Deep Tide Guide: This article is from a16z researcher Oliver Hsu, and is the most systematic "Physical AI" investment map since 2026. His judgment is: the main thread of language/code is still scaling, but the areas that can truly develop the next generation of disruptive capabilities are the three fields adjacent to the main thread—general-purpose robotics, autonomous science (AI scientists), and new human-computer interfaces like brain-computer interfaces. The author breaks down the five underlying capabilities that underpin them and argues that these three fronts will form a structurally reinforcing flywheel that feeds into each other. For those who wants to understand the investment logic of Physical AI, this is currently the most complete framework.
Today's dominant AI paradigm is organized around language and code. The scaling laws of large language models are well understood, the commercial flywheel of data, compute, and algorithmic improvements is turning, the returns from each step up in capability are still large, and most of these returns are visible. This paradigm deserves the capital and attention it absorbs.
But another set of adjacent fields has already made substantial progress in their incubation periods. These include VLA (Vision-Language-Action models), WAM (World Action Models), and other general-purpose robotics approaches; physical and scientific reasoning centered around the "AI scientist"; and new interfaces that leverage AI progress to reshape human-computer interaction (including brain-computer interfaces and neurotechnology).
Beyond the technology itself, these directions are beginning to attract talent, capital, and founders. The technical primitives for extending frontier AI into the physical world are maturing simultaneously, and progress over the past 18 months suggests these fields will soon enter their own scaling phases.
In any technological paradigm, the places with the largest delta between current capability and medium-term potential often share two characteristics: they can benefit from the same scaling红利 (benefits/advantages) driving the current frontier, and they are just one step removed from the mainstream paradigm—close enough to inherit its infrastructure and research momentum, yet distant enough to require substantial additional work.
This distance itself has a dual effect: it naturally forms a moat against fast followers, while also defining a problem space with sparser information and less crowding, thus more likely to yield emergent capabilities—precisely because the shortcuts haven't all been taken yet.

Three fields fit this description today: robotic learning, autonomous science (especially in materials and life sciences), and new human-computer interfaces (including brain-computer interfaces, silent speech, neuro-wearables, and new sensory channels like digital olfaction).
They are not entirely independent efforts; thematically, they belong to the same group of "frontier systems for the physical world." They share a set of underlying primitives: learned representations of physical dynamics, architectures for embodied action, simulation and synthetic data infrastructure, expanding sensory channels, and closed-loop agent orchestration. They reinforce each other in cross-domain feedback relationships. They are also the most likely places for qualitative capability leaps to emerge—products of the interaction between model scale, physical deployment, and new data modalities.
This article will梳理 (sort out/explore) the technical primitives supporting these systems, explain why these three fields represent frontier opportunities, and propose that their mutual reinforcement constitutes a structural flywheel pushing AI into the physical world.
Five Underlying Primitives
Before looking at specific applications, understand the shared technical foundation of these frontier systems. Pushing frontier AI into the physical world relies on five main primitives. These technologies are not exclusive to any single application domain; they are building blocks—enabling systems that "extend AI into the physical world" to be built. Their simultaneous maturation is what makes this moment special.

Primitive 1: Learned Representations of Physical Dynamics
The most fundamental primitive is the ability to learn a compressed, general representation of how the physical world behaves—how objects move, deform, collide, react to forces. Without this layer, every physical AI system would have to learn the physics of its domain from scratch, a cost no one can afford.
Several architectural schools are approaching this goal from different directions. VLA models start from the top: take a pre-trained vision-language model—which already possesses semantic understanding of objects, spatial relationships, and language—and add an action decoder on top to output motion control commands.
The key point is that the enormous cost of learning to "see" and "understand the world" can be amortized by internet-scale image-text pre-training. Physical Intelligence's π0, Google DeepMind's Gemini Robotics, and NVIDIA's GR00T N1 are all validating this architecture at increasingly larger scales.
WAM models start from the bottom: based on video diffusion Transformers pre-trained on internet-scale video, inheriting rich priors about physical dynamics (how objects fall, get occluded, interact under force), and then coupling these priors with action generation.
NVIDIA's DreamZero demonstrated zero-shot generalization to novel tasks and environments, achieving meaningful improvements in real-world generalization with minimal adaptation data for cross-embodiment transfer from human video demonstrations.
A third route might be most instructive for judging future directions; it skips pre-trained VLMs and video diffusion backbones entirely. Generalist's GEN-1 is a natively embodied foundation model trained from scratch on over 500,000 hours of real physical interaction data, primarily collected from people performing daily manipulation tasks via low-cost wearable devices.
It is not a VLA in the standard sense (no vision-language backbone is being fine-tuned), nor is it a WAM. It is a foundation model designed specifically for physical interaction, learning from scratch not the statistical patterns of internet images, text, or video, but the statistical patterns of human-object contact.
Spatial intelligence, as pursued by companies like World Labs, is valuable for this primitive because it addresses a common shortcoming of VLAs, WAMs, and natively embodied models: none explicitly model the 3D structure of the scene they are in.
