Author: @BlockCookies
Hello everyone, I am the Data Activity Lead at RootData.
The second round of RootData's Bounty Activity has been successfully concluded. While sharing this review, rather than just cold numbers, I'd like to discuss: Why is promoting 'data transparency' in Web3 extremely challenging, yet something that must be done?
First, here are the data for this round's activity: Over 140 unique users participated, providing 1220 pieces of feedback, ultimately resulting in 564 validated data points, with an average approval rate of 46.2%.
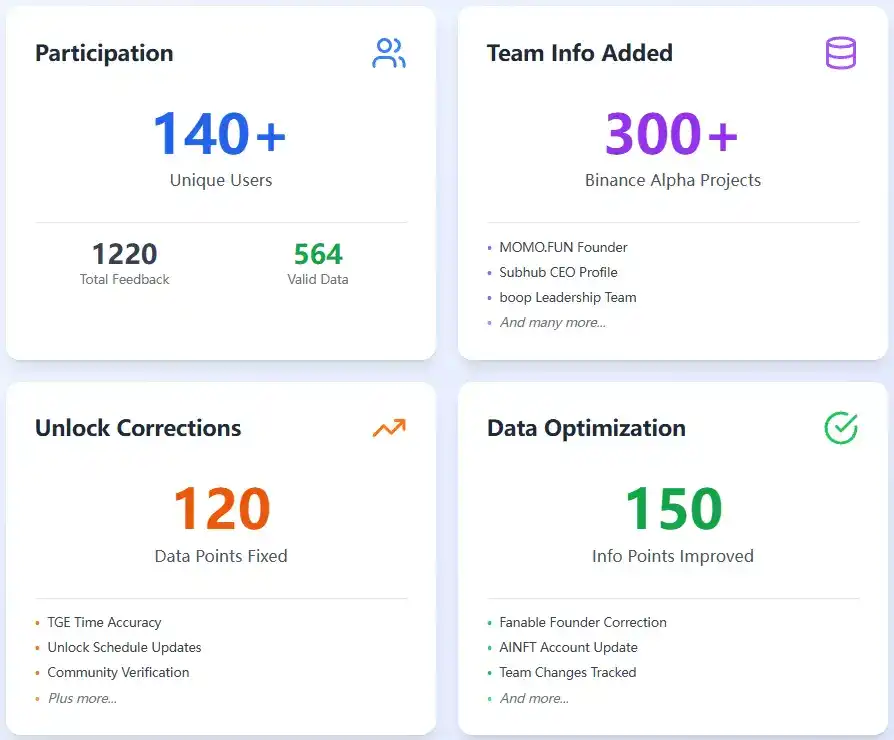
Overview of Round 2 Bounty Activity Data
This activity helped RootData supplement nearly 300+ 'People Behind the Alpha,' such as executives and leads from MOMO.FUN, Subhub, boop, etc. These individuals often do not list their positions in their X bios or LinkedIn but may appear at events or be active in communities.
Additionally, we corrected about 120 token unlock information points. Some had inaccurate TGE times, while some had unlock rules not disclosed promptly; these issues were all optimized through the community's efforts.
Furthermore, we conducted in-depth optimization on 150 existing data points. For instance, we found that the founder of Fanable was mistakenly recorded as a non-Web3 individual with the same name, and its Managing Director Sergio had already left; the AINFT project had long changed its Twitter account...
Why are we pushing for transparency in the Web3 space? This data might seem mundane, and RootData itself is an expert in aggregating off-chain data, so why spend our own funds and mobilize the community for such 'grunt work'?
Honestly, when my boss @yubopan1 assigned me this task, I hesitated too. But one thing he said struck a chord: "From the ICO era to the FTX incident, the biggest tragedy for users is the lack of fair 'investment知情权 (right to know).' As crypto moves towards compliance, data platforms must be at the forefront, acting as that mirror."
As the data lead, I deeply feel his judgment is correct: Relying on a single source is insufficient for accuracy. Data未经多方验证 is不足以让 RootData become a platform trusted by investors.
Take token unlock data alone; it's very 'fragmented': the same project might have 5 different versions across 5 mainstream unlock platforms.
As is well known, Binance Listing requires submitting at least 3 team members. RootData has cataloged over 18,000 industry figures. How many update their resumes urgently before TGE, and how many 'quietly leave' after securing funding?
This round revealed: Significant projects experience frequent core team changes around TGE. For investors, this is often a 'barometer' of the project's direction. If no one verifies and discloses this, it gets lost in the daily information overload.
To ensure 'transparency' isn't just a slogan, our current implemented solutions include:
- Monthly disclosures of false funding intelligence.
- Regular in-depth research, like the recently published 《Exchange Listing Decision Report》.
- Increasing the frequency of LinkedIn profile动态抓取 and verification.
Moreover, we insist on rigorous review standards. In this round, a user provided detailed information on the River development team, but the source was merely a post by a third-party account on Binance Square. Despite the detailed content, due to the lack of official endorsement or multi-source cross-verification, we still chose not to approve it.
This round focused on 'Binance Alpha,' and we also attempted communication with the Binance team. We don't aim to target any specific exchange; on the contrary, we hope to stand together with industry giants.
We once reached out to the Binance team to confirm some key dimensions, and the response was very positive: "If there's any information regarding Alpha that needs confirmation, feel free to communicate anytime."
Single-point data correction is just the beginning. In the future, RootData will connect 'discrete data points' into 'logically rigorous transparency reports,'甚至 transforming them into practical investment strategies.
Transparency is a持久战 (long-term battle) and an inevitable path for Web3 to go mainstream. We need more 'data hunters' to join us in揭开迷雾 (lifting the fog). Everyone is welcome to leave comments and discuss.





