Editor's Note: This article introduces a personal knowledge system built on Claude Code and Obsidian. Its core is no longer the traditional RAG model of "querying and retrieving temporarily each time," but rather an attempt to have AI continuously build and maintain an evolvable knowledge base (Wiki).
Structurally, this system can be divided into three layers:
· First, the raw data layer, including unmodifiable input sources like notes, articles, and transcripts;
· Second, the structured knowledge base maintained by AI, which continuously updates to complete cross-references and relationship building;
· Third, the Schema rule layer, used to standardize the organization of knowledge and the system's operational logic.
Around this structure, the system operates through three core functions: Ingest, to continuously bring external information into the system; Query, to enable instant access to knowledge; and Lint, to check structural consistency and fix potential issues.
Under this mechanism, knowledge no longer remains a one-time conversation result but is gradually沉淀 (precipitated) into a reusable long-term asset through the cycle of "writing — organizing — reusing." The author suggests that this model gives knowledge a compound interest-like accumulation effect: on one hand, it reduces the individual's cognitive load, and on the other hand, it improves the accuracy and contextual consistency of the model's output.
However, the effective operation of this system is also premised on one condition — continuous input and maintenance. Without a steady stream of data injection and structural updates, this "second brain" will struggle to form a true accumulation effect, and its advantages will diminish accordingly.
The following is the original text:
Claude Code + Obsidian is the most powerful AI combination I have ever used.
I have almost built an "AI second brain" that incorporates all my thoughts, reading, writing, online research, and more. This includes my business plans, all the YouTube videos I've published, articles I've written, and everything else important to me.
Claude Code + Obsidian has quickly become popular on various platforms, and this is no coincidence.
For me personally, this AI system has significantly reduced my cognitive burden, allowing me to focus my energy on what truly matters—whether it's business or personal life.

This system might look a bit complex, but it actually only takes 5 minutes to set up. More importantly, it has a built-in memory mechanism and continuously optimizes itself with use.
Next, I will guide you step-by-step to replicate this "AI second brain" system, which can tangibly improve your efficiency.
I recommend reading to the end of the article—I will include a complete Claude Code + Obsidian quick reference guide and all the resources mentioned (all free).
Before You Start
This system is not entirely my original creation; its inspiration came from a viral tweet by Andrej Karpathy a few days ago about an "LLM knowledge base."
Related reading: https://x.com/karpathy/status/2039805659525644595
This tweet went viral quickly because it offered an idea to solve a key pain point in current AI development.
That problem is: every time you start a new conversation or switch to a new AI tool, you have to repeatedly re-enter prompts and provide context, almost starting from scratch each time.
By combining this system prompt with Obsidian and Claude Code, this problem can be completely solved, while also significantly improving the quality of AI output.
How Does This System Work?
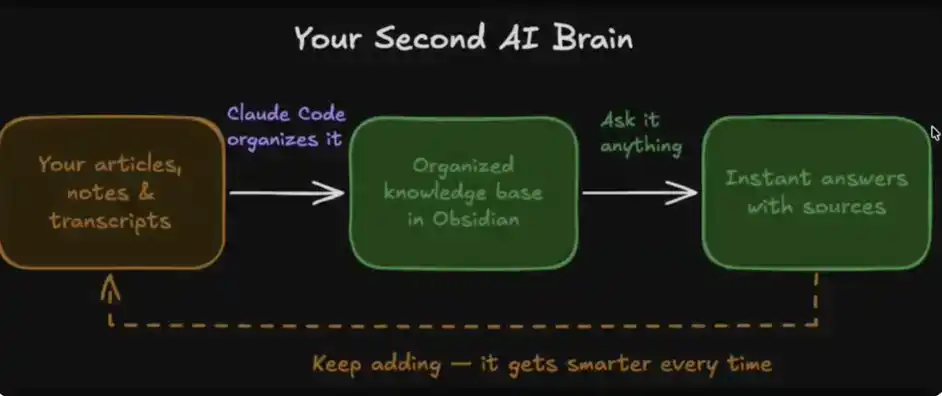
The entire system consists of four core modules:
1. Your Data: Includes articles, notes, transcripts, ideas, etc.
2. Organization: Automated organization in Obsidian by Claude Code
3. Instant Access: You can query this "database" at any time for answers
4. Evolving Memory: The system continuously becomes smarter with use
What is the real power of this system?
