En el proceso de crear @insidersdotbot, he tenido conversaciones profundas con varios equipos de market making de alta frecuencia y arbitraje, y una de las mayores demandas ha sido cómo desarrollar estrategias de arbitraje.
Nuestros usuarios, amigos y socios están explorando la ruta compleja y multidimensional del arbitraje en Polymarket. Si eres un usuario activo de Twitter, estoy seguro de que has visto tweets como "Gané X cantidad de dinero con la estrategia de arbitraje XX en los mercados de predicción".
Sin embargo, la mayoría de los artículos simplifican demasiado la lógica subyacente del arbitraje, haciéndolo parecer como "yo también puedo hacerlo" o "solo usa Clawdbot", sin explicar detalladamente cómo entender sistemáticamente y desarrollar tu propio sistema de arbitraje.
Si quieres entender cómo las herramientas de arbitraje en Polymarket ganan dinero, este artículo es la explicación más completa que he visto hasta ahora.
Dado que el original en inglés tiene partes muy técnicas que requieren mayor investigación, lo he reestructurado y complementado para que, con solo este artículo, puedas entender todos los puntos clave sin tener que parar a buscar información.
El arbitraje en Polymarket no es un simple problema matemático
Ves un mercado en Polymarket:
Precio YES $0.62, precio NO $0.33.
Piensas: 0.62 + 0.33 = 0.95, menos de $1, ¡hay oportunidad de arbitraje! Compras YES y NO por $0.95, sin importar el resultado, recuperas $1.00, ganancia neta $0.05.
Tienes razón.
Pero el problema es: mientras tú haces manualmente esta suma, los sistemas cuantitativos ya están haciendo algo completamente diferente.
Están escaneando simultáneamente 17,218 condiciones, abarcando 2^63 combinaciones posibles de resultados, encontrando todas las contradicciones de precios en milisegundos. Para cuando tú terminas de colocar tus dos órdenes, el spread ya ha desaparecido. El sistema ya encontró la misma oportunidad en docenas de mercados relacionados, calculó el tamaño óptimo de posición considerando la profundidad del libro de órdenes y las comisiones, ejecutó todas las operaciones en paralelo y movió el capital a la siguiente oportunidad. [1]
La brecha no es solo velocidad. Es la infraestructura matemática.
Capítulo 1: Por qué la "suma" no es suficiente — El problema del politopo marginal
La falacia del mercado único
Veamos un ejemplo simple.
Mercado A: "¿Ganará Trump las elecciones en Pensilvania?"
Precio YES $0.48, precio NO $0.52. Suman exactamente $1.00.
Parece perfecto, sin oportunidad de arbitraje, ¿verdad?
Error.
Añade un mercado y el problema aparece.
Mercado B: "¿Superará el Partido Republicano al oponente por más de 5 puntos porcentuales en Pensilvania?"
Precio YES $0.32, precio NO $0.68. También suman $1.00.
Ambos mercados individualmente son "normales". Pero hay una relación lógica de dependencia:
Las elecciones presidenciales de EE.UU. no cuentan votos a nivel nacional, sino por estado. Cada estado es un "campo de batalla" independiente; quien obtenga más votos en ese estado, se lleva todos los votos electorales (el ganador se lo lleva todo). Trump es el candidato republicano. Así que "el republicano gana en Pensilvania" y "Trump gana en Pensilvania" son lo mismo. Si el Partido Republicano gana por más de 5 puntos, no solo significa que Trump ganó Pensilvania, sino que lo hizo por mucho.
En otras palabras, el YES del mercado B (victoria aplastante republicana) es un subconjunto del YES del mercado A (victoria de Trump) — una victoria aplastante implica victoria, pero victoria no necesariamente implica victoria aplastante.
Y esta dependencia lógica crea oportunidades de arbitraje.
Es como apostar por dos cosas — "¿lloverá mañana?" y "¿habrá tormenta eléctrica mañana?".
