Autor | ZeR0 骏达, 智东西
Editor | 漠影
LAS VEGAS, 5 de enero de 2026 (智东西) — Recién, el fundador y CEO de Nvidia, Huang Renxun, pronunció el primer discurso clave de 2026 en la Consumer Electronics Show (CES) 2026. Huang Renxun, vistiendo como siempre su chaqueta de cuero, anunció 8 lanzamientos importantes en 1.5 horas, desde chips y racks hasta diseño de red, proporcionando una introducción en profundidad de toda la nueva plataforma generacional.
En el campo de la computación acelerada y la infraestructura de IA, Nvidia presentó el supercomputador de IA NVIDIA Vera Rubin POD, el dispositivo de óptica encapsulada conjuntamente (CPO) NVIDIA Spectrum-X Ethernet, la plataforma de almacenamiento de memoria contextual para inferencia NVIDIA, y el NVIDIA DGX SuperPOD basado en DGX Vera Rubin NVL72.

NVIDIA Vera Rubin POD utiliza 6 chips desarrollados internamente por Nvidia, que abarcan CPU, GPU, Scale-up, Scale-out, capacidades de almacenamiento y procesamiento, todas las partes están co-diseñadas para satisfacer las demandas de modelos avanzados y reducir el coste computacional.
Entre ellos, la CPU Vera adopta la arquitectura de núcleo personalizada Olympus, la GPU Rubin introduce un motor Transformer con un rendimiento de inferencia NVFP4 de hasta 50 PFLOPS, un ancho de banda NVLink por GPU de hasta 3.6 TB/s, soporte para la tercera generación de computación confidencial universal (el primer TEE a nivel de rack), logrando un entorno de ejecución confiable completo a través de dominios de CPU y GPU.

Estos chips ya han regresado de la fabricación (taped-out), Nvidia ya ha verificado todo el sistema NVIDIA Vera Rubin NVL72, y los socios también han comenzado a ejecutar sus modelos y algoritmos de IA integrados internamente, todo el ecosistema se está preparando para el despliegue de Vera Rubin.
En otros lanzamientos, el dispositivo de óptica encapsulada conjuntamente NVIDIA Spectrum-X Ethernet optimiza significativamente la eficiencia energética y el tiempo de actividad de las aplicaciones; la plataforma de almacenamiento de memoria contextual para inferencia NVIDIA redefine la pila de almacenamiento para reducir el cómputo repetitivo y mejorar la eficiencia de inferencia; el NVIDIA DGX SuperPOD basado en DGX Vera Rubin NVL72 reduce el coste por token de los grandes modelos MoE a 1/10.

