Just now, Claude Sonnet 5 has arrived!
Code name: Fennec, the fennec fox, the smallest fox in the Sahara Desert.
This is Anthropic's Sonnet model with the strongest Agent capabilities to date, with performance close to that of the flagship Opus 4.8.
Effective immediately, Sonnet 5 becomes the default model for all Free and Pro users.

It can autonomously plan and invoke browser and terminal tools.
Just a few months ago, this required spending a lot of money to invoke super-large models; now, Sonnet easily achieves it.
Compared to the previous generation Sonnet 4.6, Sonnet 5 shows significant performance improvements in reasoning, tool use, programming, and knowledge work tasks.
Key points:
SWE-bench Pro score of 63.2%, surpassing GPT-5.5's 58.6%, slightly behind Opus 4.8's 69.2%
'Humanity's Last Exam' score of 57.4%, only 0.5 percentage points behind Opus 4.8
Standard pricing: $3 per million input tokens / $15 per million output tokens, only 60% of Opus 4.8's price
Browser injection defense: 0.93% success rate, beating both Mythos 5 and Opus 4.8

Interestingly, Fable 5 was also revealed to be making a comeback on the same day. But the cost is mandatory real-name verification, and it will most likely be limited to US users.
Sonnet 5, on the other hand, promises to hold nothing back, and is available globally for all users to use openly starting today.

On Par with Opus 4.8 Across the Board, the Strongest Worker AI Launches a Surprise Attack
This sudden launch of Sonnet 5 also helps fill the void left by the unavailability of Fable 5.
For many developers, the year one of the Agent era began with Sonnet.
Claude Sonnet 3.5, 3.6, and 3.7 were among the earliest models to demonstrate astonishing abilities in writing code and using tools.
In other words, the concept of "letting AI do the work itself" was first proven feasible by the Sonnet "medium cup" series.
But over the past year or so, the most dramatic leaps in capability have been concentrated on the Opus "large cup" line. Sonnet was left directly behind by the flagship.
What Sonnet 5 aims to do is close this gap!
Anthropic sets the tone with one sentence – Claude Sonnet 5 is the most capable "worker" Sonnet in history.
Looking at its real-world performance scores best illustrates this point.
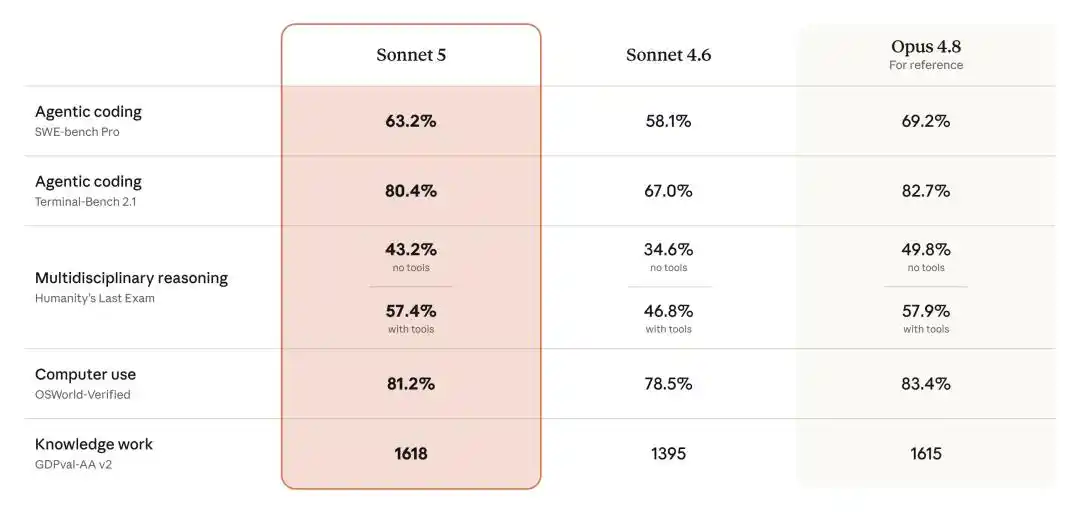
In its traditional stronghold of programming, Sonnet 5 impressively scores 63.2% on SWE-bench Pro. The previous Sonnet 4.6 only managed 58.1%, while Opus 4.8 currently leads with 69.2%.
In contrast, OpenAI's flagship GPT-5.5 only scores 58.6% on the same benchmark, and Google's Gemini 3.5 Flash scores just 55.1%.
