This summer, Musk is going to do something unprecedented in history. Taking a large language model company and packing it into a rocket company, then taking them public together.
The last thing OpenAI should do right now is probably make a phone. But Sam Altman doesn't seem to think so.
In the first quarter of this year, OpenAI's revenue and user growth both fell short of expectations. Its rival Anthropic, with Claude Code, snatched away the group most willing to pay. Following this script, OpenAI should now be consolidating, focusing, and first proving it can make money, gearing up for an IPO by the end of this year or early next.
But the supply chain tells a different story. It's going to challenge the world's most mature, most closed, and most profitable consumer electronics category: the iPhone.
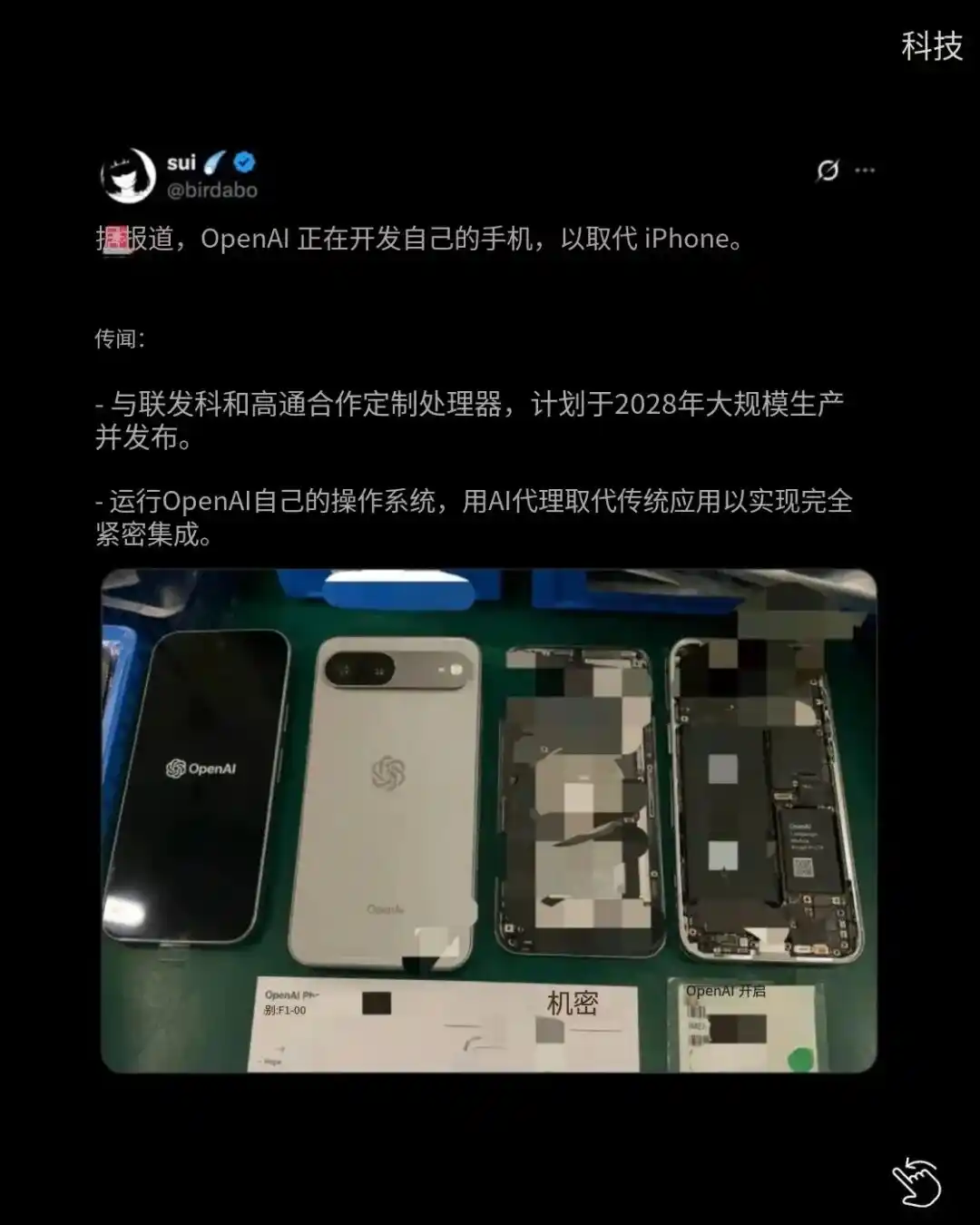
According to leaks, OpenAI is accelerating development of its first AI Agent phone, with mass production as early as the first half of 2027 and a target of shipping 30 million units over the next two years.
Is it crazy?
Probably not. OpenAI has likely already seen a more dangerous problem clearly: ChatGPT is smart, but it doesn't have hands.