Si hay tormenta eléctrica, definitivamente está lloviendo (la tormenta es un subconjunto de la lluvia). Así que el precio de "tormenta YES" no puede ser mayor que el precio de "lluvia YES". Si el mercado valora violando esta lógica, puedes comprar bajo y vender alto, ganando "beneficio libre de riesgo", eso es arbitraje.
Explosión exponencial: por qué la búsqueda por fuerza bruta no funciona
Para cualquier mercado con n condiciones, teóricamente hay 2^n combinaciones posibles de precios.
¿Suena manejable? Veamos un caso real.
Mercado del Torneo NCAA 2010 [2]: 63 partidos, cada uno con resultado ganar/perder. El número de combinaciones posibles de resultados es 2^63 = 9,223,372,036,854,775,808 — más de 9 trillones. Había más de 5000 apuestas en el mercado.
¿Qué tan grande es 2^63? Si revisas mil millones de combinaciones por segundo, te tomaría unos 292 años revisarlas todas. Por eso la "búsqueda por fuerza bruta" es completamente inviable aquí.
¿Revisar cada combinación una por una? Computacionalmente imposible.
Mira las elecciones de EE.UU. 2024. El equipo de investigación encontró 1,576 pares de mercados con posibles dependencias. Si cada par tiene 10 condiciones, entonces cada par requiere revisar 2^20 = 1,048,576 combinaciones. Multiplicado por 1,576 pares. Para cuando tu portátil termine de calcular, los resultados electorales ya habrán sido anunciados.
Programación entera: usar restricciones en lugar de enumeración
La solución de los sistemas cuantitativos no es "enumerar más rápido", sino no enumerar en absoluto.
Usan programación entera (Integer Programming) para describir "qué resultados son legales".
Veamos un ejemplo real. Mercado del partido Duke vs Cornell: cada equipo tiene 7 apuestas (0 a 6 victorias), 14 condiciones en total, 2^14 = 16,384 combinaciones posibles.
Pero hay una restricción: no pueden ambos ganar más de 5 partidos, porque se encontrarían en semifinales (solo uno puede avanzar).
