En 2026, el desarrollo global de la IA alcanzó un punto de inflexión histórico: Los gastos de capital en razonamiento por parte de los principales proveedores de nube superaron, por primera vez en la historia, a los gastos de capital en entrenamiento. El foco de la industria se desplazó de "entrenar modelos grandes" a "usar modelos grandes", y la estructura de la demanda de capacidad computacional sufrió un cambio fundamental.
En la era del entrenamiento, la contradicción central de la capacidad computacional era la "precisión doble y la escala de clústeres"; al entrar en la era del razonamiento, la contradicción central se convirtió en "el ancho de banda de memoria y la latencia de comunicación".
El cuello de botella del razonamiento de modelos grandes ya no es solo el cálculo, sino el movimiento de datos: los pesos del modelo, los valores de activación intermedios y la KV Cache necesitan interactuar frecuentemente entre la DRAM externa (como la HBM) y la GPU. Cuanto más grande es el modelo, mayor es el consumo energético y la latencia del movimiento de datos, lo que finalmente supera con creces el consumo energético del cálculo en sí, formando así el "Muro de la Memoria".
Las GPU de NVIDIA han construido una fortaleza sólida con CUDA y NVLink, pero aún no pueden evitar los tiempos de inactividad de las GPU causados por los cuellos de botella en el ancho de banda.
La empresa china de modelos grandes Zhipu realizó un experimento muy simple: en un clúster de razonamiento con 512 GPUs, manteniendo las GPU, el modelo y el código sin cambios, solo al cambiar el límite superior del ancho de banda de red de 200GB/s a 400GB/s, el rendimiento de razonamiento aumentó directamente un 10% y la latencia de salida del primer token se redujo un 19%. La lógica es simple: si ensanchas la carretera, los coches pueden correr más rápido.
Sin embargo, arquitecturas no basadas en GPU, representadas por Cerebras, parecen estar abriendo una brecha en este Muro de la Memoria.

Comparación de tamaño entre el chip Cerebras WSE-3 y la GPU NVIDIA B200
La esencia de Cerebras: Una máquina de computación "cerca de la memoria" basada en SRAM
Cerebras Systems fue fundada en Silicon Valley por Andrew Feldman y otros. El equipo fundador original provenía en su mayoría de una empresa llamada SeaMicro, especializada en servidores micro de bajo consumo, que luego fue adquirida por AMD. Luego:
En 2015, el equipo fundador estableció la ruta de la "computación a escala de oblea".
En 2016, completaron el registro, la ronda de financiación Serie A, y entraron en una fase de desarrollo en modo sigiloso.
En 2019, lanzaron su primer producto, el chip WSE-1 y el sistema CS-1, basados en el proceso de 16nm de TSMC.
En 2021, lanzaron la segunda generación de productos, basados en el proceso de 7nm de TSMC.
En 2024, lanzaron la tercera generación de productos (WSE-3 / CS-3), basados en el proceso de 5nm de TSMC. El chip y el sistema se fabricaron completamente en los Estados Unidos, siendo un sistema de chips puramente de fabricación estadounidense.
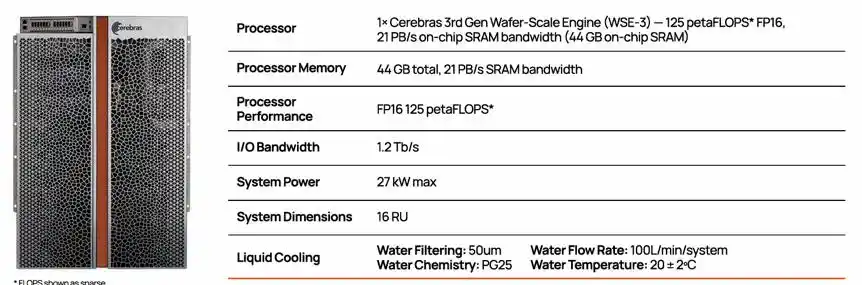
Configuración del sistema CS-3, que incluye 1 chip WSE-3
La filosofía arquitectónica del Motor a Escala de Oblea (Wafer-Scale Engine, WSE) de Cerebras es simple, directa y va al grano: Utilizar la ampliación extrema del espacio físico para obtener una compresión extrema de la latencia en el movimiento de datos.
Un chip normal se fabrica cortando una oblea en muchos chips pequeños, como hace NVIDIA con sus GPUs. Cerebras hace lo contrario: no corta, sino que toma casi toda la oblea para hacer un chip gigantesco, llamado Wafer-Scale Engine, WSE.
