Contraintes liées au calcul
Depuis la fin de l'année dernière, des GPU nationaux tels que Moore Threads, MetaX, Biren Technology et Enflame Technology ont suscité un engouement capitaliste. Cependant, derrière cette fête de richesse sur le marché secondaire, une ligne sombre devient de plus en plus claire, et les problèmes qu'elle soulève deviennent de plus en plus urgents.
Ces dernières années, les puces d'IA nationales se sont principalement concentrées sur le côté relativement sûr et plus périphérique de l'« inférence », comme le projet récent de Doubao d'acheter 50 000 puces Enflame Technology pour des tâches d'inférence, afin de satisfaire les appels fréquents de cette plus grande application d'IA terminale en Chine.
Dans la séquence supérieure de la pyramide de calcul qu'est l'entraînement de l'IA, les puces nationales ne peuvent actuellement participer qu'à des tâches périphériques « d'assistance ».
Les puces d'entraînement d'IA sont principalement utilisées pour l'entraînement des modèles d'intelligence artificielle, impliquant d'importants calculs matriciels et ajustements de paramètres, nécessitant ainsi une puissance de calcul robuste et un haut rendement énergétique. Elles sont plus puissantes et également très coûteuses, comme les séries A100, H100, H200 de Nvidia et la série MI300 d'AMD ;
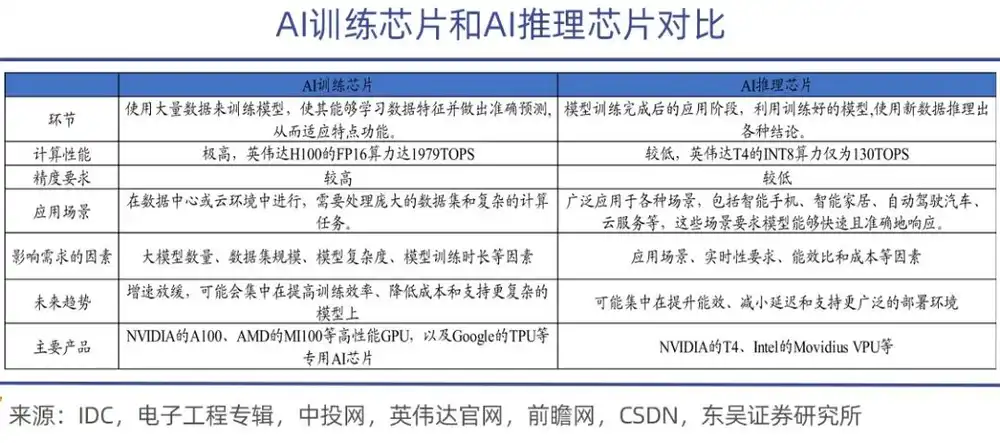
En comparaison, la tâche des puces d'inférence est beaucoup plus légère. Elles sont utilisées dans la phase de déploiement après l'entraînement du modèle, principalement responsables de l'exécution des tâches d'inférence du modèle, nécessitant une grande réactivité. Les puces d'inférence doivent offrir une réponse rapide et une faible consommation d'énergie tout en garantissant la précision.
Une métaphore appropriée serait que l'entraînement consiste à « apprendre des connaissances » au modèle d'IA, tandis que l'inférence consiste à « appliquer les connaissances » par le grand modèle. Pendant la phase d'apprentissage, la puce d'entraînement doit mobiliser des données massives pour « nourrir » des mises à jour dynamiques de paramètres de l'ordre de milliards, de milliers de milliards, voire de dizaines de milliers de milliards, nécessitant non seulement une puissance de calcul robuste, mais aussi une bande passante et des capacités de communication efficaces, ainsi qu'une stabilité au sein de clusters de dizaines de milliers de cartes.
La racine de l'écart entre les modèles sino-américains réside précisément dans ces « aspects invisibles », en particulier l'absence de puces d'entraînement haut de gamme.
