Les prompts sont morts, vive les loops.
C'est le nouveau point de mire que Huang Renxun, "Lao Huang", a récemment placé pour la nouvelle tendance de l'IA, faisant le buzz sur Internet :
Personne n'écrit de prompts de nos jours. Le nouveau métier, c'est d'écrire et de gérer des loops. (Nobody writes prompts anymore. The new job is to write and handle loops.)
Qu'est-ce qu'un loop ? Traduit littéralement par "boucle", dans le jargon de l'IA, cela signifie :
Vous ne donnez plus d'instructions manuelles à l'IA. Vous concevez un système qui donne les instructions, valide les résultats, recommence en cas d'échec, et ce jusqu'à ce que le travail soit terminé.
Hein ? Ce n'est pas ce que font les Agents aujourd'hui ? Pourquoi sortir un nouveau concept ?
Mettons cette question de côté pour le moment. En jetant un coup d'œil autour, je me suis rendu compte que ce "loop" est vraiment très populaire —
En plus de Lao Huang, des figures comme Peter "le père des langoustes", Boris Cherny "le père de Claude Code", Andrew Ng, et d'autres grands noms en parlent tous et le poussent activement.
(Peter) Arrêtez d'écrire des prompts pour les Agents de programmation. Concevez des loops, et laissez les loops prompter l'Agent à votre place.
(Boris) Je n'écris plus de prompts pour Claude. J'ai un tas de loops qui tournent, ce sont eux qui donnent les instructions à Claude et décident de la prochaine étape. Mon travail, c'est d'écrire des loops.
Et alors que "écrire des loops" remplace "écrire des prompts" dans le quotidien des grands noms, il est clair que le loop a dépassé le stade de "juste un nouveau concept de plus".
Les questions qui restent sont :
Que signifie concrètement un loop ? Comment est-il devenu si populaire si soudainement ?
Qu'est-ce qu'un loop exactement ?
Pour comprendre cette nouvelle chose qu'est le loop, revenons d'abord à l'ancien paradigme.
Ces deux dernières années, la procédure standard pour la programmation IA était celle-ci :
Vous écriviez un prompt, l'IA crachait du code, vous n'étiez pas satisfait, vous en écriviez un autre, l'IA corrigeait, vous regardiez à nouveau......
En bref, un va-et-vient constant, avec l'humain qui surveillait tout le processus.
Karpathy avait même critiqué indirectement le fait que "l'humain est le goulot d'étranglement", et avait conseillé :
Vous ne pouvez pas rester assis là à attendre pour écrire un prompt à chaque étape, vous devez vous extraire du processus.
Extraire l'humain du processus, c'est précisément ce que le loop vise à résoudre.
Sa logique centrale tient en une phrase :
Vous définissez un objectif, l'IA exécute seule, valide elle-même les résultats, en cas d'échec elle recommence avec les erreurs, et ce jusqu'à ce que l'objectif soit atteint ou que la limite budgétaire soit atteinte.
Le rôle de l'humain passe alors de "messager" à "concepteur de règles".
Revenons donc à la question initiale : quelle est la différence avec un Agent ?
Évidemment, l'Agent est la personne qui fait le travail, tandis que le loop est le mécanisme de gestion qui permet à cette personne de travailler continuellement sans que vous ayez à la surveiller.
Un Agent sans loop, vous dites un mot et il bouge, c'est fondamentalement un outil obéissant.
Un Agent équipé d'un loop devient vraiment un système capable de fonctionner de manière autonome.

Le principe semble en effet peu compliqué, mais reste un peu abstrait.
Ne vous inquiétez pas, je suis allé voir les cas concrets actuels de mise en œuvre des loops, et j'ai découvert qu'ils sont déjà cachés dans des systèmes que nous connaissons bien.
Autour des loops, une "double confrontation" s'est formée au niveau des produits commercialisés.
Le premier est Claude Code, que nous utilisons tous les jours, qui a construit une trilogie autour du loop :
/loop pour les boucles programmées, /goal pour la conduite par objectif (jusqu'à ce que les critères de validation soient satisfaits), /schedule pour les tâches planifiées dans le cloud (qui tournent même ordinateur éteint).
La conception la plus ingénieuse est celle de /goal, qui cache le principe clé du loop — on ne peut pas juger sa propre copie.
Claude Code a directement intégré ce principe dans son architecture produit :
Le code est écrit par le grand modèle, mais validé par un autre petit modèle indépendant, Haiku. Les deux modèles ont des rôles distincts.
Ainsi, l'Agent ne peut pas s'auto-attribuer une note élevée, et la validation a une contrainte réelle.

