Le domaine de la génération d'images à partir de texte est depuis longtemps un champ de bataille ultra-compétitif, semblant à bout de souffle.
Pour entraîner aujourd'hui un modèle performant de génération d'images à partir de texte, de quoi avez-vous besoin ?
Si l'on part des solutions principales actuelles, cela nécessite : un encodeur-décodeur VAE pré-entraîné, la concaténation d'encodeurs de texte, des mécanismes d'injection de conditionnement soigneusement conçus, des masses de données, une étape d'alignement par RL ou DPO...
Globalement, tout le monde semble admettre un postulat de départ : pour faire de la génération d'images à partir de texte, cela doit être aussi complexe.
L'équipe de Kaiming He a pris le contre-pied de cette approche, apportant une nouvelle réflexion dans le domaine des modèles de génération d'images à partir de texte. Ils ont publié MiniT2I —— un modèle de génération d'images à partir de texte dans l'espace des pixels délibérément conçu pour être minimaliste.
Pas d'encodeur-décodeur VAE, pas d'injection de conditionnement AdaLN, pas de fonctions de perte auxiliaires, pas de données privées, pas d'alignement RL/DPO, un objectif pur de « flow matching » entraîné directement sur les pixels. La version B/16 à 258M de paramètres atteint 0.87 sur GenEval et 84.2 sur DPG-Bench, surpassant les modèles comparables dans l'espace des pixels ayant plusieurs fois plus de paramètres.

La proposition centrale de MiniT2I est la suivante : si l'on considère la condition textuelle comme des « tokens de contexte avec des informations sémantiques » injectées dans le modèle, la génération d'images à partir de texte et la génération conditionnée par classe sur ImageNet ne sont pas fondamentalement si différentes —— l'architecture peut être similaire, la puissance de calcul comparable, et même le volume de données peut être aligné.

- Titre de l'article : A Minimalist Baseline for Text-to-Image Generation
- Blog technique : https://peppaking8.github.io/#/post/minit2i
- Dépôt open-source : https://github.com/PeppaKing8/minit2i-jax
Parcours technique : À chaque étape, on simplifie
Sortie directe dans l'espace des pixels, pas de VAE
Le premier choix de conception de MiniT2I est très radical : se débarrasser du VAE et effectuer directement le débruitage sur les pixels RGB.
Les modèles de diffusion latente (Latent Diffusion) sont le paradigme dominant actuel : ils compriment d'abord l'image dans un espace de faible dimension avec un auto-encodeur avant d'effectuer la diffusion. Cela rend effectivement les hautes résolutions réalisables, mais au prix de l'introduction d'erreurs de reconstruction, d'une étape d'entraînement supplémentaire, et de problèmes de non-alignement des objectifs entre l'encodeur et le débruiteur.
La raison pragmatique du choix de l'espace des pixels pour MiniT2I est la suivante : pour une résolution de 512×512, en utilisant des patchs de 16×16 pour découper l'image en 1024 tokens, la longueur de séquence est parfaitement dans la zone de confort d'un Transformer. Sans VAE, le calcul pour une passe avant passe de ~1379 GFLOPs à ~570 GFLOPs (configuration B/16), et il n'y a plus de plafond de précision de reconstruction —— la qualité de sortie est aussi bonne que les capacités du débruiteur.
L'expérience le confirme : à budget de paramètres équivalent, le FID du modèle pixel est égal à celui du modèle espace latent (18.7 vs 19.0), mais le coût par pas est 5 fois inférieur.

Architecture MM-JiT : Retour au Transformer simple
Le MM-DiT de SD3 utilise AdaLN (Adaptive Layer Normalization) dans chaque bloc pour injecter le pas de temps et l'encodage textuel moyenné dans le réseau —— chaque sous-bloc doit calculer les paramètres scale, shift et gate via un MLP supplémentaire généré à partir du vecteur conditionnel. C'est un mécanisme de modulation sophistiqué, mais MiniT2I a constaté qu'il n'était pas indispensable.