Mientras que un chip tradicional se forma cortando una oblea completa de 300 mm de diámetro en cientos de chips pequeños; Cerebras opta por conservar la oblea completa y utilizarla directamente como todo el chip. El WSE-3 más reciente tiene 4 billones de transistores, 900,000 núcleos de IA, cada uno equipado con 48 KB de SRAM local, lo que le da al chip completo 44 GB de SRAM en el chip, proporcionando un ancho de banda de memoria en el chip (on‐chip memory bandwidth) de 21 PB/s y un ancho de banda de red (fabric bandwidth) de 214 Pb/s. Esto es miles de veces mayor que el ancho de banda de la HBM tradicional.
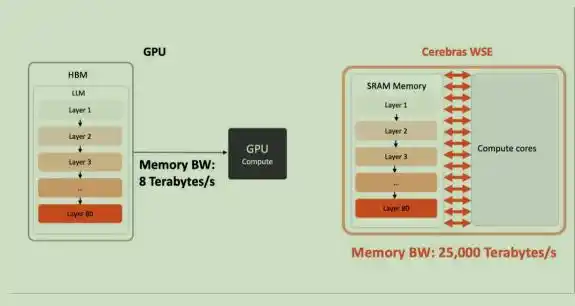
El ancho de banda de memoria de Cerebras WSE es 2625 veces mayor que el del chip empaquetado NVIDIA B200, rompiendo el cuello de botella del ancho de banda de memoria en escenarios de razonamiento de modelos grandes.
En la arquitectura de Cerebras, los pesos del modelo nunca se almacenan en la SRAM, sino en la memoria externa MemoryX, y se transfieren capa por capa hacia el gran chip. La implementación separa el almacenamiento de los pesos del modelo neuronal de las unidades de cálculo.
Todos los pesos del modelo se almacenan externamente en el módulo de expansión de memoria MemoryX. Los pesos necesarios para el cálculo de cada capa de la red se transmiten a demanda, capa por capa, al sistema CS-3. Los pesos se almacenan en la DRAM y la memoria flash de MEMORY X y se transmiten al sistema CS-3 a velocidad de ancho de banda completo. Estos pesos no se almacenan en el sistema CS-3, ni siquiera de forma temporal en caché. El CS-3 realiza los cálculos confiando en el mecanismo de flujo de datos subyacente de sus núcleos.
Cerebras, gracias a su arquitectura a escala de oblea, muestra barreras aplastantes en el razonamiento de LLM limitado por el ancho de banda de memoria. Durante la generación token por token, los pesos fluyen capa por capa desde el MemoryX externo hasta el CS-3. Ejecutando diferentes modelos, la velocidad de tokens es de 1.5 a 5 veces mayor que la de la NVIDIA B200.
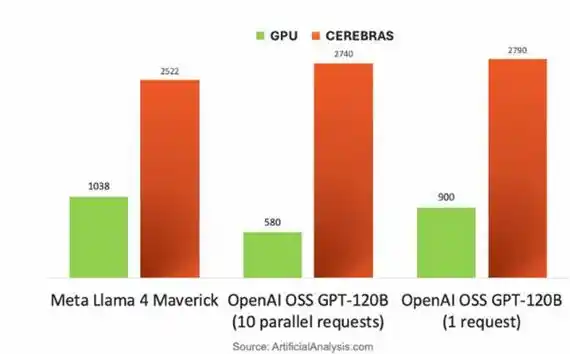
Comparación de la velocidad de tokens entre la GPU NVIDIA DGX B200 y el chip Cerebras CS-3, ejecutando diferentes modelos grandes
Su ventaja central radica en: los 44 GB de SRAM en el chip del CS-3 proporcionan un ancho de banda súper alto de 21 PB/s (2625 veces el de la B200) y una interconexión de 214 Pb/s, liberando la transmisión del flujo de pesos de las limitaciones de la interfaz HBM. Por lo tanto, su rendimiento es especialmente destacado en TTFT (Time To First Token, tiempo desde que se envía la solicitud hasta que el modelo devuelve el primer token), contextos largos y cargas de trabajo de agentes.
Aunque los pesos están externos en MemoryX y se cargan capa por capa a demanda y no se almacenan en caché en el chip, el CS-3, confiando en el mecanismo de flujo de datos de sus núcleos, realiza cálculos completos con precisión FP16 sin pérdidas en la SRAM; además, gracias a la escalabilidad lineal del rendimiento, también libera un rendimiento agregado sorprendente en razonamiento concurrente multiusuario.
