Editor's Note: The following discussions are personal opinions and do not constitute investment advice. Information compiled from X.
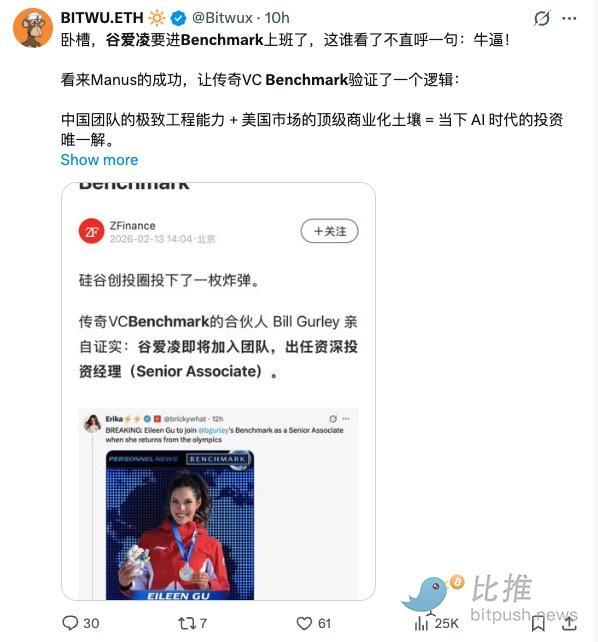
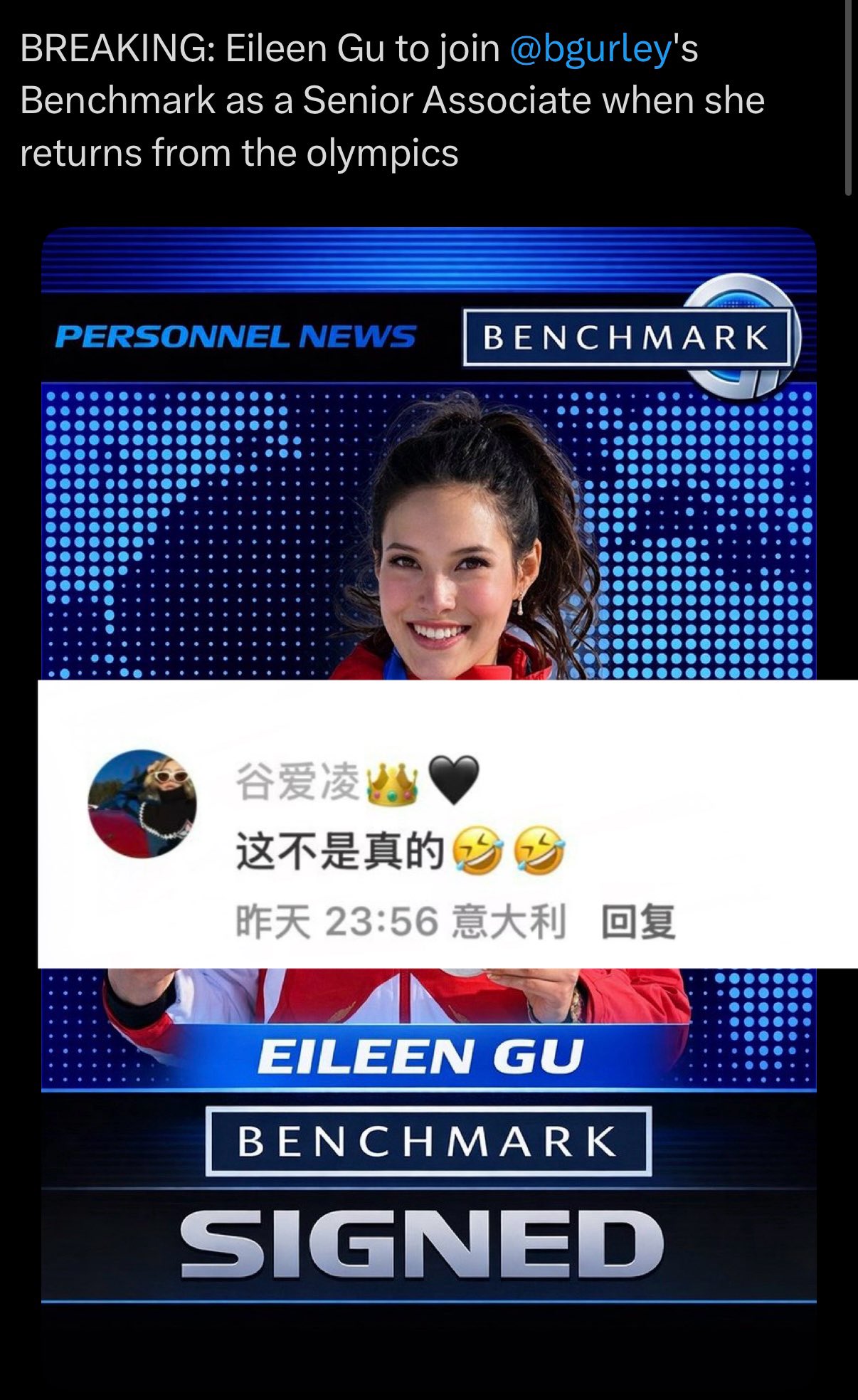
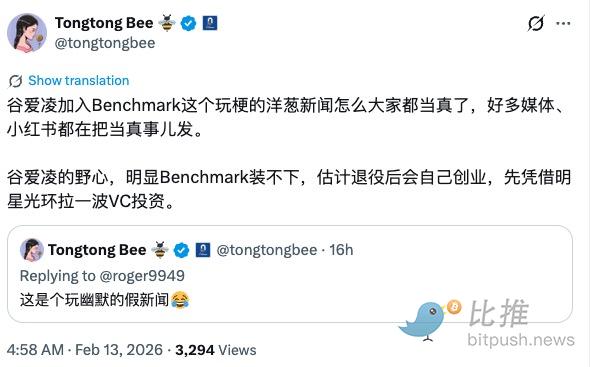
Eileen Gu Joining Benchmark? Fake!
Popular Replies:
Next step: HTX Co-CEO, TRON Global Ambassador lol
She's been getting roasted these past few days—criticized in Chinese circles, called out in English circles, one moment representing Americans, the next representing Chinese!
Fun fact: Eileen Gu is a U.S. citizen, and the U.S. government taxes globally. So, 40% of every dollar she earns in China goes to the U.S. government!
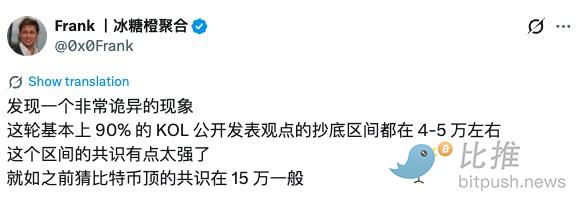
90% of KOLs' Bottom-Buying Range is $40K-$50K?
Popular Replies:
You're right on point. Actually, if it really drops to $40K-$50K, it would be reasonable. History is there, everyone gets it. The fear is if it drops to $20K-$30K or even lower—that would shatter all faith.
Hahaha, a couple of months ago they were shouting $60K. If it really drops to $40K-$50K, they'll start yelling $30K-$40K.
"Eight Years, Still $1900"—ETH Maximalists Collective Meltdown

