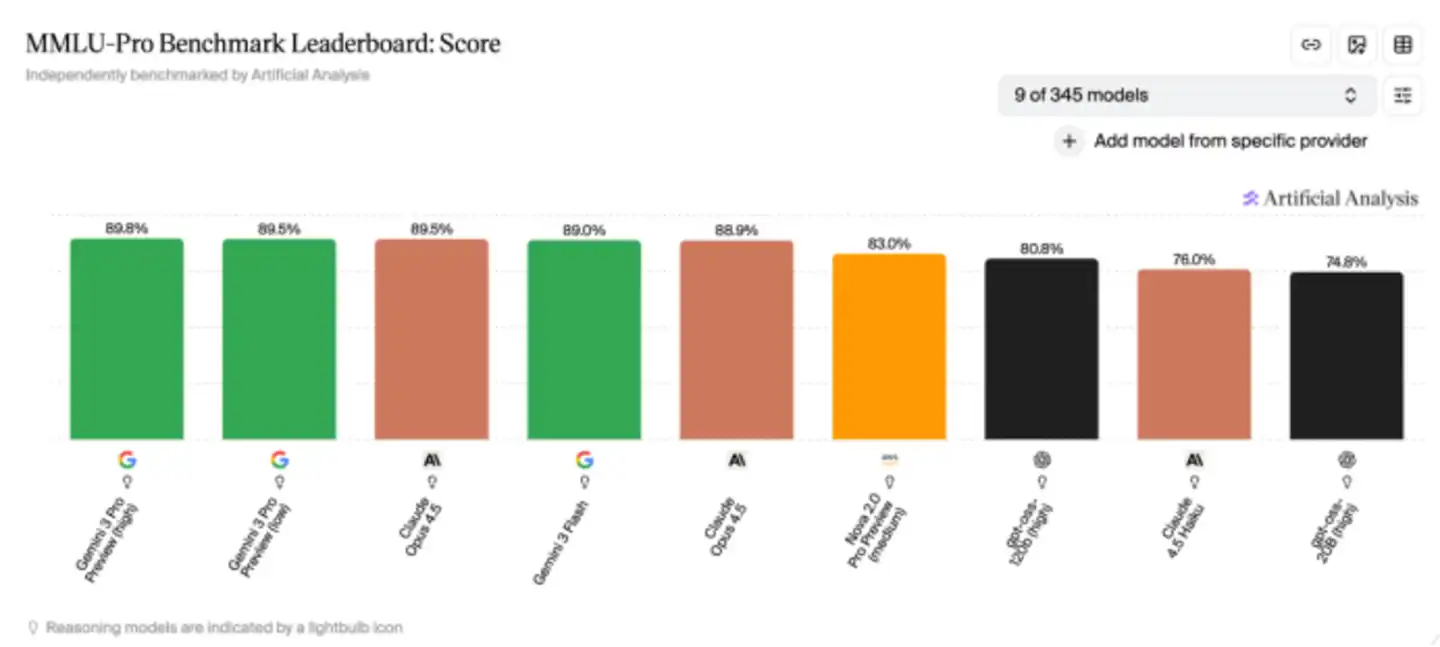
Beaucoup de graphiques comparatifs de performance lors des lancements de modèles dépendent d'eux ; certains classements sur HuggingFace sont également construits sur ces systèmes d'évaluation. On pourrait même dire que lorsque l'industrie de l'IA discute des capacités des modèles aujourd'hui, elle utilise déjà un langage commun défini par ces référentiels.
Mais il est intéressant de noter que presque tout le monde se focalise sur les scores, mais peu de gens savent qui sont les examinateurs. Et derrière MMLU-Pro, MMMU et MMMU-Pro, on peut voir le même nom – Chen Wenhu.
Il est professeur assistant au Département d'informatique de l'Université de Waterloo au Canada. Sur Google Scholar, ses articles ont été cités plus de 30 000 fois.
Il est également le fondateur du « TIGERLab (TIGER Lab) », dont le nom complet en anglais est Text and Image GEnerative Research Lab. Comme le nom contient un caractère «虎» (tigre), Chen Wenhu lui a donné un nom chinois très reconnaissable – 虎头帮 (Hu Tou Bang, la Bande à la Tête de Tigre).
Après la panne de l'ancien examen
Chen Wenhu a d'abord été remarqué par plus de monde grâce à MMLU-Pro.
Le MMLU était autrefois l'un des référentiels d'évaluation les plus couramment utilisés pour juger les capacités des grands modèles de langage. Il ressemble à un examen général, couvrant plusieurs disciplines, utilisé pour mesurer les performances du modèle dans les tâches de compréhension des connaissances et de raisonnement.
Au début, cet examen était très utile. Les écarts entre modèles pouvaient être distingués par les scores, et l'industrie pouvait également l'utiliser pour observer si les grands modèles de langage progressaient vraiment.
Mais le problème est vite apparu.
Avec l'amélioration continue des capacités des modèles, le MMLU est progressivement devenu « trop facile ». Les scores des modèles de pointe sont devenus de plus en plus élevés, les écarts entre eux de plus en plus faibles.