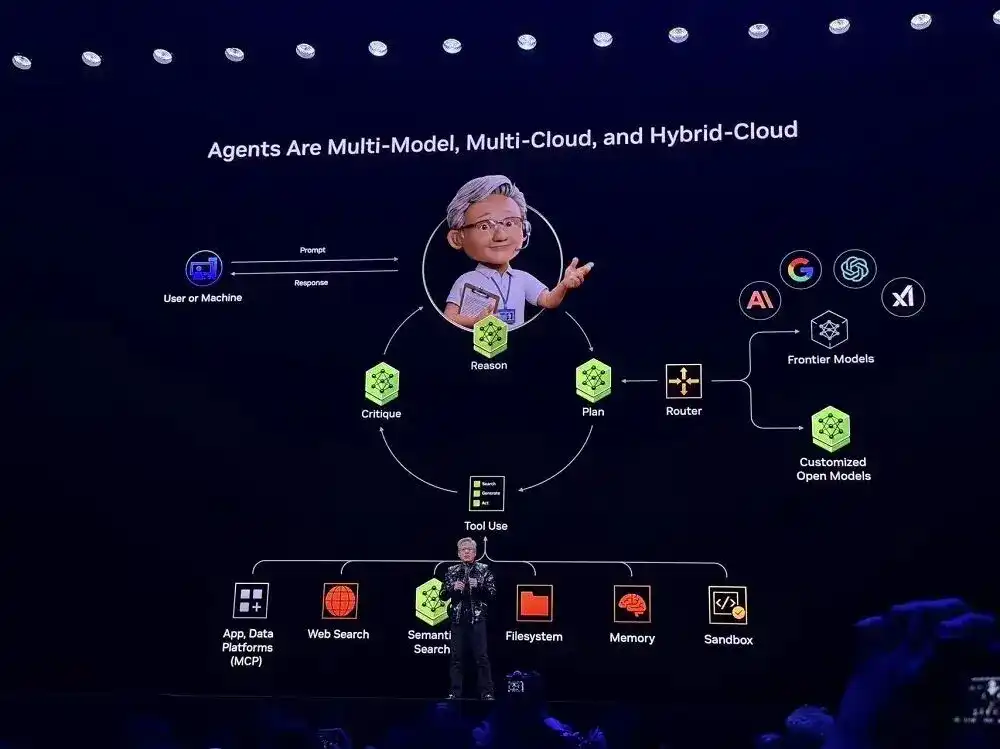
En cuanto a modelos abiertos, Nvidia anunció la expansión de su familia de modelos de código abierto, lanzando nuevos modelos, conjuntos de datos y bibliotecas, incluyendo la serie de modelos de código abierto NVIDIA Nemotron que añade modelos Agentic RAG, modelos de seguridad, modelos de voz, y también lanzó nuevos modelos abiertos para todo tipo de robots. Sin embargo, Huang Renxun no entró en detalles en su discurso.
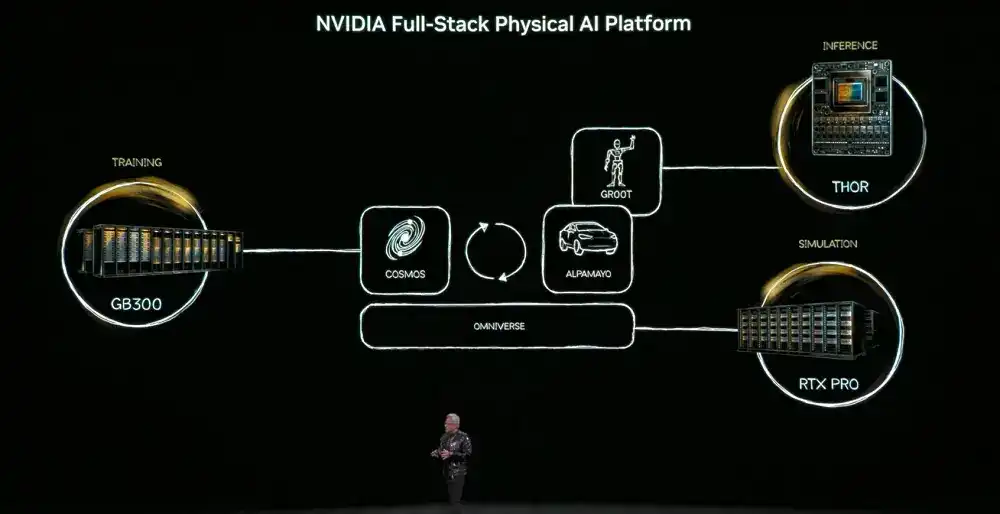
En cuanto a la IA física, el momento ChatGPT de la IA física ha llegado, la tecnología full-stack de Nvidia permite que el ecosistema global transforme industrias a través de la tecnología robótica impulsada por IA; la amplia biblioteca de herramientas de IA de Nvidia, incluyendo la nueva combinación de modelos de código abierto Alpamayo, permite que la industria global del transporte logre rápidamente una conducción L4 segura; la plataforma de conducción autónoma NVIDIA DRIVE ahora está en producción, equipando todos los nuevos Mercedes-Benz CLA, para una conducción definida por IA L2++.

