Il y a quelques instants, DeepSeek V4 a effectué une mise à jour.
Il a introduit un nouveau cadre de décodage spéculatif (Speculative Decoding) nommé DSpark, et a rendu open source en parallèle la pile complète du cadre de décodage spéculatif DeepSpec qui le soutient.
DeepSeek-V4-Pro-DSpark n'est pas un modèle architectural entièrement nouveau, mais plutôt DeepSeek-V4-Pro doté d'un module de décodage spéculatif. L'accent de cette mise à jour porte sur la mise en œuvre technique et non sur une évolution des capacités intrinsèques du modèle.
DSpark a déjà été déployé sur les flux de trafic en ligne réels de DeepSeek-V4 (Flash et Pro), accélérant considérablement la vitesse d'inférence des grands modèles de langage (LLM).

Rapport technique : « DSpark: Confidence-Scheduled Speculative Decoding with Semi-Autoregressive Generation »
Lien vers le rapport technique : https://github.com/deepseek-ai/DeepSpec/blob/main/DSpark_paper.pdf
L'objectif central de DSpark est de résoudre les goulets d'étranglement de latence et de débit auxquels est confrontée l'inférence des LLM dans des environnements de production (en particulier dans des scénarios à forte concurrence). En bref, DSpark combine avec succès une « génération parallèle » à haut débit avec une « validation adaptative à la charge ».
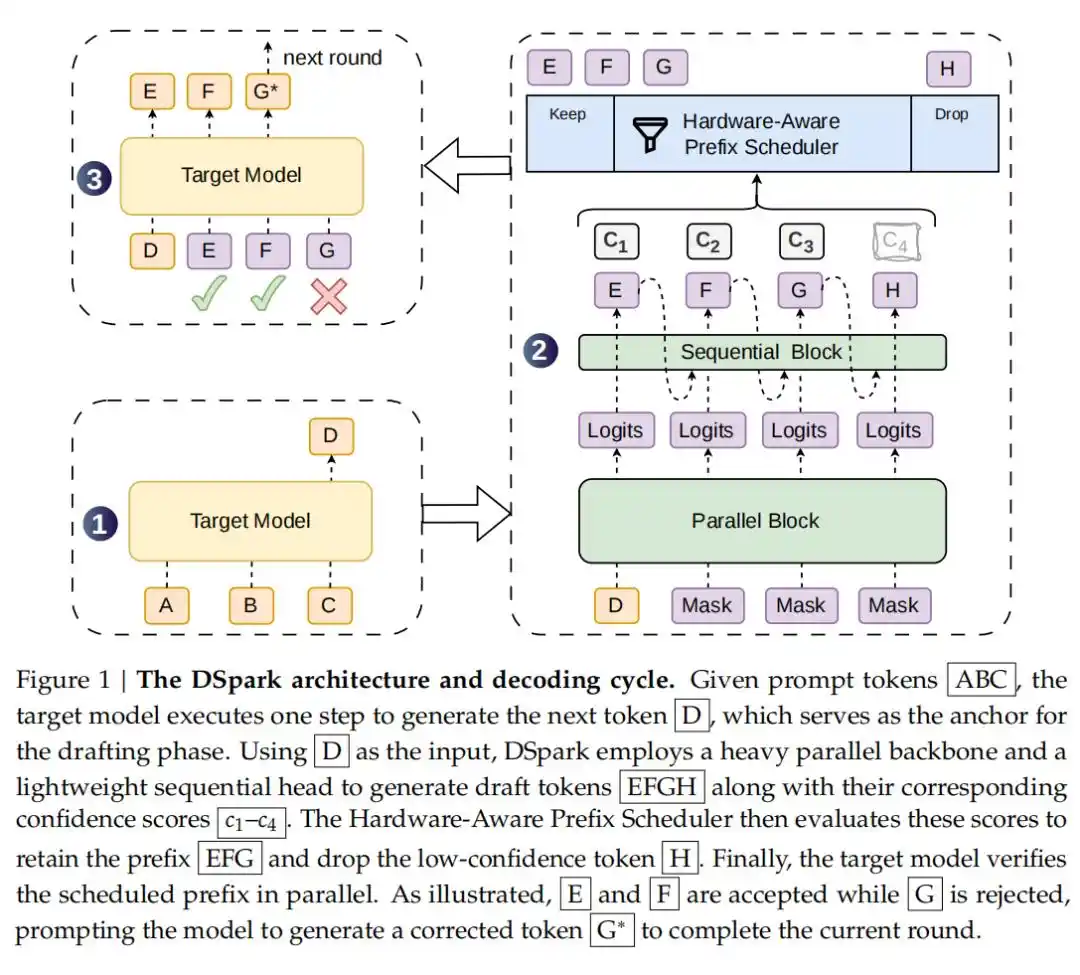
Le décodage spéculatif est une technique qui accélère l'inférence des grands modèles de langage sans modifier leur distribution de sortie. L'idée principale est d'introduire un « modèle de brouillon » (draft model) léger, qui prédit plusieurs tokens candidats, puis de faire valider et accepter par lots ces candidats par le modèle cible (target model). Cela transforme la génération token par token séquentielle en une vérification par lots parallèle, réduisant considérablement la latence de bout en bout.