It can answer you, but it has a hard time completing tasks for you. It lives in other people's systems—Apple's, Microsoft's, operating systems, browsers—so it can't get the real permissions.
What we want to discuss next isn't why OpenAI wants to build a phone. It's how this company came to realize, step by step, that without its own terminal device, ChatGPT can never truly break free.
ChatGPT's Success is Also a Form of Path Dependency
In April 2026, SpaceX secured an option: it could acquire Cursor for up to $60 billion later in the year.
OpenAI's initial belief wasn't in phones, browsers, or any particular App. It believed in the model—or more precisely, in intelligence itself.
In its worldview, as long as the model is powerful enough, the entry point, product, and business model will all be pushed forward by intelligence.
This wasn't just talk. In 2020, OpenAI published the later frequently cited Scaling Laws paper, establishing a relatively optimistic belief: by scaling up the model, data, and compute together, intelligence would improve in a predictable way.
In other words, the most important thing wasn't to grab an entry point first, but to make the model even stronger. With strong enough intelligence, the world would naturally make way.
This belief was realized on November 30, 2022.

That day ChatGPT launched. It had no flashy interface, no hardware, no platform pre-installation, just an input box on a webpage. But it gave ordinary people an experience they'd never had before: you type a sentence, and it replies like a human.
The awe wasn't just that AI could talk, but that it had barely relied on any traditional entry point. No phone manufacturers pushed it, no operating system placed it in a prominent spot; users found it themselves.
Two months, 100 million monthly active users—the fastest-growing consumer application in human history.
OpenAI seemed to be right. Microsoft immediately doubled down, embedding its capabilities into Copilot, Office, and Bing; Apple also integrated ChatGPT into Apple Intelligence at WWDC 2024.
At that moment, OpenAI stood at the center of the era. The strongest model, the most users, the deepest partnerships.
But that's precisely where the problems started.
ChatGPT's success was too dazzling. So dazzling that it easily made OpenAI believe: the model itself is the entry point. It didn't need to own a phone first, nor control an operating system first—if the intelligence was impressive enough, users would come find it.
The real cracks that emerged later also started here.
Claude Code Rewrote the Rules of Monetization
The first crack came from Anthropic.
In May 2025, it released Claude Code. No flashy demo, no blockbuster launch event. This product simply entered developers' terminals, codebases, and Git workflows, helping engineers get the job done.
Six months after launch, Claude Code reached a $1 billion annual run rate; in less than a year, over $2.5 billion. By April 2026, Anthropic's overall annualized revenue crossed $30 billion.
Meanwhile, OpenAI was at $2 billion monthly revenue, or roughly $24 billion annualized.
Anthropic achieved higher revenue with far fewer users than ChatGPT. This is what OpenAI should truly be worried about.
The reason is simple—it captured a group of people most willing to pay.
The question is, why was OpenAI a step slower?
Not because it couldn't see Agents. It was because ChatGPT's success was too dazzling, so dazzling that OpenAI continued moving forward with its original inertia: make a stronger model, expand the user base, find the next universal entry point.
So over these past two years, you've seen OpenAI attempt many 0-to-1 projects—GPT Store, Sora, Operator, Deep Research—all born from this line of thinking. They collectively point to one judgment: as long as the model is strong enough, new products, new entry points, new business models will naturally emerge.

But Anthropic chose a different path. It didn't first create a super entry point for everyone. Instead, it nailed Claude Code into developers' workflows, repeatedly polishing one thing—letting AI finish the job.
This is where OpenAI was slow. It wasn't that it didn't make new products, but that it didn't immediately take a high-paying-use-case scenario from 1 to 100.
Sora is a classic example. It stunned the world upon release, but video generation consumed vast amounts of compute, and user retention and the business model weren't clear enough. When OpenAI later shut down Sora, it was, in a sense, a pruning—it began to realize that creating a stunning AI demo and penetrating a high-value workflow are two different things.
Model capabilities can create highlights, but commercial efficiency comes from consistently delivering results.
At this point, OpenAI finally realized: Agent isn't an add-on feature; it's the core of the next phase of AI commercialization. ChatGPT can't just prove it's smart; it must prove it can complete tasks for users.
But when it truly starts taking over tasks, what it hits isn't the ceiling of model capability, but the ceiling of permissions.
900 Million Users, How to Turn Them into Money
OpenAI is, of course, catching up. In May 2025, it launched Codex, directly responding to Claude Code. By April 2026, Codex reached 3 million weekly active users.
But in the coding battle, OpenAI will find it hard to win back in the short term—Anthropic has already captured the mindshare for coding Agents, leaving the follower to play catch-up.
This is also why OpenAI began reallocating resources: shifting attention from projects that easily create hype but struggle to achieve commercial closure, towards Agents, the enterprise market, and more fundamental research.
But what it really needs to look at is its bigger card—900 million weekly active users.
These people aren't programmers; they won't pay for code. But they all have needs: writing emails, making proposals, researching, booking travel, shopping, organizing files.