Selon la loi d'échelle (Scaling Law) des grands modèles, plus les paramètres du modèle sont nombreux, plus les besoins en calcul augmentent linéairement, tandis que l'expansion exponentielle des coûts de calcul et matériels fait de l'entraînement des grands modèles un « jeu réservé » à une poignée de géants technologiques.
Parmi les géants technologiques américains, Meta à lui seul prévoit de déployer plus de 1,2 million de GPU haut de gamme d'ici fin 2026, avec un investissement annuel dépassant 1450 milliards de dollars ; selon d'autres estimations, la puissance de calcul totale d'IA de Google équivaut à 5 millions de Nvidia H100, une seule entreprise représentant un quart du total mondial.
Les dépenses en capital d'Amazon, Microsoft, Alphabet et Meta cette année atteignent 7250 milliards de dollars, en hausse de 77% par rapport à l'année précédente, ce qui équivaut à 13% de l'investissement privé intérieur total annuel des États-Unis. Morgan Stanley prédit même qu'en 2027, les dépenses en capital des entreprises technologiques américaines pourraient atteindre un record historique de 1100 milliards de dollars.
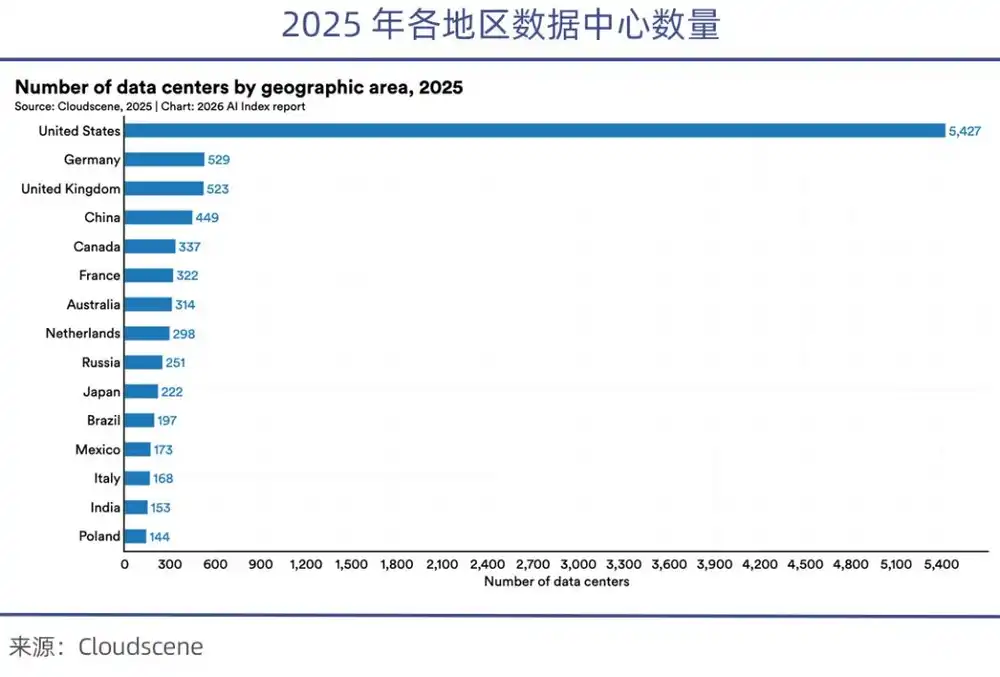
Actuellement, les États-Unis contrôlent plus de 70% des GPU haut de gamme mondiaux. Après l'interdiction des puces, la Chine ne dispose que d'un huitième des puces haut de gamme disponibles aux États-Unis. Le rapport Stanford AI Index Report 2026 indique que le nombre de centres de données aux États-Unis (5427) est plus de 10 fois supérieur à celui de la Chine.
Selon les estimations de l'Académie chinoise des technologies de l'information et des communications (CAICT), début 2025, la puissance de calcul des États-Unis était de 2400 EFLOPS, contre 1053 EFLOPS pour la Chine, soit plus du double.