As humans, our cognitive bandwidth is limited. We forget, sometimes struggle to connect different ideas, and there's ultimately a limit to the amount of information we can track and process simultaneously.
With this four-module system, you are essentially offloading your cognitive burden, handing over the work of "connecting, organizing, and understanding information" to Obsidian and Claude Code.
Your ideas begin to be systematically linked; one note can automatically connect to another, and you can always extract, combine, and call upon these contents through Claude.
In this structure, your knowledge is no longer fragmented but a network that can be constantly called upon and reorganized—with almost no upper limit.
How to Build Your AI Brain in 5 Minutes
1. Download Obsidian
Official website: https://obsidian.md/
2. Create Your Vault
After downloading, Obsidian will prompt you to create a "Vault".
You can think of it as a folder on your computer where we will store everything and allow Claude Code to access and manage this data.
You can name this Vault whatever you like—I simply called mine "Obsidian Vault".
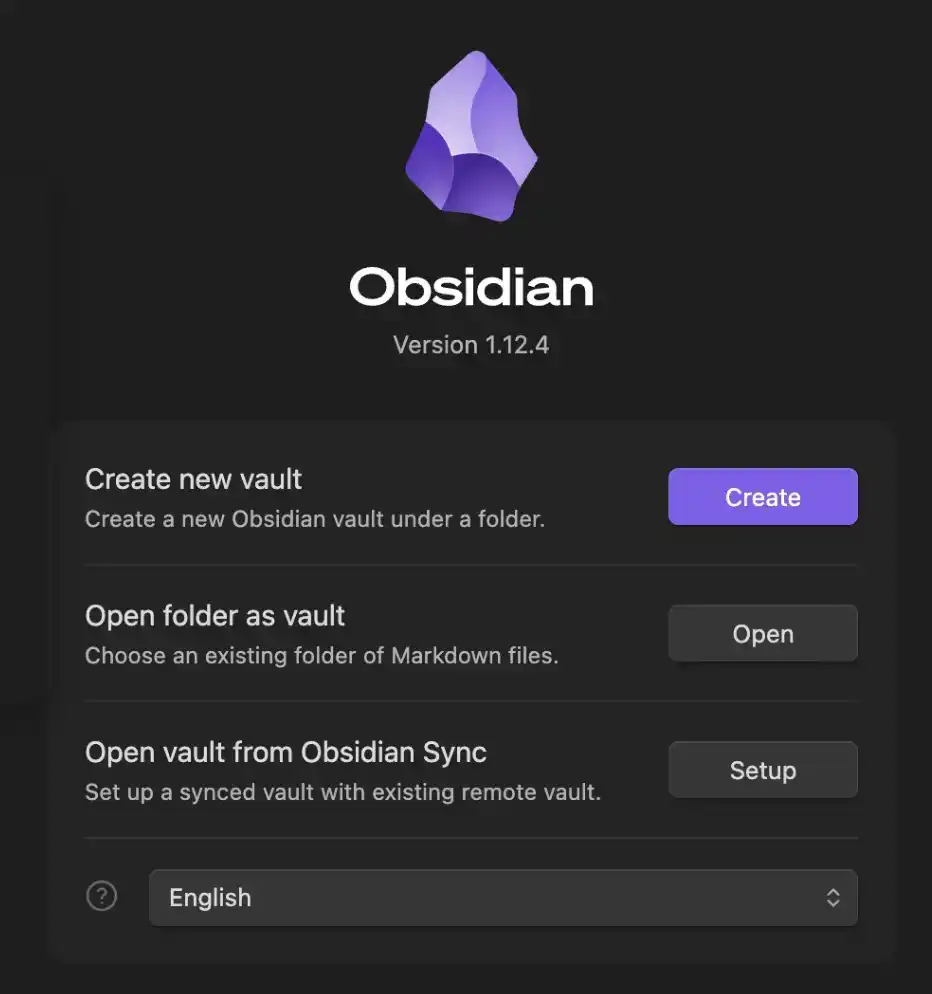
This Vault is where Obsidian stores all your data and notes; everything will be saved as MD (Markdown) files.