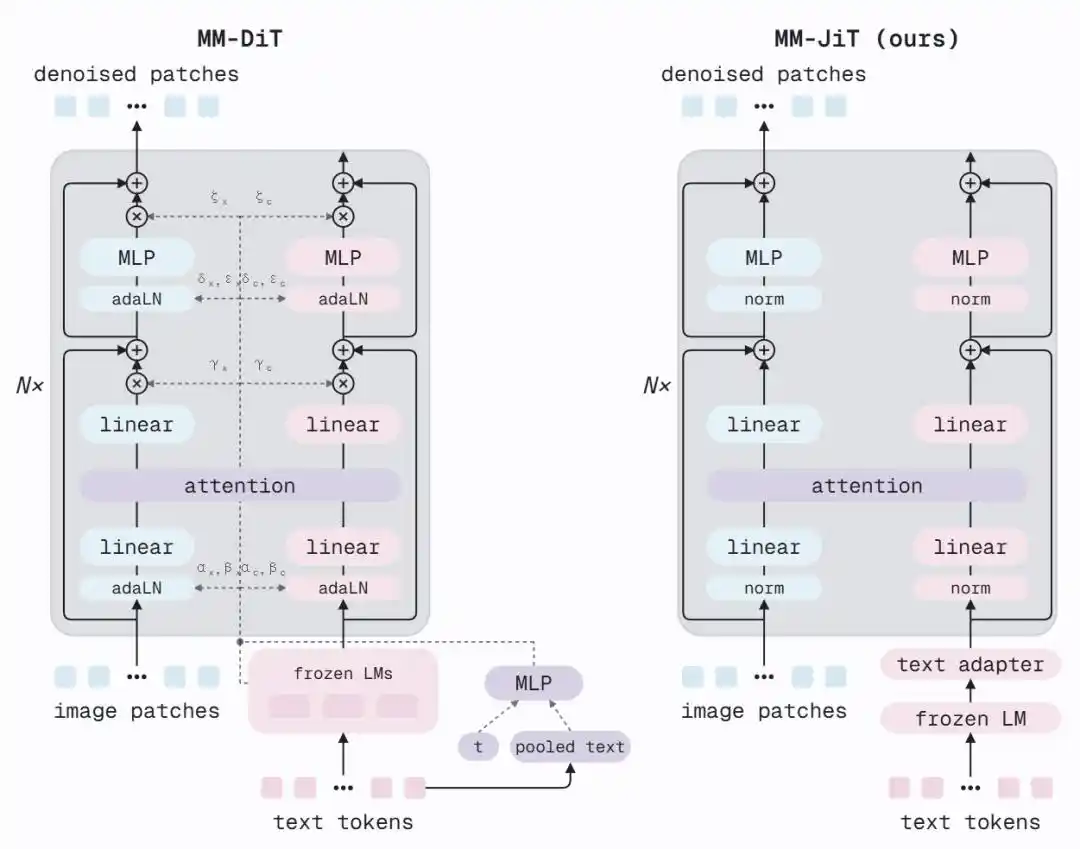
L'architecture MM-JiT proposée par MiniT2I fait deux choses :
1. Ajouter deux adaptateurs de texte : Insérer deux blocs Transformer légers avant l'attention conjointe, pour que les caractéristiques figées du T5 s'« adaptent » d'abord aux besoins du débruiteur.
2. Supprimer la branche AdaLN : Ne plus injecter le pas de temps et les informations textuelles globales par un chemin supplémentaire. Le modèle peut toujours percevoir le niveau de bruit —— car l'image contaminée par le bruit porte elle-même l'information du pas de temps.
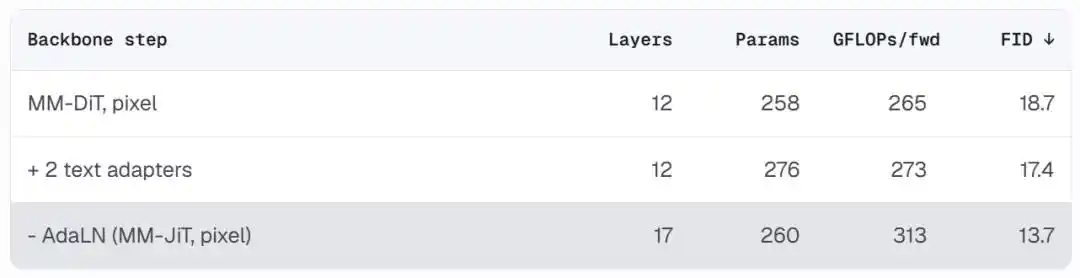
Le résultat est une architecture propre proche d'un Transformer standard avec pré-normalisation. Sans AdaLN, le nombre de paramètres diminue, mais on peut échanger le même budget de calcul contre plus de couches (12 couches → 17 couches). Le FID passe de 18.7 à 13.7, et l'architecture elle-même est plus facile à comprendre et à modifier.
Données d'entraînement : Toutes publiques, en deux phases
Les données d'entraînement de MiniT2I poursuivent également un idéal de minimalisme :
- Pré-entraînement : LLaVA-recaptioned CC12M (ensemble de données re-légendé par VLM, disponible publiquement), 250K pas.
