原创|Odaily 星球日报(@OdailyChina)
作者|Wenser(@wenser 2010)

8月9日,当下最为火热的新兴发币平台 BAGS 官方发文庆祝平台交易量突破1.1亿美元,其市场份额也增长至 23.5%,首次超越 LetsBonk.fun 跃居第二,仅次于老牌Meme发币平台 Pump.fun。而在 Nyan Cat 创作者、Chillguy 创作者等艺术家的接连发声后,BAGS 也以“名人+慈善”概念成为了Meme市场为数不多的注意力焦点。
关于 BAGS 平台的详细介绍,可参考Odaily星球日报南枳的《BAGS 收入跃居 Solana 第二,一文速览必备基础工具》一文,而在本文,我们要聊的,则是 BAGS 平台背后的两则稍显另类的“闹剧”。
“闹剧”一:创始人明牌站队BTH代币,花别人的钱买帽子,版税揣自己兜里?
正如加密人群所熟知的那样,对于一键发币平台而言,流动性和注意力是唯二重要的事情,而注意力往往能够吸引流动性的不断涌入。
正因如此,BAGS 平台创始人 FINN 选择参与 WIF HAT 原型帽子的拍卖,但令人非议的是,其并未使用自己的资金参与竞拍,而是选择了使用BTH手续费参与竞拍。
据 X 平台用户伊藤开司(@kaisi 420)发文爆料,如同曾经加密人群众筹集资参与美国宪法拍卖发起 Constitution DAO 一样,原本有个借助加密社区“集资买帽子”概念的 Meme 币 BWH(简称 OG 币)率先突围,收获了大量注意力及流动性,市场表现有破圈潜力。但 BAGS 平台创始人 @finnbags 并不甘心错失这一波渔翁之利。
其反其道而行之,选择买入另一个名为 BTH 的Meme 币,借此,发币及交易等相关手续费成为他的囊中之物,之后,其再度打着“由我来拍卖 WIF 原型帽子”的名号堂而皇之地收割市场、消费名声。
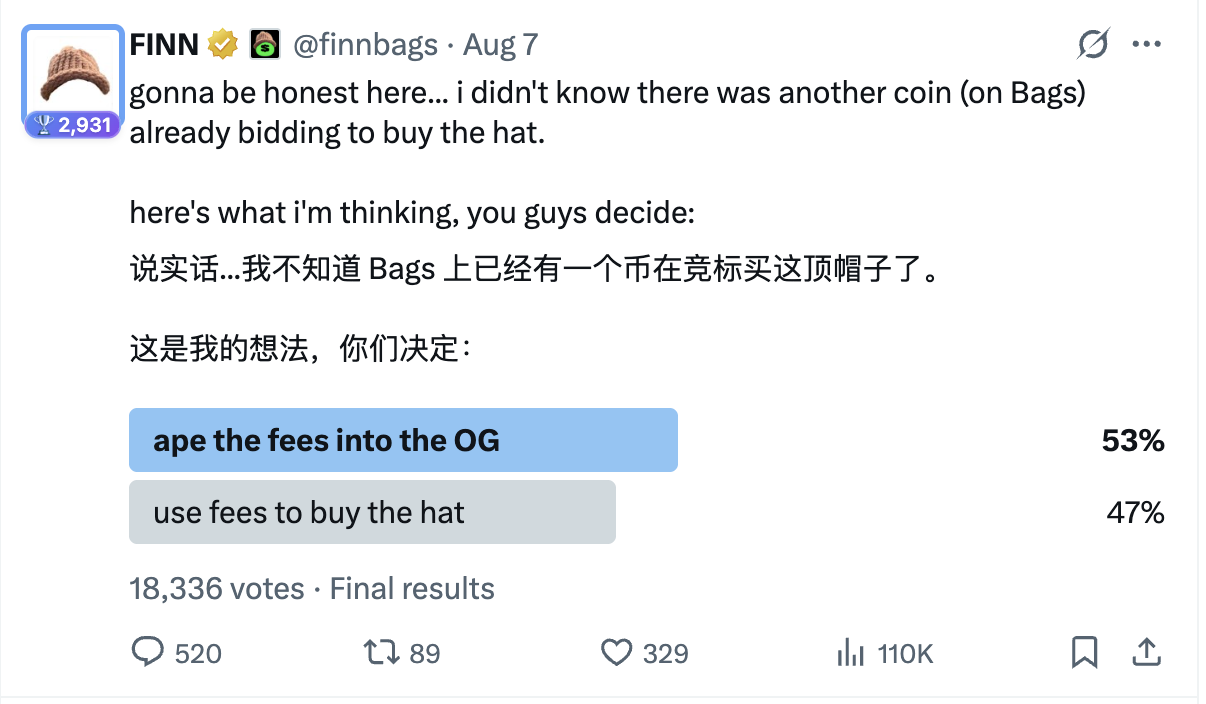