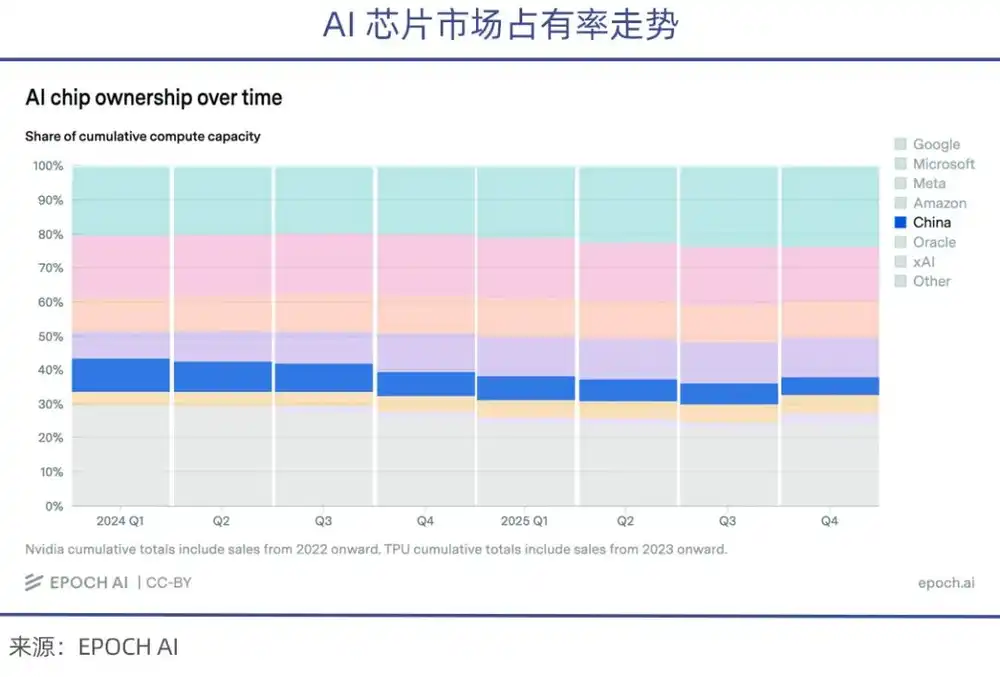
La puissance de calcul détenue par ces quatre géants technologiques, chacun pris séparément, dépasse déjà la somme de toutes les entreprises d'IA chinoises.
Cet avantage écrasant en matière de calcul permet aux entreprises américaines de réaliser une dizaine d'itérations expérimentales de grands modèles en un an.
Musk est encore plus extravagant, son xAI possédant Colossus 2, présenté comme le « premier cluster d'IA de classe GW » au monde. C'est pourquoi il affirme avec assurance qu'il est en train d'entraîner simultanément 7 modèles - deux modèles à 1 000 milliards de paramètres, deux à 1 500 milliards, un à 6 000 milliards et un à 10 000 milliards de paramètres. Cette « esthétique de la force brute » n'est possible qu'avec une abondance extrême de puissance de calcul.

Parallèlement, en raison des restrictions américaines à l'exportation de puces, la part reçue par les entreprises chinoises dans les puces d'IA haut de gamme expédiées ces dernières années a continuellement diminué (selon les statistiques d'epoch.AI).
On peut affirmer sans exagération que l'énorme écart dans les fondations de calcul maintiendra l'IA chinoise dans une phase de rattrapage à long terme, et rendra également plus difficile le processus pour les grands modèles nationaux de rattraper leurs homologues américains.
Écart générationnel
« Le rythme de l'innovation en Chine est irrésistible », « Quiconque pense que la Chine ne peut pas produire (de puces) se trompe lourdement. L'écart entre la Chine et les États-Unis n'est que de l'ordre de la nanoseconde. »
Jensen Huang, fondateur de Nvidia, a à plusieurs reprises salué les progrès des semi-conducteurs chinois en public.