Sur cette base, l'innovation de DSpark réside dans l'introduction d'une architecture de génération semi-autorégressive (Semi-Autoregressive Generation) : elle conserve l'avantage du haut débit du modèle de brouillon parallèle, tout en ajoutant un module séquentiel léger qui modélise les dépendances entre les tokens à l'intérieur d'un bloc, afin d'atténuer le problème de la dégradation du taux d'acceptation que rencontre souvent le modèle de brouillon parallèle pour les positions ultérieures.
En outre, il y a la vérification planifiée par confiance avec conscience matérielle (Confidence-Scheduled Verification) : les approches précédentes de décodage spéculatif envoyaient souvent tous les tokens de brouillon générés pour validation de manière aveugle. En cas de charge système élevée, ces derniers tokens, très susceptibles d'être rejetés, gaspillaient sérieusement la précieuse puissance de calcul du traitement par lots. DSpark introduit une tête de confiance (Confidence Head) pour évaluer la probabilité de survie de chaque token. En combinaison avec un planificateur de préfixe conscient du matériel, le système peut, en fonction des caractéristiques de débit en temps réel du moteur, définir dynamiquement la longueur de validation optimale pour chaque requête, en allouant la puissance de calcul uniquement aux tokens ayant la meilleure récompense attendue.
Pour être déployé dans une infrastructure en ligne réelle, le planificateur de DSpark adopte un mécanisme asynchrone, compatible avec le « zéro-overhead scheduling » (ZOS) et la relecture continue de graphes CUDA. Il utilise les prédictions historiques des deux étapes précédentes pour décider de la longueur de troncature dynamique actuelle, masquant ainsi la latence de planification, évitant les pauses dans le pipeline GPU, tout en garantissant une restitution parfaite et sans perte de la distribution de sortie du modèle cible.