Terminal-Bench 2.1 performance is even more ferocious. Sonnet 5 skyrockets to 80.4%, leaving Sonnet 4.6's 67.0% far behind with a huge 13 percentage point jump. It's less than 2 points away from Opus 4.8's 82.7%.
On the cross-disciplinary reasoning benchmark dubbed 'Humanity's Last Exam', Sonnet 5 with tools achieves 57.4%, compared to Opus 4.8's 57.9%—a mere 0.5 percentage point difference. GPT-5.5 scores only 52.2% on the same test, and Gemini 3.1 Pro scores 51.4%.
In computer control capabilities, Sonnet 5 scores 81.2% on OSWorld-Verified, again surpassing GPT-5.5's 78.7% and closely trailing Opus 4.8's 83.4%.
More surprisingly, in knowledge work, Sonnet 5 scores 1618 on GDPval-AA v2, directly overtaking Opus 4.8's 1615.
In agent search and tool use performance, Sonnet 5 provides Opus 4.8-level capabilities at the lowest cost.
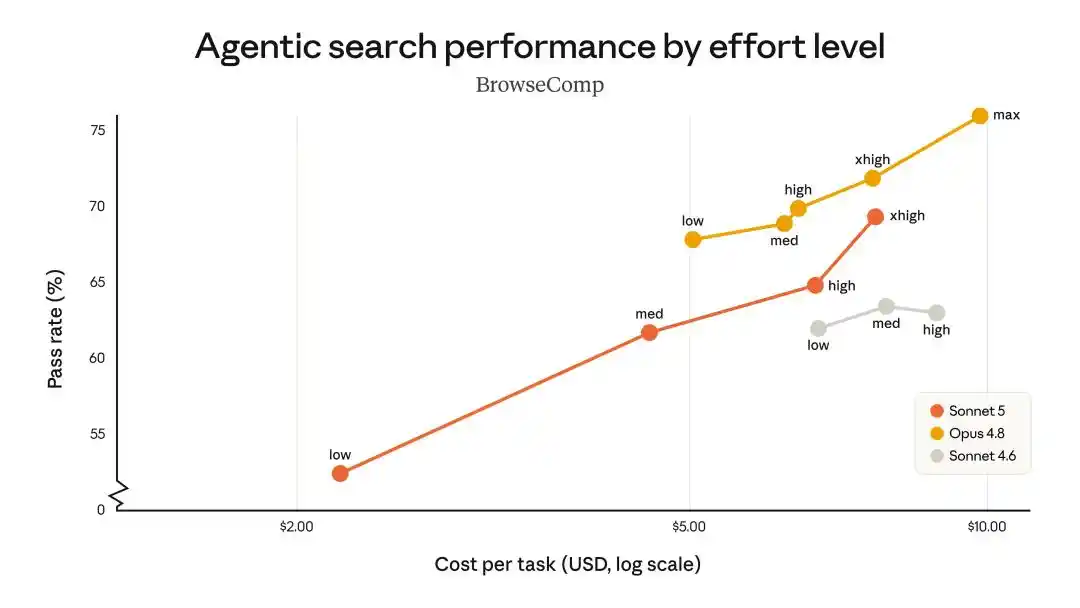
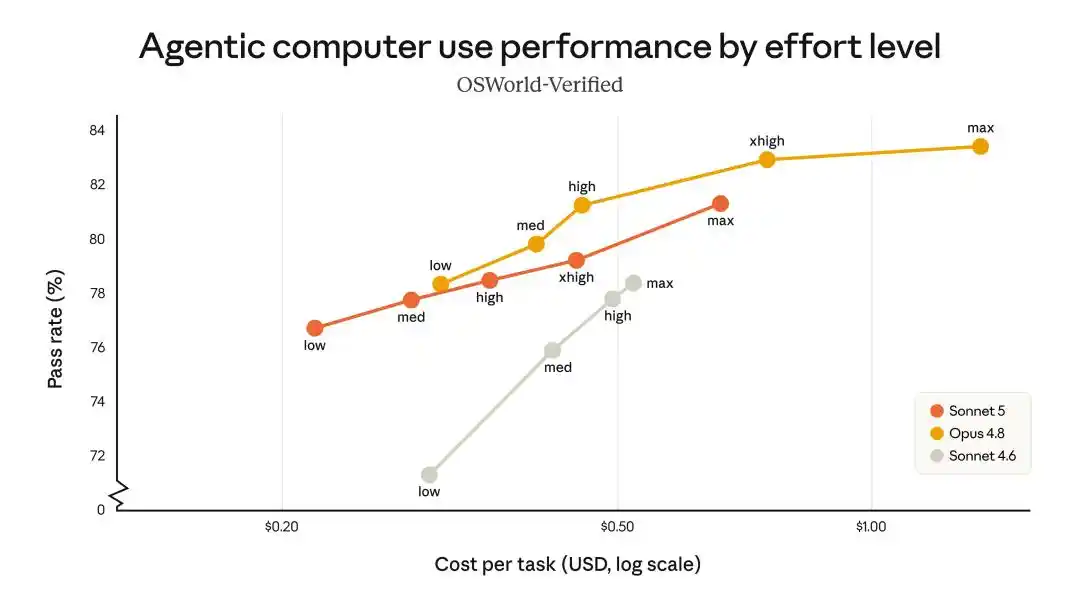
It can be said that in almost every benchmark, Sonnet 5's performance falls within the 90% to 100% range of Opus 4.8's scores.
