Par | Alter
Le matin du 24 avril, DeepSeek V4, longtemps attendu, a finalement dévoilé son vrai visage.
Ce jour-là, DeepSeek-V4-Pro a immédiatement atteint la première place du classement des modèles open source de Hugging Face, et deux « innovations nucléaires » ont été largement saluées :
Premièrement, un contexte ultra-long d'un million de tokens, mais avec une consommation de KV cache seulement 10% de celle de V3.2, ce qu'un ingénieur d'Amazon a vivement salué comme une solution au problème de pénurie de HBM ;
Deuxièmement, l'adaptation aux puces chinoises, avec une collaboration étroite avec Huawei pendant le développement et une adaptation immédiate aux puces chinoises telles que Ascend et Cambricon.
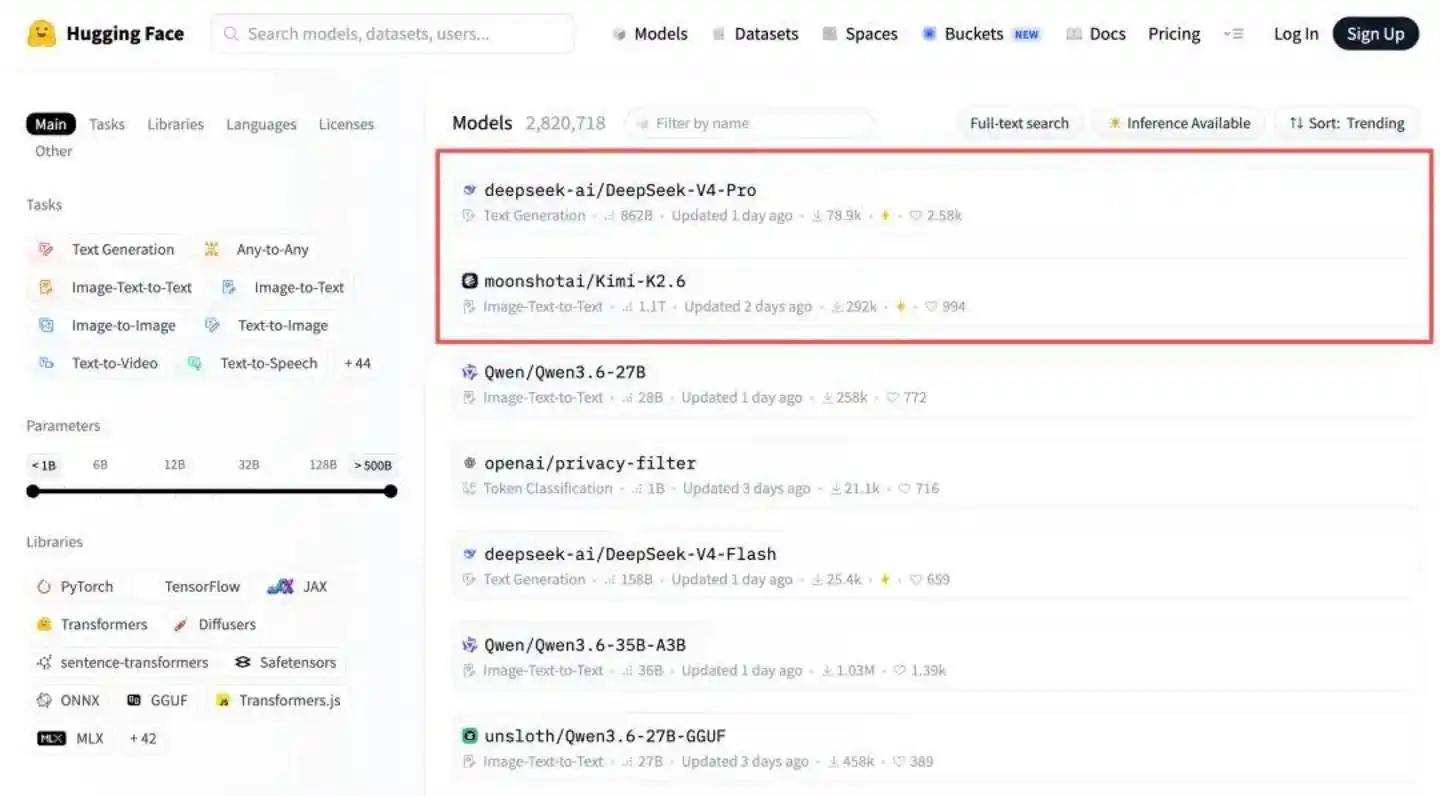
Coïncidence, le modèle classé deuxième sur le leaderboard des modèles open source de Hugging Face est justement Kimi K2.6, publié et open source dans la nuit du 20 avril.