01. Nuevo supercomputador de IA: 6 chips autodesarrollados, potencia de cálculo por rack de 3.6 EFLOPS
Huang Renxun cree que cada 10 a 15 años, la industria informática experimenta una remodelación completa, pero esta vez, dos transiciones de plataforma ocurren simultáneamente, de CPU a GPU, de "programar software" a "entrenar software", la computación acelerada y la IA están reconstruyendo toda la pila informática. La industria informática de 10 billones de dólares de la última década está experimentando una modernización.
Al mismo tiempo, la demanda de potencia de cálculo también se ha disparado. El tamaño de los modelos crece 10 veces al año, la cantidad de tokens que los modelos usan para pensar crece 5 veces al año, y el precio por token disminuye 10 veces al año.
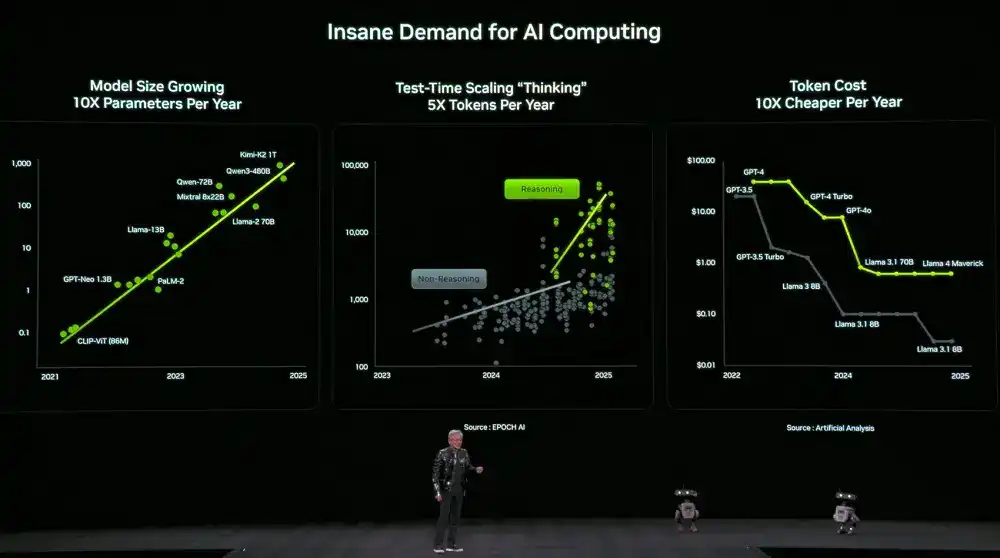
Para hacer frente a esta demanda, Nvidia ha decidido lanzar nuevo hardware de computación cada año. Huang Renxun reveló que Vera Rubin ya ha entrado plenamente en producción.
El nuevo supercomputador de IA NVIDIA Vera Rubin POD utiliza 6 chips autodesarrollados: CPU Vera, GPU Rubin, conmutador NVLink 6, tarjeta de red inteligente ConnectX-9 (CX9), DPU BlueField-4, CPO Spectrum-X 102.4T.
CPU Vera: Diseñada para el movimiento de datos y el procesamiento de agentes, tiene 88 núcleos Olympus personalizados de Nvidia, 176 hilos de multihilo espacial de Nvidia, 1.8 TB/s de NVLink-C2C soporta memoria unificada CPU:GPU, memoria del sistema de 1.5 TB (3 veces la de la CPU Grace), memoria LPDDR5X SOCAMM con ancho de banda de 1.2 TB/s, y soporta computación confidencial a nivel de rack, duplicando el rendimiento de procesamiento de datos.

GPU Rubin: Introduce el motor Transformer, rendimiento de inferencia NVFP4 de hasta 50 PFLOPS, 5 veces la GPU Blackwell, compatible con versiones anteriores, mejora el rendimiento a nivel BF16/FP4 manteniendo la precisión de inferencia; rendimiento de entrenamiento NVFP4 de 35 PFLOPS, 3.5 veces Blackwell.
Rubin es también la primera plataforma que soporta HBM4, ancho de banda HBM4 de 22 TB/s, 2.8 veces la generación anterior, capaz de proporcionar el rendimiento necesario para exigentes modelos MoE y cargas de trabajo de IA.

Conmutador NVLink 6: Velocidad por lane aumentada a 400 Gbps, utiliza tecnología SerDes para lograr transmisión de señales de alta velocidad; cada GPU puede lograr un ancho de banda de comunicación de interconexión completa de 3.6 TB/s, el doble que la generación anterior, ancho de banda total de 28.8 TB/s, rendimiento de cómputo in-network a precisión FP8 de 14.4 TFLOPS, soporta 100% refrigeración líquida.

