By | Luo Chao Channel
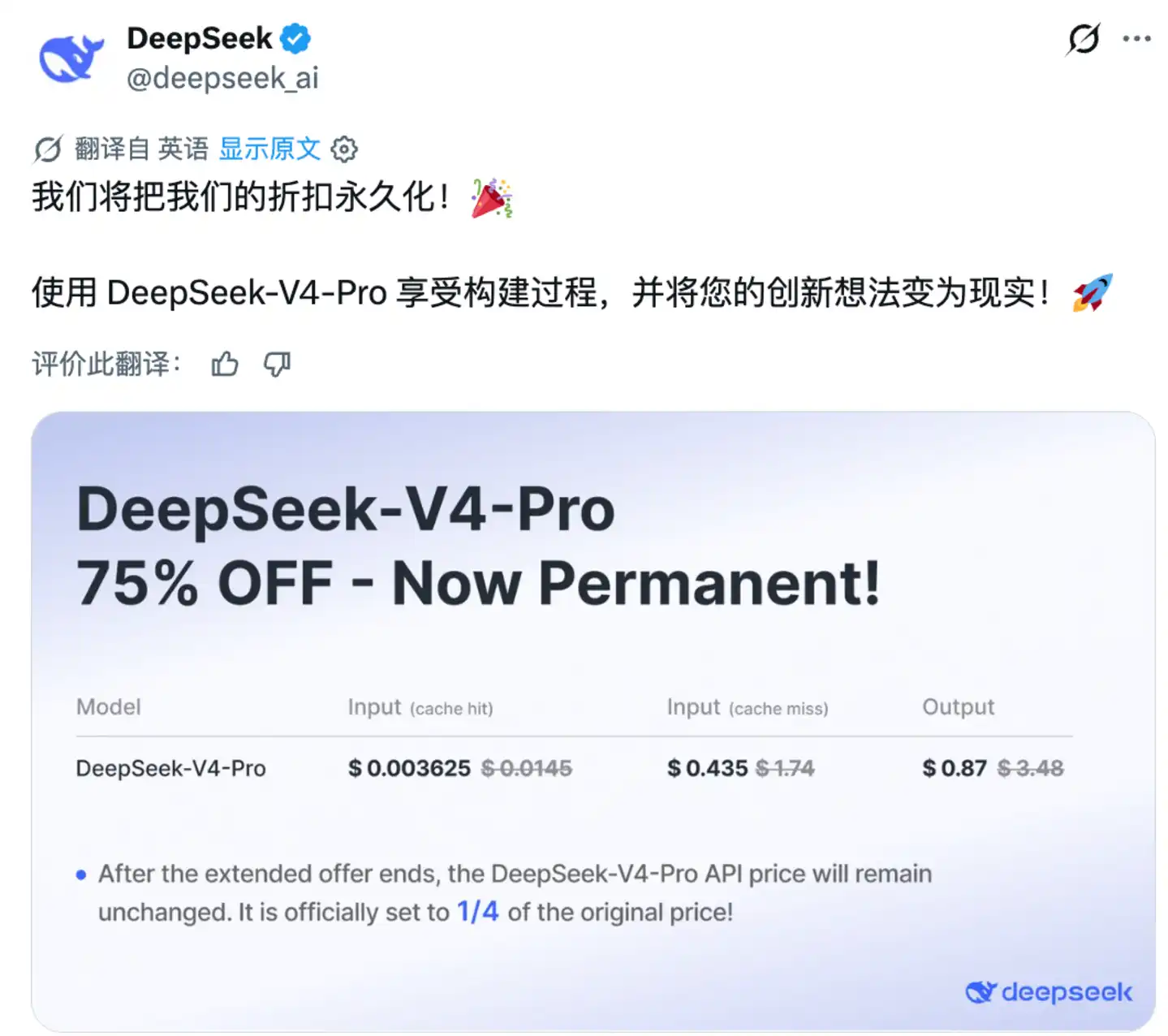
DeepSeek has announced it will make the 75% discount on its V4-Pro API "permanent," effective globally.
The final pricing structure: the base input price has been reduced from $1.74 / million tokens to $0.435 / million tokens, and the output price from $3.48 / million tokens to $0.87 / million tokens. For input cache hits across the entire API product line, DeepSeek has implemented even greater concessions: $0.003625 / million tokens, all following a Pinduoduo-style rock-bottom pricing model.
A wave of voices immediately emerged on social media, including X, hailing Liang Wenfeng as the Cyber Bodhisattva, the "Feng God," or "Saint Liang" of the AI circle. The sentiment doesn't just come from the cheapness itself — DeepSeek has long been called the "Pinduoduo of AI," free for C-end users and affordable for B-end, and the world is used to its low prices. The difficulty of this round of price cuts lies in the fact that AI prices are rising globally.