Si cela s'était passé de l'autre côté du Pacifique, la « collision » de deux modèles à billions de paramètres n'aurait pas manqué de donner lieu à des attaques mutuelles pour la valorisation et les parts de marché, mais en Chine, la scène a été totalement différente : pas de révélations mutuelles, pas de guerre des relations publiques sournoise, et même une « permutation » au niveau technique sous-jacent.
Derrière cette « situation inhabituelle » se cache une divergence dans les approches technologiques de l'IA entre la Chine et les États-Unis : La Silicon Valley est en train d'« ériger frénétiquement de hauts murs », tentant de préserver ses intérêts acquis par le closed-source ; les fabricants chinois de grands modèles ont quant à eux choisi de « démanteler les murs », évoluant vers une coévolution sur le terrain open source.
01 La Silicon Valley plongée dans le « Jeu des Trônes »
Contrairement à l'approche open source diversifiée des grands modèles chinois, les têtes d'affiche de l'IA de la Silicon Valley, représentées par OpenAI, Anthropic et Google Gemini, sont toutes des adeptes du closed-source.
Lorsque les innovations technologiques de pointe sont enfermées dans leurs propres data centers, face à la pression des coûts de calcul et aux attentes des marchés financiers, l'« esprit de la Silicon Valley », autrefois connu pour son ouverture et sa collaboration, s'efface progressivement, et les acteurs tombent inévitablement dans un « jeu de pouvoir » à somme nulle.
Au cours des deux dernières années, la « guerre froide » technologique s'est transformée en affrontements publics ouverts, le moyen le plus typique étant de se « voler la vedette » mutuellement : Lancer rapidement des mises à jour fracassantes de son propre produit au moment crucial où un concurrent publie un nouveau produit pour étouffer sa visibilité est devenu une opération courante dans la Silicon Valley.
Dès mai 2024, OpenAI et Google avaient simultanément publié de nouveaux produits d'IA, l'un disant que GPT-4o était leader mondial, l'autre que la famille Gemini couvrait tous les écosystèmes et chemins. Finalement, les PDG des deux entreprises n'ont pas pu s'empêcher de se moquer ouvertement l'un de l'autre sur les réseaux sociaux.
Pas seulement des « luttes » avec Google, la rivalité entre OpenAI et Anthropic est également devenue acharnée : le 16 avril, à peine plus de deux heures après qu'Anthropic ait publié son nouveau modèle Claude Opus 4.7, OpenAI a annoncé une mise à jour majeure de Codex, lançant le slogan « Codex for (almost) everything ». Il était évident pour tous que cette coïncidence de timing n'était pas un hasard, mais bien une « embuscade » soigneusement planifiée par OpenAI contre Anthropic.
Outre les « combats littéraires » sur la scène médiatique, les « combats physiques » consistant à se « dévoiler mutuellement » sont également devenus monnaie courante dans la Silicon Valley.
Anthropic a annoncé en grande pompe le 7 avril avoir atteint un chiffre d'affaires annualisé de 300 milliards de dollars, dépassant ainsi les 250 milliards de dollars d'OpenAI.
Une semaine plus tard, le directeur des revenus d'OpenAI a déclaré sans ambages dans une note interne adressée à tous les employés : le chiffre d'affaires annualisé de 300 milliards de dollars annoncé par Anthropic contenait des erreurs importantes, car il utilisait la « méthode brute », incluant dans son chiffre d'affaires total la part reversée aux fournisseurs de services cloud comme Amazon et Google, ce qui avait surestimé le revenu annualisé d'environ 80 milliards de dollars.
Cette pratique consistant à déstabiliser un concurrent dans une communication interne n'est pas courante dans le secteur technologique ; le but était simplement de dire aux investisseurs - le mythe de la croissance d'Anthropic est gonflé.
Et une fois que l'hostilité s'installe, elle influence chaque décision de manière insidieuse.
Après qu'Anthropic se soit « brouillé » avec le Pentagone pour avoir refusé de supprimer certaines clauses de sécurité spécifiques de son contrat, OpenAI a annoncé quelques heures plus tard avoir conclu un partenariat avec le département de la Défense américain.
Lors du « Super Bowl » de 2026, Anthropic a investi massivement dans une publicité dont le message était : « La publicité entre dans le domaine de l'IA, mais n'entrera pas dans Claude. » On peut dire que c'était un « coup direct » à OpenAI, qui commençait tout juste à tester les fonctionnalités publicitaires.......
Pourquoi d'anciens « frères de promo » en sont-ils arrivés à un point d'hostilité irréconciliable ?
La racine réside dans la logique inhérente au modèle commercial closed-source : la base de survie du closed-source est la construction de barrières, et la condition préalable à la construction de barrières est de bloquer la diffusion technologique, monopoliser la productivité la plus avancée. Ajoutez à cela l'incompatibilité des routes technologiques et l'opposition des récits produits, cela forme naturellement un équilibre de Nash : Celui qui « cesse le feu » en premier verra son récit de marque s'effondrer, s'enfonçant finalement plus profondément dans le marasme de la consommation interne.