¿Cómo maneja esto la programación entera? Tres restricciones son suficientes:
· Restricción uno: De las 7 apuestas de Duke, exactamente una es verdadera (Duke solo puede tener un número final de victorias).
· Restricción dos: De las 7 apuestas de Cornell, exactamente una es verdadera.
· Restricción tres: Victoria de Duke en 5 partidos + Victoria de Duke en 6 partidos + Victoria de Cornell en 5 partidos + Victoria de Cornell en 6 partidos ≤ 1 (no pueden ambos ganar tantos).
Tres restricciones lineales, reemplazando 16,384 verificaciones por fuerza bruta.
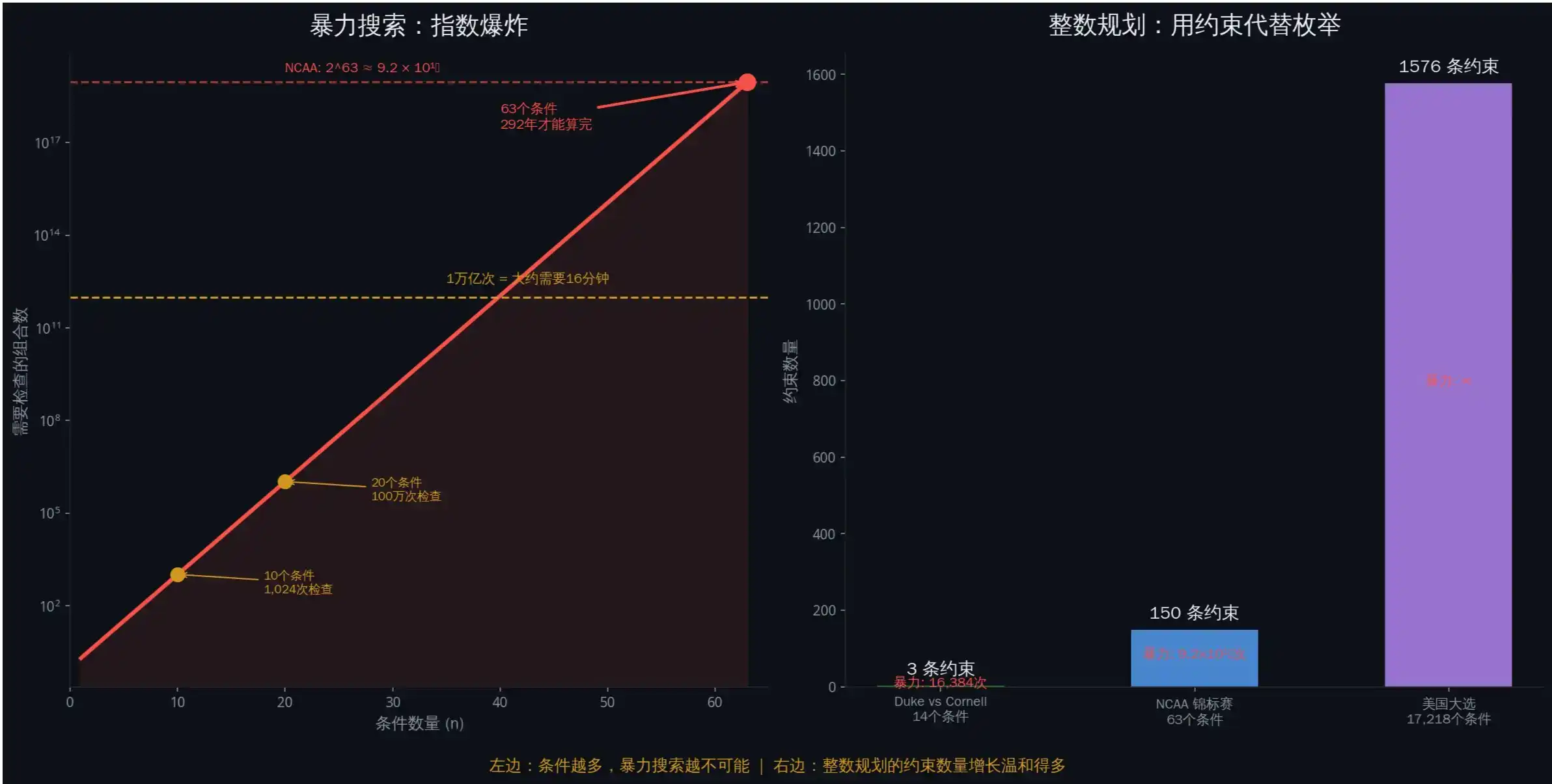
En otras palabras, la búsqueda por fuerza bruta es como leer cada palabra en un diccionario para encontrar una. La programación entera es como ir directamente a la página que comienza con esa letra. No necesitas revisar todas las posibilidades, solo necesitas describir "cómo se ve una respuesta legal" y dejar que el algoritmo encuentre las valoraciones que violan las reglas.
Datos reales: 41% de los mercados tenían arbitraje [2]
El artículo original menciona que el equipo de investigación analizó datos de abril 2024 a abril 2025:
• Revisaron 17,218 condiciones
• De ellas, 7,051 condiciones tenían arbitraje de mercado único (41%)
• Mediana de desviación de precios: $0.60 (debería ser $1.00)
• 13 pares confirmados de arbitraje explotable entre mercados
Una mediana de desviación de $0.60 significa que el mercado se desvía consistentemente un 40%. Esto no es "casi eficiente", es "masivamente explotable".
Capítulo 2: Proyección de Bregman — Cómo calcular la operación de arbitraje óptima
Detectar el arbitraje es un problema. Calcular la operación de arbitraje óptima es otro.
No puedes simplemente "tomar un promedio" o "ajustar un poco el precio". Necesitas proyectar el estado actual del mercado al espacio legal libre de arbitraje, manteniendo la estructura de información en los precios.