3. Set Up Claude Code
Next, you need to configure a way to access Claude Code. For me (and likely for most people), the simplest method is to use the desktop client directly.
In the main chat interface, click "Select Folder," then find and select the Obsidian Vault you just created.
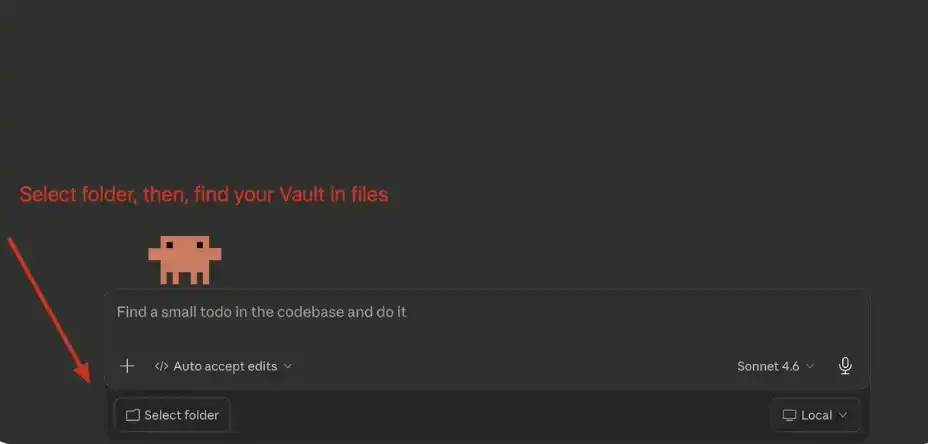
4. Set the System Prompt
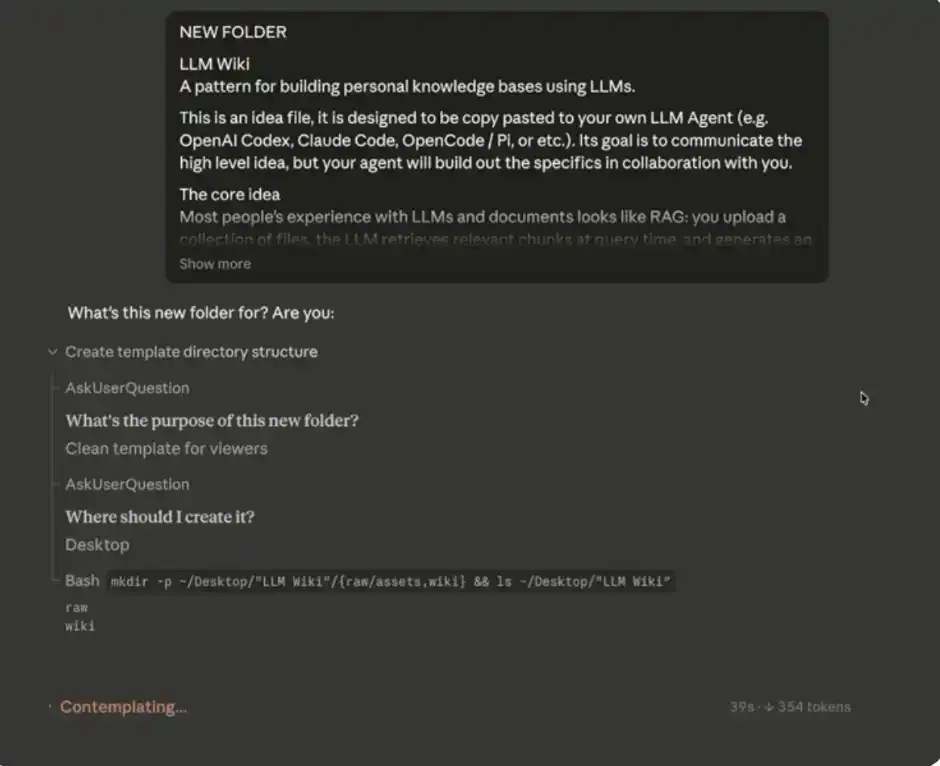
After selecting the folder, the next step is to paste Andrej Karpathy's system prompt into the main chat box.