Reports indicate that in DeepSeek's ongoing record-breaking Series A financing, Liang Wenfeng will personally contribute up to 20 billion RMB, accounting for 40% of the total funding. For most companies, the first thing after financing is to strengthen cash flow and make performance look better, but Liang Wenfeng does not plan to use commercialization promises to attract investors, instead insisting on open-source and pursuing AGI. This price cut truly follows through on his word. The last time someone bravely expressed a lack of desire to make money was Pinduoduo, whose co-founder explicitly told investors in a 2024 earnings call: "Starting from Q3, our profits will gradually decline and won't rebound in the short term. In the long run, the decline in profitability is inevitable." The stock price plummeted.
Sam Altman talks about democratizing AI, but OpenAI is rapidly moving towards the opposite of its name: CloseAI. Liang Wenfeng, however, is personally ensuring that everyone, every enterprise, can use AI as affordably as possible. But is Liang Wenfeng truly a living bodhisattva? Not at all. He is an entrepreneur. Open-source and affordability are merely choices of business model, which is exceptionally commendable now and will become increasingly rare in the future.
Because: AI is getting more expensive.
This week, Microsoft canceled internal Claude Code licenses because the token-based billing was too high to bear. Microsoft heavily invested in OpenAI and also provides Azure cloud services to Anthropic, possessing computing resources envied by all enterprises, yet the token costs still hurt. Coincidentally, Uber's CTO reported an embarrassing situation to management in April: the company's AI budget prepared for the entire year of 2026 was exhausted within four months, with 95% of engineers using AI programming tools monthly and 70% of submitted code generated by AI. The exact quote was: "I'm back to the drawing board because the budget I thought I would need is blown away already."
The fact that big companies' token budgets are burning through much faster than expected certainly has to do with employees "not treating beans as rations" and burning tokens recklessly, but the root cause of token budget tension is that AI is getting more expensive. US AI software prices have risen by 20% to 37% over the past year. The "Big Three" — Anthropic, OpenAI, and Google — have all quietly increased the effective price for the same AI output over the past six months.
(Source: X)
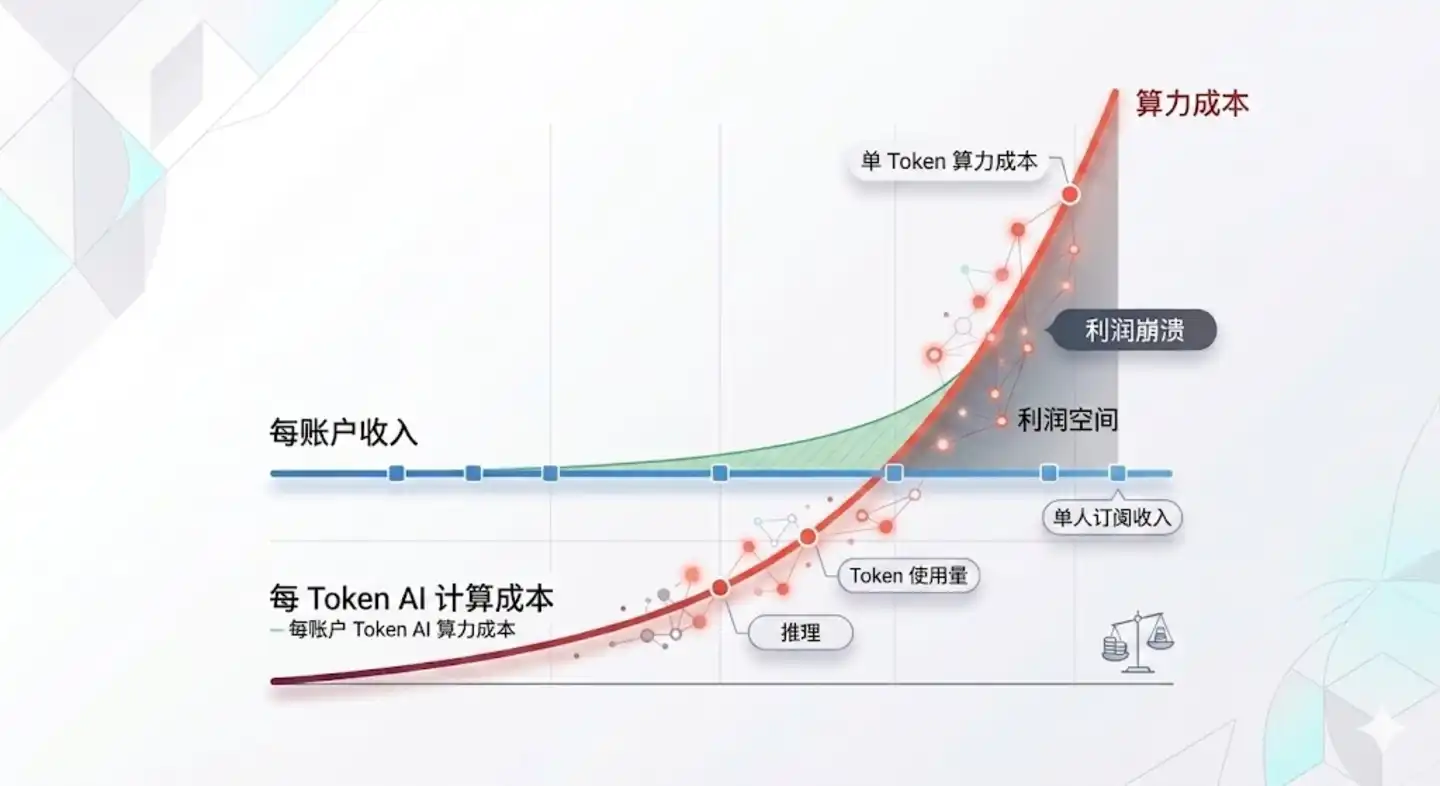
The prevailing narrative used to be: "The larger the scale of AI application, the higher the level of industrialization, the lower the cost, and the happier enterprises will be." How naive.
And this trend will not reverse. Price is determined by supply and demand, not cost, but the supply-demand relationship for AI has completely reversed in 2026. Before, big companies begged people to use AI, needing to educate the market and promote the technology. AI was always subsidized — how many free "Thousand Questions" cups of milk tea have you had? Now? People are increasingly actively using it, "can't live without it after the first puff." AI programming, AI documentation, AIGC, even AI search are becoming more widespread. The era of AI subsidies is completely over.