02 La « coévolution » du camp open source
En reportant notre regard sur la Chine, le scénario est totalement différent.
Remontons à plus d'un an, l'émergence soudaine de DeepSeek-R1 a mis un coup de frein à la course effrénée des startups de grands modèles, les « six petits tigres » des grands modèles en finale étant les premiers touchés. La plus grande différence avec la Silicon Valley est que DeepSeek n'a pas joué le rôle du « requin » mangeant tous les poissons de l'étang, mais plutôt celui d'un poisson-chat qui a activé tout l'écosystème chinois des grands modèles, poussant tout le monde à adopter l'open source.
Un exemple direct est celui de Moonlight (Yue Zhi An Mian), dont la trajectoire de croissance coïncide étroitement avec celle de DeepSeek : toutes deux sont des équipes startups lancées en 2023, toutes deux maintiennent une structure d'équipe extrêmement réduite mais avec une densité de talents très élevée, et toutes deux sont de ferventes adeptes de la loi de Scaling.
En juillet 2025, Moonlight a publié le premier modèle open source au monde avec des billions de paramètres, Kimi K2, déclarant sans ambages dans son rapport technique avoir adopté l'architecture MLA open source de DeepSeek. Pour les grands modèles, le cauchemar du traitement de textes très longs est le mur de la mémoire, et le caractère révolutionnaire de l'architecture MLA réside dans le fait qu'elle compresse astucieusement le KV Cache à un taux impressionnant de plus de 93%.
Grâce à la « norme industrielle » contribuée par DeepSeek, les équipes de grands modèles, y compris Moonlight, n'ont pas eu à réinventer la roue, réduisant rapidement les coûts d'inférence.
L'histoire ne s'arrête pas là.
En parcourant la documentation technique de DeepSeek V4, l'architecture du modèle est décrite en détail, et l'une des mises à niveau importantes consiste à remplacer l'optimiseur AdamW par Muon pour la plupart des modules, permettant une vitesse de convergence plus rapide et une meilleure stabilité de l'entraînement.
Dans la documentation technique de Kimi K2.6, l'optimiseur Muon est également mentionné, permettant une amélioration de l'efficacité par 2 pour la même quantité d'entraînement.
L'optimiseur Muon, mentionné par les deux modèles, a été initialement proposé par le chercheur indépendant Keller Jordan fin 2024 dans un blog. L'équipe de Moonlight, également aux prises avec AdamW, a apporté des améliorations techniques cruciales à Muon début 2025, ajoutant des capacités comme Weight Decay et le contrôle RMS, et l'a nommé MuonClip.
Moonlight a été la première à valider la stabilité de l'optimiseur Muon sur Kimi K2, réalisant un pré-entraînement complet avec « zéro pic de perte ». DeepSeek, lors de l'entraînement de son grand modèle V4, a également adopté l'optimiseur Muon préalablement validé.
Il convient de noter que la « coévolution » des grands modèles open source ne sombre pas dans l'homogénéisation, mais s'oriente vers une voie d'« harmonie sans uniformité ».
Par exemple, DeepSeek-V4 se concentre sur le renforcement des capacités fondamentales du modèle de base, consolidant davantage le plafond de performance des grands modèles open source mondiaux et fournissant à toute l'industrie une base fondamentale aux performances rivalisant avec les flagships propriétaires ; Kimi K2.6 se spécialise sur l'ingénierie de déploiement des Agents, résolvant le point sensible de l'exécution autonome à long terme des grands modèles, et ouvrant la voie critique à l'entrée des grands modèles dans les scénarios de production réels.
Tout au long de ce processus, il n'y a pas eu de négociations commerciales prolongées, pas de bataille de brevets tendue. Dans le camp open source, l'innovation technologique circule librement comme de l'eau, et celui qui fait du bon travail est utilisé par tous.
Puiser des nutriments dans l'écosystème open source, se compléter sur le plan technologique. Les fabricants chinois de grands modèles démontrent par leurs actions une autre possibilité en dehors de la Silicon Valley.
03 Les États-Unis « construisent des murs », la Chine « construit des routes »
Tout en admirant la coévolution open source, il faut faire face à une réalité commerciale.
Actuellement, les revenus annualisés d'OpenAI et d'Anthropic dépassent tous les deux les dizaines de milliards de dollars, tandis que les revenus des principaux fabricants chinois de grands modèles viennent tout juste de franchir le cap du milliard de dollars annualisé.
La valorisation d'OpenAI sur le marché secondaire est d'environ 8800 milliards de dollars, celle d'Anthropic a grimpé à environ 1000 milliards de dollars, tandis que les valorisations de Kimi et DeepSeek lors de leur dernier tour de financement sont respectivement de 18 et 20 milliards de dollars.