- Fine-tuning : ~120 000 paires image-texte de haute qualité (BLIP3o-60K + jeu de données LAION DALL・E 3 Discord + ShareGPT-4o-Image), 40K pas.
Ce mode « pré-entraînement - fine-tuning » en deux phases s'aligne complètement sur le paradigme d'entraînement des LLM : le pré-entraînement assure la couverture, le fine-tuning enseigne au modèle ce qu'est une bonne réponse. Les ablations montrent que les deux sont indispensables —— avec seulement le pré-entraînement, la qualité d'image peut être bonne mais le suivi des prompts est médiocre ; avec seulement le fine-tuning, la vision du modèle est trop étroite, et la diversité de génération s'effondre.
Résultats : Petit modèle, grandes performances
Dans la comparaison entre modèles de génération d'images dans l'espace des pixels, le rapport qualité/prix de MiniT2I est extrêmement remarquable :
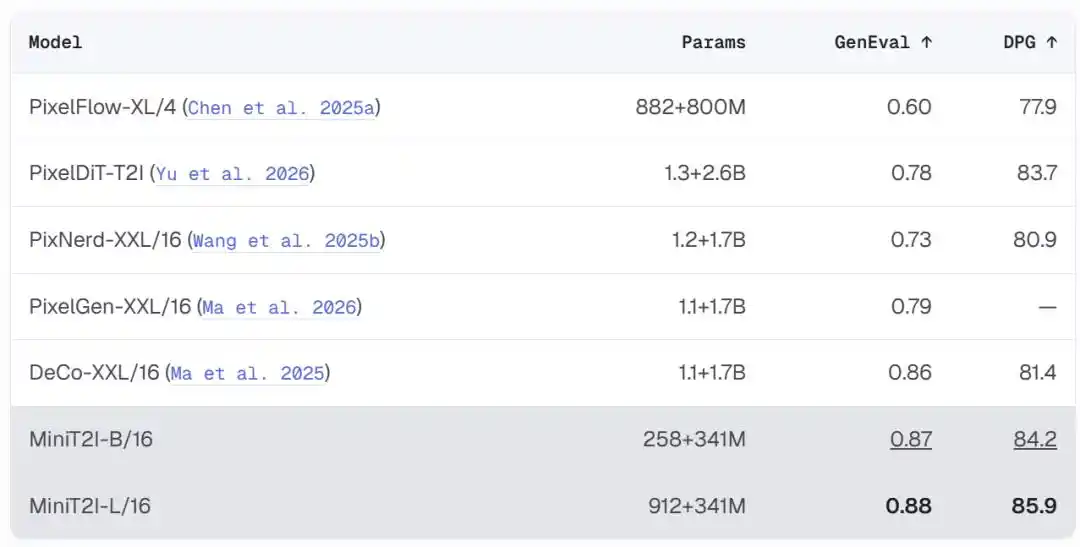
MiniT2I-B/16, avec seulement environ 600M paramètres totaux (incluant l'encodeur de texte), surpasse sur GenEval et DPG-Bench des modèles ayant 3 à 4 fois plus de paramètres. Et le coût d'entraînement est extrêmement bas : le modèle d'ablation B/32 nécessite seulement environ 3 jours sur 8 H100, et le total de FLOPs d'entraînement est équivalent à une expérience standard ImageNet de 200 époques.
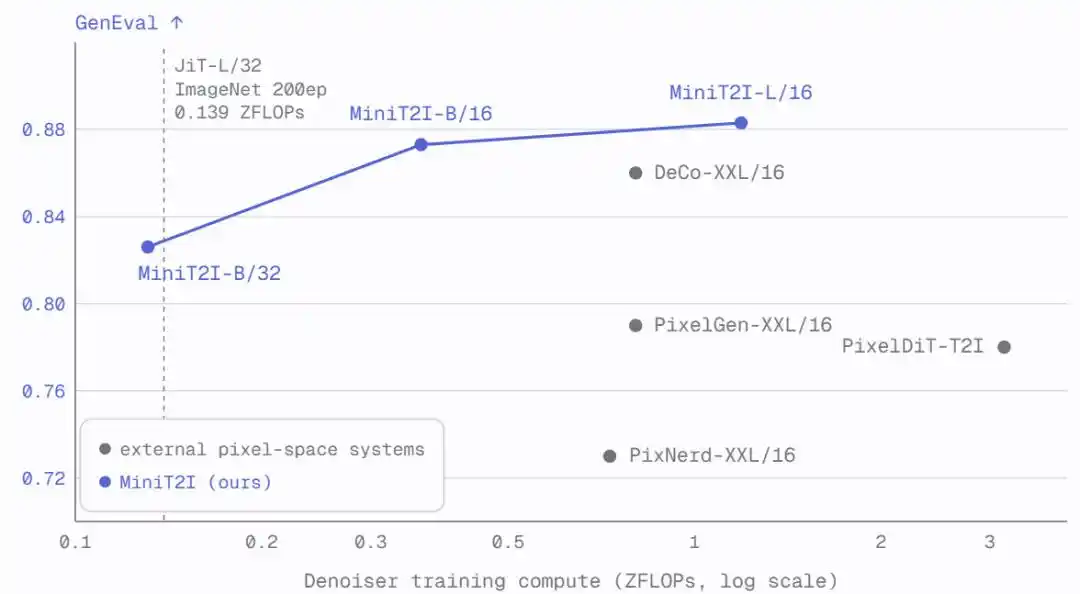
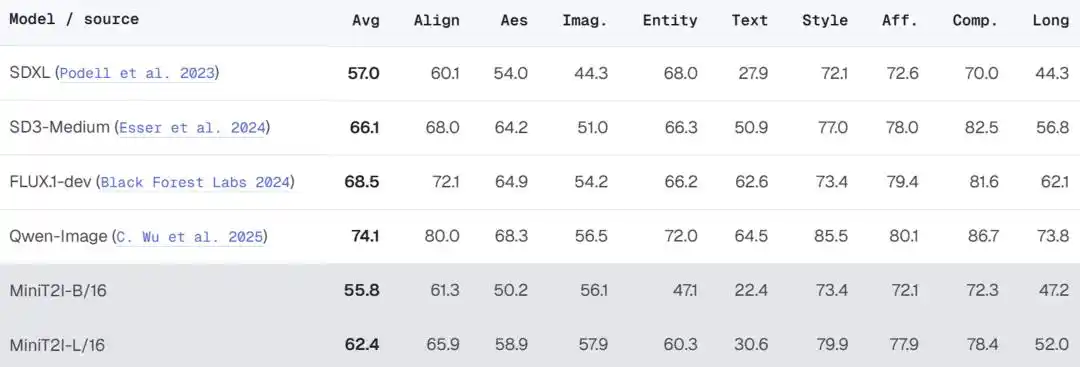
En passant à L/16 (912M paramètres), le modèle montre des progrès évidents en termes de diversité stylistique, relations spatiales et rendu du texte, avec une qualité de génération sur des scènes imaginatives équivalente voire supérieure à celle de SD3-Medium (~2B paramètres).
Dans l'évaluation plus complète de PRISM-Bench, MiniT2I-L/16 excelle dans les dimensions style, composition et imagination (79.9, 78.4, 57.9), approchant déjà le niveau de SD3-Medium. Mais il reste un écart pour le rendu du texte (30.6 contre 50.9 pour SD3) et les entités nommées (60.3 contre 66.3) —— l'équipe reconnaît honnêtement que c'est une limite inhérente à la formule de données publiques, nécessitant des données spécifiques supplémentaires pour la combler.