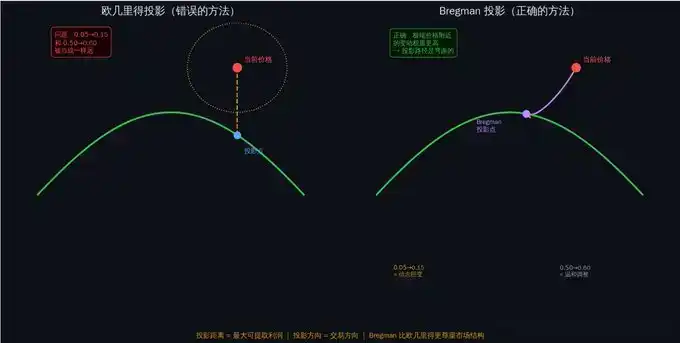
Por qué la "distancia en línea recta" no funciona
La idea más intuitiva es: encontrar el "precio legal" más cercano al precio actual, y operar la diferencia.
En lenguaje matemático, minimizar la distancia euclidiana: ||μ - θ||2
Pero esto tiene un problema fatal: trata todos los movimientos de precio como iguales.
Pasar de $0.50 a $0.60, y pasar de $0.05 a $0.15, ambos son aumentos de 10 centavos. Pero su contenido de información es completamente diferente.
¿Por qué? Porque el precio representa probabilidad implícita. Pasar del 50% al 60% es un ajuste moderado de opinión. Pasar del 5% al 15% es un vuelco enorme de convicción — un evento casi imposible se vuelve "algo posible".
Imagina que te pesas. Pasar de 70 kg a 80 kg, dirías "engordé un poco". Pero pasar de 30 kg a 40 kg (si eres adulto), es "pasar de estar moribundo a desnutrición severa". El mismo cambio de 10 kg, significa algo completamente distinto. Con los precios pasa igual — los movimientos de precios cerca de 0 o 1 contienen más información.
Divergencia de Bregman: la "distancia" correcta
Los creadores de mercado de Polymarket usan LMSR (Regla de Puntuación de Mercado Logarítmica) [4], donde el precio esencialmente representa una distribución de probabilidad.
En esta estructura, la medida de distancia correcta no es la distancia euclidiana, sino la divergencia de Bregman. [5]
Para LMSR, la divergencia de Bregman se convierte en la divergencia KL (Kullback-Leibler) [6] — una métrica que mide la "distancia de teoría de la información" entre dos distribuciones de probabilidad.
No necesitas memorizar la fórmula. Solo necesitas entender una cosa:
La divergencia KL automáticamente da más peso a los movimientos cerca de precios extremos. Un movimiento de $0.05 a $0.15, bajo divergencia KL, está "más lejos" que un movimiento de $0.50 a $0.60. Esto coincide exactamente con nuestra intuición — los movimientos de precios extremos significan un impacto informativo mayor.
Un buen ejemplo es el último mercado de predicción de @zachxbt, donde Axiom superó a Meteora en el último momento, también con movimientos de precios extremos como catalizador del cambio.
Beneficio de arbitraje = Distancia de la proyección de Bregman
Esta es una de las conclusiones centrales del artículo original basado en el artículo de referencia:
El beneficio máximo garantizado que cualquier operación puede obtener es igual a la distancia de la proyección de Bregman del estado actual del mercado al espacio libre de arbitraje.
En otras palabras: Cuanto más se desvíen los precios del mercado del "espacio legal", más dinero se puede ganar. Y la proyección de Bregman te dice:
1. Qué comprar/vender (la dirección de la proyección te dice la dirección de la operación)
2. Cuánto comprar/vender (considerando la profundidad del libro de órdenes)
3. Cuánto puedes ganar (la distancia de la proyección es el beneficio máximo)
El arbitrajista número uno ganó $2,009,631.76 en un año. [2] Su estrategia fue resolver este problema de optimización más rápido y preciso que todos los demás.