Musk exprime souvent des points de vue similaires sur X – « La Chine résoudra certainement le problème du goulot d'étranglement des puces, et dans le domaine de la puissance de calcul pour l'intelligence artificielle, elle dépassera de loin tous les autres pays du monde », « La Chine gagnera la course à l'IA sur Terre ».
Les éloges dithyrambiques de ces grands noms de la technologie à l'égard du développement de l'IA chinoise sont facilement crus. Ces déclarations ont clairement une connotation de flatterie excessive. Certains médias américains ne cessent de propager l'idée que l'écart entre les modèles chinois et américains est minime, tentant de brouiller les faits et de masquer certaines vérités objectives.
À cet égard, les domaines liés à l'IA en Chine devraient rester lucides et calmes.
Si aujourd'hui les grands modèles chinois avancés ne diffèrent guère de leurs homologues américains pour résoudre des problèmes standardisés, l'écart apparaît plus manifeste dans des environnements industriels et d'entreprise complexes.
Comparés aux modèles de pointe américains comme ceux d'Anthropic, les modèles chinois sont toujours des suiveurs. L'évaluation américaine CAISI estime que le plus puissant modèle chinois, DeepSeek V4 Pro, a environ 8 mois de retard sur la pointe américaine.
Kai-Fu Lee a récemment indiqué dans une interview au Wall Street Journal qu'en prenant comme référence des modèles américains de pointe comme Claude Fable 5 d'Anthropic, les États-Unis ont actuellement environ 15 mois d'avance sur la Chine.

Les grands modèles suivent la loi d'échelle (Scaling Law) : plus le nombre de paramètres du modèle est grand, plus les données d'entraînement sont nombreuses, plus la puissance de calcul investie est importante, meilleures sont les performances du modèle. Aujourd'hui, les grands modèles américains les plus avancés sont entrés dans l'ère des dizaines de milliers de milliards de paramètres, et leur vitesse d'itération s'accélère encore.
Le plus puissant modèle d'Anthropic, Mythos, atteint déjà 10 000 milliards de paramètres, son entraînement coûtant 100 milliards de dollars ; le Colossus 2 de xAI entraîne simultanément 7 modèles, dont des modèles à 6 000 et 10 000 milliards de paramètres ; le cycle d'itération d'un modèle à 4 000 milliards de paramètres chez OpenAI n'est que d'un mois.
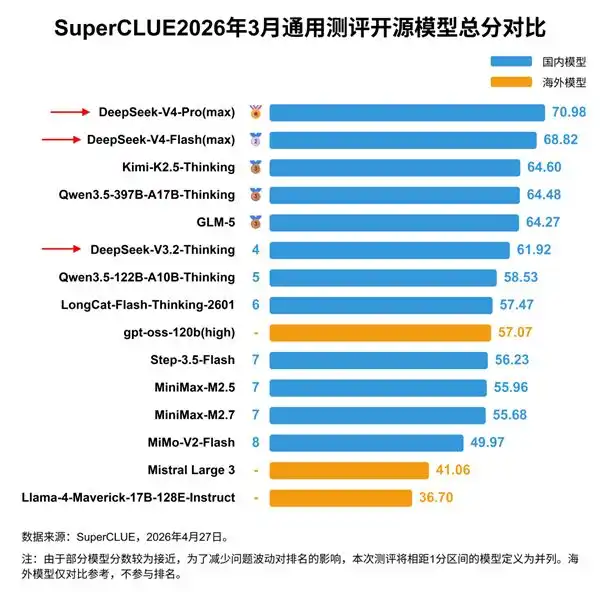
Le modèle chinois le plus puissant, DeepSeek V4 Pro, a un nombre total de paramètres de 1 600 milliards, soit environ 6 fois moins que les modèles américains de pointe à dizaines de milliers de milliards de paramètres.
