原文作者:Storm Slivkoff、Georgios Konstantopoulos
原文编译:Luffy,Foresight News
以太坊状态增长及其与 Gas 限制的关系被广泛误解。人们普遍认为状态增长是以太坊的主要扩展瓶颈。然而,关于状态增长的讨论常常因术语不精确和缺乏详细的定量证据而受阻。
采用数据驱动的方法可以使状态增长问题变得更加清晰。在本文中,我们利用高分辨率数据集来了解状态增长的大小和形状。在这个过程中,我们得出了令人惊讶的结论:现代消费硬件可以维持当前的状态增长率至少十年。此外,考虑到软件和硬件的不断改进,这条跑道可能会无限期地延长。
我们相信,以太坊有一个明确的路线图: 1)完全消除状态增长作为扩容瓶颈;2)将 Gas 限制提高到支持全球规模去中心化金融体系的水平。本文系列的目标是开发一种科学方法来理解和制定这一扩展路线图。
本文是有关以太坊扩容系列文章的第 1 部分,主要介绍状态增长,第 2 部分是关于历史增长,第 3 部分是关于状态访问,第 4 部分是关于 Gas 限制。
什么是状态增长?
「状态增长」一词通常用来概括任何以太坊扩展瓶颈,即数据大小超过以太坊节点硬件的容量。然而,状态增长不应该以这种单一的方式来思考。以太坊数据有多种类型,每种类型都与节点的底层硬件组件有独特的关系。因此,使用精确的术语来解释每个不同的扩展瓶颈至关重要。
状态是构建和验证新以太坊区块所需的一组数据。状态由合约字节码、合约存储、账户余额和账户随机数组成。历史是节点从创世区块同步到最新区块所需的数据集。历史由区块和交易组成。状态和历史是不重叠的数据集。从这些定义来看,至少有 3 种不同的现象给节点的硬件带来了巨大的压力:
状态增长:新账户、新合约字节码、新合约存储的积累。
历史增长:新区块和新交易的积累。
状态访问:用于构建和验证区块的一组读写操作。
每个瓶颈都与节点的硬件限制有独特的关系。四个相关性最高的硬件限制是:
网络 IO 是节点为了与对等节点达成稳定共识而必须维持的上传和下载速度量。