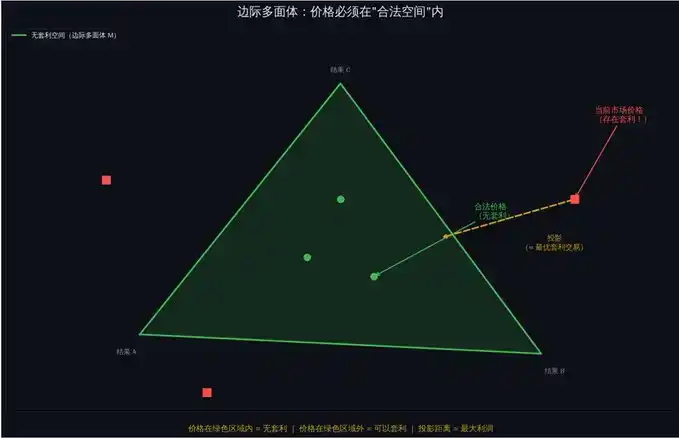
Pongamos una analogía: imagina que estás en una montaña, y al pie hay un río (espacio libre de arbitraje). Tu posición actual (precios de mercado actuales) está a cierta distancia del río.
La proyección de Bregman es como encontrar "el camino más corto desde tu posición hasta el río" — pero no la distancia en línea recta, sino el camino más corto considerando el terreno (estructura del mercado). La longitud de este camino es el beneficio máximo que puedes obtener.
Capítulo 3: Algoritmo Frank-Wolfe — Convertir la teoría en código ejecutable
Bien, ahora lo sabes: para calcular el arbitraje óptimo, necesitas hacer una proyección de Bregman.
Pero el problema es — calcular directamente la proyección de Bregman no es factible.
¿Por qué? Porque el espacio libre de arbitraje (politopo marginal M) tiene un número exponencial de vértices. Los métodos estándar de optimización convexa requieren acceso al conjunto completo de restricciones, es decir, enumerar cada resultado legal. Ya dijimos que esto es imposible a escala.
La idea central de Frank-Wolfe
Lo genial del algoritmo Frank-Wolfe [7] es: no intenta resolver todo el problema de una vez, sino que se acerca paso a paso a la respuesta.
Funciona así:
Paso 1: Comienza con un pequeño conjunto conocido de resultados legales.
Paso 2: Optimiza en este pequeño conjunto, encuentra la solución óptima actual.
Paso 3: Usa programación entera para encontrar un nuevo resultado legal, añádelo al conjunto.
Paso 4: Verifica si está lo suficientemente cerca del óptimo. Si no, vuelve al Paso 2.
Cada iteración, el conjunto solo añade un vértice. Incluso después de 100 iteraciones, solo necesitas rastrear 100 vértices — no 2^63.

Imagina que buscas la salida en un laberinto enorme.
El método de fuerza bruta es recorrer cada camino. El método Frank-Wolfe es: primero tomar un camino al azar, luego en cada cruce preguntar a un "guía" (solucionador de programación entera): "Desde aquí, ¿qué dirección es más probable que lleve a la salida?" y luego dar un paso en esa dirección. No necesitas explorar todo el laberinto, solo tomar la decisión correcta en cada nodo clave.
Solucionador de programación entera: el "guía" en cada paso
Cada iteración de Frank-Wolfe requiere resolver un problema de programación lineal entera. Esto es teóricamente NP-duro (es decir, "no hay un algoritmo general rápido conocido").
Pero los solucionadores modernos, como Gurobi [8], pueden resolver eficientemente problemas bien estructurados.
El equipo de investigación usó Gurobi 5.5. Tiempo real de solución:
• Iteraciones tempranas (pocos partidos terminados): menos de 1 segundo
• Intermedias (30-40 partidos terminados): 10-30 segundos
• Tardías (50+ partidos terminados): menos de 5 segundos
¿Por qué más rápido después? Porque a medida que se determinan los resultados, el espacio de soluciones factibles se reduce. Menos variables, restricciones más ajustadas, solución más rápida.
Problema de explosión del gradiente y Frank-Wolfe con Barrera
Frank-Wolfe estándar tiene un problema técnico: cuando el precio se acerca a 0, el gradiente de LMSR tiende a menos infinito. Esto hace que el algoritmo sea inestable.