It's practically like paying Sonnet's price for 90% of Opus's brainpower.
$2 Limited-Time Promotion, But With a Hidden Pitfall
The price is this release's real "killer feature".
For API pricing, Anthropic is offering a limited-time promotion: $2 per million tokens for input, $10 per million tokens for output.
After August 31st, the price reverts to the original $3 for input and $15 for output.
In comparison, Opus 4.8 is priced at $5 and $25, and GPT-5.5 Standard is $5 and $30.
During the promotion period, both input and output prices are only 40% of Opus 4.8's. Even after the standard price resumes, it's only 60%.

However, while Anthropic appears full of sincerity on the surface, there's a little trick hidden in the details.
The reason is that Sonnet 5 uses a completely new tokenizer. The number of tokens for the same input text may inflate by a factor of 1.0 to 1.35.
Once the promotion period ends, the original price of $3/$15 combined with the tokenizer inflation effect will definitely make the real spending sting a bit more than using Sonnet 4.6.
But even so, compared to Opus, it's still a crushing difference.
Counterattacking All Flagship Models in the Family
The System Card hides one of Sonnet 5's most underestimated aspects.
Prompt injection attack success rate: 0.19%, on par with Opus 4.8. GPT-5.5 is at 3.08%, Gemini 3.5 Flash is at 6.66%.

In browser injection defense, the attack success rate is only 0.93%, while Mythos 5 is at 29.7% and Opus 4.8 at 31.5%.
A $2 mid-range model has counterattacked and defeated all flagship models in the family; with protective measures enabled, it drops directly to 0%.
For malicious code injection, Sonnet 4.6 had a high attack success rate of 45.26%. Sonnet 5 has reduced this to 0.29%, an improvement of 150 times.
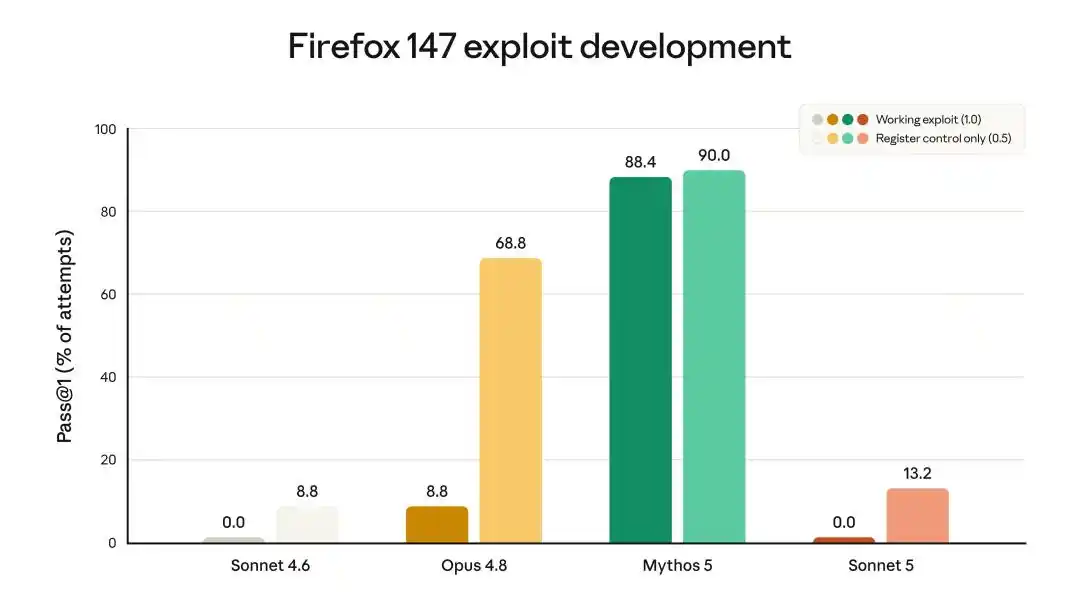
In the Firefox 147 vulnerability exploitation test, Mythos 5 could write usable exploits 88.4% of the time, Opus 4.8 at 8.8%, and Sonnet 5 at 0.0%. It can write top-tier business code, but can't write a single usable exploit.
