Two years' work, now completed in a few weeks.
Recently, neuroscientist Jérôme Lecoq and his team at the Allen Institute compressed the writing time of a long-form review article from nearly two years to just a few weeks.
Jérôme Lecoq had a backlog of about 10 reviews, many exceeding 100 pages, with every single citation checked sentence by sentence by an AI agent.
The tool helping him was Claude Science, the new application just launched by Anthropic.

On June 30, 2026, Anthropic released Claude Science, positioned as an AI workbench for scientists. (Image source: Anthropic official blog)
According to Anthropic, this task would have taken the scientist and his team two years in the past.
Anthropic's positioning for Claude Science is not just a smarter research model, but an AI workbench tailored for scientists.
Its true breakthrough lies in: for the first time, breaking down scientific research into an auditable, step-by-step pipeline.
Currently, Claude Science is in beta on macOS and Linux, available to Pro, Max, Team, and Enterprise users.
What's Really Changing is the Entire Research Toolchain
Anyone who has done research understands the drudgery:
A project requires jumping between dozens of databases, each with its own schema and query language;
File formats are all over the place, requiring custom pipelines and viewers for each;
You have a row of tools on hand: PubMed for literature, Jupyter for code, R for statistics, cluster terminals for submitting jobs...
Constant context switching, leaving little time for actual scientific thinking amidst the work of moving, splicing, and debugging.
What Claude Science does is bundle these fragmented scenarios into a single execution environment:
Literature analysis, multi-step computation, chart polishing, manuscript drafting—all stages are completed in the same environment, so you don't interrupt your train of thought switching tools.
It can run on your local macOS or Linux machine, connect via SSH to remote machines, or attach to a high-performance computing (HPC) login node.
Just like using Jupyter normally, it goes where the data is.
It even handles computational resource scheduling.
Large tasks like protein folding or running a genomic pipeline on massive data used to require researchers to babysit: setting up jobs, queuing for cluster time, monitoring success or failure, and pulling results back—half a day gone in a flash.
Claude Science takes over this flow: drafting a plan, asking for permission before touching new resources, letting you review or revert tasks before they are written and submitted, scaling analysis from 1 GPU to hundreds.
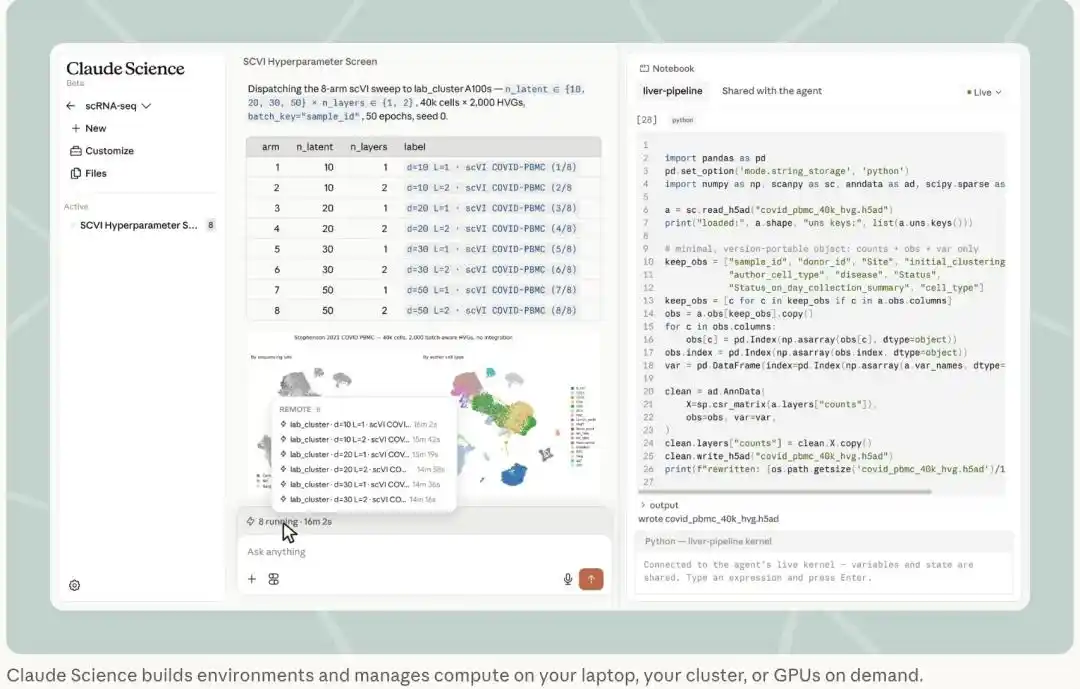
Claude Science dispatches an 8-group scVI hyperparameter scan to a lab's A100 cluster. The Notebook on the right shares the same live kernel with the agent, with variables and state synchronized in real-time. (Image source: Anthropic official blog)
More importantly, sensitive data doesn't leave the original system; only the context truly needed for each step is sent to Claude.