La solución es Frank-Wolfe con Barrera: no optimizar en el politopo completo M, sino en una versión ligeramente "contraída" M. El parámetro de contracción ε se reduce adaptativamente con las iteraciones — comenzando lejos del borde (estable), luego acercándose gradualmente al borde real (preciso).
Los estudios muestran que en la práctica, 50 a 150 iteraciones son suficientes para converger.
Rendimiento real
Un hallazgo clave en el artículo [2]:
En los primeros 16 partidos del Torneo NCAA, el creador de mercado Frank-Wolfe (FWMM) y el creador de mercado de restricciones lineales simple (LCMM) se desempeñaron similarmente — porque el solucionador de programación entera aún era demasiado lento.
Pero después de 45 partidos, se completó la primera proyección exitiva en 30 minutos.
Desde entonces, FWMM fue 38% mejor que LCMM en la fijación de precios de las apuestas.
El punto de inflexión fue: cuando el espacio de resultados se redujo lo suficiente para que la programación entera pudiera resolver dentro de la ventana de tiempo de operación.
FWMM es como un estudiante que calienta en la primera mitad del examen, pero una vez que entra en ritmo, domina. LCMM es el estudiante consistentemente estable pero con techo limitado. La diferencia clave: FWMM tiene un "arma" más fuerte (proyección de Bregman), solo necesita tiempo para "cargarla" (esperar a que el solucionador termine).
Capítulo 4: Ejecución — Por qué puedes perder dinero incluso después de calcular
Detectaste el arbitraje. Calculaste la operación óptima con proyección de Bregman.
Ahora necesitas ejecutar.
Aquí es donde fallan la mayoría de las estrategias.
Problema de ejecución no atómica
Polymarket usa CLOB (Libro de Órdenes Limitadas Centralizado) [9]. A diferencia de los exchanges descentralizados, las operaciones en CLOB se ejecutan secuencialmente — no puedes garantizar que todas las órdenes se completen simultáneamente.
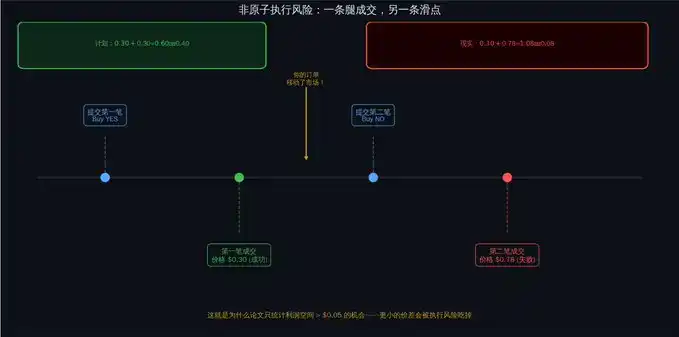
Tu plan de arbitraje:
Comprar YES, precio $0.30. Comprar NO, precio $0.30. Costo total $0.60. Sin importar el resultado, recuperas $1.00. Beneficio $0.40.
Realidad:
· Envías orden YES → precio de ejecución $0.30 ✓
· Tu orden cambió el precio de mercado.
· Envías orden NO → precio de ejecución $0.78 ✗
· Costo total: $1.08. Recuperación: $1.00. Resultado real: pierdes $0.08.
Una pata se ejecutó, la otra no. Quedaste expuesto.
Por eso el artículo solo cuenta oportunidades con margen de beneficio superior a $0.05. Los spreads más pequeños son comidos por el riesgo de ejecución.
VWAP: El precio de ejecución real
No asumas que puedes operar al precio cotizado. Calcula el precio promedio ponderado por volumen (VWAP) [10].
El método del equipo de investigación fue: para cada bloque en la cadena Polygon (aprox. 2 segundos), calcular el VWAP de todas las operaciones YES y el VWAP de todas las operaciones NO en ese bloque. Si |VWAP_yes + VWAP_no - 1.0| > 0.02, se registra como una oportunidad de arbitraje [2].