存储大小是节点为了构建、验证和分发区块而必须在永久存储中保存的数据量。
内存大小是节点必须在内存中缓存的数据量,以便与区块链的末端保持同步。
存储 IO 是节点为了与区块链末端保持同步而必须执行的每秒读写操作量。
这些瓶颈和硬件限制之间的关系如图 1 所示。
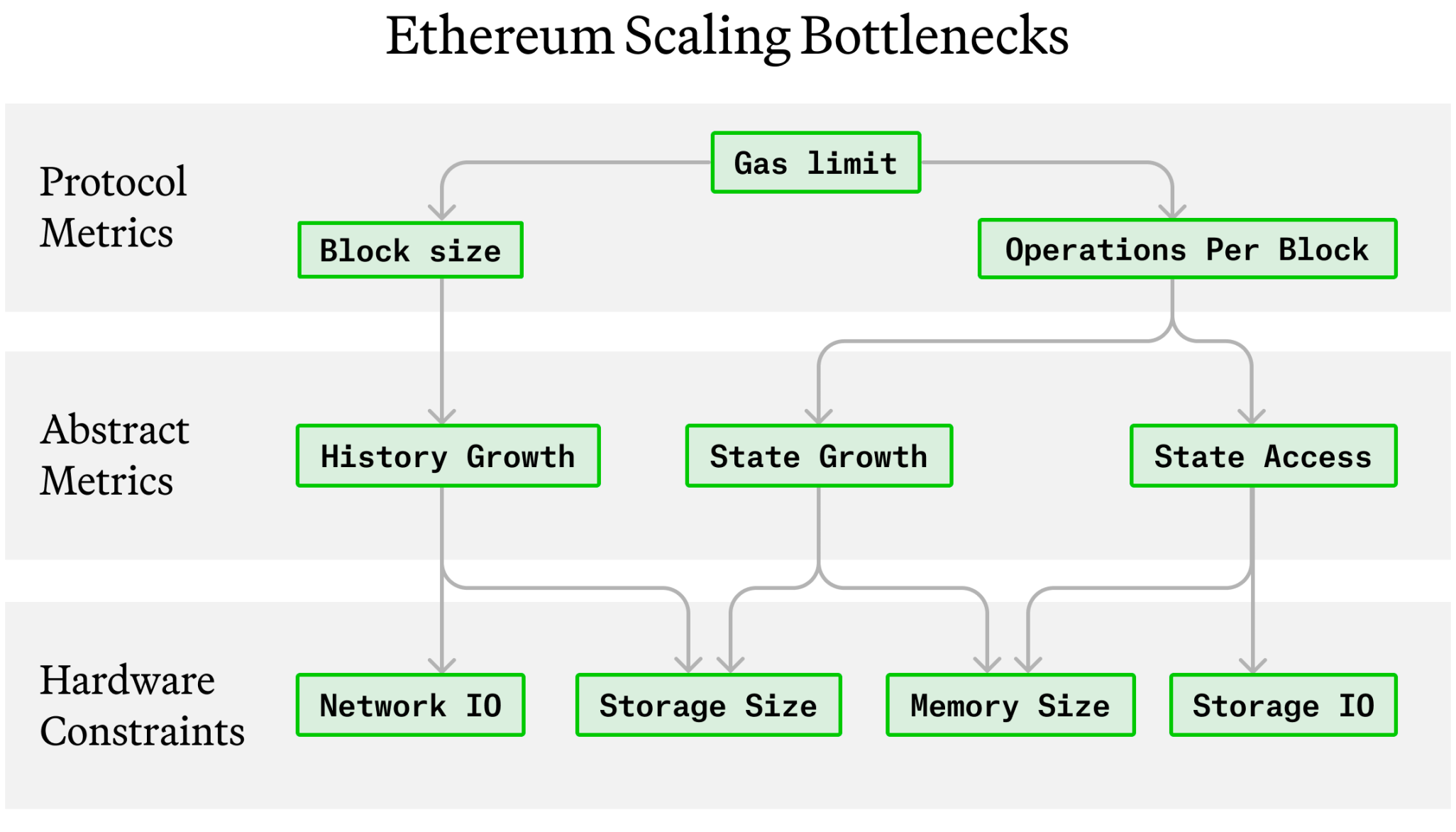
图 1 :以太坊扩容瓶颈
从图的顶部开始,每次以太坊执行交易时,该交易使用的所有资源都以 Gas 定价。因此,以太坊的 Gas 限制是一个单维量,它对所有形式的链上活动进行速率限制。 Gas 限制的下游是区块大小和每个区块的操作。每个区块的字节越多,历史记录增长得越快。每个区块的 IO 操作越多,状态访问率越大,并且(通常)状态增长率也越大。
因此,扩展瓶颈与节点的硬件约束有关,如下所示:
为了支持大量的状态增长,节点必须有足够的存储和内存空间。如果状态变得太大,则要么无法容纳在存储中,要么状态的频繁访问部分将无法包含在内存中,从而使得性能降低。
为了支持大量的历史增长,节点必须有足够的网络带宽来共享大量的区块数据和足够的存储容量来存储该数据。
为了支持大量的状态访问,节点必须有大量的内存来缓存热状态,并有大量的存储 IO 来支持足够的读写操作。
特别是对于状态增长而言,主要挑战是确保状态规模的增长速度不会超过消费者硬件的持续改进。节点内存和存储是有限的资源,因此它们最终将达到瓶颈,除非状态停止增长或硬件定期升级。幸运的是,内存和存储硬件多年来一直在改进。即便如此,对这些改进的准确预测仍不确定,并且不应认为它们的快速增长将无限期地持续下去。
请注意,即将推出的 EIP-4844 引入的数据 blob 将为这些扩展关系带来一些变化。在 EIP-4844 之后,预计磁盘上累积的历史记录会少得多,传输大量 Blob 数据时网络 IO 可能会显着增加。
在本文中,我们将主要关注状态大小和状态增长率,而不是内存大小和状态访问模式。我们将在未来的工作中研究其他主题。