VLAs inherit 2D visual features from image-text pre-training; WAMs learn dynamics from video, which is a 2D projection of 3D; models learning from wearable sensor data capture forces and kinematics but not scene geometry. Spatial intelligence models can help fill this gap—learning to reconstruct and generate the complete 3D structure of physical environments and reason about it: geometry, lighting, occlusion, object relationships, spatial layout.
The convergence of these various routes is itself a key point. Whether the representation is inherited from a VLM, learned from video co-training, or built natively from physical interaction data, the underlying primitive is the same: a compressed, transferable model of physical world behavior.
The data flywheel these representations can tap into is enormous and mostly untapped—not just internet video and robot trajectories, but also the vast corpus of human bodily experience that wearable devices are beginning to collect at scale. The same representation can serve a robot learning to fold towels, an autonomous lab predicting reaction outcomes, and a neural decoder interpreting grasp intent from the motor cortex.
Primitive 2: Architectures for Embodied Action
Physical representation alone is not enough. Translating "understanding" into reliable physical action requires architectures to solve several interrelated problems: mapping high-level intent to continuous motion commands, maintaining consistency over long action sequences, operating under real-time latency constraints, and improving continuously with experience.
A dual-system hierarchical architecture has become a standard design for complex embodied tasks: a slow-but-powerful vision-language model handles scene understanding and task reasoning (System 2), paired with a fast-but-light visual-motor policy responsible for real-time control (System 1). GR00T N1, Gemini Robotics, and Figure's Helix all employ variants of this approach, resolving the fundamental tension between "large models providing rich reasoning" and "physical tasks requiring millisecond-level control frequencies." Generalist took another path, using "resonant reasoning" to allow thinking and acting to occur simultaneously.
The action generation mechanisms themselves are evolving rapidly. The flow-matching and diffusion-based action heads pioneered by π0 have become the mainstream method for generating smooth, high-frequency continuous actions, replacing the discrete tokenization borrowed from language modeling. These methods treat action generation as a denoising process similar to image synthesis, producing trajectories that are physically smoother and more robust to error accumulation than auto-regressive token prediction.
But perhaps the most critical architectural advance is the extension of reinforcement learning to pre-trained VLAs—a foundation model trained on demonstration data can continue to improve through autonomous practice, just like a person refining a skill through repetition and self-correction. Physical Intelligence's π*0.6 work is the clearest large-scale demonstration of this principle. Their method, called RECAP (Reinforcement Learning with Experience and Advantage-Conditioned Policies), addresses the long-horizon credit assignment problem that pure imitation learning cannot solve.
If a robot picks up an espresso machine portafilter at a slightly skewed angle, failure doesn't occur immediately; it might only manifest several steps later during insertion. Imitation learning has no mechanism to attribute this failure back to the earlier grasp; RL does. RECAP trains a value function to estimate the probability of success from any intermediate state, then lets the VLA choose high-advantage actions. Crucially, it integrates multiple heterogeneous data types—demonstration data, on-policy autonomous experience, corrections provided by expert teleoperation during execution—into the same training pipeline.
The results of this method are good news for the prospects of RL in the action domain. π*0.6 reliably folded 50 types of never-before-seen clothing in real home environments, assembled cardboard boxes, and made espresso on a professional machine, running for hours continuously without human intervention. On the most difficult tasks, RECAP more than doubled throughput and halved failure rates compared to pure imitation baselines. The system also demonstrated that RL post-training produces qualitative behaviors not seen in imitation learning: smoother recovery motions, more efficient grasping strategies, adaptive error correction not present in the demonstration data.
These gains illustrate one thing: The compute scaling dynamics that pushed large models from GPT-2 to GPT-4 are beginning to operate in the embodied domain—only now at an earlier point on the curve, where the action space is continuous, high-dimensional, and must contend with the unforgiving constraints of the physical world.
Primitive 3: Simulation & Synthetic Data as Scaling Infrastructure
In the language domain, the data problem was solved by the internet: naturally occurring, freely available trillions of text tokens. In the physical world, this problem is orders of magnitude harder—this is now consensus, most directly signaled by the rapid increase in startup data vendors focused on the physical world.
Collecting real-world robot trajectories is expensive, risky to scale, and limited in diversity. A language model can learn from a billion conversations; a robot (for now) cannot have a billion physical interactions.
Simulation and synthetic data generation are the infrastructure layer solving this constraint, and their maturation is a key reason why physical AI is accelerating now rather than five years ago.
Modern simulation stacks combine physics-based simulation engines, photorealistic ray-traced rendering, procedural environment generation, and world foundation models that generate photorealistic video from simulation inputs—the latter responsible for bridging the sim-to-real gap. The entire pipeline starts with neural reconstruction of real environments (possible with just a phone), populates them with physically accurate 3D assets, and proceeds to large-scale synthetic data generation with automatic labeling.
The significance of improvements in simulation stacks is that they are changing the economic assumptions underpinning physical AI. If the bottleneck for physical AI shifts from "collecting real data" to "designing diverse virtual environments," the cost curve collapses. Simulation scales with compute, not with manpower and physical hardware. This transformation of the economic structure for training physical AI systems is of the same kind as the transformation internet text data brought to training language models—meaning investment in simulation infrastructure has enormous leverage for the entire ecosystem.