VWAP es el "precio promedio que realmente pagas". Si quieres comprar 10,000 tokens, pero en el libro de órdenes a $0.30 solo hay 2,000, a $0.32 hay 3,000, a $0.35 hay 5,000 — tu VWAP es (2000×0.30 + 3000×0.32 + 5000×0.35) / 10000 = $0.326. Bastante más caro que el "mejor precio" cotizado de $0.30.
Restricciones de liquidez: cuánto puedes ganar depende de la profundidad del libro
Incluso si el precio está desviado, el beneficio que puedes obtener está limitado por la liquidez disponible.
Ejemplo real [2]:
Mercado muestra arbitraje: suma de precios YES = $0.85. Beneficio potencial: $0.15 por dólar. Pero la profundidad del libro a esos precios es solo $234. Beneficio máximo extraíble: $234 × 0.15 = $35.10.
Para arbitraje entre mercados, necesitas liquidez simultánea en todas las posiciones. La más pequeña determina tu límite.
Por eso también, en las plataformas cuantitativas existentes, es crucial mostrar el impacto del precio de la orden en el precio de ejecución.
Capítulo 5: Sistema completo — Qué se desplegó realmente
La teoría es limpia. El entorno de producción es desordenado.
Así es un sistema de arbitraje real que funciona [2].
Canalización de datos
Datos en tiempo real: Conexión WebSocket a la API de Polymarket [9], recibiendo actualizaciones del libro de órdenes (cambios de precio/volumen), notificaciones de operaciones ejecutadas, eventos de creación/liquidación de mercados.
Datos históricos: Consulta de eventos de contrato a través de la API del nodo Polygon de Alchemy — OrderFilled (ejecución de operación), PositionSplit (acuñación de nuevo token), PositionsMerge (destrucción de token).
El equipo de investigación analizó 86 millones de operaciones [2]. Esta escala requiere infraestructura, no un script.
Actualmente también hay planes de abrir una API de operaciones de alta velocidad. Si planeas usar un modelo de operación similar y deseas ser de los primeros en probar la API, no dudes en enviarme un DM.
Capa de detección de dependencias
Para 305 mercados de elecciones de EE.UU., había 46,360 pares posibles para verificar. El análisis manual es imposible.
El equipo de investigación usó un método inteligente: usar el modelo de lenguaje grande DeepSeek-R1-Distill-Qwen-32B para un filtrado inicial.
Entrada: descripciones de las condiciones de dos mercados. Salida: JSON con las combinaciones de resultados legales.
Luego, tres capas de verificación: ¿Cada mercado tiene exactamente una condición verdadera? ¿El número de combinaciones legales es menor que n × m (existe dependencia)? ¿El subconjunto dependiente satisface las condiciones de arbitraje?
Resultado: 40,057 pares independientes (sin arbitraje) → 1,576 pares con dependencia (arbitraje potencial) → 374 pares cumplen condiciones estrictas → 13 pares verificados manualmente como explotables [2].
El LLM tuvo una precisión del 81.45% en mercados multicondición complejos. Suficiente para filtrado inicial, pero requiere verificación manual antes de ejecutar.
Motor de optimización de tres capas
· Capa 1: Restricciones lineales simples (LCMM). Verificación rápida de reglas básicas — "suma de probabilidades igual a 1", "si A implica B, entonces P(A) no puede exceder P(B)". Se completa en milisegundos, elimina errores de valoración obvios.
· Capa 2: Proyección de programación entera (Frank-Wolfe + Gurobi). Esto es el núcleo. Parámetros: Alpha = 0.9 (extraer al menos 90% del arbitraje disponible), ε inicial = 0.1 (contracción del 10%), umbral de convergencia = 1e-6, límite de tiempo = 30 minutos. Iteraciones típicas: 50-150. Tiempo de solución por iteración: 1-30 segundos.
· Capa 3: Verificación de ejecución. Antes de enviar órdenes, simula la ejecución en el libro de órdenes actual. Verifica: ¿La liquidez es suficiente? ¿Cuál es el deslizamiento esperado? ¿El beneficio garantizado después del deslizamiento? ¿El beneficio supera el umbral mínimo ($0.05)? Solo ejecuta si todo pasa.