NVIDIA ConnectX-9 SuperNIC: Proporciona 1.6 Tb/s de ancho de banda por GPU, optimizada para IA a gran escala, con ruta de datos completamente definida por software, programable y acelerada.

NVIDIA BlueField-4: DPU de 800 Gbps, utilizado para tarjetas de red inteligentes y procesadores de almacenamiento, equipado con 64 núcleos de CPU Grace, combinado con ConnectX-9 SuperNIC, para descargar tareas de computación relacionadas con red y almacenamiento, mientras mejora las capacidades de seguridad de red, rendimiento de computación 6 veces mayor que la generación anterior, ancho de banda de memoria 3 veces mayor, velocidad de acceso de GPU al almacenamiento de datos aumentada al doble.

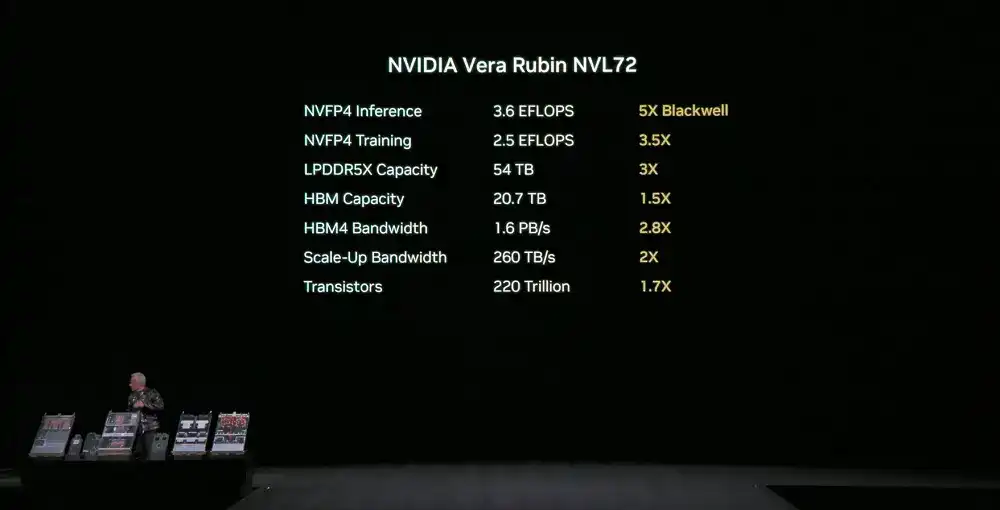
NVIDIA Vera Rubin NVL72: A nivel de sistema, integra todos estos componentes en un sistema de procesamiento de un solo rack, tiene 2 billones de transistores, rendimiento de inferencia NVFP4 de 3.6 EFLOPS, rendimiento de entrenamiento NVFP4 de 2.5 EFLOPS.
Este sistema tiene una capacidad de memoria LPDDR5X de 54 TB, 2.5 veces la generación anterior; memoria HBM4 total de 20.7 TB, 1.5 veces la generación anterior; ancho de banda HBM4 de 1.6 PB/s, 2.8 veces la generación anterior; ancho de banda total de escala vertical alcanza 260 TB/s, superando la escala total del ancho de banda de Internet global.
Este sistema se basa en el diseño de rack MGX de tercera generación, las bandejas de computación adoptan un diseño modular, sin host, sin cables, sin ventiladores, haciendo que el montaje y mantenimiento sea 18 veces más rápido que el GB200. El trabajo de montaje que originalmente tomaba 2 horas, ahora toma unos 5 minutos, y mientras el sistema original usaba aproximadamente un 80% de refrigeración líquida, ahora usa 100% refrigeración líquida. Un solo sistema en sí pesa 2 toneladas, y con el líquido refrigerante puede alcanzar 2.5 toneladas.