But simulation is not just a robotics primitive. The same infrastructure serves autonomous science (digital twins of lab equipment, simulated reaction environments for hypothesis pre-screening), new interfaces (simulated neural environments for training BCI decoders, synthetic sensory data for calibrating new sensors), and other domains where AI interacts with the physical world. Simulation is the universal data engine for physical world AI.
Primitive 4: Expanding Sensory Channels
The physical world communicates through signals far richer than vision and language. Haptics conveys material properties, grasp stability, contact geometry—information cameras cannot see. Neural signals encode motor intent, cognitive state, perceptual experience with a bandwidth far exceeding any existing human-computer interface. Subvocal muscle activity encodes speech intent before any sound is produced. The fourth primitive is the rapid expansion of AI's access to these previously hard-to-reach sensory modalities—driven not only by research but also by an entire ecosystem building consumer-grade devices, software, and infrastructure.
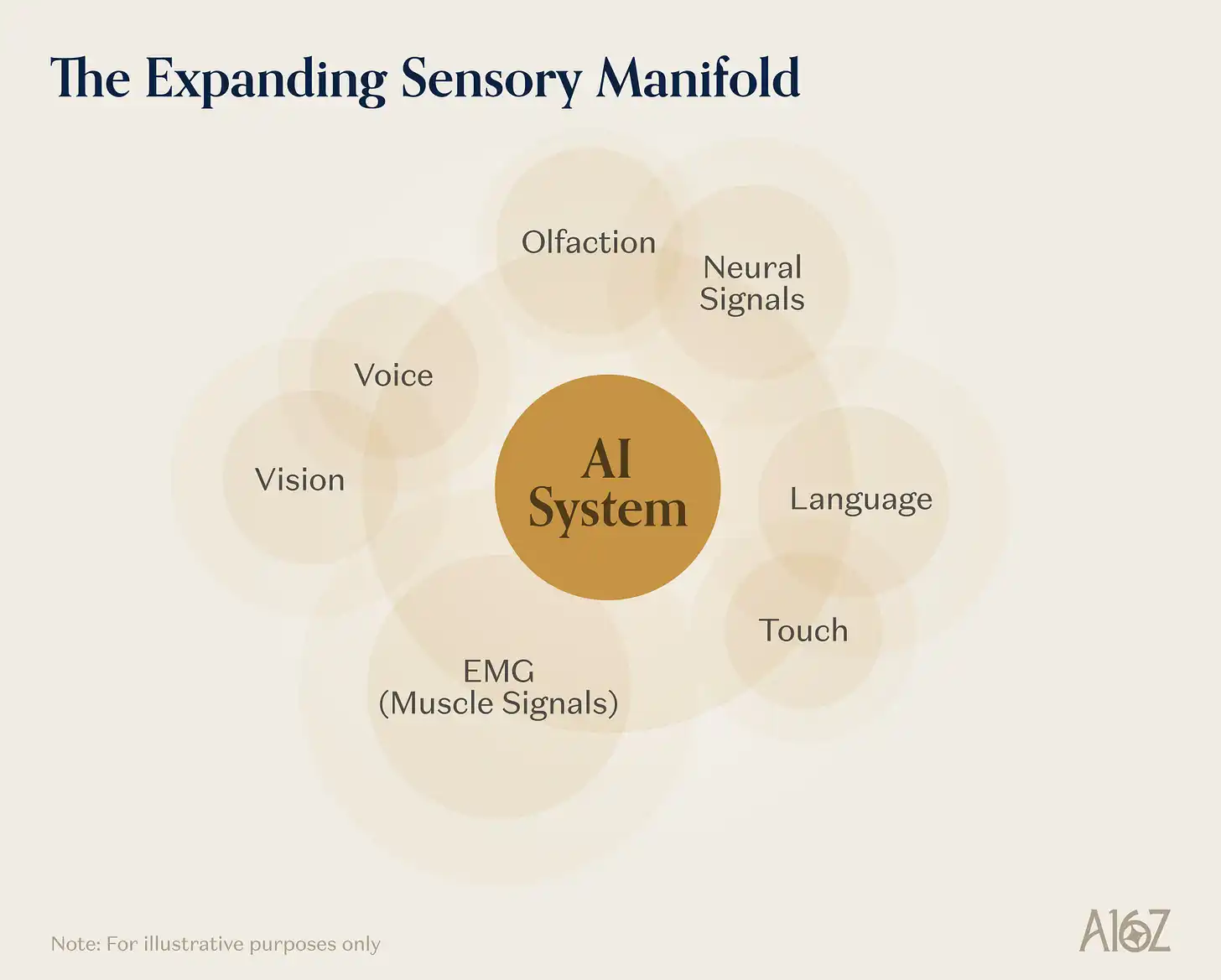
The most直观的指标 (intuitive indicator) is the emergence of new device categories. AR devices have significantly improved in experience and form factor in recent years (companies are already building applications for consumer and industrial scenarios on this platform); voice-first AI wearables give language-based AI a more complete physical world context—they literally follow users into physical environments.