The more people use it, the greater the demand, the tighter token resources become, so the computing power shortage has spilled over from GPUs to CPUs, storage, and even bandwidth. Intel, Micron, SK Hynix, Samsung Electronics, SanDisk, and domestic companies like Jiangbolong and the two "Longs" are feasting alongside Nvidia. Where does the doubling revenue growth of semiconductor giants in 2026 come from? It certainly isn't from the OpenAI-Oracle-Microsoft triangular closed-loop investment, right? Enterprises' pain is just beginning. And AI products like ChatGPT, Claude, Gemini, and Doubao emphasizing strict hierarchies between free and paid tiers will also make individual users increasingly conflicted.
It's like ride-hailing: during the craze, you could take premium cars to and from work for free, with capital footing the bill. After user habits were established, subsidies ended, prices returned to normal levels, and those who needed to take the subway still did. AI is the same. Therefore, against the backdrop of rising token prices across the industry, DeepSeek's insistence on cutting prices is no longer just a display of personal courage as a "Cyber Bodhisattva," but demonstrates a kind of reverse pricing power: we can be this cheap, still operate normally, and quality doesn't drop.
If Liang Wenfeng wanted, DeepSeek wouldn't need to be this cheap at all. So people are starting to worry: Will DeepSeek become the Linux of the AI era? Huge influence, but not making big money. Linux's contribution to the IT industry is far greater than Windows or Android (which itself is based on the Linux kernel), but it's open-source and commercially hasn't spawned giants like Microsoft or Google. DeepSeek currently has huge influence, but its commercial capabilities are far inferior to the Silicon Valley Big Three, and even cannot compete with the three domestic players: Kimi, MiniMax, and Zhipu. 2025 revenue ranking of the "Four Little Dragons": Zhipu (2025 revenue 724 million RMB) > MiniMax (2025 revenue approx. 560 million RMB) > Moonshot AI (approx. 200 million) > DeepSeek (unknown but lower).
Liang Wenfeng made money through AI quantitative trading and can personally invest 20 billion in DeepSeek, but the story of "running on love" cannot last forever.
Furthermore, under the open-source model, others can also distill, deploy, and fine-tune, so DeepSeek's technological moat will become thinner. So you always see news like this: "After Zhipu GLM-5.1 was open-sourced, it refreshed global scores on the SWE-bench Pro benchmark," "Xiaomi's MiMo-V2.5-Pro tops the global open-source large model leaderboard..." A joint report from MIT and Hugging Face shows that in the past year, open-source models developed in China accounted for 17.1% of global downloads, surpassing the US's 15.8%, ranking first globally.