Gestión de posiciones: Fórmula de Kelly modificada
La fórmula estándar de Kelly [11] te dice qué fracción de tu capital invertir en una operación. Pero en escenarios de arbitraje, necesita un ajuste por riesgo de ejecución:
f = (b×p - q) / b × √p
Donde b es el porcentaje de beneficio de arbitraje, p es la probabilidad de ejecución completa (estimada basada en la profundidad del libro), q = 1 - p.
Límite superior: 50% de la profundidad del libro. Más allá de esta proporción, tu orden misma movería significativamente el mercado.
Resultado final
De abril 2024 a abril 2025, beneficio total extraído:
Arbitraje de condición única: Compra baja de ambos lados $5,899,287 + Venta alta de ambos lados $4,682,075 = $10,581,362
Reequilibrio de mercado: Compra baja de todos YES $11,092,286 + Venta alta de todos YES $612,189 + Compra de todos NO $17,307,114 = $29,011,589
Arbitraje combinado entre mercados: $95,634
Total: $39,688,585
Los 10 principales arbitrajistas se llevaron $8,127,849 (20.5% del total). El arbitrajista número uno: $2,009,632, de 4,049 operaciones, promedio $496 por operación [2].
No es lotería. No es suerte. Es la ejecución sistemática de precisión matemática.
La realidad final
Mientras los operadores leen "10 trucos para mercados de predicción", ¿qué hacen los sistemas cuantitativos?
Usan programación entera para detectar dependencias entre 17,218 condiciones. Calculan operaciones de arbitraje óptimas con proyección de Bregman. Ejecutan el algoritmo Frank-Wolfe manejando explosiones de gradiente. Estiman deslizamiento con VWAP y ejecutan órdenes en paralelo. Extraen sistemáticamente 40 millones de dólares en beneficios garantizados.
La brecha no es suerte. Es infraestructura matemática.
El artículo es público [1]. Los algoritmos son conocidos. Los beneficios son reales.
La pregunta es: ¿Puedes construirlo antes de que se extraigan los próximos 40 millones?
Consulta rápida de conceptos
• Politopo Marginal (Marginal Polytope) → El espacio formado por todos los "precios legales". Los precios deben estar en este espacio para estar libres de arbitraje. Se puede entender como la "región legal de precios".
• Programación Entera (Integer Programming) → Usar restricciones lineales para describir resultados legales, evitando la enumeración por fuerza bruta. Comprime 2^63 verificaciones en unas pocas restricciones [3]
• Divergencia de Bregman / Divergencia KL → Método para medir la "distancia" entre dos distribuciones de probabilidad, más adecuado para escenarios de precio/probabilidad que la distancia euclidiana. Los movimientos cerca de precios extremos tienen más peso [5][6]
• LMSR (Regla de Puntuación de Mercado Logarítmica) → Mecanismo de fijación de precios utilizado por los creadores de mercado de Polymarket, el precio representa probabilidad implícita [4]
• Algoritmo Frank-Wolfe → Un algoritmo de optimización iterativo, cada iteración solo añade un nuevo vértice, evitando enumerar el número exponencial de resultados legales [7]
• Gurobi → Solucionador de programación entera líder en la industria, el "guía" en cada iteración de Frank-Wolfe [8]
• CLOB (Libro de Órdenes Limitadas Centralizado) → Mecanismo de matching de operaciones de Polymarket, las órdenes se ejecutan secuencialmente, no se puede garantizar atomicidad [9]
• VWAP (Precio Promedio Ponderado por Volumen) → El precio promedio que realmente pagas, considera la profundidad del libro. Más realista que el "mejor precio cotizado" [10]
• Fórmula de Kelly → Te dice qué fracción de tu capital invertir en una operación, equilibrando ganancia y riesgo [11]
• Ejecución no atómica → El problema de que múltiples órdenes no se puedan garantizar simultáneamente. Una pata ejecutada y otra no = riesgo de exposición.
• DeepSeek → Modelo de lenguaje grande utilizado para el filtrado inicial de dependencias de mercado, precisión 81.45%