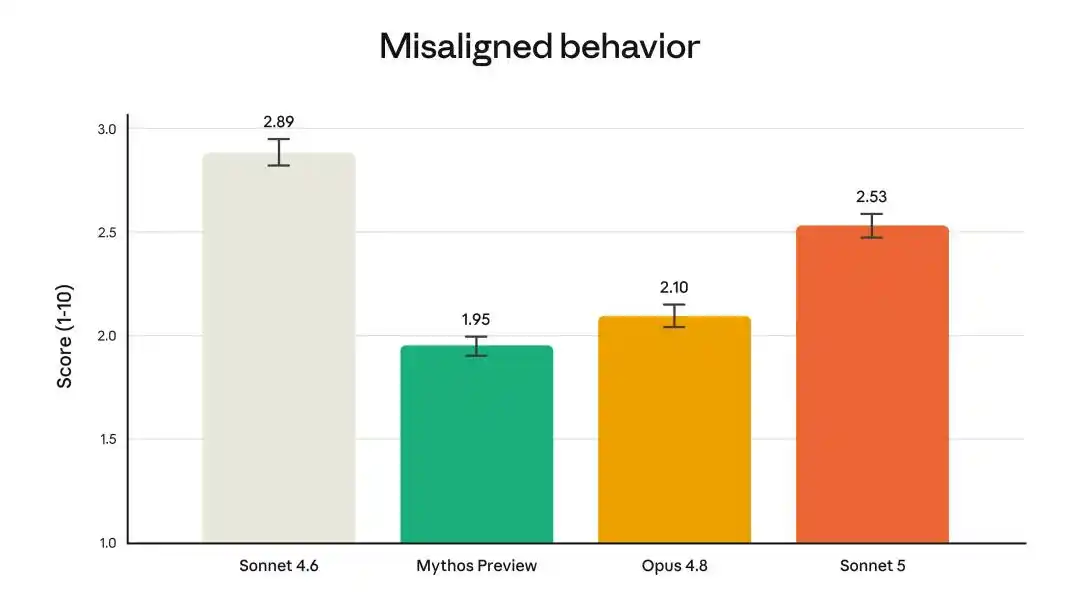
A side effect is a misalignment behavior score of 2.53 (out of 10), an improvement over Sonnet 4.6's 2.89, but higher than Opus 4.8's 2.10 and Mythos Preview's 1.95.
It has become stronger, and also more opinionated.
Not Competing for the Crown, Specializing in Cutting Down the Mid-Tier
Sonnet 5 occupies an incredibly precise position. Its upward-facing capabilities approach those of Opus 4.8 and GPT-5.5, while its downward-facing price is close to the level of Gemini 3.5 Flash.
Just as OpenAI doubled its prices compared to the previous generation, Anthropic turned around and pushed Sonnet 5's entry price down to $3.
Developers who were previously hesitant about paying for a flagship now have a lethally powerful alternative.
While everyone else is focusing on fighting at the top, Anthropic has fired a shot at the mid-tier.
Developer Wallets Voted Tonight
Now, Sonnet 5's performance has stepped into the flagship range; most tasks like fixing bugs, adding tests, or refactoring can be handled in one go.
The awkward situation where Opus felt too expensive to use, but Sonnet wasn't good enough, is gone as of today.
It's more cost-effective. The same budget that could previously run only one Opus-level Agent can now run two or three parallel Sonnets.
The cost barrier for multi-Agent architectures has been kicked lower by Sonnet 5.
When Fable 5 will make its kingly return is still unknown.
But Sonnet 5 is already standing firmly here right now, with its performance pushed right up to Opus's doorstep.
For the vast majority of developers, it is the most capable and most usable Claude to have on hand for quite some time to come.
References:
https://x.com/claudeai/status/2072017450611142835
https://www.anthropic.com/news/claude-sonnet-5
This article is from the WeChat public account "New Zhiyuan", author: ASI Revelation