Long-term, neural interfaces may open even more complete interaction modalities. The shift in computing brought by AI creates an opportunity to radically upgrade human-computer interaction, and companies like Sesame are building new modalities and devices for this.
Voice, a more mainstream modality, also brings tailwinds for emerging interaction methods. Products like Wispr Flow promote voice as a primary input (due to its high information density and natural advantages), improving the market conditions for silent speech interfaces as well. Silent speech devices use multiple sensors to capture tongue and vocal cord movements, recognizing language silently—they represent a human-computer interaction modality with even higher information density than speech.
Brain-computer interfaces (invasive and non-invasive) represent a deeper frontier, and the commercial ecosystem around them continues to advance. Signals will appear at the confluence of clinical validation, regulatory approval, platform integration, and institutional capital—a technology category that was purely academic just a few years ago.
Haptic perception is being incorporated into embodied AI architectures, with some models in robotic learning explicitly including touch as a first-class citizen. Olfactory interfaces are becoming real engineering products: wearable olfactory displays using micro odor generators with millisecond response times have been demonstrated in mixed reality applications; olfactory models are also being paired with visual AI systems for chemical process monitoring.
The common pattern in these developments is: they converge at the limit. AR glasses continuously generate visual and spatial data of user interaction with the physical environment; EMG wristbands capture the statistical patterns of human movement intent; silent speech interfaces capture the mapping from subvocal articulation to language output; BCIs capture neural activity at currently the highest resolution; tactile sensors capture the contact dynamics of physical manipulation. Each new device category is also a data generation platform, feeding the underlying models across multiple application domains.
A robot trained on data using EMG to infer movement intent learns different grasping strategies than one trained only on teleoperation data; a lab interface responding to subvocal commands enables a completely different scientist-machine interaction than a keyboard-controlled lab; a neural decoder trained on high-density BCI data produces motor planning representations unavailable through any other channel.
The proliferation of these devices is expanding the effective dimensionality of the data manifold available for training frontier physical AI systems—and much of this expansion is driven by well-capitalized consumer goods companies, not just academic labs, meaning the data flywheel can expand alongside market adoption rates.
Primitive 5: Closed-Loop Agent Systems
The final primitive is more architectural. It refers to the orchestration of perception, reasoning, and action into systems that operate continuously, autonomously, and in a closed loop, working over long time horizons without human intervention.
In language models, the corresponding development is the rise of agent systems—multi-step reasoning chains, tool use, self-correction processes—pushing models from single-turn Q&A tools to autonomous problem solvers. In the physical world, the same transition is happening, just with far more demanding requirements. A language agent can roll back an error at no cost; a physical agent cannot undo a spilled reagent bottle.
Physical world agent systems have three properties that distinguish them from their digital counterparts.
First, they need to be embedded in the experiment or operation loop: directly interfacing with raw instrument data streams, physical state sensors, and execution primitives, so reasoning is grounded in physical reality, not textual descriptions of it.
Second, they require long-horizon persistence: memory, provenance tracking, safety monitoring, recovery behaviors, linking multiple run cycles together, rather than treating each task as an independent episode.
Third, they need closed-loop adaptation: revising strategies based on physical outcomes, not just textual feedback.
This primitive fuses individual capabilities (good world models, reliable action architectures, rich sensor suites) into complete systems capable of autonomous operation in the physical world. It is the integration layer, and its maturation is the prerequisite for the three application areas below to exist as real-world deployments rather than isolated research demos.
Three Domains
The primitives above are general enabling layers; they don't themselves specify where the most important applications will emerge. Many domains involve physical action, physical measurement, or physical perception. What distinguishes "frontier systems" from "merely improved existing systems" is the degree to which model capability improvements and scaling infrastructure compound within the domain—not just better performance, but the emergence of new capabilities previously impossible.
Robotics, AI-driven science, and new human-computer interfaces are the three domains where this compounding effect is strongest. Each assembles the primitives in a unique way, each is bottlenecked by constraints that the current primitives are lifting, and each, in operation, generates as a byproduct a type of structured physical data—data that in turn makes the primitives themselves better, creating feedback loops that accelerate the entire system. They are not the only physical AI domains worth watching, but they are where frontier AI capabilities interact most intensively with physical reality, and are farthest from the current language/code paradigm—thus offering the largest space for new capabilities to emerge—while also being highly complementary to it and able to benefit from its红利 (benefits/advantages).
Robotics
Robotics is the most literal embodiment of physical AI: an AI system must perceive, reason, and exert physical action on the material world in real time. It also constitutes a stress test for every primitive.
Consider how much a general-purpose robot must do to fold a towel. It needs a learned representation—a physical prior—of how deformable materials behave under force, which language pre-training does not provide. It needs an action architecture that can translate high-level instructions into sequences of continuous motion commands at control frequencies of 20 Hz or higher.