La série Claude d'Anthropic est déjà reconnue comme le plus puissant modèle de programmation d'IA des deux dernières années, et Mythos a une nouvelle fois élargi les horizons du public, ses performances étant encore plus impressionnantes que celles du précédent modèle phare, Oups 4.6.
OpenBSD jouit d'une réputation de système le plus sécurisé de l'industrie, pourtant Mythos a trouvé une vulnérabilité non découverte pendant 27 ans ; il a également décelé des vulnérabilités dans FFmpeg et le noyau Linux qui n'avaient pas été trouvées depuis plusieurs années, voire plus d'une décennie, et ce de manière totalement autonome, sans aide humaine.
Il faut savoir que le « pré-entraînement » du grand modèle détermine le plafond des capacités du modèle ; on ne peut pas, via un « post-entraînement », amener un modèle à paramètres de l'ordre du millier de milliards au niveau de capacité d'un modèle à 10 000 milliards de paramètres. Et le facteur déterminant du pré-entraînement est la puce de calcul haut de gamme, qui détermine l'échelle des paramètres et la vitesse d'itération de l'entraînement.
Liu Qingfeng, président de iFlytek, l'a reconnu : actuellement, les principaux fabricants de grands modèles, en particulier les géants américains, construisent des plateformes de calcul à très grande échelle. Le calcul national chinois traverse effectivement une période douloureuse, ce qui entraîne des limitations dans l'entraînement de contextes de texte très longs.
Il est donc clair que l'écart en matière de puissance de calcul est à l'origine de la différence entre les modèles chinois et américains.
L'essor national
Une entreprise monopolise 90% du marché mondial des puces d'entraînement d'IA haut de gamme – cela aide Nvidia à maintenir son trône de première capitalisation boursière mondiale. Sa capitalisation boursière totale a même dépassé le PIB de l'Allemagne, troisième économie mondiale, en 2025.
Les données de TrendForce montrent qu'au premier trimestre 2026, sur le marché mondial des serveurs GPU, Nvidia a capturé 68%, AMD 5% à 6%, tandis que l'ensemble des fabricants de GPU nationaux chinois représente moins de 4%.
Grâce à son avantage du premier arrivé, ses barrières technologiques ultra-solides, son interconnexion à haut débit, son écosystème logiciel et son lien avec les procédés avancés de TSMC, Nvidia règne en maître. Dans les scénarios d'entraînement haut de gamme, le GB300 de Nvidia surpasse le MI325 d'AMD, et est également meilleur que le Siyuan 690 de Cambricon ou le MTT40 de Moore Threads, en particulier dans l'entraînement de grands modèles à paramètres de l'ordre du millier de milliards, où il dépasse les concurrents de plus de 30%.
Face à l'interdiction d'exportation, Jensen Huang avait déjà indiqué que la part de marché de Nvidia en Chine (nouveaux marchés) était pratiquement tombée à zéro, ne laissant que le marché existant. Soutenu par la politique de substitution nationale, des entreprises telles que Huawei (Ascend 910), Hygon (DCU ShenSuan 2), Cambricon (Siyuan 370/590), ainsi que Moore Threads, MetaX, etc., ont émergé successivement.
Parmi elles, l'Ascend 910 est la puce de calcul la plus puissante de Huawei, l'Ascend 910B atteignant une puissance de calcul de 640 TOPS (INT8), comparable à la puce Nvidia A100.