You can copy the prompt here: https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f

Your input should look like this:
Tip: You don't necessarily have to open Obsidian manually if you don't want to. Simply give the MD folder (your Vault) and related data to Claude Code, and it can directly read, write, and modify these files—and these changes will automatically sync to your Obsidian "second brain."
5. Build Your Database
After you enter the system prompt, Claude Code will start asking you for some data sources to initialize and gradually populate your "second brain."
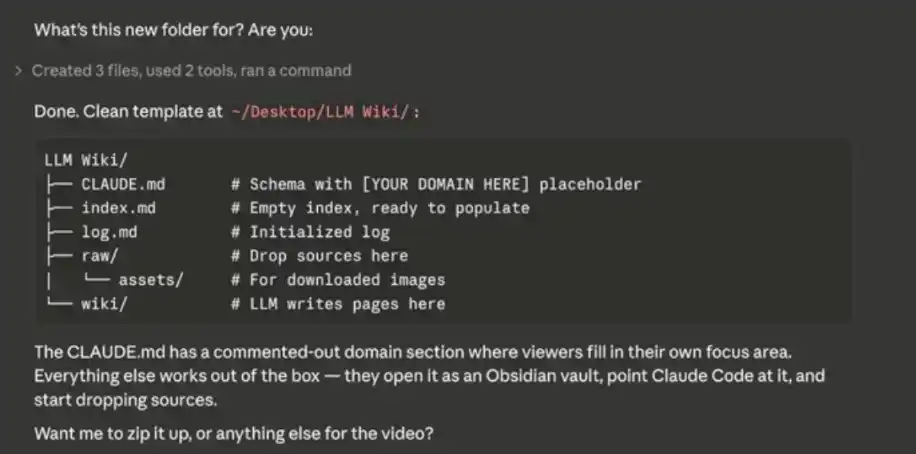
Think of Obsidian as a "blank notebook"—you need to actively input content at first for the database to gradually build up. Importable content includes: notes, CSV files, Markdown/text files, etc.
Some practical suggestions:
· Export data from your existing note-taking tools
· If you use Notion, you can export as CSV files
· Have Claude (or another LLM) organize information about you to initialize your "second brain"
· Import your existing writings, bookmarks, ideas, etc., all at once—this is the best time to establish initial data, and you can always add more later
Note that a database with a large amount of data, like mine, isn't built overnight but is accumulated over time through continuous input.

That's it, your "AI second brain" is set up and ready to run. Next, I'll share some pro tips to help you use it more efficiently.
Pro Tips
1. Obsidian Chrome Extension
If you want to add data to the system more easily, just install the Obsidian Chrome extension. It allows you to click "Add to Obsidian" while browsing the web to save content directly into your knowledge base. This makes the process of building your "second brain" very smooth.
I often use this feature myself to collect articles, web data, research materials, etc.