以太坊状态的组成
理解状态增长的下一步是检查状态的总规模以及每个状态贡献的大小。目前,以太坊状态数据量约 245.5 GB。这个数字是使用 reth 节点测量的,但每个节点客户端的数字大致可以比较,如表格所示。账户、合约字节码和合约存储分别占据状态的 14.1% 、 4.3% 和 81.7% 。
图 2 显示了各类智能合约协议占用了多少状态规模。下图中,每个合约类别的大小表示其存储槽和字节码占用的字节数。
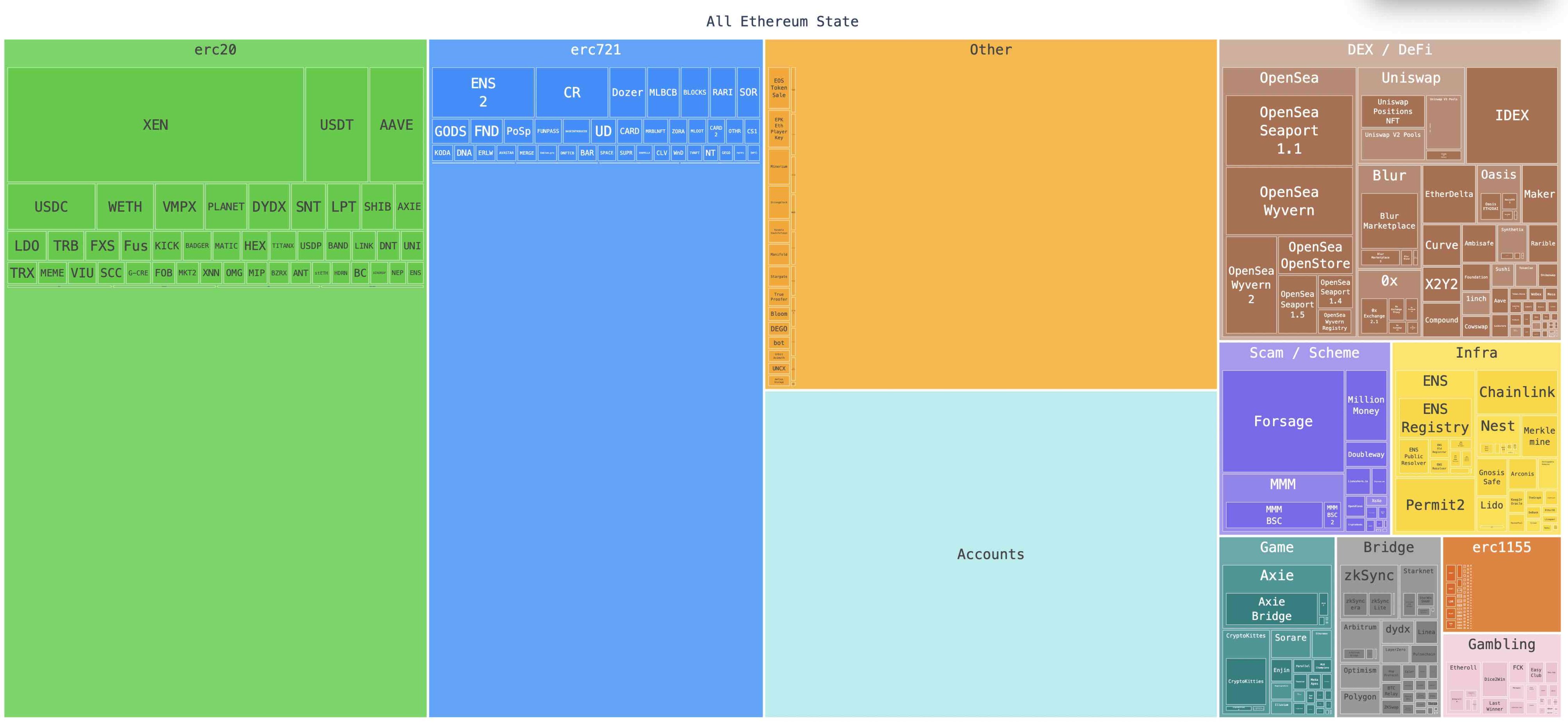
图 2 :以太坊状态分布
图 2 中的数字表示节点客户端必须在磁盘上存储的总字节数。这包括索引使用的数据和其他类型的存储开销。每个账户和每个存储槽的平均存储大小分别为 133.6 字节和 191.3 字节。
以下是图 2 中一些最重要的信息:
代币是状态的最大贡献者。以太坊状态的最大贡献者是 ERC-20 和 ERC-721 代币,分别占据状态的 27.2% 和 21.6% 。代币之所以占用如此多的状态,是因为每个代币的每个用户余额必须单独存储在自己的 32 字节存储槽中。因此,以太坊状态规模的一半与以太坊用户总数和每个用户持有的代币总数成比例。
以太坊至少 7.4% 的状态处于休眠中。以太坊状态中的一些最大的合约不再活跃。这些协议发布于区块空间和状态空间比现在便宜得多的时候,包括游戏、赌博和诈骗类别中的大多数协议,还有许多不再活跃的 DEX,包括 IDEX、Etherdelta 和 Oasis。这些协议总共构成了以太坊状态的至少 7.4% 。休眠状态的真实水平更高,因为它还包括 ERC-20、ERC-721 和其他类别中的长尾项目。
L2 跨链桥占据以太坊状态的不到 2% 。通过利用压缩、ZK 证明和改进的编码等技术,L2 交易比主网更有效地利用状态。尽管 L2 仅占主网状态的 2% ,但 L2 每秒的总交易数量比主网多 5 倍。
以太坊状态增长有多快?
