TL;DR
Over the past few years, the star of AI infrastructure has been the GPU. Those who secured more H100s or B200s had a stronger supply of computing power. But as we move into the Rubin and subsequent platforms, investors need to look one level deeper: Can the GPUs fit into the rack? Can the rack receive stable power? Can the heat be dissipated? Can the systems be fully loaded and tested before leaving the factory?
This is precisely why 800VDC is now being discussed in the market. Since 2025, Nvidia has consistently and publicly advocated for 800VDC architecture, incorporating it into the design direction for next-generation AI factories and high-power racks. On the surface, this is a shift in voltage specification from traditional low voltage to high-voltage DC. Looking deeper, AI servers are no longer just assemblies of boards and chips; they are increasingly resembling power engineering projects.
Ordinary investors can think of it this way: a full rack of AI servers is like a small building with extremely high electricity consumption. Past power delivery methods could still support racks of several dozen or even a hundred kilowatts. But as power continues to increase, the problem is no longer just "how many GPUs to buy," but rather how to deliver the electricity, how to dissipate the heat, and how to run the machines at full load continuously before they leave the factory.
High-Power Racks Are Approaching the Limits of Low-Voltage Power Supply
The starting point for this change is the rapid rise in AI rack power. Traditional server racks might only consume a few to tens of kilowatts. With Nvidia's GB200/GB300 generation, whole-rack power has entered the hundred-kilowatt range. According to Tom’s Hardware, the GB200/GB300 NVL72 consumes approximately 120-140kW.
Power density could climb further post-Rubin. Some supply chain and industry estimates suggest the Rubin NVL72 might reach approximately 180-220kW. This range is not officially confirmed by Nvidia and should still be considered third-party estimates, but the direction is clear: leading-edge AI racks are becoming higher-density power consumption units.
The power issue can be explained by a formula: Power equals Voltage multiplied by Current. To deliver the same 600kW of power, if the voltage is lower, a larger current is required. A larger current necessitates thicker cables and busbars, causes more severe heat generation, and leads to higher power loss in the lines.
Traditional low-voltage power supply is like using a very thick water pipe to slowly move a large volume of water. It works, but the pipe gets thicker, heavier, and takes up more space. Rack space, which should be reserved for GPUs, memory, networking, and cooling structures, gets crowded out by power shelves, cables, and busbars. At power levels of several hundred kilowatts and beyond, continuing to rely on low-voltage, high-current systems becomes increasingly uneconomical.

The idea behind 800VDC is to increase the voltage, deliver power more efficiently to the vicinity of the rack, and then step it down locally for use by the GPUs. It's akin to increasing water pressure to use narrower pipes to deliver the same amount of water. Nvidia's official materials state that 800VDC can reduce current, copper usage, cable volume, and conversion stages, potentially increasing efficiency by up to 5% and improving TCO by up to 30%. Some third-party and partner calculations also mention that copper usage could drop by about 45%, with actual benefits depending on the data center and rack integration methods.

This isn't just about saving copper. For Nvidia, the core value of 800VDC is to enable continued increases in compute density for next-generation AI racks. Low-voltage systems aren't unusable, but in the highest-density AI factories, they are beginning to approach engineering limits.
Nvidia Redefines Infrastructure Roles with Reference Architecture
What's significant about Nvidia is not just proposing a voltage solution, but using a reference architecture to redefine the division of labor within the ecosystem. Since 2025, Nvidia has publicly introduced the 800VDC architecture multiple times, showcasing its design direction for high-power systems like Rubin and Kyber racks in technical blogs and at forums like OCP.
According to Nvidia's official blog, its 800VDC ecosystem partners include Delta Electronics, Schneider Electric, Vertiv, Infineon, STMicroelectronics, as well as companies like ABB, Eaton, GE Vernova, Hitachi Energy, Siemens, Navitas, and Texas Instruments. It's more accurate to describe this as ecosystem collaboration and adaptation, not to be directly interpreted as confirmed orders.