L'autre est OpenAI Codex.
Le fonctionnement de Codex se rapproche plus d'une combinaison "chaîne de production automatisée + conduite par objectif + multiples sous-Agents". Dans l'expérience pratique de certains développeurs, on peut voir jusqu'à 8 Agents fonctionnant simultanément dans leurs sandbox cloud respectives, chacun faisant son travail, avant de rassembler les résultats.
Il est intéressant de noter que, bien que les approches des deux entreprises soient différentes, la forme finale est très similaire —
Toutes deux décomposent les tâches complexes, les distribuent à plusieurs Agents pour une exécution parallèle, puis agrègent les résultats.
Dans les évaluations publiques et la réputation de la communauté, leurs performances sont également très proches.
Cela montre également un problème : les modèles eux-mêmes ne peuvent plus apporter de différences significatives, le véritable écart se situe dans l'orchestration des loops en amont.
Sur ce point, regardons simplement comment Boris Cherny, le "père de Claude Code", travaille chaque jour pour tout comprendre.
Il raconte qu'il a désinstallé son IDE en novembre dernier, ne l'a pas ouvert pendant un mois, et l'a finalement supprimé.
Maintenant, il a des centaines de petits Agents qui fonctionnent simultanément, certains scannent les issues GitHub, d'autres lisent les retours des utilisateurs sur Slack, d'autres surveillent les échecs CI. Chaque Agent travaille dans sa branche de code isolée, un écrit le code, un autre exécute les tests pour valider.
Seuls les cas insolubles arrivent dans sa boîte de réception, attendant son jugement.
Selon lui, depuis Opus 4.5, tout son code est écrit par Claude Code, et aujourd'hui la plupart du code est écrit directement sur son téléphone.
La prochaine étape, c'est la boucle, où les Agents se promptent mutuellement, sans intervention humaine intermédiaire.
Vous voyez, la forme ultime du loop est déjà très claire :
L'humain n'écrit pas de code, n'écrit pas de prompts, il écrit seulement des règles et des jugements, et laisse le reste au loop.
Comment se mettre au loop
Alors, comment se mettre au loop ?
Un blogueur nommé Codez sur X a déjà tout résumé pour nous, il a publié une feuille de route pratique en 14 étapes. J'en ai extrait quelques éléments concrets.

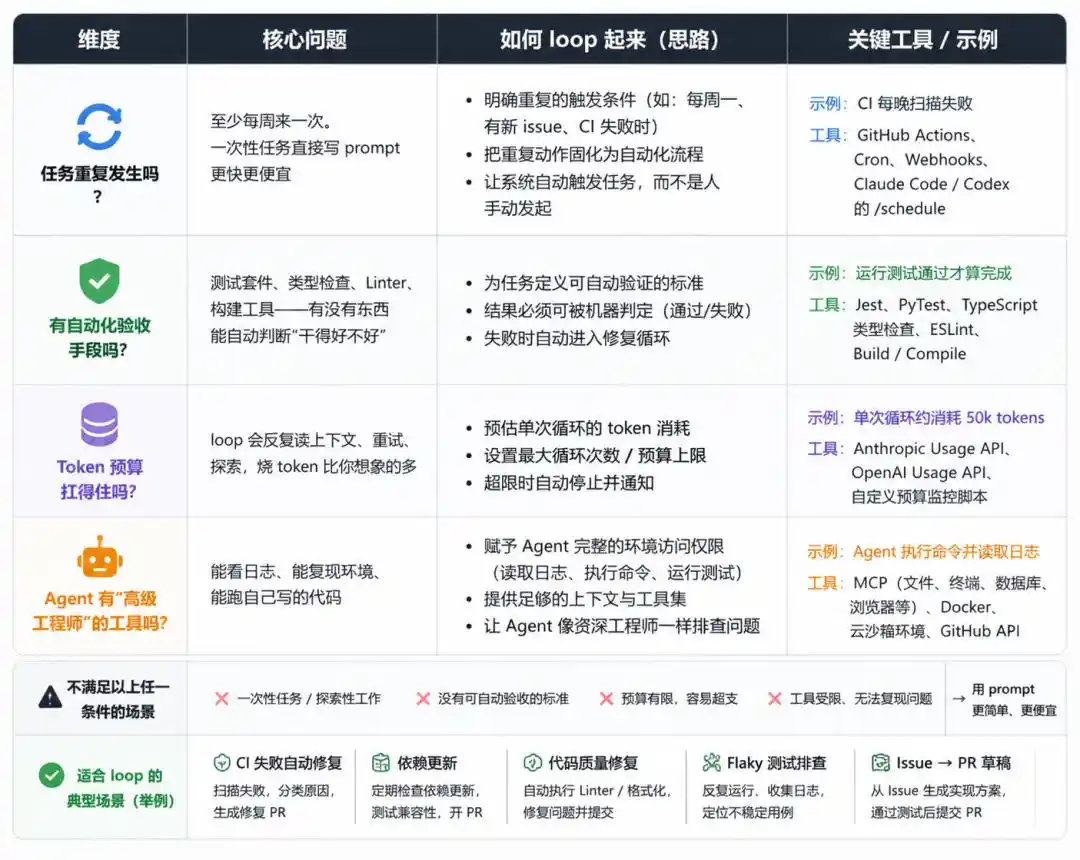
Étape 1 : Ne vous précipitez pas pour construire, faites d'abord le "test des 4 conditions"
Le loop n'est pas adapté à toutes les tâches. En créer un sans réfléchir ne fera que perdre de l'argent.
