作者:Tyler
最近看了成龙大哥的口碑新作《捕风追影》,里面有个桥段挺有意思——上百亿港币的加密资产,被锁在一个 12 个单词的助记词钱包里,结局只剩最后一个单词未知。
我看完去试了下,结果发现第 10 位和第 12 位并不在标准助记词库里,显然编剧是故意这么写,避免有人照着剧情复原钱包搞诈骗,毕竟链上类似的骗局并不罕见:
骗子会故意泄露一个「带余额」的钱包地址(典型在 Tron 链上,利用 Owner 机制),诱导大家转入 Gas,守株待兔,资金一旦转入就再也拿不回来了。

但这里有趣的一点在于,电影里说只差最后一个单词不知道。可在真实世界里,助记词遵循 BIP39 标准,一共就 2048 个单词,也就是说,暴力破解最后一位,顶多也就 2048 种可能,如果再缩小范围,比如电影中已知开头字母是「es」,那可能性更少,一分钟就能试完。
不过,电影之外更值得重温的问题是:助记词、私钥、公钥,到底是什么关系?为什么丢了助记词就等于丢了所有资产?
一、助记词:私钥:公钥/地址 = 「钥匙串」:「钥匙」:「门牌号」
助记词是遵循 BIP39 标准的备份方式,从 2048 个英文单词的词库中,通过算法随机选取并组合而成的 12、18 或 24 个单词。
这组助记词经过 PBKDF2 算法处理后,会生成一个种子(Seed),再由这个 Seed 按照 BIP32/BIP44 等路径标准,派生出一系列私钥,进而对应一系列的公钥/地址。
一组助记词 → 生成一系列私钥 → 生成一系列公钥 → 对应一系列地址
换句话说:
-
助记词 = 钥匙串,和私钥往往是一对多的关系,理论上一组助记词可以衍生出成千上万个私钥;
-
私钥 = 钥匙,每一把私钥对应一个地址的使用权;
-
公钥/地址 = 门牌号,可以公开,别人能用它给你转账;
所以可以将助记词视为你的「钥匙串」,而每个私钥就像其中一把能开门的钥匙,用来签名、证明你对某个钱包地址的控制权——当你发起一笔交易时,就是用私钥来签名,告诉全网:「这笔转账是我授权的」。
二、那能不能自己挑选助记词?
那是不是有朋友就会觉得:我能不能自己来凑 12 个单词?比如生日、最喜欢的英文单词、偶像名字,这样更有个性。
答案是:可以,但极度危险。
因为计算机生成的随机数是真随机,而人类挑单词时几乎都带有模式(常见词、习惯用词、顺序偏好),这会大幅缩小搜索空间,让你的助记词更容易被猜中。
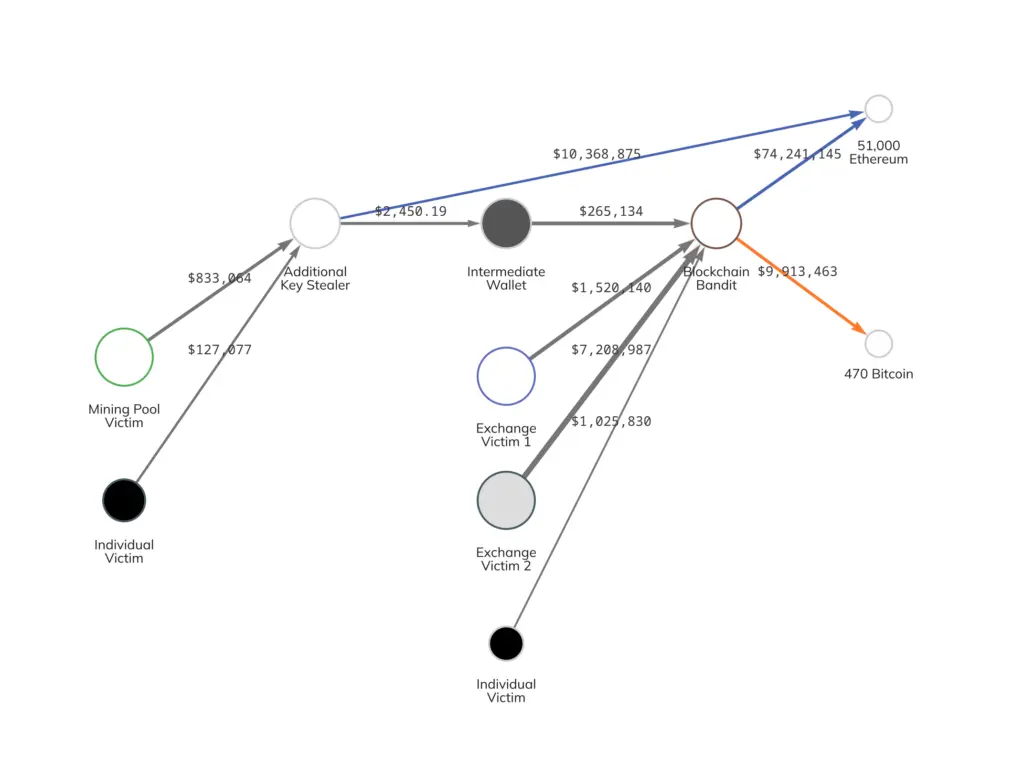