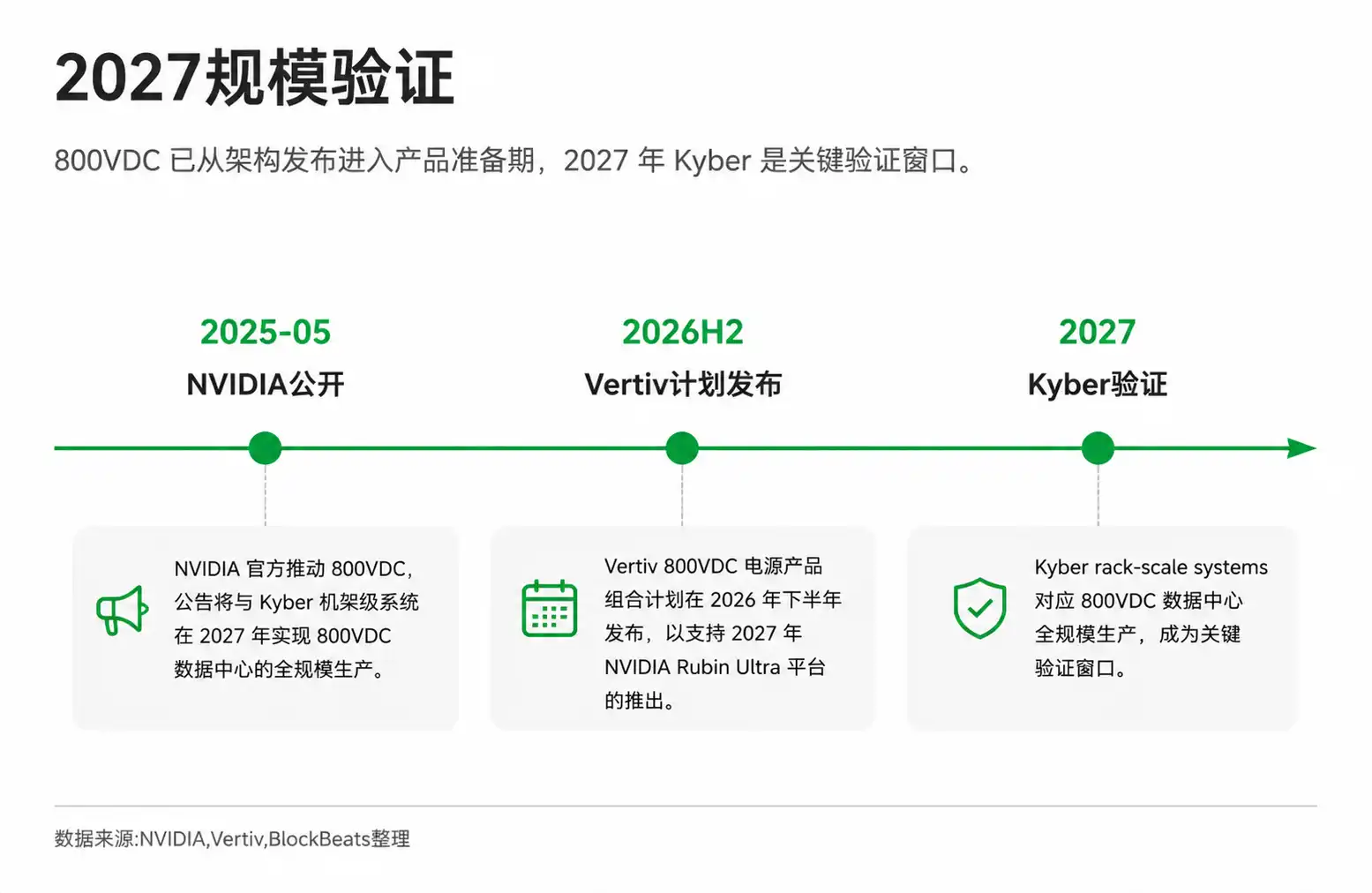
800VDC involves not a single component upgrade, but a change across an entire chain: from data center power distribution and rack power supplies to backup batteries, power devices, connectors, and whole-rack integration. Previously, power conversion might have been distributed across multiple stages like UPS, PDU, server PSUs, and motherboard power delivery. Under a high-voltage DC architecture, power is delivered closer to the rack, then stepped down by modules within or near the GPU.