Avant de commencer, répondez à ces quatre questions :
La tâche se répète-t-elle ?
Y a-t-il un moyen de validation automatisée ?
Le budget en tokens peut-il supporter la charge ?
L'Agent a-t-il les outils d'un "ingénieur senior" ?
△
Si les quatre conditions sont réunies, alors cela vaut la peine de créer un loop.
Étape 2 : Commencez par le plus petit loop viable
Pour la première fois, pas de fantaisie, construisez simplement un kit de quatre éléments :
Un déclencheur (Automation) : fonctionnant à intervalles réguliers ou déclenché par des événements. Utilisez /loop dans Claude Code, ou le panneau Automations dans Codex.
Une compétence (Skill) : Écrivez le contexte du projet dans STATE.md, afin de ne pas avoir à tout réexpliquer à chaque exécution.
Un fichier d'état (State File) : Utilisez Markdown pour noter "où en est-on, ce qui a réussi, ce qui a échoué", pour reprendre la prochaine fois.
Un portail (Gate) : Tests, vérification de types, build — quelque chose qui peut automatiquement bloquer les mauvais résultats.
Et l'ordre est crucial : d'abord, exécuter manuellement une fois → l'écrire en Skill → l'intégrer dans un loop → enfin, programmer.
Sauter des étapes est la principale cause de mort des loops en environnement de production.
Étape 3 : Soyez celui qui "découpe les copies", pas celui qui "note les copies"
Le principe le plus important dans toute conception de loop, déjà mentionné précédemment, est le suivant — celui qui écrit le code et celui qui valide le code doivent être séparés.
Concrètement, cela signifie :
Utilisez un modèle (ou un sous-Agent) pour écrire, et un autre modèle indépendant (ou un autre sous-Agent) pour valider. Celui qui valide ne doit pas voir le processus de raisonnement de celui qui écrit le code.
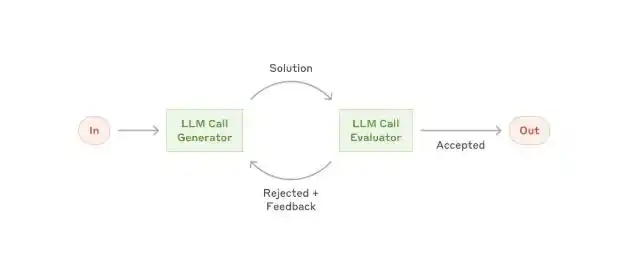
Pourquoi est-ce si important ? Parce que lorsqu'un modèle note son propre code, il est souvent "trop indulgent".
Tout code qui "semble correct" a de fortes chances de révéler de nombreux problèmes face à un validateur indépendant.
Étape 4 : Ne retombez pas dans les pièges où d'autres sont déjà tombés
Voici quelques conseils pour éviter les pièges.
1. Aucune condition d'arrêt stricte. Un loop s'arrête seulement quand vous découvrez la facture ou êtes limité, donc il faut définir une limite de tokens, une limite d'itérations, une limite de temps.
2. L'état n'est pas persistant. La mémoire d'un Agent est de courte durée, ce qu'il a appris aujourd'hui, il l'oubliera demain. Il faut donc l'écrire dans un fichier d'état (STATE.md) et le relire à chaque exécution.
3. Faire faire à un loop des tâches "nécessitant un jugement". Réécriture d'architecture, code d'authentification, logique de paiement, décisions d'orientation produit — ne laissez pas un loop toucher à cela. Les loops conviennent aux tâches "claires en termes de justesse, vérifiables par machine, ne dépendant pas du jugement humain", comme la correction automatique de lint, les PR de mise à jour de dépendances, la classification des échecs CI, la reproduction de tests flaky.