Avec la sortie de l'o3 par OpenAI, ce problème est devenu encore plus évident. La précision de l'o3 sur le MMLU approchait déjà les 100%, et d'autres modèles de pointe ont également rendu des scores proches du maximum.
Cela peut sembler être une bonne nouvelle, mais pour l'évaluation, cela signifie au contraire un problème.
Si tout le monde peut obtenir une note proche du maximum sur un examen, il devient difficile de continuer à juger qui est plus fort, et en quoi. Il peut encore prouver que le modèle possède certaines capacités, mais il n'est plus adapté pour mesurer de nouveaux progrès.
L'industrie de l'IA avait besoin d'un examen plus difficile, et moins facile à « bachoter ».
En 2024, Chen Wenhu et son équipe ont lancé le MMLU-Pro.
Le MMLU-Pro a repensé cet examen, plutôt que de simplement agrandir la base de questions.
Il contient 12032 questions, couvrant 14 domaines comme les mathématiques, la physique, la chimie, le droit, l'ingénierie, la psychologie, la santé, etc. Par rapport à la version originale du MMLU, il étend les choix de 4 à 10, réduisant la probabilité que le modèle devine la bonne réponse ; il inclut également plus de questions de raisonnement, et élimine celles relativement simples, ambiguës ou manquant de pouvoir discriminant de l'ancienne base.
L'effet est direct.
Les résultats du document de recherche montrent que la précision des modèles sur le MMLU-Pro a chuté de 16% à 33% par rapport à la version originale du MMLU. Lorsqu'un même modèle est testé avec 24 styles d'instructions différents, la fluctuation des scores est également passée de 4% à 5% pour le MMLU original, à environ 2%.
C'est-à-dire que ce nouvel examen est non seulement plus difficile, mais aussi plus stable.
Il a permis de rétablir un écart entre les modèles qui semblaient tous excellents sur l'ancien examen. Il est ainsi plus facile de voir si un modèle sait vraiment raisonner, ou s'il est simplement plus doué pour traiter les anciennes questions.
Des référentiels d'évaluation utiles
Le MMLU-Pro a rapidement été adopté par l'industrie.
Il a ensuite été intégré à la piste « Datasets and Benchmarks » du NeurIPS 2024, et également intégré au cadre d'évaluation des modèles de langage lm-evaluation-harness d'EleutherAI. Pour la communauté des modèles open source, cela signifie qu'il n'est plus seulement un ensemble de données dans un article de recherche, mais qu'il est entré dans la chaîne d'outils d'évaluation courante.
De nombreux modèles ont commencé à rapporter leur score MMLU-Pro lors de leur publication. Certains classements sur HuggingFace l'ont également intégré dans leur système d'évaluation.
Si le MMLU-Pro résout le problème de « l'ancien examen défaillant » dans l'évaluation des modèles de langage, alors le MMMU a propulsé Chen Wenhu et TIGERLab au centre de l'évaluation multimodale.
Les problèmes des modèles multimodaux sont plus complexes.
Un modèle de langage répondant à une question traite principalement du texte. Un modèle multimodal doit simultanément traiter des images, des graphiques, des schémas, des cartes, des tableaux, des partitions de musique, des structures chimiques et d'autres formes d'informations. Il ne s'agit pas seulement de comprendre l'énoncé, mais aussi de véritablement comprendre le contenu de l'image, et de raisonner en combinant les informations visuelles, les informations textuelles et les connaissances disciplinaires.
Le référentiel d'évaluation MMMU contient 11 500 questions multimodales, issues d'examens universitaires, de tests et de manuels, couvrant six grands domaines : arts et design, affaires, sciences, santé et médecine, sciences humaines et sociales, technologie et ingénierie, subdivisés en 30 disciplines et 183 sous-domaines.
Ces questions ne demandent pas simplement au modèle « ce qu'il y a dans l'image » ; elles exigent du modèle qu'il combine les informations visuelles et les connaissances disciplinaires, comme un étudiant résoudrait un problème spécialisé.
Lors du lancement du MMMU, l'équipe de recherche a testé 14 modèles multimodaux open source, ainsi que des modèles propriétaires représentatifs comme GPT-4V et GeminiUltra. Même les modèles propriétaires les plus performants de l'époque, GPT-4V et GeminiUltra, n'ont atteint que des précisions de 56% et 59%.
Ces chiffres indiquent que, bien que les modèles multimodaux semblent progresser rapidement, ils ont encore beaucoup de chemin à parcourir face à des problèmes nécessitant une véritable compréhension et un raisonnement spécialisé.
Plus tard, l'équipe de Chen Wenhu a également lancé le MMMU-Pro, pour combler davantage les possibilités pour les modèles de contourner les informations visuelles. Il filtre les questions pouvant être répondues par un modèle textuel seul, élargit les options de réponse, et introduit un paramètre « vision-only », intégrant la question dans l'image, exigeant que le modèle accomplisse simultanément la lecture visuelle et la compréhension textuelle.
En termes simples, il empêche le modèle de « deviner la réponse en ne lisant que le texte ».