No wonder there are increasing voices in Silicon Valley saying: There must be a US version of DeepSeek; we cannot sit back and watch the AI industry replay the stories of Shein, Temu, or TikTok. "If an open-source champion does not rise in the United States, the world will run on open-source models and software from whichever country can produce the strongest, most stable, cheapest, customizable, scalable models that meet personal and commercial needs." Topics involving great power competition often sound grand, but the competition behind them is real.
Behind DeepSeek's rise lies the narrative of indigenous substitution. V4's support for Ascend brought joy, and driven by domestic computing power, the price competitiveness DeepSeek currently displays is just the appetizer. In the technical report, DeepSeek indicated that after the batch release of Ascend 950 super nodes in the second half of the year, the price of V4-Pro will be significantly reduced further. The best is yet to come.
There's also the advantage of high-level AI talent. AI talent is expensive to a "luxury" level, but China's is relatively cheaper. Lei Jun making headlines for poaching Luo Fuli from DeepSeek with a ten-million-yuan salary, while Zuckerberg was offering $1 billion to poach people, including via acqui-hires. But the difference between what a $1 billion person and a ten-million-yuan person produces is clearly not 700 times. The price gap in AI talent will actually translate into a systemic price gap in the token production system.
The bigger competitive advantage lies in the energy system, which is the first layer of Jensen Huang's AI five-layer cake.
The end of AI is computing power, and the end of computing power is electricity. In April 2026, DeepSeek posted job listings for Senior Data Center Operations Engineers and Senior Delivery Managers in Ulanqab, Inner Mongolia, indicating its move to build token factories in the west, pushing cost advantages from the software layer down to the physical layer. The last time I wrote about Ulanqab in an article was when Kuaishou was building a data center there: close to power plants, suitable climate for cooling. Moreover, green electricity prices in western China are about 0.2-0.3 RMB/kWh, only 1/5 to 1/4 of those in Europe and the US.
It's not just that western green electricity is competitive. According to 2025 data from the International Energy Agency, China's total installed power generation capacity has exceeded 2,300 GW, accounting for about 22% of the global total, ranking first; the US has about 1,300 GW. More crucially, China has the world's most complete power structure: thermal, hydro, wind, nuclear, and photovoltaic all included. Data shows that China's industrial electricity prices have long been maintained at $0.06 to $0.08/kWh, while California's industrial electricity prices are close to $0.18/kWh, and even exceed $0.25/kWh in parts of Germany. This means that training a ten-thousand-card cluster in China is naturally dozens of percentage points cheaper than in Europe and the US.
In the operating costs of AI large models, electricity costs account for 60%-70% of total operating costs. It's not just running the model that uses electricity; cooling is a major part. The "infrastructure maniac" even builds data centers directly on the seabed, with offshore wind power input nearby and seawater circulation for free cooling. Then there are large-scale projects like "West-East Electricity Transmission" and "East Data West Computing." The ability to regionally dispatch power and computing is extremely strong. Guizhou, Inner Mongolia, Ningxia were already core nodes of "East Data West Computing." The pathway for moving AI computing power centers west was prepared long ago.
Using Chinese AI essentially means using AI trained by a more competitive energy system — more economical, more affordable AI. This is one reason why the overseas revenue of Kimi, MiniMax, etc., exploded after the Spring Festival. It's not just that the algorithms are stronger; it's that they have an electricity price cheat.
Nvidia can define the price of high-end computing power, but DeepSeek and others are grasping the pricing power of tokens. You might say cheap AI is no good. AI is indeed you get what you pay for. DeepSeek V4 only narrowed the gap between open-source and closed-source to a historical minimum. The company candidly acknowledges the objective gap with top models like GPT, and it's not multimodal — it can recognize images but not generate them.
But this hasn't stopped the community from flocking to DeepSeek. The reason: most real business scenarios don't require calling the world's strongest model every time. Consulting, customer service, summarization, translation, code completion, enterprise knowledge bases, automated workflows — these don't require the highest intelligence, but "barely usable + cheap enough + stable enough." When DeepSeek V4's inference cost is only about 1% (Flash) to 11% (Pro) of GPT-5.5's, an enterprise with the same budget can call tens of times more tokens, try more prompt chains, iterate more agent workflows, and the final output might even be better. After all, AI itself is a "probability" game. If it's cheap enough, getting results by making do is perfectly acceptable.
Therefore, the more expensive AI gets, the more valuable DeepSeek's cheapness becomes, and the more valuable the company DeepSeek becomes. Liang Wenfeng and his investors understand this better than anyone.