It needs simulation-generated training data because no one has collected millions of real towel-folding demonstrations. It needs tactile feedback to detect slippage and adjust grip force, as vision cannot distinguish a secure grasp from a failing one. It also needs a closed-loop controller that can recognize when folding goes wrong and recover, rather than blindly executing a memorized trajectory.
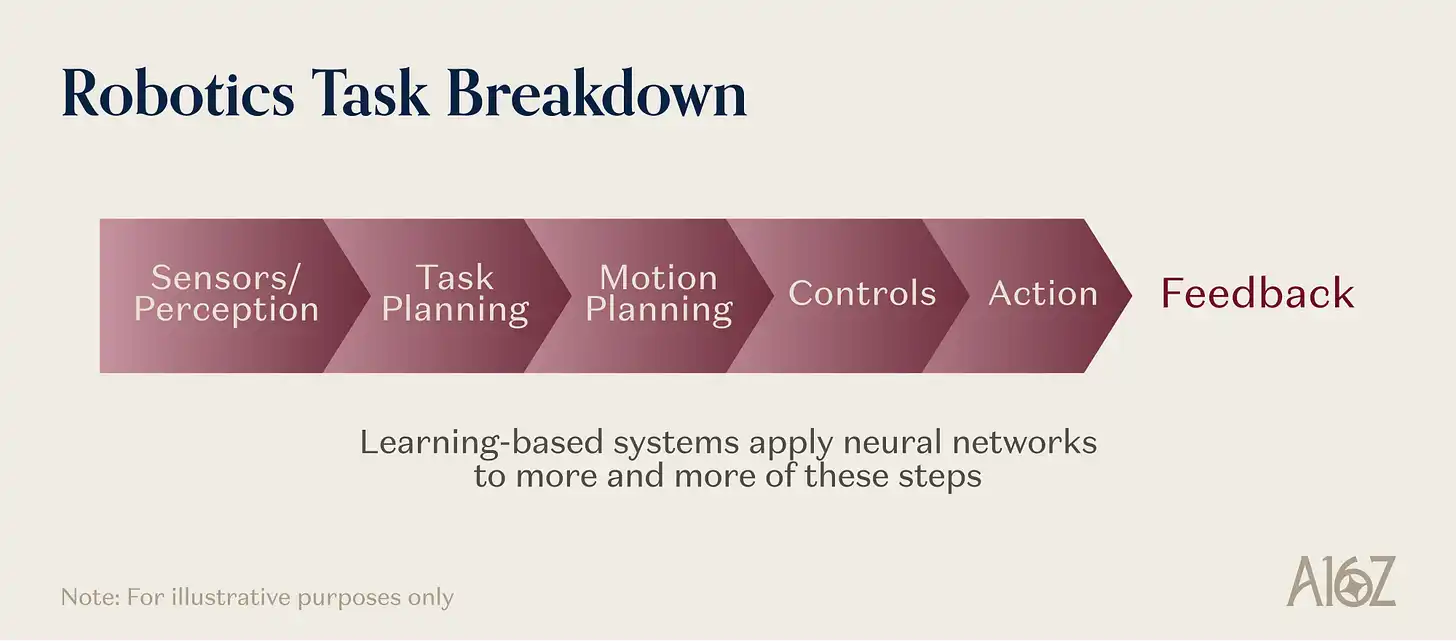
This is why robotics is a frontier system, not a mature engineering discipline with better tools. These primitives are not improving existing robotic capabilities; they are unlocking categories of manipulation, locomotion, and interaction previously impossible outside narrow, controlled industrial settings.
Frontier progress over the past few years has been significant—we've written about it before. First-generation VLAs proved foundation models could control robots for diverse tasks. Architectural advances are connecting high-level reasoning with low-level control in robotic systems. On-device inference is becoming feasible. Cross-embodiment transfer means a model can be adapted to a new robot platform with limited data. The remaining core challenge is reliability at scale, which remains the deployment bottleneck. 95% success rate per step translates to only 60% for a 10-step task chain, while production environments require far higher. RL post-training holds great potential here to help the field cross the capability and robustness threshold needed for the scaling phase.
These advances have implications for market structure. Value in the robotics industry has for decades been concentrated in the mechanical systems themselves. Mechanics remain a critical part of the stack, but as learned strategies become more standardized, value will migrate towards models, training infrastructure, and data flywheels. Robotics also feeds back into the primitives above: every real-world trajectory is training data to improve world models, every deployment failure exposes gaps in simulation coverage, every test on a new embodiment expands the diversity of physical experience available for pre-training. Robotics is both the most demanding consumer of primitives and one of their most important sources of improvement signals.
Autonomous Science
If robotics tests the primitives with "real-time physical action," autonomous science tests something slightly different—sustained multi-step reasoning about causally complex physical systems, over time horizons of hours or days, where experimental results must be interpreted, contextualized, and used to revise strategies.