Every Chart Comes with Traceable Code
Science inherently deals with visuals: protein 3D structures, genome browser tracks, chemical formulas—these are essentially diagrams.
Building on this, Claude Science, while generating charts and drafts, also outputs the code that created them and can render them natively.
The key lies in reproducibility.
Whenever Claude Science generates a chart, it "pins" the exact code that created it, along with the runtime environment, plain-language descriptions, and the full conversation history, right onto the chart.
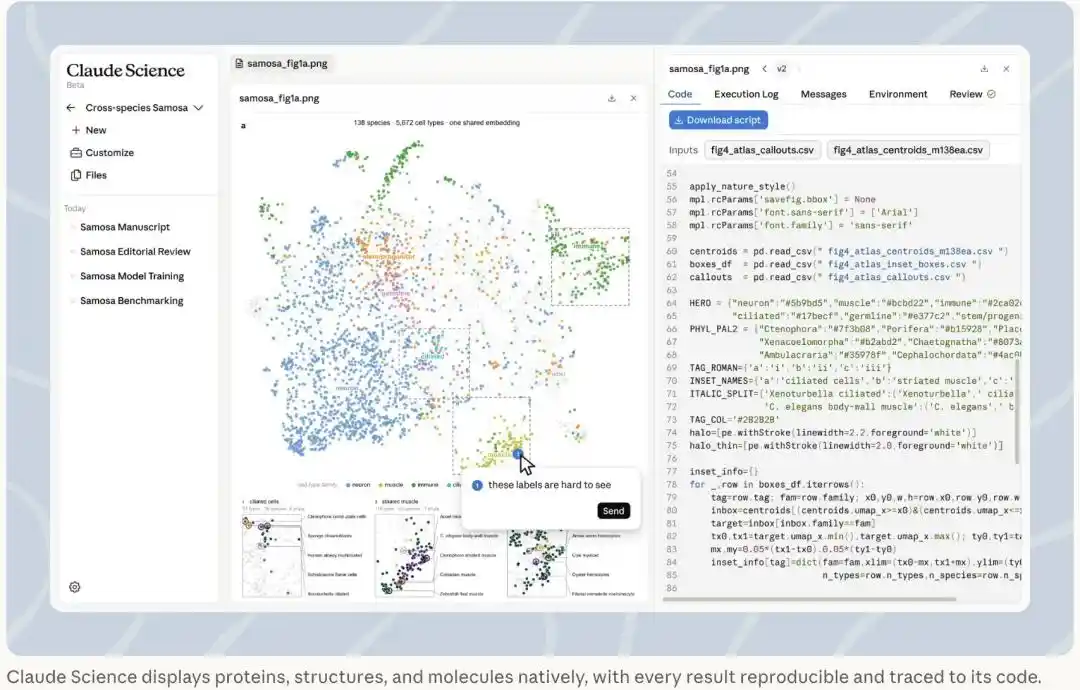
On the left, a cell chart across 138 species; on the right, the exact code that generated it is displayed side-by-side. Annotating with a sentence can have the agent modify the chart. Every result is reproducible and traceable to its code. (Image source: Anthropic official blog)
Months often pass from a paper's submission to publication; months later, when a reviewer asks you to rerun a specific chart, you can easily reproduce the entire chain of inputs, process, and results on the spot.
Want to edit the chart? Just speak—"remove gridlines," "switch the y-axis to log," the agent directly edits the code it wrote.
You can also fork the session at any point to try two different approaches simultaneously, without disrupting the original thread.
In short, research is integrated for the first time into an auditable workflow, with code, environment, and history all placed within a closed loop.
One Agent Writes, Another Specializes in Finding Errors
Behind Claude Science, it's not a single agent working alone.
You're facing a coordinating agent that manages over 60 pre-configured skills and connectors for genomics, single-cell analysis, proteomics, structural biology, and cheminformatics.
When work piles up, it can spawn additional agents for division of labor and can call upon expert agents you've created yourself.