Certains crient que la valorisation des fabricants chinois de grands modèles est sous-estimée, d'autres pensent que : « La capacité à transformer la réputation technologique en argent comptant est l'épreuve cruciale qui se pose aux fabricants chinois. » Les discussions sur le « rapport qualité-prix » de l'open source ont fait rage.
Pour entrevoir l'issue finale, on peut se baser sur les phases de concurrence des grands modèles :

La première phase était « la course aux paramètres, la course aux Benchmarks ». Fin avril 2026, cette phase est pratiquement terminée, les scores des différents acteurs sur les classements n'arrivent plus à creuser un écart substantiel.
La deuxième phase est « la course à l'efficacité de l'entraînement, la course au coût d'inférence, la course à l'innovation architecturale ». C'est la phase actuelle, résultat inévitable de la pression des coûts de calcul.
La troisième phase sera « la course aux systèmes d'Agent, la course à l'écosystème, la course aux développeurs ». Lorsque le Token passera de trafic gratuit à « carburant » pour l'exécution des tâches, la prospérité de l'écosystème déterminera la survie.
Dans quelle niche écologique se situent les grands modèles open source chinois ? Nous avons trouvé deux ensembles de données comparatives直观的.
Le premier est le coût d'entraînement.
GPT-5, publié en août 2025, a coûté plus de 500 millions de dollars à entraîner ; Kimi K2 Thinking, de la même période, a coûté environ 4,6 millions de dollars à entraîner ; DeepSeek n'a pas publié le coût d'entraînement des modèles V4, mais le modèle V3 n'a coûté que 5,576 million de dollars... Les fabricants chinois de grands modèles n'ont utilisé qu'une fraction des ressources d'OpenAI pour entraîner des modèles de niveau équivalent.
L'autre est le volume d'appels.
Début 2026, les données de la plateforme d'agrégation multi-modèles OpenRouter ont montré : Sous l'impulsion des produits Agent représentés par OpenClaw, la consommation mondiale de Tokens a connu une croissance exponentielle, et la « dream team » open source chinoise, grâce à sa réputation « efficace et abordable », a dépassé les États-Unis en volume d'appels pendant plusieurs semaines consécutives.
La raison n'est pas difficile à expliquer.
Le camp open source chinois a déjà validé la « roue de rétroaction positive » : La société A open source une technologie de base, la société B l'adopte et l'optimise sur le plan de l'ingénierie, puis restitue les résultats et l'expérience d'optimisation à tout l'écosystème. Si l'évolution des modèles closed-source est une croissance linéaire basée sur l'empilement massif de puissance de calcul, ce qui attend la voie open source est la diffusion exponentielle apportée par la collision des innovations technologiques.
Selon le rapport de recherche de JPMorgan, le taux de croissance annuel composé (TCAC) de la consommation de tokens d'inférence d'IA en Chine entre 2025 et 2030 sera d'environ 330%, passant de 10 000 milliards de tokens en 2025 à 3900 000 milliards de tokens en 2030, soit une multiplication par 370.
Autrement dit, 2026 est encore au début de l'explosion de l'IA, et il reste des opportunités de croissance de plusieurs centaines de fois au cours des 5 prochaines années, il est bien trop tôt pour tirer des conclusions définitives.
Précisément grâce à la confiance en ces opportunités à long terme, alors que les géants de la Silicon Valley construisent frénétiquement des murs, les fabricants chinois de grands modèles choisissent de renforcer constamment la route vers l'AGI par une complémentarité collaborative.
04 Pour conclure
Qui aura le dernier mot dans cette vague d'IA fracassante ? La réponse ne concerne pas seulement les modèles, mais aussi l'autonomie et le contrôle de la puissance de calcul. Si le modèle est comparé à une « bombe atomique », alors la puissance de calcul nationale, libérée du blocus technologique externe, est la « fusée » qui envoie la bombe atomique dans le ciel.
Il est réconfortant de constater que l'intégration entre les modèles nationaux et la puissance de calcul nationale devient de plus en plus étroite : Dans la documentation technique de DeepSeek V4, le NPU Ascend et le GPU NVIDIA sont listés côte à côte dans la liste de validation matérielle ; Moonlight, dans son dernier article, a fait fonctionner le pré-remplissage et le décodage de l'inférence des grands modèles sur différentes puces, ouvrant la porte à une participation à grande échelle des puces nationales dans l'inférence des modèles.
Début 2025, DeepSeek R1 a offert aux grands modèles nationaux une chance de s'asseoir à la table des négociations ; en 2026, le camp des grands modèles open source chinois, grâce à la collaboration et la coopération, ne cesse de créer davantage de capital dur pour définir les règles du jeu.