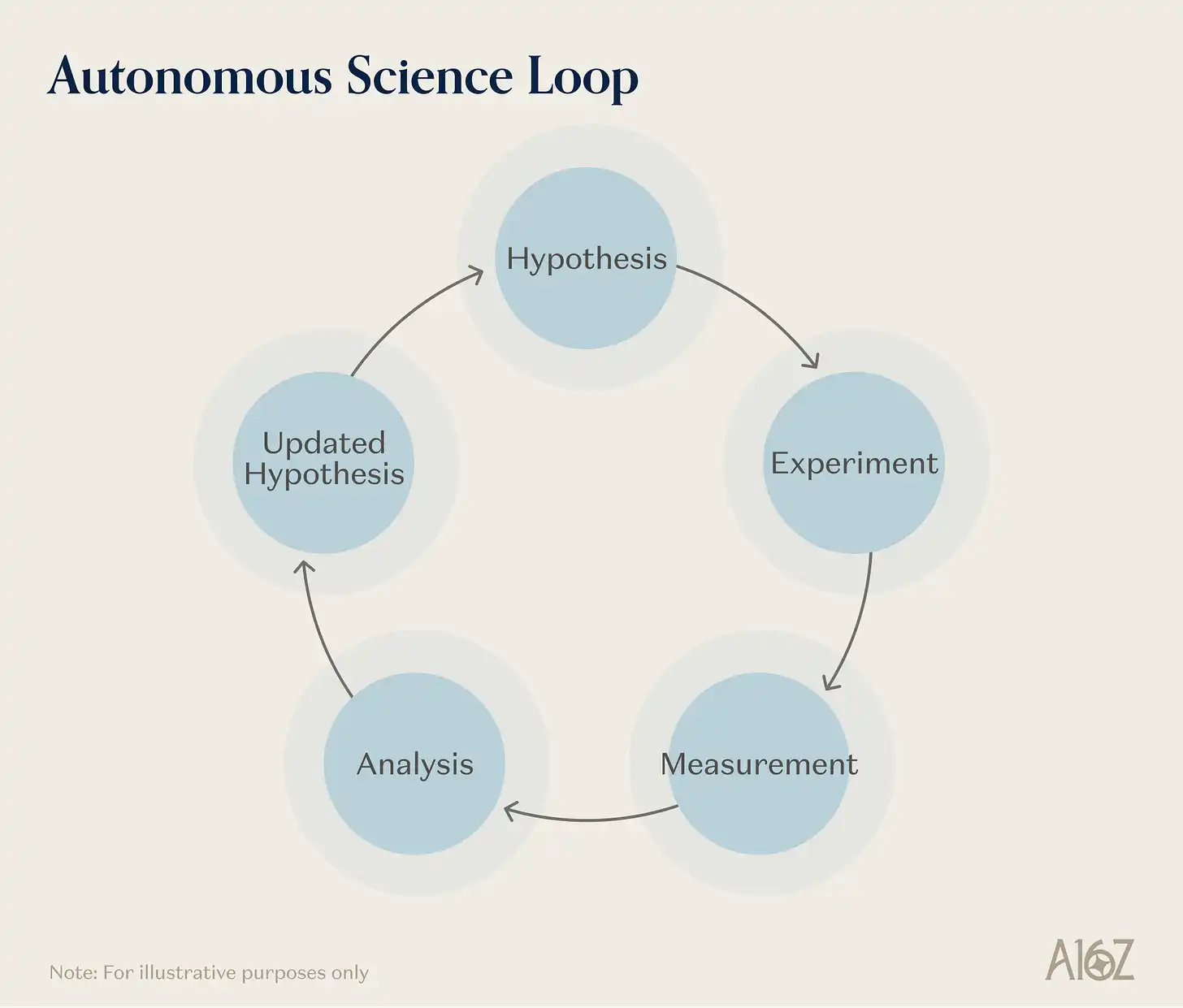
AI-driven science is the most thorough combination of primitives. A self-driving lab (SDL) needs learned representations of physico-chemical dynamics to predict what an experiment will yield; needs embodied action to pipette, position samples, operate analytical instruments; needs simulation for pre-screening candidate experiments and allocating scarce instrument time; needs expanded sensing capabilities—spectroscopy, chromatography, mass spectrometry, and increasingly novel chemical and biological sensors—to characterize results.
It更需要 (needs more than any other domain) the closed-loop agent orchestration primitive: the ability to maintain multi-round "hypothesis-experiment-analysis-revise" workflows无人介入 (without human intervention), preserving provenance, monitoring safety, and adjusting strategies based on information revealed each round.
No other domain invokes these primitives so deeply. This is why autonomous science is a frontier "system," not just lab automation with better software. Companies like Periodic Labs and Medra, in materials science and life sciences respectively, synthesize scientific reasoning capabilities with physical validation capabilities to achieve scientific iteration, producing experimental training data along the way.
The value of such systems is intuitively obvious. Traditional material discovery takes years from concept to commercialization; AI-accelerated workflows could theoretically compress this process far more. The key constraint is shifting from hypothesis generation (which foundation models can assist well) to fabrication and validation (requiring physical instruments, robotic execution, closed-loop optimization). SDLs target this bottleneck.