Además del ancho de banda, también hay una ventaja en consumo energético. Recientemente, Liu Sheng, presidente de Zhongji Innolight, también mencionó en un discurso que el requisito de los clientes para los módulos ópticos es de 1 pJ/bit, mientras que actualmente es de 10 pJ/bit. En el chip de Cerebras, el consumo energético de la interconexión es de solo 0.15 pJ/bit, mientras que el consumo energético de la interconexión de las GPU actuales es de 10 pJ/bit.
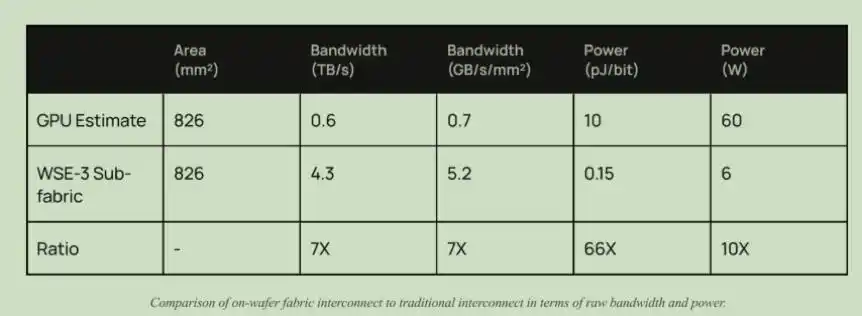
Comparación del ancho de banda y el consumo energético entre la arquitectura de interconexión de Cerebras y la de las GPU
Por lo tanto, si la arquitectura de chip grande a escala de oblea de Cerebras se convierte en la corriente principal para el razonamiento o incluso el entrenamiento de IA, podría tener un impacto significativo y un cambio estructural en el volumen de envíos de los módulos ópticos tradicionales y el CPO (Co-Packaged Optics). La lógica central es: la alta demanda de módulos ópticos y CPO existe esencialmente para resolver el cuello de botella del ancho de banda en la "interconexión entre chips" y "interconexión entre nodos" en los clústeres de GPU; mientras que la arquitectura de Cerebras resuelve el problema precisamente "eliminando la interconexión distribuida".
Contraintuitivo: Los "falsos y verdaderos" puntos débiles del chip grande a escala de oblea
El núcleo de un chip siempre reside en el Trade Off (el arte de la compensación). Cerebras, para lograr un ancho de banda extremo de la SRAM en el chip, también trae algunos problemas.
¿Bajo rendimiento?
Todo lo contrario, el tamaño de un solo núcleo de IA se reduce a 0.05 mm² (1% del tamaño de un núcleo de cálculo individual de la H100), por lo que el rendimiento es en realidad más alto. Mediante el enrutamiento en el chip, se pueden apagar y evitar los núcleos defectuosos, lo que aumenta la tolerancia a defectos en 100 veces en comparación con los procesadores multinúcleo tradicionales. De hecho, el chip completo tiene 1 millón de núcleos de IA, pero considerando el rendimiento, se anuncian oficialmente como 900,000 núcleos de IA.
¿Solo es bueno en razonamiento, no en entrenamiento?
En los primeros años desde la fundación de Cerebras, el entrenamiento era el tema principal, por lo que la compañía siempre se centró mucho en el trabajo de entrenamiento. Es solo que cuando la demanda de razonamiento se disparó, la gente descubrió que sus ventajas en razonamiento eran más evidentes.
En realidad, el cálculo distribuido simplificado también trae una serie de ventajas, como la reducción de la complejidad del código y la reducción de la sobrecarga de comunicación.
Entrenar un modelo de 175 mil millones de parámetros en 4000 GPUs generalmente requiere alrededor de 20,000 líneas de código de entrenamiento distribuido.
Cerebras logró un entrenamiento equivalente con 565 líneas de código: todo el modelo cabe en la oblea y no es necesario lidiar con la complejidad del paralelismo de datos.
La escalabilidad de la SRAM está muerta, la ventaja central se enfrenta a un techo físico.
El producto de tercera generación se basa en el proceso de 5nm de TSMC, y su capacidad de SRAM solo aumentó un 10% en comparación con el producto de segunda generación basado en el proceso de 7nm de TSMC. Después de los 5nm, el área de la celda de SRAM casi ya no se reduce con los avances en el proceso.