La bandeja del conmutador NVLink puede lograr mantenimiento de tiempo de inactividad cero y tolerancia a fallos, el rack puede seguir funcionando cuando se retira una bandeja o se despliega parcialmente. El motor RAS de segunda generación permite comprobaciones de estado con tiempo de inactividad cero.
Estas características mejoran el tiempo de actividad y el rendimiento del sistema, reduciendo aún más los costes de entrenamiento e inferencia, satisfaciendo los requisitos de alta fiabilidad y alta mantenibilidad de los centros de datos.
Más de 80 socios de MGX están listos para soportar el despliegue de Rubin NVL72 en redes hyperscale.
02. Tres nuevos productos revolucionan la eficiencia de la inferencia de IA: nuevo dispositivo CPO, nueva capa de almacenamiento contextual, nuevo DGX SuperPOD
Al mismo tiempo, Nvidia lanzó 3 productos importantes: el dispositivo de óptica encapsulada conjuntamente NVIDIA Spectrum-X Ethernet, la plataforma de almacenamiento de memoria contextual para inferencia NVIDIA, y el NVIDIA DGX SuperPOD basado en DGX Vera Rubin NVL72.
1. Dispositivo de óptica encapsulada conjuntamente NVIDIA Spectrum-X Ethernet
El dispositivo de óptica encapsulada conjuntamente NVIDIA Spectrum-X Ethernet se basa en la arquitectura Spectrum-X, utiliza un diseño de 2 chips, utiliza SerDes de 200 Gbps, cada ASIC puede proporcionar 102.4 Tb/s de ancho de banda.
Esta plataforma de conmutación incluye un sistema de alta densidad de 512 puertos, y un sistema compacto de 128 puertos, cada puerto tiene una velocidad de 800 Gb/s.

El sistema de conmutación CPO (óptica encapsulada conjuntamente) puede lograr una mejora de 5 veces en eficiencia energética, 10 veces en fiabilidad, 5 veces en tiempo de actividad de la aplicación.
Esto significa que se pueden procesar más tokens por día, reduciendo aún más el coste total de propiedad (TCO) del centro de datos.
2. Plataforma de almacenamiento de memoria contextual para inferencia NVIDIA
La plataforma de almacenamiento de memoria contextual para inferencia NVIDIA es una infraestructura de almacenamiento nativa de IA a nivel de POD, utilizada para almacenar KV Cache, basada en BlueField-4 y aceleración Ethernet Spectrum-X, estrechamente acoplada con NVIDIA Dynamo y NVLink, logrando una planificación contextual cooperativa entre memoria, almacenamiento y red.
Esta plataforma trata el contexto como un tipo de datos de primera clase, puede lograr 5 veces el rendimiento de inferencia, 5 veces mejor eficiencia energética.

Esto es crucial para mejorar aplicaciones de contexto largo como conversaciones de múltiples turnos, RAG, razonamiento multi-paso Agentic, estas cargas de trabajo dependen en gran medida de la capacidad de almacenar, reutilizar y compartir eficientemente el contexto en todo el sistema.
La IA está evolucionando de chatbots a IA Agentic (agente), que razona, invoca herramientas y mantiene estado a largo plazo, las ventanas de contexto se han expandido a millones de tokens. Este contexto se guarda en KV Cache, recalcular cada paso desperdiciaría tiempo de GPU y traería una gran latencia, por lo que es necesario almacenarlo.
Pero la memoria de GPU, aunque rápida, es escasa, el almacenamiento de red tradicional es demasiado ineficiente para el contexto a corto plazo. El cuello de botella de la inferencia de IA está pasando del cómputo al almacenamiento contextual. Por lo tanto, se necesita una nueva capa de memoria entre la GPU y el almacenamiento, optimizada para inferencia.

Esta capa ya no es un parche posterior, sino que debe estar co-diseñada con el almacenamiento de red, para mover datos contextuales con el menor sobrecoste.
Como un nuevo nivel de almacenamiento, la plataforma de almacenamiento de memoria contextual para inferencia NVIDIA no existe directamente en el sistema host, sino que se conecta a través de BlueField-4 fuera del dispositivo de computación. Su ventaja clave es que puede escalar más eficientemente el tamaño del grupo de almacenamiento, evitando así el cómputo repetitivo de KV Cache.
Nvidia está colaborando estrechamente con socios de almacenamiento para introducir la plataforma de almacenamiento de memoria contextual para inferencia NVIDIA en la plataforma Rubin, permitiendo a los clientes desplegarla como parte de una infraestructura de IA completamente integrada.
3. NVIDIA DGX SuperPOD construido sobre Vera Rubin
A nivel de sistema, NVIDIA DGX SuperPOD sirve como plano de despliegue para fábricas de IA a gran escala, utiliza 8 sistemas DGX Vera Rubin NVL72, con red de escala vertical NVLink 6, red de escala horizontal Spectrum-X Ethernet, incorpora la plataforma de almacenamiento de memoria contextual para inferencia NVIDIA, y está validado por ingeniería.
Todo el sistema está gestionado por el software NVIDIA Mission Control, logrando una eficiencia máxima. Los clientes pueden desplegarlo como una plataforma llave en mano, completando tareas de entrenamiento e inferencia con menos GPUs.
Debido al diseño cooperativo extremo a nivel de 6 chips, bandeja, rack, Pod, centro de datos y software, la plataforma Rubin logra una caída significativa en los costes de entrenamiento e inferencia. En comparación con la generación anterior Blackwell, para entrenar un modelo MoE del mismo tamaño, solo se necesita 1/4 del número de GPUs; con la misma latencia, el coste por token de grandes modelos MoE se reduce a 1/10.