Ce genre de travail peut sembler quelque peu fastidieux, mais il est crucial. Parce que les modèles multimodaux à l'avenir devront pénétrer des scénarios comme la santé, l'éducation, la recherche scientifique, la conception, l'ingénierie, etc., et il ne suffira pas de décrire une image. Ils devront pouvoir juger, raisonner, expliquer, et être capables de trouver la partie vraiment utile dans des informations visuelles complexes.
La personne derrière l'« examen »
Le travail ultérieur de Chen Wenhu sur MMLU-Pro et MMMU découle de sa direction de recherche de longue date.

Son intérêt de recherche est lié à la compréhension d'informations complexes, aux questions-réponses basées sur la connaissance et au raisonnement.
Il a obtenu son diplôme de licence à l'Université des sciences et technologies de Huazhong, puis a poursuivi un master à l'Université RWTH d'Aix-la-Chapelle en Allemagne, avant d'obtenir un doctorat en informatique à l'Université de Californie à Santa Barbara. Pendant son doctorat, il avait déjà commencé des recherches sur des directions telles que les questions-réponses complexes, le raisonnement sur tableaux, la localisation de preuves de connaissances, etc.
Ce type de tâches a un point commun : la réponse n'est souvent pas dans un seul texte.
Elle peut être cachée dans un tableau, ou nécessiter de combiner un paragraphe de texte et une image, ou encore nécessiter que le modèle recherche d'abord des informations, puis les intègre, calcule et raisonne. Le modèle ne peut pas se contenter de répéter des connaissances existantes.
Les projets auxquels Chen Wenhu a participé, comme HybridQA, TabFact, ProgramofThoughts, MAmmoTH, sont tous liés à cette lignée.
Cela explique aussi pourquoi il est sensible aux failles dans l'évaluation des modèles.
Un bon référentiel d'évaluation ne consiste pas simplement à rendre les questions de plus en plus difficiles, mais à anticiper où le modèle est le plus susceptible de « deviner la réponse » ou de « sembler savoir ».
Le modèle peut avoir mémorisé la base de questions, ou deviner grâce aux choix, ou encore utiliser du texte pour contourner les informations visuelles… Une bonne évaluation doit combler ces failles.
Après son doctorat, Chen Wenhu est entré chez Google Research, puis a participé de 2021 à 2025 aux travaux sur le modèle multimodal Gemini et sur l'évaluation chez Google DeepMind. Cette expérience est également importante. L'exposition prolongée au développement de modèles de pointe lui a permis de mieux comprendre comment les capacités des modèles se développent, et de voir plus facilement les biais et angles morts potentiels dans l'évaluation.
À l'automne 2022, Chen Wenhu a rejoint la Faculté d'informatique de l'Université de Waterloo en tant que professeur assistant. La même année, il a été sélectionné comme titulaire d'une Chaire IA Canada CIFAR. Par la suite, il a fondé le « TIGERLab (虎头帮) » et a poursuivi ses recherches sur les modèles de base, les capacités multimodales et les référentiels d'évaluation.

虎头帮 ne se contente pas de faire des référentiels d'évaluation, il fait également de la recherche sur les modèles et les systèmes.
Dans le domaine de la vidéo, UniVideo tente de placer la compréhension, la génération et l'édition vidéo dans un même cadre, permettant au modèle non seulement de générer une séquence, mais aussi de comprendre le contenu, de répondre aux instructions et d'effectuer des modifications. Vamba vise la compréhension de longues vidéos, en résolvant les problèmes de mémoire, de calcul et d'efficacité d'entraînement posés par des vidéos d'une heure. MoCha, développé en collaboration avec l'équipe Générative AI de Meta, se concentre sur la génération de personnages virtuels parlants, en générant des vidéos de haute qualité de personnages à partir de descriptions audio et textuelles.
Un examinateur qui ne s'est jamais assis à un examen ne peut pas créer un bon examen. Le fait de développer soi-même des modèles les rend, en retour, plus aptes à évaluer.
Parce qu'une véritable bonne évaluation provient souvent de la compréhension des limites des capacités des modèles. Ce n'est qu'en sachant comment un modèle est construit, en connaissant les problèmes qu'il rencontre dans des tâches réelles, qu'il est plus facile de concevoir des questions capables de mesurer les écarts et de révéler les problèmes.
Aujourd'hui, Chen Wenhu a rejoint le laboratoire de super-intelligence de Meta, où son travail continue de se concentrer sur les données d'entraînement préalable multimodales et sur l'évaluation, au service des modèles de base de Meta.
L'industrie de l'IA ne manque pas de personnes visibles. Dans l'industrie de l'IA, les projecteurs se braquent généralement sur les entrepreneurs, les chercheurs stars et les responsables des grandes entreprises de modèles. Les lancements de nouveaux produits, les annonces de financement, les modèles open source et les réorganisations d'équipes attirent souvent le plus l'attention extérieure, et rendent ces noms plus visibles pour le public.
Mais dans le domaine de l'IA d'aujourd'hui, la participation des talents chinois va bien au-delà de ces positions les plus en vue.