Hong Kong Conference Essay Extravaganza




Pessimism Pervades the Industry—Some Flee, Others Hold Firm
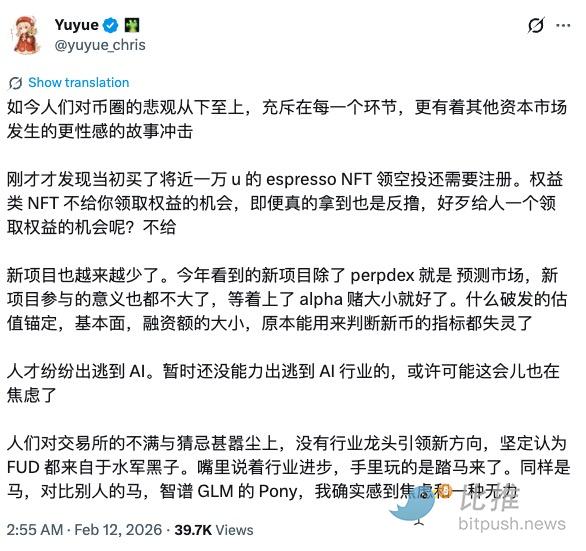
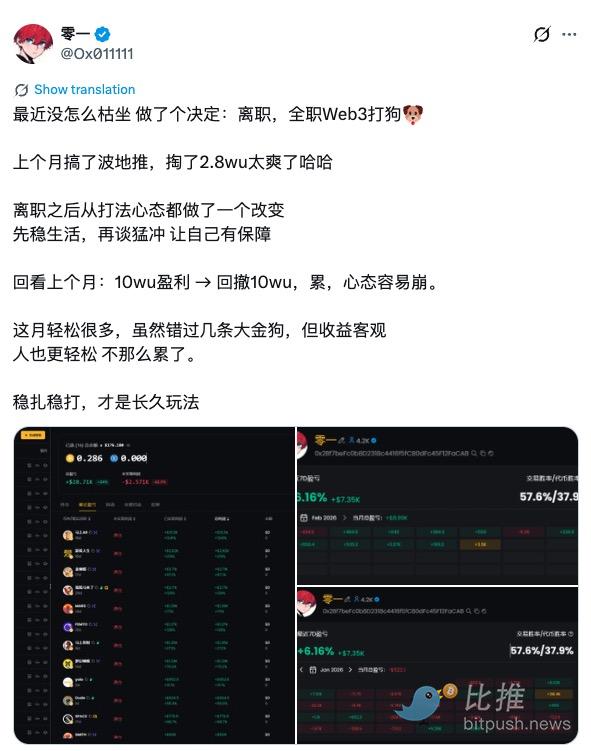

Popular Replies:
Extremes reverse—wait for the mean reversion. Right now, it's about resting. The sooner you rest up, the more advantage you'll have;
Just wait it out;
The AI circle's siphon effect should become particularly strong this year.
Twitter:https://twitter.com/BitpushNewsCN
Bitpush TG Discussion Group:https://t.me/BitPushCommunity
Bitpush TG Subscription: https://t.me/bitpush