4. Ne pas lire les Diff. Les loops fusionnent le code de plus en plus vite, votre compréhension du dépôt de code devient de plus en plus superficielle. C'est ce qu'on appelle la "dette de compréhension" — le véritable coût n'est pas la facture de tokens, mais le jour où vous devrez déboguer un système que personne dans l'équipe n'a lu. Il est donc conseillé de lire les Diff, même rapidement.
Étape 5 : Une seule mesure compte
Ne vous souciez pas du nombre de tokens brûlés, du nombre de PR ouvertes, du nombre de tâches exécutées.
Le seul indicateur utile est : Quel est le coût moyen par modification acceptée.
Si votre "taux d'acceptation" est inférieur à 50 %, cela signifie que vous faites le travail de revue que le loop était censé vous éviter, c'est-à-dire que le loop perd de l'argent.
Des prompts aux loops, quatre sauts de paradigme
Maintenant que nous avons compris les principes et les méthodes, la dernière question est :
Pourquoi les loops sont-ils devenus si populaires maintenant ?
Bien que, strictement parlant, le concept de loop Engineering ait moins de trois semaines d'existence.
Il n'est pas apparu de nulle part. En remontant la ligne du temps, on voit un chemin d'évolution très clair.
Les grands noms l'ont déjà résumé pour nous, recopions simplement :
De Prompt → Context → Harness → loop, quatre sauts en tout.
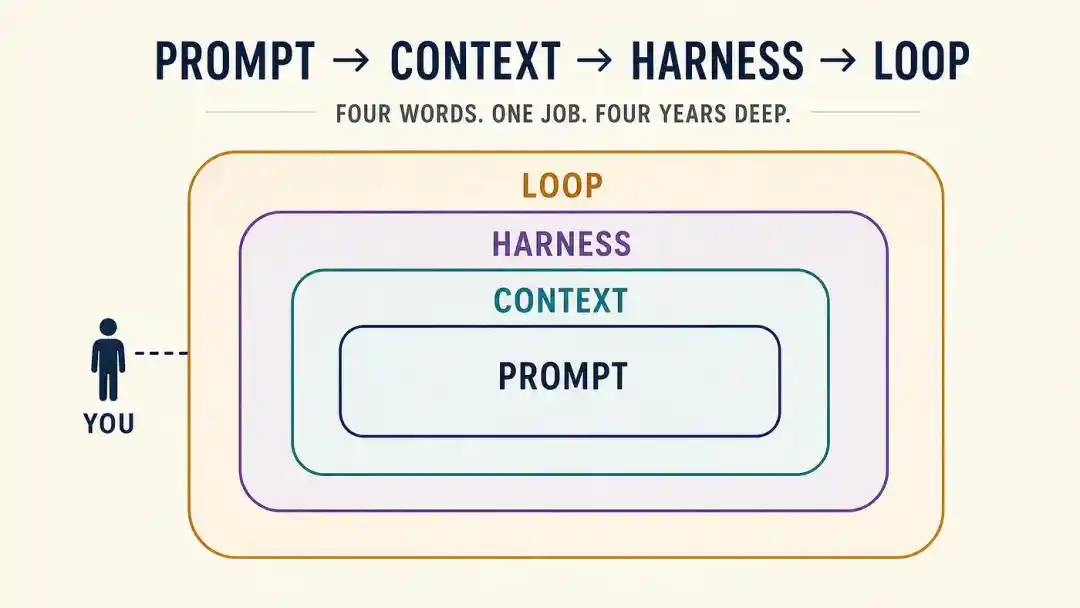
En bref, de 2023 à 2024, c'était le règne du Prompt Engineering.
À l'époque, tout le monde cherchait à savoir : comment écrire un prompt pour que l'IA travaille correctement.
Un bon et un mauvais prompt donnaient des résultats radicalement différents, donc à cette époque, "savoir écrire un prompt" équivalait pratiquement à "savoir utiliser l'IA".
À ce stade, la relation entre l'humain et l'IA restait très superficielle — vous disiez un mot, elle répondait un mot, chaque instruction devait être tapée manuellement.
Mais avec l'amélioration des capacités des modèles, l'élargissement des fenêtres de contexte, et la popularisation croissante du RAG et de l'intégration des dépôts de code, le problème a commencé sa première migration.
Aux alentours de 2024-2025, l'industrie a commencé à souligner l'importance du "Context Engineering", l'accent passant de "comment poser la question" à "quoi montrer à l'IA".
En d'autres termes, l'IA ne dépend plus d'un seul prompt, mais de tout le contexte que vous lui fournissez.