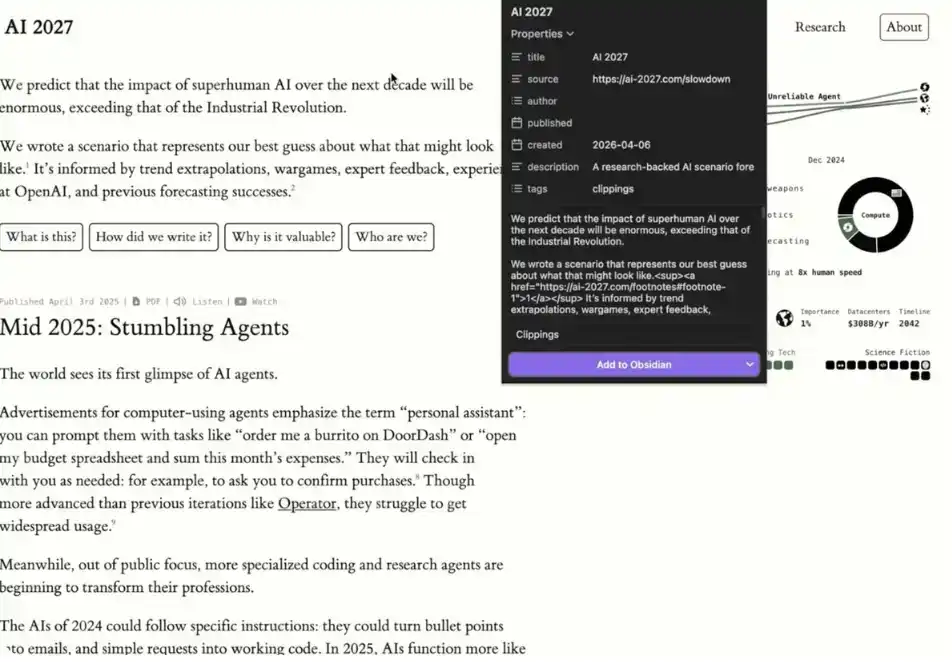
Note that data added via the extension is initially just an "isolated data source."
You can then tell Claude Code: "I just added [x] to Obsidian, please help me integrate this content into my Wiki."
Claude Code will automatically create links between this new data and existing content, truly integrating it into your "second brain." This is also why this tool combination is so powerful.
2. Use Separate Vaults
Andrej Karpathy recommends using two separate Vaults:
· One for work/business content
· One for personal life/goal management
My own experience is also that this structure is the clearest and most effective.
3. Practicality
I find one of the most valuable uses of this system is actually very simple: making your LLM prompts more precise.
When the model has access to your complete personal information, business plans, writing context, etc., it can generate more "customized," higher-quality prompts (even "super Prompts") that are closer to the real situation.
Of course, the uses of this system go far beyond this, but if you want to start with just one most practical scenario, I would strongly recommend starting with "improving prompt quality."
4. Orphans
In Obsidian, "Orphans" refer to data points that are not connected to other notes.
This feature is useful because it can help you:
· Find ideas that haven't been integrated yet
· Discover "weak areas" in your database
· Determine which content is worth further expansion or deepening
In other words, it's not just an organizational tool but also a mechanism to help you discover blind spots in your thinking.

You can click the "three dots" in the upper right corner to find and turn on the Orphans switch to see which content hasn't been linked yet.
Potential Drawbacks of This System
We've covered many advantages, use cases, and optimization methods. So what are its shortcomings? Under what circumstances might this system not be suitable for you?
1. For those not accustomed to visualization
A core advantage of this system is the ability to visualize data. If you don't rely on or are not accustomed to this approach, its benefits for you might be limited.
2. Requires some maintenance cost
If you are unwilling to continuously maintain a database, this system might not be for you. Although the maintenance cost is not high, without continuously inputting data into the "second brain," it's difficult for it to provide value.
3. Storage usage
All content is stored locally as Markdown files, which will occupy some device space. This also needs to be considered in advance.