之前就出过「伪随机钱包」的安全事件,有些钱包生成助记词时使用了伪随机算法,结果熵远远不足,被黑客暴力遍历直接穷举破解——2015 年黑客组织 Blockchain Bandit 就利用故障的随机数生成器和程序码漏洞,系统性地搜寻弱安全私钥,成功扫出了 70 多万个脆弱钱包地址,并盗走了其中超过 5 万枚 ETH。
当然有些极客会用骰子(得确保骰子也足够均匀)摇随机数,再映射到 BIP39 单词库,这才算手工安全,但对大多数人来说,没必要搞这么复杂,反而容易出错。
三、能不能暴力撞出 V 神或其他巨鲸的钱包?
这个问题我当年也脑补过,幻想自己哪天生成了一个钱包地址,结果一看里边有上百万枚 ETH,瞬间财富自由,直接偷家某位巨鲸。
不得不说,光想就挺诱人。但现实是:概率几乎等于零。
为什么?因为助记词的可能组合数量已经夸张到超出人类想象:
-
12 个单词:有效组合数约 2¹²⁸ ≈ 3.4 × 10³⁸
-
24 个单词:有效组合数约 2²⁵⁶ ≈ 1.16 × 10⁷⁷
这个数量级是什么概念?
我们都知道地球上的沙子多到数不清,但科学家们估算过一个近似值,假设地球上的所有沙滩、沙漠加起来,沙子的总数大约是 7.5×10¹⁸ 粒,这也意味着:
-
12 个单词的有效组合数,相当于地球全部沙子总数的 4.5 × 10¹⁹ 倍
-
24 个单词的有效组合数,更是地球上沙子总数的 1.5 × 10⁵⁸ 倍
换句话说,就好像地球上每一粒沙子,都变成一颗「新地球」,每个新地球里还有沙滩和沙子,然后你要在所有这些沙子里,一次性随机找到你事先标记好的那一粒。
这已经远远超出人类可以想象的规模。

所以,暴力破解钱包的概率,不是「极低」,而是在已知的物理学和计算能力下,等同于零,想靠「撞库」发财,还不如去买彩票,中奖概率高得多。
回到电影的那个设定:如果真有人只差一个助记词单词,那确实有可能通过暴力遍历去尝试。
最后,关于钱包/助记词/私钥的几点安全小贴士:
-
优先使用经过时间和市场检验、开源代码审计的非托管钱包,如 MetaMask、Trust Wallet、SafePal 等,有条件的直接使用硬件钱包;
-
助记词和私钥,永远不要截图、不要存网盘、不要复制粘贴、不要发给别人;
-
最好纸笔抄写(可以考虑使用不锈钢助记词板,防潮、防火、防腐蚀),放在安全的地方,且 2~3 处多点备份;
-
公钥/地址可以放心公开,它就是你的门牌号,但要注意识别钓鱼链接;
-
建议用干净的设备管理钱包,不要随便装来历不明的插件或 App;
-
记住一句话:任何人向你要助记词,100% 是骗子。