Another important property of autonomous science—true for all physical world systems—is its role as a data engine. Every experiment run by an SDL produces not just a scientific result, but also a physically grounded, experimentally validated training signal.
A measurement of how a polymer crystallizes under specific conditions enriches the world model's understanding of material dynamics; a validated synthesis pathway becomes training data for physical reasoning; a characterized failure tells the agent system where its predictions break down. The data produced by an AI scientist running real experiments is qualitatively different from internet text or simulation output—it is structured, causal, empirically verified. This is precisely the kind of data physical reasoning models need most and lack other sources for. Autonomous science is the pathway that directly converts physical reality into structured knowledge, improving the entire physical AI ecosystem.
New Interfaces
Robotics extends AI into physical action; autonomous science extends it into physical research. New interfaces extend it into the direct coupling of artificial intelligence with human perception, sensory experience, and bodily signals—devices spanning AR glasses, EMG wristbands, all the way to implantable brain-computer interfaces.
What binds this category together is not a single technology, but a common function: expanding the bandwidth and modality of the channel between human intelligence and AI systems—and in the process, generating data on human-world interaction directly usable for building physical AI.

The distance from the mainstream paradigm is both the challenge and the potential of this field. Language models conceptually know about these modalities but are not natively familiar with the motor patterns of silent speech, the geometry of olfactory receptor binding, or the temporal dynamics of EMG signals.
The representations to decode these signals must be learned from the expanding sensory channels themselves. Many modalities lack internet-scale pre-training corpora; data often can only be produced by the interfaces themselves—meaning the system and its training data co-evolve, something without parallel in language AI.
The near-term manifestation of this field is the rapid rise of AI wearables as a consumer category. AR glasses are perhaps the most visible example, but other wearables primarily using voice or vision as input are also emerging concurrently.
This ecosystem of consumer devices both provides new hardware platforms for extending AI into the physical world and is becoming infrastructure for physical world data. A person wearing AI glasses continuously produces first-person video streams of how humans navigate physical environments, manipulate objects, and interact with the world; other wearables continuously capture biometric and motion data. The installed base of AI wearables is becoming a distributed physical world data acquisition network, recording human physical experience at a previously impossible scale.
Think of the scale of smartphones as consumer devices—a new category of consumer device that allows computers to perceive the world in new modalities at equivalent scale also opens a massive new channel for AI's interaction with the physical world.
Brain-computer interfaces represent a deeper frontier. Neuralink has implanted multiple patients, with surgical robots and decoding software iterating. Synchron's intravascular Stentrode has been used to allow paralyzed users to control digital and physical environments. Echo Neurotechnologies is developing a BCI system for speech restoration based on their research in high-resolution cortical speech decoding.
New companies like Nudge are also being formed, gathering talent and capital to build new neural interface and brain interaction platforms. Technical milestones at the research level are also noteworthy: the BISC chip demonstrated wireless neural recording with 65,536 electrodes on a single chip; the BrainGate team decoded internal speech directly from the motor cortex.
The common thread running through AR glasses, AI wearables, silent speech devices, and implantable BCIs is not just that "they are all interfaces," but that they collectively constitute an increasing-bandwidth spectrum between human physical experience and AI systems—every point on this spectrum supports the continuous progress of the primitives behind this article's three major domains.
A robot trained on high-quality first-person video from millions of AI glasses users learns operational priors completely different from one trained on curated teleoperation datasets; a lab AI responding to subvocal commands is a completely different experience in latency and fluency than a keyboard-controlled lab; a neural decoder trained on high-density BCI data produces motor planning representations unavailable through any other channel.
New interfaces are the mechanism for making the sensory channels themselves larger—they open previously non-existent data channels between the physical world and AI. And this expansion is driven by consumer device companies aiming for scaled deployment, meaning the data flywheel will accelerate alongside consumer adoption.
Systems for the Physical World
The reason to view robotics, autonomous science, and new interfaces as different instances of frontier systems assembled from the same set of primitives is that they enable each other and compound.