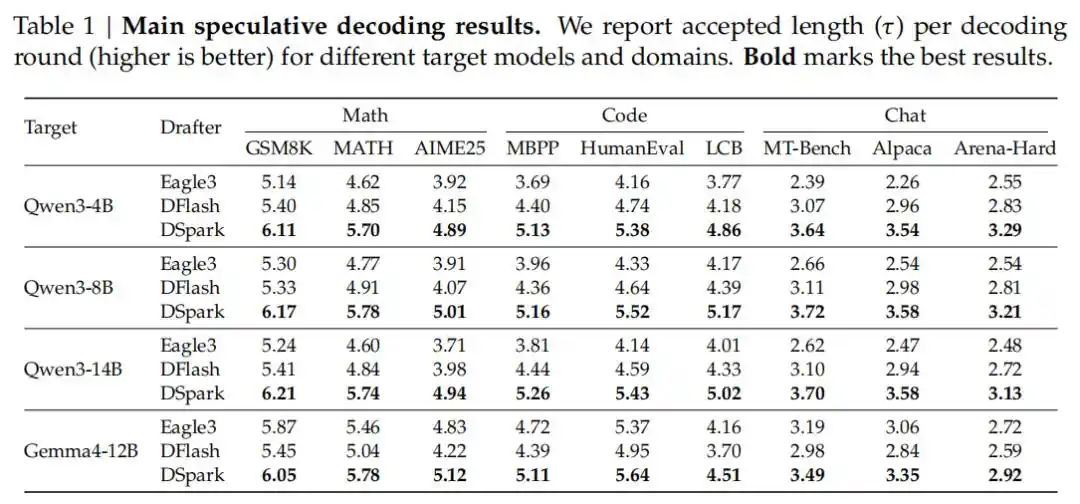
Dans des tests couvrant plusieurs domaines comme le raisonnement mathématique, la génération de code et les dialogues quotidiens, DSpark a largement surpassé les modèles autorégressifs (Eagle3) et les modèles de brouillon parallèles (DFlash) les plus avancés actuels. Par exemple, sur des modèles cibles de la série Qwen3 (4B, 8B, 14B), la longueur moyenne d'acceptation a été améliorée de 26,7 % à 30,9 % par rapport à Eagle3, et de 16,3 % à 18,4 % par rapport à DFlash.
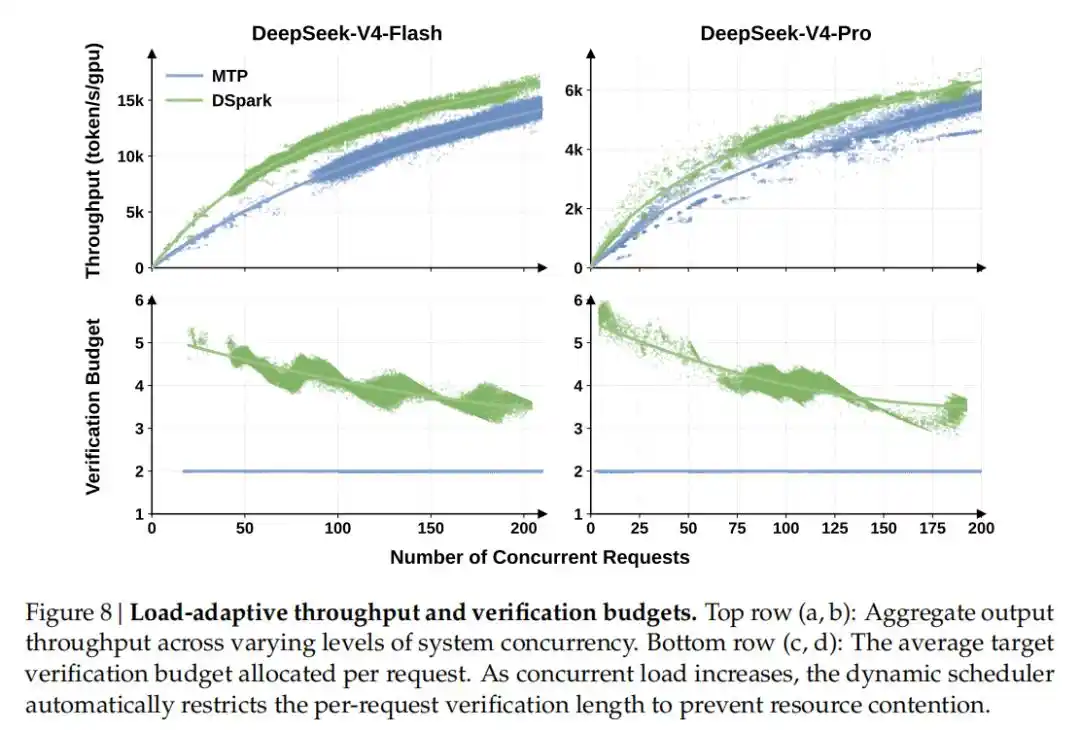
Par rapport à la référence de production single-token précédemment déployée (MTP-1), tout en maintenant le même débit global, DSpark a augmenté la vitesse de génération pour les utilisateurs de 60 % à 85 % (modèle Flash) et de 57 % à 78 % (modèle Pro).