Limites et perspectives
MiniT2I est une preuve de concept d'une voie technique, pas un produit final. L'équipe indique honnêtement plusieurs problèmes non résolus :
- Artéfacts de patch dans l'espace des pixels : Il existe une discontinuité mesurable aux frontières des patchs (le gradient à la frontière est 17-22% plus élevé qu'ailleurs), ce que n'ont pas les modèles en espace latent.
- Effets secondaires du CFG dans l'espace des pixels : Un coefficient de guidage élevé (~6) pousse les tokens locaux hors de la variété des données, se manifestant directement comme des défauts visuels sans « lissage » par un décodeur.
- Plafond de résolution : Actuellement fonctionne bien en 512×512, passer à 4K+ nécessiterait des séquences plus longues ou des mécanismes d'attention plus efficaces.
- Goulot d'étranglement des données : Le rendu du texte et les entités nommées restent plus faibles que dans les systèmes industriels, nécessitant un renforcement par des données spécifiques.
MiniT2I prouve que la génération d'images à partir de texte à son stade actuel n'est pas un jeu réservé aux meilleurs laboratoires industriels.
Lorsqu'un modèle de 258M paramètres, utilisant uniquement des données publiques, entraîné pendant 3 jours avec une puissance de calcul académique, arrive à battre des adversaires plusieurs fois plus gros, peut-être que la génération d'images à partir de texte est en train de vivre un changement de paradigme, passant de « l'empilement de ressources » à « la purification ».
« La génération d'images à partir de texte n'est plus une forteresse inattaquable. Nous vous invitons à l'utiliser et à l'améliorer, pour créer des bases encore plus simples. »
Cet article provient du compte WeChat « Machine Heart » (机器之心)