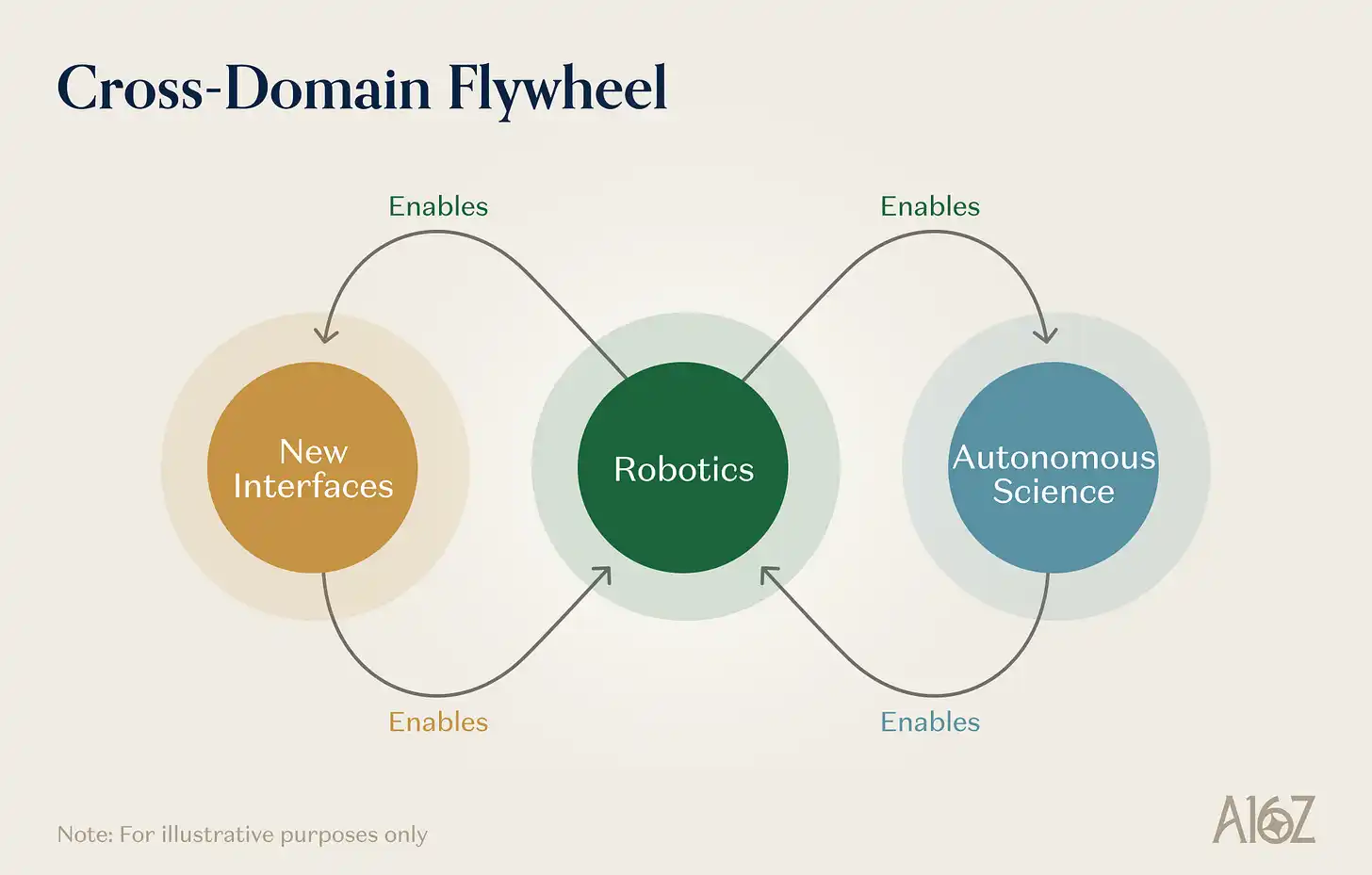
Robotics enables autonomous science. A self-driving lab is essentially a robotic system. The manipulation capabilities developed for general-purpose robots—dexterous grasping, liquid handling, precise positioning, multi-step task execution—can be directly transferred to lab automation. Every step forward in the generality and robustness of robot models expands the range of experimental protocols an SDL can execute autonomously. Every advance in robotic learning lowers the cost and increases the throughput of autonomous experimentation.
Autonomous science enables robotics. The scientific data produced by self-driving labs—validated physical measurements, causal experimental results, material property databases—can provide the kind of structured, grounded training data most needed by world models and physical reasoning engines. Furthermore, the materials and components needed for next-generation robots (better actuators, more sensitive tactile sensors, higher density batteries, etc.) are themselves products of materials science. Autonomous discovery platforms that accelerate materials innovation directly improve the hardware substrate on which robotic learning operates.
New interfaces enable robotics. AR devices are a scalable way to collect data on "how humans perceive and interact with the physical environment." Neural interfaces produce data on human movement intent, cognitive planning, sensory processing. This data is extremely valuable for training robotic learning systems, especially for tasks involving human-robot collaboration or teleoperation.
There is a deeper observation here about the very nature of frontier AI progress itself. The language/code paradigm has produced extraordinary results and is still rising strongly in the scaling era. But the physical world offers an almost infinite supply of new problems, new data types, new feedback signals, new evaluation criteria. Grounding AI systems in physical reality—through robots manipulating objects, labs synthesizing materials, interfaces connecting to biological and physical worlds—we open a new scaling axis complementary to the current digital frontier—and likely mutually improving.
What behaviors these systems will emerge is hard to predict precisely—emergence is defined by capabilities arising from the interaction of independently understandable but combined unprecedented elements. But historical patterns are optimistic. Every time AI systems gained a new modality of interaction with the world—seeing (computer vision), speaking (speech recognition), reading/writing (language models)—the resulting capability leaps far exceeded the sum of their individual improvements. The transition to physical world systems represents the next such phase change. In this sense, the primitives discussed in this article are being built right now, potentially enabling frontier AI systems to perceive, reason, and act upon the physical world, unlocking significant value and progress within it.