状态增长最重要的方面是状态增长率随时间的变化。这个比率揭示了状态问题的严重性及其变化趋势。
图 3 显示了自 2015 年以太坊成立以来的状态增长率。这些增长率是通过对每个合约类别中的合约字节码和合约存储求和来计算的。
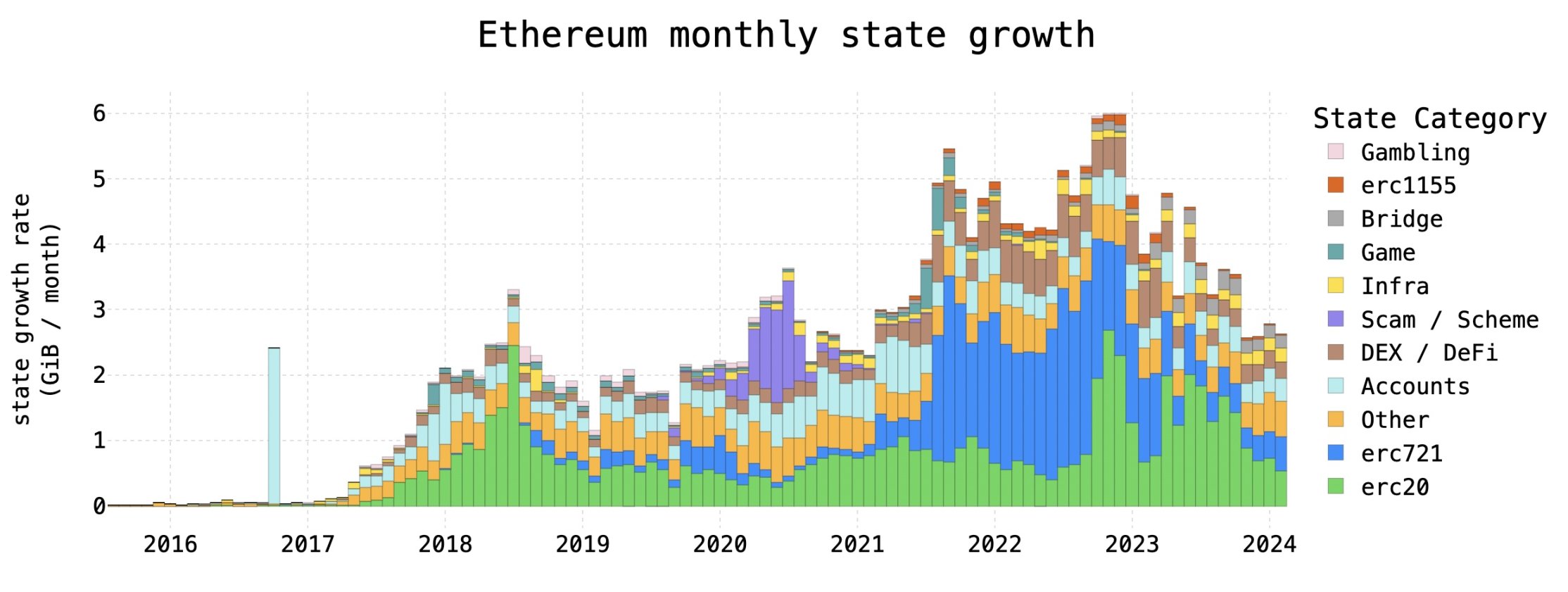
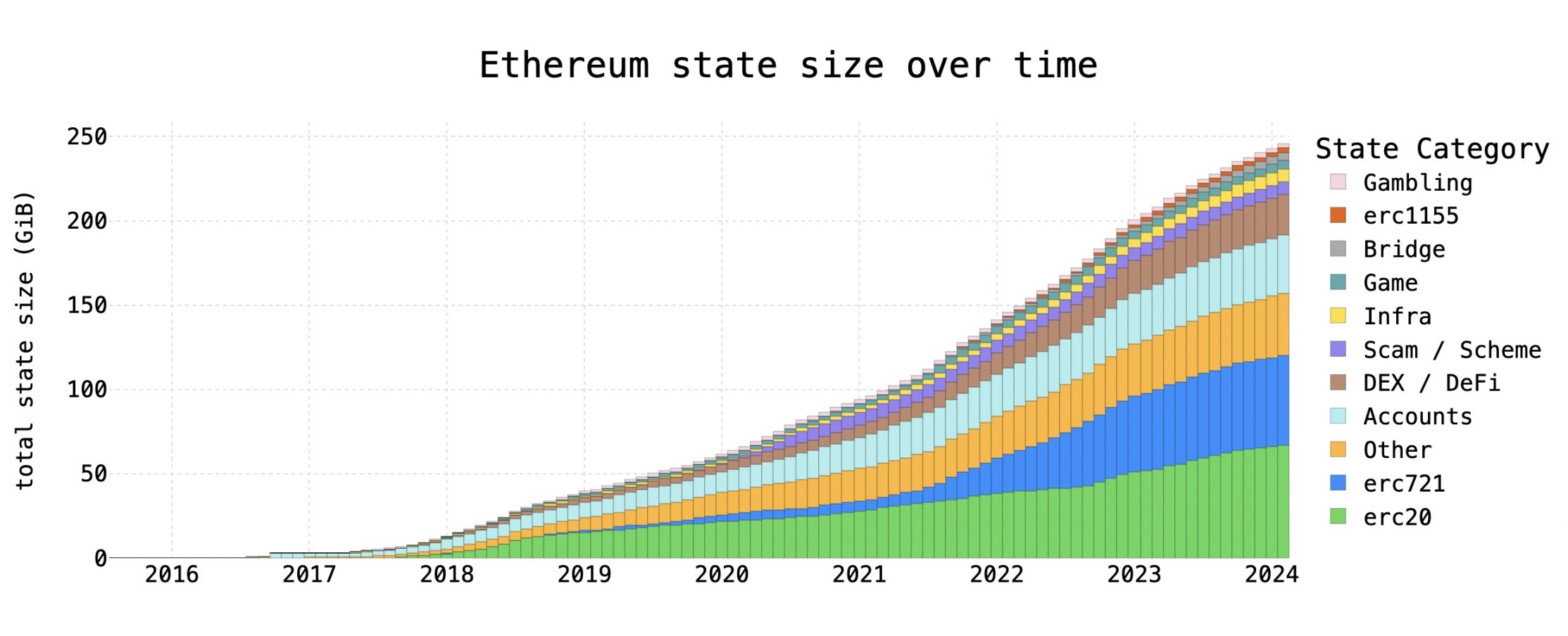
图 3 :以太坊状态随时间的增长
以下是图 3 一些最重要的信息:
目前,状态每月增长约 2.62 GB,低于每月 5.99 GB 的峰值。通过这些数字预测 5 年内状态总规模将在 396 GB 到 606 GB 之间。尽管人们可能将当前的增长率描述为每年 12.8% ,但在状态持续增长的同时,绝对增长率一直在下降,因此简单的指数增长可能不是一个合适的模型。
最近状态增长的下降主要是因为 NFT 活动的减少。尽管人们可能期望不同类型的网络活动之间存在一定程度的相关性,但各个状态贡献者之间存在令人惊讶的独立性。例如,尽管过去几年总状态增长率有所下降,但自 2020 年以来,ERC-20 状态增长率实际上每年都在增加。
状态增长达到 2021 年以来的最低水平。这种下降相当令人惊讶,但考虑到状态主要与新代币余额的成正比,这是有道理的。如果状态增长率一直在下降,人们可能会认为以太坊有能力支持更高的 Gas 限制。这可能是事实,但重要的是要记住: 1)在当前的 Gas 定价模型下,没有什么可以阻止增长率的新一轮飙升, 2)状态并不是 Gas 限制下游的唯一瓶颈。
可接受的状态增长值是多少?