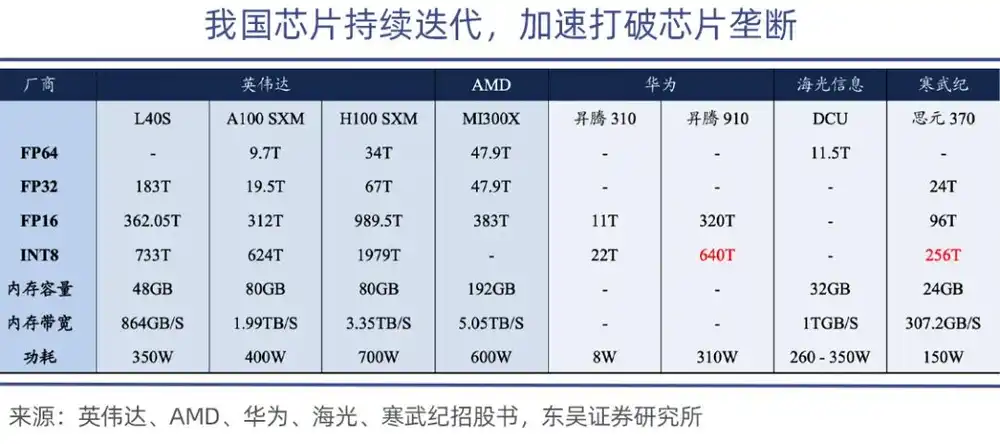
En termes de performance absolue, les GPU nationaux présentent encore un écart, mais ils peuvent d'abord s'attaquer aux scénarios d'inférence et périphériques. Actuellement, les GPU nationaux répondent largement aux besoins d'inférence généraux des entreprises et gouvernements chinois, l'écart avec les produits Nvidia de milieu de gamme s'étant réduit à 15%-20%, ce qui rend la substitution réalisable.
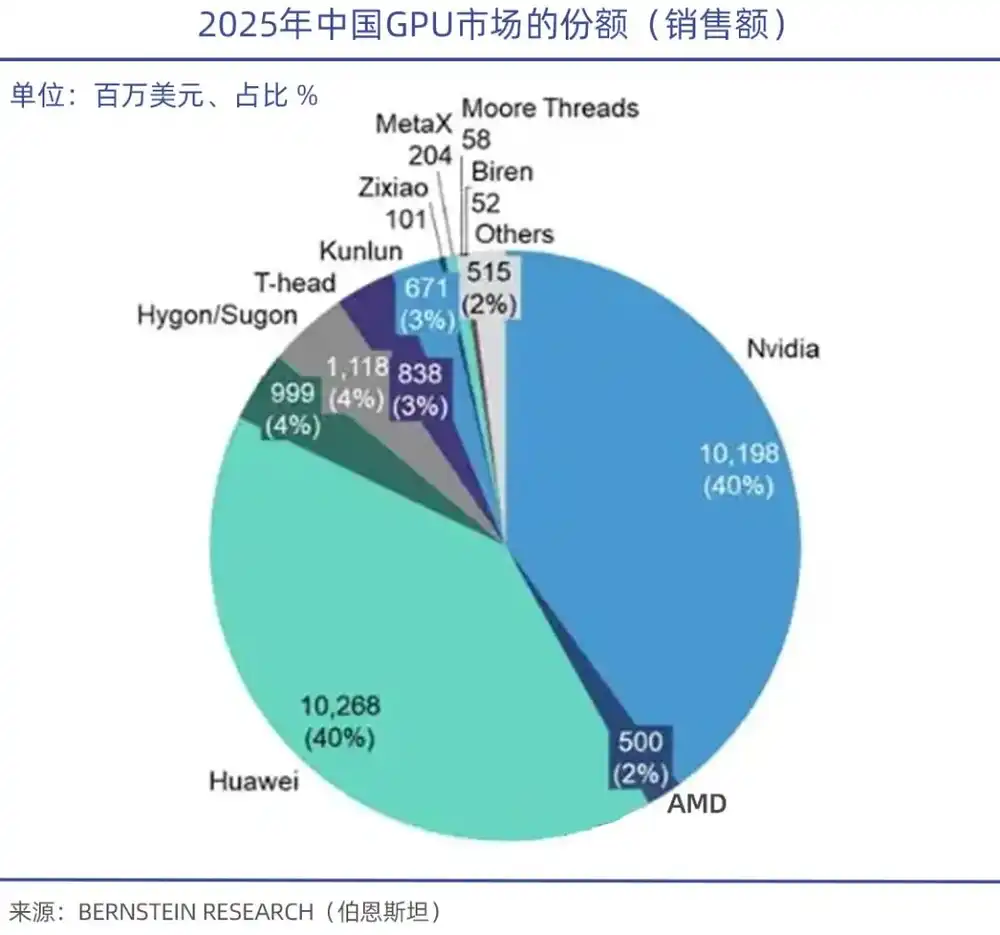
Il est particulièrement important de souligner que si la performance de calcul est cruciale, l'écosystème logiciel sous-jacent reste le point faible des GPU nationaux. Tout comme CUDA est le fondement de l'empire GPU de Nvidia, l'académicien de l'Académie d'ingénierie de Chine Zheng Weimin a souligné que le problème central des puces d'IA nationales est leur écosystème insuffisant. Si l'écosystème était bon, même avec une performance à 60%, il y aurait des utilisateurs.