Esto significa que Cerebras ya no puede aumentar significativamente su ventaja central (capacidad de SRAM) actualizando el proceso de TSMC (por ejemplo, pasando de 5nm a 3nm) como lo hacía antes.
Limitados por el tamaño de la oblea, la capacidad de disipación de calor y el costo de fabricación, los recursos de almacenamiento en el chip, como la SRAM, son difíciles de escalar linealmente de manera sincronizada con los núcleos de cálculo, encontrándose con un cuello de botella en la proporción de recursos. Esto prácticamente bloquea su camino de evolución.
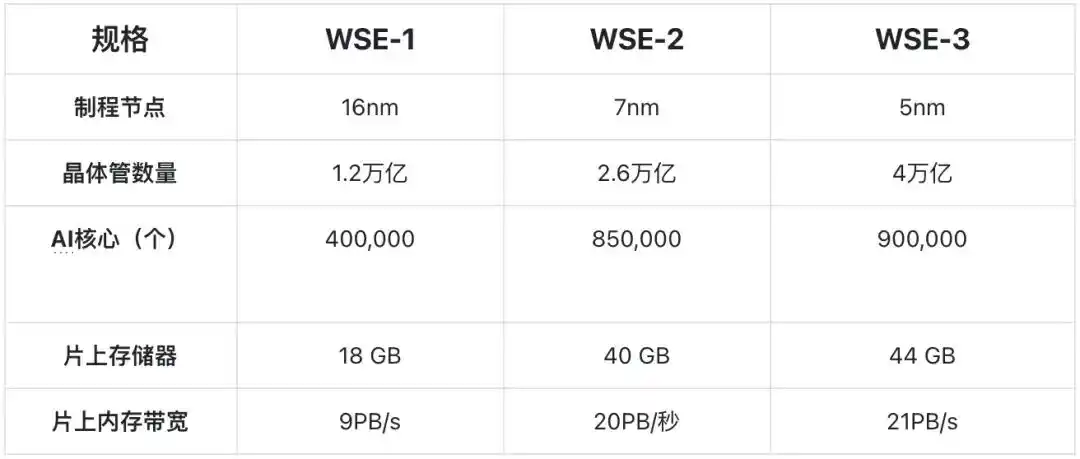
Especificaciones técnicas de las tres generaciones de productos de Cerebras
El triple infierno de la disipación de calor, el proceso y el ecosistema.
El calor se concentra en toda la oblea, la densidad del flujo de calor es alta, por lo que debe depender de salas de servidores personalizadas y sistemas de refrigeración líquida dedicados. Además, la generalidad del ecosistema significa que los clientes deben adaptarse a su pila de software personalizada, la compatibilidad con marcos de programación generales existentes como CUDA es débil, y los costos de portabilidad y adaptación del software son altos.
Bajo ancho de banda fuera del chip, convirtiéndose en una "isla" de expansión.
Debido a las limitaciones del diseño físico a escala de oblea, el número de pines de E/S que se pueden sacar en el borde del WSE es extremadamente limitado, lo que resulta en un ancho de banda de E/S de solo 150 GB/s. Comparado con el ancho de banda bidireccional de 1.8 TB/s de NVIDIA NVLink, esto es como una caracola. Esto significa que es extremadamente difícil para el WSE expandirse hacia afuera a alta velocidad. Aunque la interconexión SwarmX de Cerebras funciona bastante bien en combinaciones de múltiples sistemas, frente a modelos muy grandes que requieren interconexión de alta velocidad entre múltiples chips, el ancho de banda externo extremadamente bajo se convierte en una limitación física estructural.
Disputa de rutas: Autodesarrollo de los grandes fabricantes, ¿cuánto tiempo le queda a la ventana de oportunidad de Cerebras?
Los métodos de los grandes fabricantes para resolver la "necesidad de mayor ancho de banda y menor latencia en el razonamiento" no se limitan a la ruta de la oblea completa. Están llevando a cabo un cerco a la ventaja tecnológica de las startups a través de tres caminos paralelos.
1 Chips ASIC autodesarrollados
El Google TPU v8 ya se ha dividido en versiones específicas para entrenamiento y específicas para razonamiento; el AWS Trainium 4 está en camino; el Microsoft Maia ya se usa internamente en Azure, construido sobre el proceso de 3nm de TSMC, con núcleos tensoriales nativos FP8/FP4, un sistema de memoria rediseñado, equipado con 216 GB de HBM3e y 272 MB de SRAM en el chip; incluso Anthropic ha comenzado a evaluar el desarrollo de su propio chip de razonamiento.