También se lanzó el NVIDIA DGX SuperPOD que utiliza sistemas DGX Rubin NVL8.
Con la arquitectura Vera Rubin, Nvidia, junto con socios y clientes, está construyendo los sistemas de IA más grandes, avanzados y de menor coste del mundo, acelerando la adopción generalizada de la IA.

La infraestructura Rubin estará disponible en la segunda mitad de este año a través de CSPs e integradores de sistemas, Microsoft y otros serán los primeros en desplegarla.
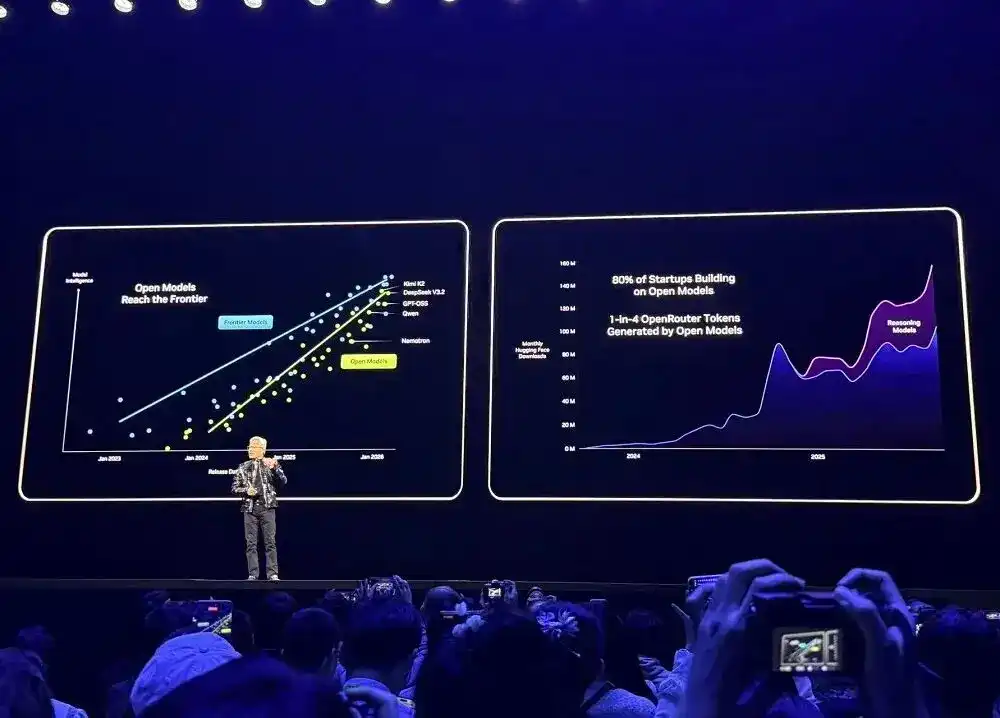
03. El universo de modelos abiertos se expande: nuevo modelo, datos, contribuyente importante al ecosistema de código abierto
A nivel de software y modelos, Nvidia continúa aumentando su inversión en código abierto.
Plataformas de desarrollo principales como OpenRouter muestran que en el último año, el uso de modelos de IA creció 20 veces, y aproximadamente 1/4 de los tokens provienen de modelos de código abierto.
<极速6>