On peut dire que l'écosystème logiciel est la barrière la plus dure dans la course aux GPU, et dans ce domaine également, les capacités de Nvidia sont difficiles à remplacer.
L'écosystème CUDA, développé sur plus d'une décennie, compte désormais plus de 4 millions de développeurs, des centaines de milliers de modèles open source, une chaîne d'outils tierce complète, couvrant l'entraînement et l'inférence de l'IA, le rendu graphique et le calcul scientifique, formant une barrière écologique extrêmement solide.
Les données d'IDC montrent qu'actuellement, plus de 95% des modèles d'IA dans le monde sont développés sur l'écosystème CUDA. Les GPU nationaux, soutenus par les politiques, doivent collaborer à long terme avec la chaîne industrielle et nécessitent suffisamment de patience de la part des médias et des marchés financiers.
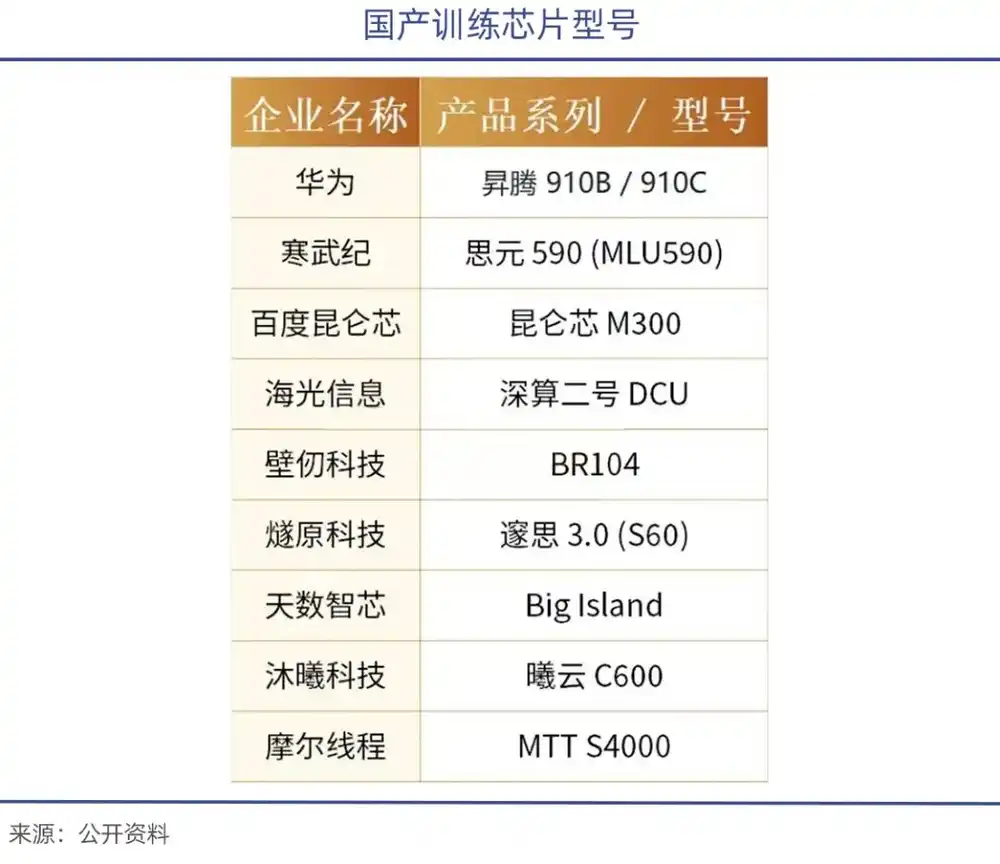
En janvier de cette année, Zhipu AI, en collaboration avec Huawei, a open-sourcé le nouveau modèle de génération d'images GLM-Image. Ce modèle, basé sur l'équipement Huawei Ascend Atlas 800T A2 et le cadre d'IA MindSpore, a réalisé un processus complet fermé, de la gestion des données à l'entraînement du modèle. Il s'agit du premier modèle multimodèle SOTA entraîné entièrement sur des puces nationales ;
Moore Threads a également collaboré avec l'Institut de recherche en intelligence artificielle de Pékin (BAAI) pour réaliser l'entraînement complet du modèle cérébral corporel RoboBrain 2.5, développé en interne par BAAI, en utilisant le cluster de calcul intelligent MTT S5000 et le cadre FlagOS-Robo. Cette réalisation a validé pour la première fois l'utilisabilité des clusters de calcul nationaux dans l'entraînement des grands modèles d'intelligence incarnée.
On peut constater que les GPU nationaux ont réalisé des percées en matière de compatibilité et de construction d'écosystème, passant d'une « percée ponctuelle » sur le front de l'inférence à une « adaptation progressive » sur le front de l'entraînement, ce qui représente déjà un progrès significatif.
Conclusion