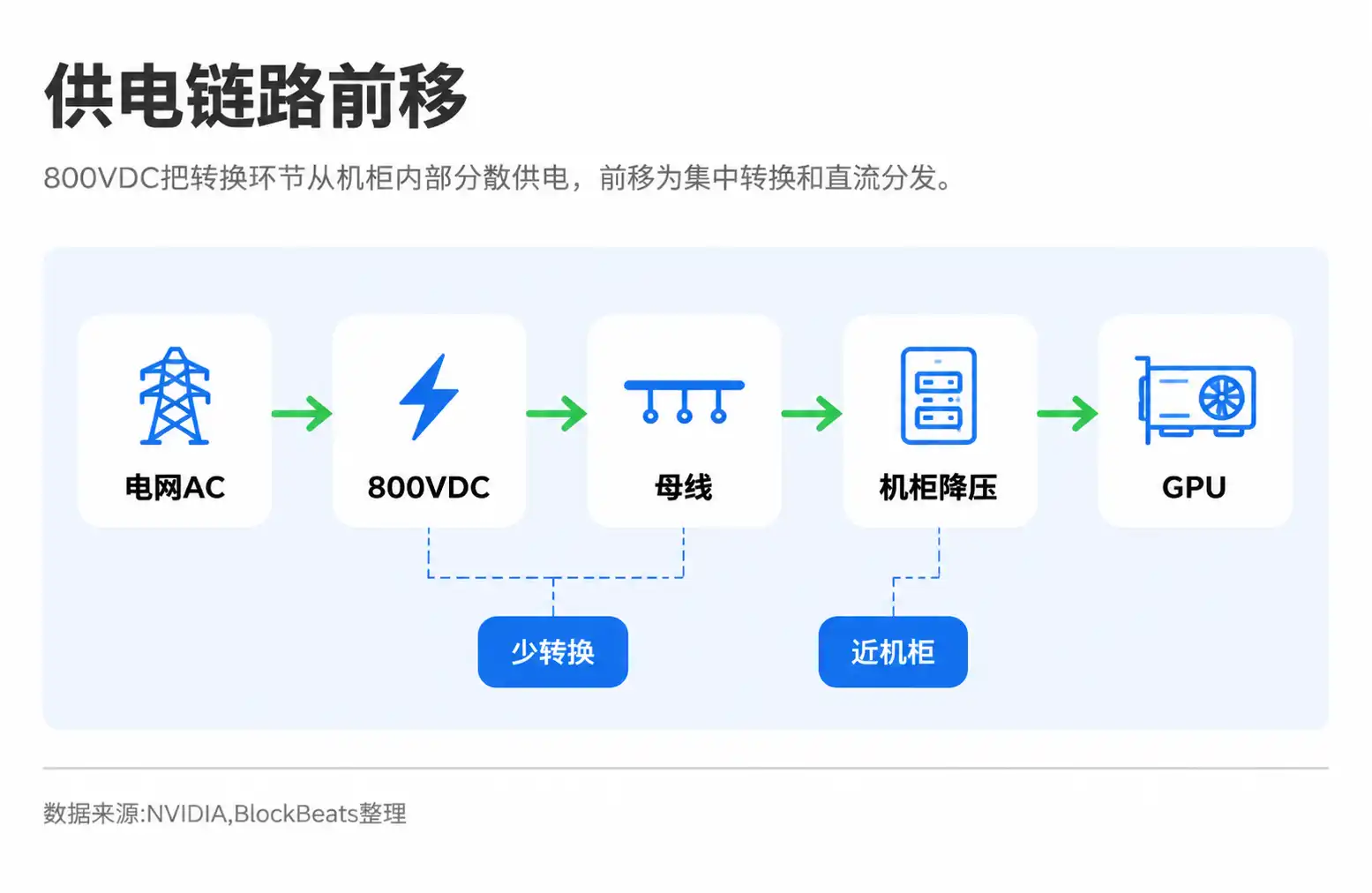
The weighting within the value chain will also shift accordingly. In the traditional server era, investors focused more on GPUs, CPUs, memory, and system integrators. In the era of high-power AI racks, power shelves, busbars, connectors, power semiconductors, liquid cooling systems, and whole-rack validation capabilities are all becoming part of the delivery capability.
Boundaries must also be clarified. 800VDC is more like an important reference architecture for leading-edge, high-density AI factories, not a standard that all data centers will immediately switch to. Many existing data centers will continue using traditional AC or hybrid architectures. New projects will also adopt it in layers based on power density, cost, owner willingness to retrofit, and safety regulations. What the market is truly trading on is not that everything will switch to 800V this year, but that the infrastructure rules for the highest-density AI racks post-2027 are changing.
Power Supplies, Connectors, Liquid Cooling, and Whole-Rack Testing Move to the Forefront
From an investment perspective, the most direct impact of 800VDC is bringing infrastructure segments that were previously in the background to the forefront.
The first category is power infrastructure companies, such as Vertiv, Schneider Electric, Delta Electronics, and some South Korean and Taiwanese power equipment manufacturers. They are not just selling traditional data center power equipment; they need to participate in the design of power distribution, rack power supply, backup batteries, and high-voltage DC systems for the new generation of AI factories. According to Asia Business Daily, Nvidia has communicated with South Korean power equipment companies like LS Electric, HD Hyundai Electric, and Hyosung regarding 800VDC data center infrastructure. This report is based on industry insider information and should not be equated with confirmed orders, but it illustrates that power equipment providers are being included in the AI factory ecosystem.