Outre DSpark, DeepSpec a également été rendu open source. Il s'agit d'une base de code complète pour entraîner et évaluer les modèles de brouillon pour le décodage spéculatif. C'est « l'infrastructure open source » qui porte cette solution ainsi que d'autres implémentations d'algorithmes de pointe, comprenant des outils de préparation de données, des implémentations de modèles de brouillon, du code d'entraînement et des scripts d'évaluation.
DeepSpec divise le flux global en trois phases : préparation des données, entraînement et évaluation. Les trois phases doivent être exécutées dans l'ordre, les sorties d'une phase servant d'entrées à la suivante.
Lors de la phase de préparation des données, il faut télécharger les données de prompts, regénérer les réponses en utilisant un moteur d'inférence sur le modèle cible, et construire un cache cible (target cache). Il est à noter qu'avec la configuration par défaut de Qwen/Qwen3-4B, le volume du cache cible peut atteindre environ 38 To ; une évaluation adéquate des ressources de stockage est nécessaire avant utilisation.
La phase d'entraînement peut être lancée via `bash scripts/train/train.sh`. Ce script appellera `train.py` et lancera un worker pour chaque GPU visible. Les utilisateurs peuvent choisir différentes configurations d'algorithmes et de modèles cibles dans le répertoire `config/` en spécifiant `config_path`. Le projet permet également d'ajuster les paramètres d'entraînement en modifiant `config_path`, `target_cache_dir`, ainsi qu'en utilisant `--opts` pour modifier un champ de configuration individuel.
En termes de matériel, la configuration et les scripts par défaut de DeepSpec sont conçus pour un environnement à un seul nœud avec 8 GPU. Si le nombre de GPU est inférieur, l'utilisateur doit réduire en conséquence le nombre de GPU visibles dans `CUDA_VISIBLE_DEVICES`.
La phase d'évaluation est lancée via `bash scripts/eval/eval.sh`. Le script d'évaluation utilisera le checkpoint du modèle de brouillon entraîné pour mesurer les acceptations sur plusieurs tâches de référence de décodage spéculatif. Les ensembles de données d'évaluation actuellement listés dans le projet incluent GSM8K, MATH500, AIME25, HumanEval, MBPP, LiveCodeBench, MT-Bench, Alpaca et Arena-Hard-v2, couvrant différents types de tâches comme le raisonnement mathématique, la génération de code, les capacités de dialogue et les questions-réponses générales.
En termes d'algorithmes, DeepSpec inclut actuellement trois modèles de brouillon : DSpark, DFlash et Eagle3. En ce qui concerne les familles de modèles cibles, le projet prend actuellement en charge Qwen3 et Gemma.
La mise en open source de DeepSpec intègre la pratique technique du décodage spéculatif, auparavant dispersée au sein de différentes équipes de recherche, en un ensemble standardisé d'outils reproductible et extensible. Pour les chercheurs et ingénieurs souhaitant accélérer l'inférence de leurs propres grands modèles, cela signifie qu'ils peuvent directement entraîner des modèles de brouillon personnalisés sur un cadre mature, en sautant une grande partie du travail de construction d'infrastructure de base répétitif.
Liens de référence :
https://github.com/deepseek-ai/DeepSpec/blob/main/DSpark_paper.pdf
https://github.com/deepseek-ai/DeepSpec
Cet article est issu du compte WeChat public « Machine Heart » (ID:almosthuman2014), auteurs : Zenan, Yang Wen