À ce stade, la capacité d'organisation de l'information devient plus importante que l'écriture de prompts, la granularité du contrôle passe de "une phrase" à "un ensemble d'informations".
Vers 2025-2026, alors que les systèmes d'Agents entraient progressivement dans les flux de développement réels, le problème continuait de s'élargir.
À ce moment, les gens se sont rendu compte qu'il ne suffisait plus de donner des informations et du contexte. L'IA devait pouvoir utiliser des outils, exécuter du code, appeler des API, suivre des approbations d'accès.
Il fallait donc lui construire un environnement d'exécution où elle pouvait travailler, être contrainte et accéder aux ressources du monde réel.
C'est précisément pour cela qu'est né le "Harness Engineering".
Et sur la base du Harness, le "loop Engineering" est devenu la nouvelle direction d'évolution.
Si le Harness résout le problème de "l'IA peut-elle travailler dans un environnement réel", alors le loop résout le problème de "l'IA peut-elle travailler continuellement dans cet environnement, faire avancer les tâches d'elle-même, sans qu'un humain ait besoin de surveiller chaque étape".
Son cœur n'est plus la capacité d'exécution unique, mais la capacité de fonctionnement d'un système en boucle fermée.
Ainsi, de Prompt à Context, puis à Harness, puis à loop, cela ressemble à un remplacement de concepts, mais il s'agit essentiellement d'un chemin de migration continu :
Le contrôle humain sur l'IA passe à une granularité de plus en plus élevée, de "écrire une phrase", à "fournir des informations", puis à "construire un système", et finalement à "concevoir une boucle".
Un processus de libération progressive des mains humaines.

En réalité, bien que cette notion de loop vienne tout juste de devenir populaire dans l'industrie, le monde académique en avait déjà des concepts similaires.
Et beaucoup de travaux importants sont liés à une personne que nous connaissons aujourd'hui : Yao Shunyu (celui de Tencent).
L'un de ses travaux les plus représentatifs dans le domaine des Agents de grands modèles est le framework ReAct (Reason+Act) en 2022.
Ce travail a obtenu le niveau Oral à l'ICLR 2023 et a ensuite été cité des milliers de fois.
ReAct a fait une chose cruciale : lier le "raisonnement" et l'"action" en un processus cyclique.
Le grand modèle ne produit plus une réponse unique. Il raisonne d'abord de manière explicable, puis utilise des outils pour exécuter des actions, observe ensuite les retours de l'environnement, et entre dans un nouveau cycle de raisonnement. Abstrait, cela donne :
Penser → Agir → Observer → Repenser → Réagir...
Cette structure est essentiellement la première forme systématique d'"agent loop".
Après ReAct, cette voie s'est constamment élargie. Par exemple, Reflexion a introduit un mécanisme de retour d'apprentissage à partir des erreurs, Tree of Thoughts s'est étendu en un raisonnement de recherche multi-chemins, et une série de travaux ultérieurs sur les Agents utilisant des outils ont progressivement perfectionné la chaîne complète "planification + exécution + feedback".
Ces avancées académiques ont progressé petit à petit, pour finalement converger dans le monde de l'ingénierie vers les "systèmes de loop" dont on parle aujourd'hui.
D'un point de vue académique, le loop n'est donc pas l'invention d'une seule personne, c'est un chemin technologique qui converge progressivement.
Simplement, sur ce chemin, un chercheur chinois que nous connaissons se trouvait à un point nodal clé.
Enfin, il est impossible de ne pas admettre que des prompts aux loops, le développement de l'IA est tout de même trop rapide.
Trop rapide a pour conséquence que certains sont excités, tandis que d'autres ne peuvent cacher leur inquiétude.
Et Addy Osmani, le responsable ingénierie de Google qui a nommé le Loop Engineering, fait partie de ces derniers.
Dans son long article "Loop Engineering", il écrit très clairement :
C'est encore très tôt. Je reste prudent. Vous devez être très attentif au coût des tokens.

Les paroles de Karpathy sont encore plus profondes. Il a cité lors de la conférence Sequoia Capital AI Ascent 2026 une phrase qu'il a lui-même souvent repensée :
Vous pouvez externaliser votre pensée, mais vous ne pouvez pas externaliser votre compréhension.
Traduisons : l'IA peut penser à votre place, mais vous devez vraiment comprendre le problème vous-même.
C'est probablement la voix la plus lucide de toute cette frénésie autour des loops.
Références :
[1]https://x.com/i/trending/2068190968809980300
[2]https://x.com/addyosmani/status/2064127981161959567
Cet article provient du compte WeChat "Quantum Bit", auteur : Yishui