Dans l'ensemble, dans le contexte de difficultés d'importation des puces avancées étrangères, il est possible de « combiner les approches orientale et occidentale » et de marcher sur deux jambes, tout en soutenant prioritairement les puces de calcul nationales pour répondre aux besoins urgents du marché.
L'authenticité de la demande est indéniable, la « théorie de la bulle » existe toujours, mais sa voix ne s'amplifie pas. L'enthousiasme mondial pour la construction de l'IA a dépassé celui de tout autre secteur industriel à ses débuts.
Cette année, le marché financier mondial a connu un nouveau super-cycle d'IA, les actions de Samsung, SK Hynix, Broadcom et TSMC ont atteint des records, tandis que sur le marché intérieur chinois, les technologies matérielles représentées par Cambricon ont également connu une forte hausse, et le géant des modules optiques, Zhongji Innolight, a même dépassé Moutai en termes de capitalisation boursière à un moment donné.
En retraçant l'histoire des semi-conducteurs sud-coréens, la Corée du Sud a soutenu l'industrie des puces mémoire avec des efforts nationaux, a traversé ses moments les plus sombres et a finalement battu le Japon pour devenir le leader absolu de l'industrie mondiale de la mémoire.
Que ce soit pour les puces mémoire, les puces pour téléphones portables, ou même les puces d'IA actuelles, la Chine est encore en phase de rattrapage, ce qui n'est pas l'affaire d'un jour. Mais grâce à son immense marché, à l'émergence continue de talents en IA et à sa puissance capitalistique considérable, les GPU nationaux commencent déjà à montrer une certaine adaptabilité et sont capables de répondre aux besoins réels de nombreuses entreprises d'IA.
Dans cette confrontation d'IA liée au destin national, la Chine et les États-Unis sont à la fois des adversaires et des partenaires possédant les technologies, marchés et ressources dont l'autre a besoin.
Cet article provient du compte WeChat officiel : Juchao WAVE , éditeur : Yang Xuran, auteur : Xie Zefeng, titre original : 《Le défi du calcul dans la confrontation sino-américaine en matière d'IA | Juchao》