The most clever part is the reviewer agent.
It specializes in checking citations and calculations, hunting down wrong citations, unsourced numbers, charts that don't match the code, marking them, and fixing them itself.
In the Allen Institute case, the team used an actor-critic pairing: one agent responsible for writing, another specialized in evaluating its accuracy and the veracity of citations.
This structure already hints at a prototype for "AI internal peer review."
But one boundary must be clear: it's human-in-the-loop throughout.
Before utilizing new resources, it seeks authorization; every decision you can review and revoke. It automates the process, not the scientific discovery itself.
It also integrates with NVIDIA's BioNeMo Agent Toolkit, connecting natively to life science models like Evo 2, Boltz-2, and OpenFold3.
Models, data, and pipelines your lab trusts can be saved as reusable skills and integrated, automatically inherited by future sessions.
Claude Science's First Stop is Life Sciences
Claude Science's initial focus is on life sciences.
Genomics, single-cell, proteomics, structural biology, cheminformatics—ready to use out of the box.
It can read literature, query 60+ scientific databases like UniProt, PDB, Ensembl, ClinVar, ChEMBL, and GEO—you no longer need to learn how to use each disparate database one by one.

Claude Science comes with pre-configured environments for genomics, single-cell, proteomics, and cheminformatics, backed by 60+ scientific databases. (Image source: Anthropic official blog)
Manifold Bio works on tissue-targeting drugs.
They use Claude Science to nominate targets for the latest experiments, evaluating surface expression, transport, and safety for each tissue and target, then ranking candidates according to standards learned from their own proprietary data.
Manifold says ordinary programming assistants can't do this; Claude Science can complete it end-to-end, getting the right data, making the right judgments, and carrying context from past projects.
There are even more hardcore examples.
An epidemiology associate professor at the UCSF Brain Tumor Center uses it for molecular epidemiology studies of glioma, analyzing how thousands of small-effect germline variants combine to shape individual susceptibility.
According to Anthropic, this germline analysis was completed by Claude Science in about 1/10th the time, and his team independently verified the results, confirming both speed and reliability.
However, these 10x acceleration scenarios are currently limited to review writing, genomic analysis, and specific pipeline automation, and do not equate to "10x acceleration of research overall."
Simultaneously, the threshold for research credibility is being redefined.
In the past, the reliability of a study depended on peer review and whether others could reproduce it.
Reproducibility has long been a major pain point in science—code gets lost, environments change, months later even the authors themselves can't reproduce that original chart.
Claude Science ensures every chart has traceable code, every result is linked to its environment and history. It might be the first to truly cross the reproducibility hurdle.
Three Players on the Same Track
In the bio-research track, the three giants are all competing, each with a different approach.
Google bets on proprietary models, OpenAI bets on the model's scientific IQ, while Anthropic bets on workflow.
Google holds exclusive models like AlphaFold and AlphaGenome that others don't have, going directly to market.
OpenAI takes a different path.
In April this year, it launched GPT-Rosalind, a cutting-edge model specifically built for biological reasoning and drug discovery.
Now it's going further, training the model's "scientific judgment."
It just launched GeneBench-Pro, specifically testing if models can make judgments like a computational biologist: 129 questions, spanning genomics, population genetics, all the way to clinical diagnosis, specifically testing the feel for "does the data support this question" and "which step should be redone."

The strongest model, GPT-5.6 Sol, scored 28.7%, 31.5% with Pro mode; GPT-5 from a few generations ago was less than 5%.
OpenAI itself says that at this rate, the benchmark could be topped by the end of the year.
But even the strongest models only solve less than a third. The unsolvable portion is precisely where human scientists remain.
The AI shortcomings exposed by GeneBench-Pro are also obvious:
Models can start but can't close the final loop, like whether to exclude a batch of anomalous data, how to change course when a hypothesis is overturned—these judgments still require the scientist's own decision.
Claude Science doesn't bypass this either; proposals are submitted for human review, every decision left for human revocation. It automates the process, judgment is not handed to the model, humans remain in the loop.
For scientists like Lecoq, whether a review is reproducible, whether it still holds up months later, matters more than an extra few percentage points on a leaderboard.
Claude Science is betting precisely on making AI research truly land in the daily routine of the lab.
References:
https://www.anthropic.com/news/claude-science-ai-workbench
https://openai.com/index/introducing-genebench-pro/
This article is from the WeChat public account "New Zhiyuan," author: ASI Apocalypse