The second category is power devices, namely next-generation power switches like SiC/GaN (Silicon Carbide/Gallium Nitride). These are better suited than traditional silicon devices for high-voltage, high-frequency, high-efficiency scenarios. They were often discussed in the context of electric vehicles, charging piles, and industrial power supplies, but are now spilling over into AI data centers. Companies like Infineon and STMicroelectronics are therefore coming into investors' view. However, the benefits for power semiconductors also depend on specific designs, supply share, pricing, and yield, and cannot be simply equated to "800VDC concept stocks."
The third category is connection and mechanical structures, including busbars, power busways, high-voltage connectors, high-end backplanes, and some thick-copper, multi-layer PCBs. When voltage increases and current decreases, copper loss pressure eases, but requirements for insulation, safety, connection reliability, and structural design become higher. Low-end copper materials do not inherently benefit; what's truly valuable are connection and power delivery materials that can adapt to high-power, high-reliability racks.
The fourth category is liquid cooling and whole-rack ODM. As power increases, heat dissipation is no longer a secondary issue. For servers to run stably in customer data centers, they must undergo whole-rack level testing before leaving the factory, including power supply, cooling, networking, and GPU full-load stability. Whole-rack deliverers like Dell, Wiwynn, and Wistron are competing not just on assembly efficiency, but also on whether they have sufficient power, space, liquid cooling testing, and system tuning capabilities.
Design Direction is Clear, but Delivery Capability Requires Real-World Testing
Nvidia has provided a clear technical direction, but supply chain execution won't automatically be smooth. The tension here is precisely what investors need to track.
Independent supply chain analyst Dan Nystedt has recently cited Taiwanese media and industry information multiple times: AI server ODM revenues are strong, Rubin-related production preparations are advancing, but components, power infrastructure, and whole-rack burn-in testing (full-load aging tests) are becoming real constraints. Burn-in can be understood as stress testing of servers before they leave the factory. The power supply, cooling, and system stability of a whole rack of GPUs running at full load for extended periods must all pass together.
If a single rack requires continuous power at the 100-200kW level, the testing facility itself needs power and cooling capacity approaching that of a small data center. Such supply chain signals cannot be written as the industry already commonly having its own power generation, nor can they be directly interpreted as power supply having replaced GPUs as the biggest bottleneck. It's more of a reminder: Delivery in the Rubin era is not just about GPU arrival and motherboard assembly, but about power, liquid cooling, testing, and whole-rack stability all being in place simultaneously.
The logic behind the revaluation of some ODMs, power equipment, and liquid cooling companies is also here. Their value doesn't just come from participating in AI servers, but from their ability to reliably deliver high-power racks to cloud providers. In the future, if everyone gets the same Nvidia reference design, what truly differentiates them might be testing facilities, power capacity, liquid cooling debugging experience, and delivery yield.
For AI cloud providers like CoreWeave and Nebius, 800VDC is not a direct component-benefit logic, but a variable affecting capital expenditure efficiency and deployment speed. Whether high-density racks can be deployed on time impacts computing power delivery, depreciation schedules, and revenue realization. High-speed interconnect or optical module chains, like those involving Marvell or Lumentum, belong more to a parallel logic of AI cluster expansion and should not be confused with direct beneficiaries of 800VDC.
2027 to See Kyber Racks and Order Fulfillment
The direction of 800VDC is much clearer than a year ago: Nvidia is officially promoting it, partners are adapting, physical constraints exist, and leading-edge high-density AI factories need more efficient power delivery. But it is still in the preparation and early deployment window. Nvidia officially states that full-scale production for 800VDC will correspond with the 2027 Kyber rack-scale systems; true validation will depend on whether subsequent products and customer projects materialize.
What's most worth watching next is not whether a company mentions "AI power" in its announcements, but whether it has clearly entered into 800VDC-related products, customer validation, and order fulfillment. Whether ODMs disclose stronger whole-rack testing capabilities, the reliability of liquid cooling systems under prolonged full load, and whether data center owners are willing to retrofit power distribution and safety regulations for high-voltage DC architecture will all influence the rhythm of this trade.
If Rubin-related racks ramp up smoothly and 800VDC component orders move from samples and validation to volume procurement, the market will continue to increase the weighting placed on power supply, liquid cooling, connectors, and whole-rack delivery capabilities. Conversely, if power consumption configurations are lower than expected, customers adopt more conservative hybrid architectures, or testing power and liquid cooling reliability slow down delivery, the 800VDC trade will also shift from directional judgment back to verifying orders and timing. GPUs remain the core, but post-Rubin, the ability to stably deliver a whole rack of high-power systems is beginning to become a variable in asset pricing.