这一行为使得原本的 OG币市值一度下跌至 10万美元级别,在社区众人的努力下才慢慢稳住了局面,市值迎来逐步修复。而 FINN 的行为自然也引发了社区的极度不满,不少人纷纷声讨其流氓行径,而前者的回应则是——对 OG 币 BWH 的存在并不知情。随后,其还发起了“假意”尊重社区呼声的“投票”,让社区二选一:
A 将 BTH 的手续费拿去买 OG 币 BWH;
B 由 BTH 产生的手续费去买 WIF 原型帽子。

FINN 的假意声明
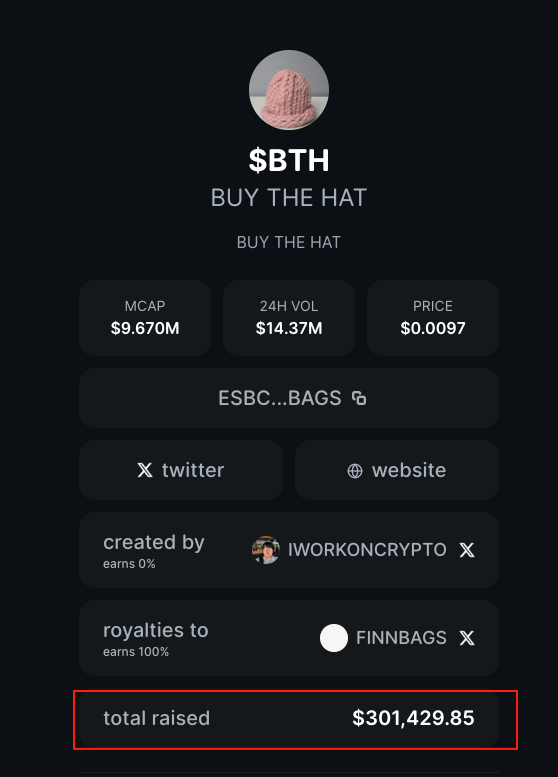
而尽管投票结果显示,A 选项的票数更多(即支持OG币 BWH),但 FINN 仍然一意孤行,选择执行 B 选项,耗资。与此同时,FINN 则以 BTH 获得了 BAGS 平台发起的“25万美元挑战赛”(即首个在 BAGS 平台市值突破1000万美元并保持 24小时)的理由,将该代币的 30万美元的版税收入囊中,来了一出“狸猫换太子”。
图片来源:Memeshot.com
毫无疑问,在装傻充愣、混淆视听这方面,FINN 绝对是个中好手,其将 OG币 BWH 与自己坐拥版税的 BTH 混为一谈的同时,还以 WIF 原型帽子拍卖事件为炒作机会,让加密市场以及诸多艺术家、创作者快速地加入了 BAGS 的平台阵营,而 BAGS 的近7日平台收入也不孚众望地超越了 letsBONK.fun,仅次于 Pump.fun。
但这出“帽子币闹剧”,却很难不让人对其人品打上一个大大的问号。
闹剧二:未经验证的平台 BUG——X平台 ID 决定代币版税领取权
与上面的“创始人人品闹剧”相比,这个闹剧暂时并未得到官方验证,但也从侧面为 BAGS 平台及用户提了个醒。
据 X 平台用户 @Researchcai 发文提醒,BAGS 平台疑似存在 BUG,即“一个币的手续费归属权是只看推特的用户名的,SPARK 的推特用户名改掉了,然后被人抢注了,抢注的那个人领取了 BAGS 里面的 6 万 U 手续费,这个币以后的手续费都归抢注的这个人了”。
截止目前,该 BUG(或功能)暂未得到 BAGS 平台层面的回应,对于 X 平台 ID(即Twitter Handle)的权属与代币版税之间的从属关系也并未得到明确说明,Odaily星球日报也将继续跟进相关动态。