If ChatGPT can evolve from a "conversational" entry point to a "task-completing" entry point, that would be OpenAI's true commercial capability.
Imagine this scenario: you want to buy a plane ticket, tell ChatGPT the time, budget, preferences. It searches flights, compares prices, checks hotels for you, and finally gives you a confirmation button.
At that moment, part of Ctrip's value is bypassed. Price comparison, ad slots, commissions, user decision influence—all would be redistributed. Buying insurance, paying credit card bills, settling utility bills follow the same logic. As long as the Agent can complete tasks for you, OpenAI has a chance to take a cut of every transaction commission, every advertising influence within.
This is where the true value of 900 million users lies—ChatGPT no longer just answers questions, but starts taking over task and transaction entry points.
But once AI starts handling tasks, it's no longer just a model in a chatbox. It needs to know where you are, see what's happening on your screen, and access your files, calendar, emails, and payments.
The problem thus shifts from "Is the model strong enough?" to "Who has the permissions?"
And permissions are precisely what OpenAI lacks.
ChatGPT Lives in Someone Else's House
OpenAI initially thought partnerships could solve the entry point problem. Apple gave it the iPhone, Microsoft gave it Office, Windows, and enterprise customers. At the time, this looked like a victory for OpenAI's faith in models.
But with the advent of the Agent era, the problem changed.
In Apple's world, ChatGPT is an external expert that gets called upon. It can answer questions, but it cannot truly take over the screen, camera, notifications, payments, and files—Apple won't hand over these permissions. Otherwise, the iPhone's "soul" would no longer belong to Apple.
It's similar with Microsoft. In the past, OpenAI provided the model, and Microsoft was responsible for integrating AI into entry points like Office. But when OpenAI itself started making Codex and enterprise Agents, it stepped onto Microsoft's turf—Agents inherently enter workflows, write code, process files, and complete tasks for employees, which is exactly the core of Microsoft's sovereignty.
So, the relationship between OpenAI and Microsoft hasn't broken immediately, but the boundaries have shifted. In April 2026, the two parties renegotiated their agreement, with Microsoft's exclusive licensing becoming non-exclusive, allowing OpenAI to serve customers on any cloud.
The meaning of this is clear: OpenAI doesn't want to be just a supplier within the Microsoft ecosystem. It wants to face customers itself, deliver Agents itself, and capture entry points itself.
At this point, its relationships with Apple and Microsoft become delicate. Because what an Agent needs isn't a showcase spot, but the default entry point, system permissions, and the intelligent terminal the user interacts with first every day.
These things, Apple won't give, and Microsoft won't either. They can't.
Ultimately, ChatGPT is strong, but it always lives in someone else's house—Apple's house, Microsoft's house, the browser's house, the operating system's house. It can be called upon, integrated, and be a great supplier, but it can't decide when it appears, nor what permissions it gets.
And the phone is the one closest to its resource endowment. 900 million weekly active users are already willing to hand questions to ChatGPT—migrating this mindset to a device is a shorter path than building an operating system or a browser from scratch.
It's not trying to make another iPhone filled with Apps, but a phone dedicated to Agents—a body that allows ChatGPT to see, call upon, and execute tasks.

This is also why in May 2025, OpenAI spent approximately $6.5 billion to acquire Jony Ive's hardware company. This person is the industrial designer of the original iPhone, one of the most important figures beside Steve Jobs. OpenAI sought him not just to make a beautiful piece of hardware, but to redefine personal devices for the AI era.
Returning to the opening question: why would a large language model company make a phone?
What OpenAI wants isn't a phone; it's sovereignty.
It wants to find a default entry point that belongs to ChatGPT itself. But making a phone essentially pushes OpenAI into direct opposition with Apple. In the past, Apple could treat ChatGPT as a supplier; if OpenAI truly makes a phone for the AI era, it's no longer a supplier but a competitor to Apple for personal entry points.
Looking back over these past few years, OpenAI's story has actually undergone a reversal.
It once believed that if the model was strong enough, the world would actively reorganize itself around intelligence. ChatGPT's explosion did prove this—it had no hardware, no pre-installation, just a webpage input box, and pulled hundreds of millions of users into the AI era.
But when the Agent era arrived, OpenAI found it still lacked the most crucial thing: sovereignty.
ChatGPT's success was a victory, but also a form of path dependency. It made OpenAI believe for too long that the model itself was the answer. It wasn't until Claude Code reached a $2.5 billion annual run rate, and until Apple and Microsoft were unwilling to hand over system permissions, that OpenAI realized: no matter how strong the model is, it still needs to capture the entry point, permissions, and tasks.
So, when OpenAI makes a phone, what it truly wants to make isn't a phone; it's ChatGPT's first body.
This article is from the WeChat public account "Pixel 301", author: Pixel 301