Esta ruta tiene una probabilidad muy alta, y conducirá directamente a que el TAM (Total Addressable Market, mercado total direccionable) de "adquisiciones de razonamiento de terceros" en 2028 se comprima entre un 10% y un 25%.
2 La generalización del proceso en la ruta del empaquetado estándar
Este es un golpe directo y contundente para Cerebras.
El SoW (System-on-Wafer) de TSMC ya está ampliamente disponible para los clientes, y el interposer CoWoS 9.5x estará disponible en 2027.
Lo que hacen estos dos productos – unir múltiples dies a nivel de oblea – es esencialmente generalizar y popularizar el proceso físico de Cerebras.
El Vera Rubin de NVIDIA entrará en este ecosistema en la segunda mitad de 2026.
Aunque la tecnología de unión entre retículas (cross-reticle stitching) propia de Cerebras es exclusiva, la ventana de exclusividad es de solo 2 a 3 años como máximo. Después de 2027-2028, su barrera de proceso será diluida por el empaquetado avanzado de TSMC.
3 La ruptura de la interconexión/óptica computacional
La interconexión y el muro de memoria de los chips electrónicos han llegado a su límite. El alto ancho de banda, baja latencia y cero interferencia de los fotones son la solución definitiva.
La ruta óptica representada por Lumentum está surgiendo. La mayor ventaja de la oblea completa es el cálculo en el chip, pero los modelos inevitablemente serán cada vez más grandes, y la interconexión de alta velocidad más allá de la escala de oblea es una necesidad.
Con la madurez del CPO (Co-Packaged Optics) y las interconexiones ópticas, es muy probable que en el futuro veamos E/S ópticas introducidas directamente en la oblea WSE, rompiendo las limitaciones de la interconexión eléctrica; y NVIDIA también podría, a través de la adquisición de empresas con ventajas arquitectónicas específicas (como Groq LPU), combinadas con la interconexión óptica, desarrollar sistemas a escala de oblea compatibles con el software existente de sus súper nodos.
Carrera al borde del precipicio: El negocio y la entrega de Cerebras
Cerebras se enfrenta actualmente a una carrera al borde del precipicio forzada por enormes pedidos.
Las transacciones con grandes clientes como OpenAI obligan a Cerebras a transformarse de una empresa de chips a un nuevo tipo de proveedor de servicios en la nube. Ya no solo vende hardware, sino que necesita bloquear y construir una enorme cantidad de capacidad de energía e instalaciones de centros de datos a corto plazo.
Según los requisitos del contrato, Cerebras necesita entregar una capacidad de centro de datos de 250 MW por año entre 2026 y 2028. Sin embargo, los requisitos de los sistemas a escala de oblea para las salas de servidores son extremadamente altos, no se pueden meter directamente en un IDC tradicional con refrigeración por aire. Actualmente, el progreso de Cerebras en la preparación de la capacidad de los centros de datos ya está claramente por detrás de los requisitos del contrato.
Desde la fabricación del chip hasta la construcción de la fábrica, desde la aprobación de la energía hasta el despliegue del sistema de enfriamiento, esto es un pantano de activos pesados y ciclos largos.
Epílogo: ¿A la izquierda o a la derecha?
Volviendo a la premisa inicial, cuando el punto de inflexión de la capacidad computacional de razonamiento ha llegado, el núcleo de la arquitectura de la capacidad computacional siempre reside en la compensación.
No hay una respuesta absolutamente correcta o incorrecta, solo la solución óptima relativa para la carga de trabajo más importante. Y la carga de trabajo ya está cambiando.
Cerebras fue a la izquierda, optando por la optimización física extrema, usando toda la oblea y una enorme cantidad de SRAM para obtener una latencia extremadamente baja en una sola tarea, lo que es invencible en escenarios extremadamente sensibles a la latencia del primer token.
NVIDIA fue a la derecha, optando por mantener la generalidad, usando HBM + NVLink + un gran rendimiento agregado de clústeres para enfrentar los mil cambios de la carga de trabajo, respondiendo a lo cambiante con lo inmutable.
Vientos y olas se levantan, el camino por delante es incierto. Es precisamente esta doble incertidumbre técnica y comercial la que incuba la posibilidad de la disrupción. En la marea computacional hacia la AGI, es aún temprano para sacar conclusiones definitivas – porque donde hay incertidumbre, hay oportunidad.
Este artículo proviene del WeChat Official Account "Garlic Particle Machine Research Institute", autor: Pili Youxia






