Large models have been growing in size, with the mainstream view being that the more parameters a model has, the closer it gets to human-like thinking. However, a paper published by a Zhejiang University team on April 1 in Nature Communications presents a different perspective (original article link: https://www.nature.com/articles/s41467-026-71267-5). They found that as model size (primarily SimCLR, CLIP, DINOv2) increases, the ability to recognize specific objects does continue to improve, but the ability to understand abstract concepts not only fails to improve but can even decline. When parameters increased from 22.06 million to 304.37 million, performance on concrete concept tasks rose from 74.94% to 85.87%, while performance on abstract concept tasks dropped from 54.37% to 52.82%.
Differences Between Human and Model Thinking
When the human brain processes concepts, it first forms a system of categorical relationships. Swans and owls look different, but humans still classify them both as birds. Moving up, birds and horses can be further grouped into the animal category. When humans encounter something new, they often first consider what it resembles from past experience and which category it might belong to. Humans continuously learn new concepts, then organize this experience, using this relational system to recognize new things and adapt to new situations.
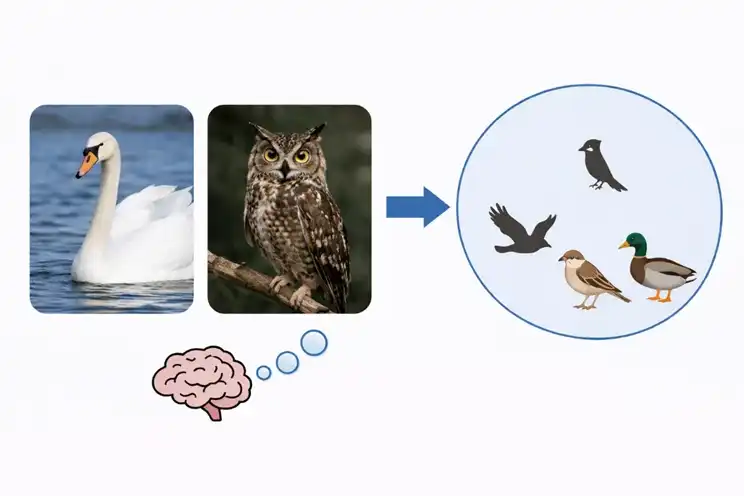
Models also classify, but they form these classifications differently. They rely primarily on patterns that repeatedly appear in large-scale data. The more frequently a specific object appears, the easier it is for the model to recognize it. When it comes to larger categories, models struggle more. They need to capture the commonalities between multiple objects and then group these commonalities into the same category. Existing models still have significant shortcomings here. As parameters continue to increase, performance on concrete concept tasks improves, while performance on abstract concept tasks sometimes even decreases.

A commonality between the human brain and models is that both internally form a system of categorical relationships. However, their emphases differ. The higher-order visual regions of the human brain naturally distinguish broad categories like living and non-living things. Models can separate specific objects but find it difficult to stably form these larger categories. This difference means the human brain more easily applies past experience to new objects, allowing for rapid categorization of unseen things. Models, conversely, rely more on existing knowledge, so when encountering new objects, they tend to focus on superficial features. The method proposed in the paper addresses this characteristic, using brain signals to constrain the model's internal structure, making it closer to the human brain's categorization method.
The Solution from the Zhejiang University Team
The team's proposed solution is also unique: instead of simply adding more parameters, they use a small amount of brain signal data for supervision. These brain signals come from recordings of brain activity while humans view images. The original paper states the goal as transferring 'human conceptual structures' to DNNs. This means teaching the model, as much as possible, how the human brain classifies, generalizes, and groups similar concepts together.
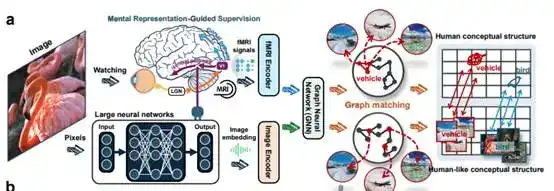
The team conducted experiments using 150 known training categories and 50 unseen test categories. The results showed that as this training progressed, the distance between the model's representations and the brain representations continuously narrowed. This change occurred for both categories, indicating that the model was learning not just individual samples but truly beginning to learn a conceptual organization method more akin to the human brain.
After this process, the model demonstrated stronger few-shot learning capabilities and performed better in novel situations. In a task requiring the model to distinguish abstract concepts like living vs. non-living things with very few examples, the model improved by an average of 20.5%, even surpassing much larger control models. The team also conducted 31 additional specialized tests, where several types of models showed improvements of nearly ten percent.
Over the past few years, the familiar path in the modeling industry has been larger model scale. The Zhejiang University team has chosen a different direction: moving from 'bigger is better' to 'structured is smarter'. Scaling up is indeed useful, but it primarily improves performance on familiar tasks. Abstract understanding and transfer capabilities, inherent to humans, are equally crucial for AI. This requires future AI thinking structures to more closely resemble the human brain. The value of this direction lies in redirecting the industry's attention from pure size expansion back to the cognitive structure itself.
Neosoul and the Future
This points to a larger possibility: AI evolution may not only occur during the model training phase. Model training can determine how AI organizes concepts and forms higher-quality judgment structures. Then, after entering the real world, another layer of AI evolution just begins: how an AI agent's judgments are recorded, tested, and how they continuously grow and evolve through real-world competition, learning and evolving on their own, much like humans. This is precisely what Neosoul is doing now. Neosoul doesn't just have AI agents produce answers; it places AI agents into a system of continuous prediction, verification, settlement, and selection, allowing them to continuously optimize themselves based on predictions and outcomes, preserving better structures and淘汰ing worse ones. What the Zhejiang University team and Neosoul jointly point towards is actually the same goal: enabling AI to not just solve problems, but to possess comprehensive thinking abilities and continuously evolve.