我们现在知道以太坊状态的 1) 规模、 2) 组成和 3) 增长率。我们如何确定可接受的状态增长值的范围?这个问题很复杂,因为它既取决于不可预测的市场力量,也取决于以太坊应该做出哪些权衡的哲学选择。
让我们从最简单的模型开始,假设未来硬件没有改进,当前的状态增长水平在普通消费硬件上可持续多久。如图 3 所示,近年来状态的年增长一直在 31 GB/ 年到 72 GB/ 年之间。目前,常见的消费类硬件最高存储容量约为 4 TB ,内存容量约为 64 GB。由此我们可以创建一个简单的存储和内存需求预测模型:
存储:节点当前总共需要存储大约 1 TB 的状态数据。实际上,这意味着许多节点正在使用大小至少为 2 TB 的磁盘。为简单起见,让我们忽略未来的历史增长,就好像我们处于后 EIP-4444 的世界中一样。我们可以计算出未来运行时间为:(剩余存储容量)/(状态增长率),如表格所示。因此,节点存储硬件可以支持当前的状态增长速度十多年,而不会耗尽 2 TB 的空间。按照目前的状态增长水平, 4 TB 足以支持运行近半个世纪。
内存:Ethereum-on-arm 用户报告称,运行以太坊节点的最小可行内存约为 16 GB。如果我们假设内存需求与状态大小成比例增长,那么每年 30 GB 到 72 GB 的状态增长将转化为每年需要 2 GB - 4.7 GB 的额外内存。因此,按照当前的 Gas 率, 32 GB RAM 应该足够使用 3 年到 8 年。 64 GB 的 RAM 应该足够使用 10 年到 23 年。
这是一个带有许多假设条件的简化模型。该模型可能的扩展条件包括 1) 历史增长, 2) 内存需求的非线性扩展, 3) 降低硬件成本, 4) 增加 Gas 限制, 5) 操作码 Gas 重新定价,以及 6) 未来以太坊架构改进。这些因素中的每一个都可以非线性相互作用并随着时间的推移而演变。我们将在未来的工作中探索这些模型扩展。
必须强调的是,长期可持续性是一件好事。即使现代硬件可以支持多年的运行,也不应该掉以轻心地缩短可运行时间。任何加速状态增长的计划都应该包括一个重要的缓冲区,以应对硬件或软件环境不可预测的变化。
如何解决状态增长问题?
为了解决状态增长问题,人们提出了许多不同的方案。以太坊架构的三项改进非常突出:Rollup、Verkle 尝试和状态过期。总而言之,这些构成了解决短期、中期和长期状态增长问题的综合路线图。
短期:Rollup 不能解决状态增长问题,但它们确实减轻了网络负担。如图 2 和图 3 所示,Rollup 能够比主网更有效地使用状态。将活动转移到 L2 确实需要在主网上存储一定量的状态,以支持用户退出。然而,L2 交易的状态足迹远低于主网上交易的足迹。因此,Rollup 可以更可持续地增加生态系统中的总活动。随着即将推出的 EIP-4844 ,Rollup 的采用预计将会增长,blob 将使 Rollup 变得更加便宜。
中期:Verkle 尝试解决验证器节点的状态增长问题,但不解决需要构建新交易的节点的问题。Verkle 尝试是以太坊状态的新数据结构。它们支持更高效的轻客户端和「无状态」节点。这些节点将能够在不了解现有状态值的情况下验证新区块。这消除了验证器节点的状态增长问题。新交易的构建仍然需要存储和访问状态,但这仍然比我们今天的情况更可持续,因为交易构建是一项可以轻松分布在许多机器上的任务。就范围而言,Verkle 尝试代表了一项可能需要数年时间才能实施的重大工程。
长期:状态过期解决了所有节点的状态增长问题,但需要额外的基础设施。状态到期允许节点丢弃状态的不活动部分,如图 2 。请注意,术语「状态休眠」可能是一个更合适的名称,因为大多数现有提案允许通过证明恢复「过期」状态。关于过期状态随着时间的推移而丢失的担忧,只要历史记录(区块和交易数据)可用,就可以重建状态。因此,无论为 EIP-4444 的历史保存问题开发什么解决方案,也都将解决状态保存问题。但如果 Verkle 尝试成功实现其目标,状态到期可能就不必要了。
状态增长问题的解决方案还有更多,其他包括状态租金和分片,但从历史上看,这些可能对用户体验或健全性产生影响。为了在更遥远的将来实现最终解决方案,可能需要将这些解决方案与其他解决方案结合起来。
总结
尽管状态增长是扩展以太坊的一个关键挑战,但我们相信这是一个可以解决的问题。通过我们对数据的解读,以太坊可以维持当前的状态增长水平多年,并为架构升级提供了舒适的缓冲。
我们相信,经验方法对于设计以太坊的 Gas 限制和引导以太坊走向最终的扩展解决方案至关重要。本文只是实现这一目标的一步。还有其他类型的超越状态的数据,每种数据都对以太坊节点和以太坊 Gas 限制施加了负担。我们希望在未来的工作中探索这些其他瓶颈。





