Want to know which large language model truly performs the strongest in OpenClaw's real-world agent tasks?
MyToken, based on evaluation websites, has compiled a transparent benchmark focused on assessing the practical capabilities of AI coding agents, looking solely at the core dimension of success rate (speed and cost belong to other independent dimensions, to be analyzed separately later). Fully public and reproducible, it only presents rigorous evaluation standards + the latest Top 10 success rate rankings.
I. Evaluation Dimension:Success Rate
Specific standard: The percentage of given tasks that the AI agent completes accurately and fully. Each task adopts a highly standardized process:
-
Precise user prompt
Sent to the agent in full to simulate real user request scenarios
-
Expected Behavior
Clearly states acceptable implementation methods and key decision points
-
Scoring Criteria (checklist)
Lists an atomic success判定 (judgment) checklist for verification item by item
II. Three Scoring Methods
This evaluation primarily employs 3 scoring methods:
-
Automated Checks: Python scripts directly verify objective results like file content, execution records, tool calls, etc.
-
LLM Judge: Claude Opus scores according to a detailed scale (content quality, appropriateness, completeness, etc.)
-
Hybrid Mode: Combines automated objective checks + LLM judge qualitative assessment
All task definitions, Prompts, and scoring logic are fully public for retesting and verification.
III. Tasks Used for Evaluation
This benchmark covers 23 tasks across different categories. It spans multiple dimensions including basic interaction, file/code operations, content creation, research & analysis, system tool calls, memory persistence, etc., highly aligning with developers' daily use scenarios of OpenClaw:
-
Sanity Check(Automated) —— Process simple instructions and reply to greetings correctly
-
Calendar Event Creation(Automated) —— Generate a standard ICS calendar file from natural language
-
Stock Price Research(Automated) —— Query stock prices in real-time and output a formatted report
-
Blog Post Writing(LLM Judge) —— Write a ~500-word structured Markdown blog post
-
Weather Script Creation(Automated) —— Write a Python weather API script with error handling
-
Document Summarization(LLM Judge) —— Provide a refined 3-part summary of the core themes
-
Tech Conference Research(LLM Judge) —— Research and organize information (name, date, location, link) for 5 real tech conferences
-
Professional Email Drafting(LLM Judge) —— Politely decline a meeting and propose an alternative
-
Memory Retrieval from Context(Automated) —— Precisely extract dates, members, tech stack, etc., from project notes
-
File Structure Creation(Automated) —— Automatically generate standard project directories, README, .gitignore
-
Multi-step API Workflow(Hybrid) —— Read config → Write calling script → Fully document
-
Install ClawdHub Skill(Automated) —— Install from the skill repository and verify usability
-
Search and Install Skill(Automated) —— Search for weather-related skills and install correctly
-
AI Image Generation(Hybrid) —— Generate and save an image based on description
-
Humanize AI-Generated Blog(LLM Judge) —— Rewrite machine-like content into natural spoken language
-
Daily Research Summary(LLM Judge) —— Synthesize multiple documents into a coherent daily summary
-
Email Inbox Triage(Hybrid) —— Analyze multiple emails and organize a report by urgency
-
Email Search and Summarization(Hybrid) —— Search archived emails and extract key information
-
Competitive Market Research(Hybrid) —— Competitive analysis in the enterprise APM field
-
CSV and Excel Summarization(Hybrid) —— Analyze spreadsheet files and output insights
-
ELI5 PDF Summarization(LLM Judge) —— Explain a technical PDF in language a 5-year-old can understand
-
OpenClaw Report Comprehension(Automated) —— Precisely answer specific questions from a research report PDF
-
Second Brain Knowledge Persistence(Hybrid) —— Store information across sessions and recall it accurately
IV. Core Conclusion: Top 10 Large Model Rankings by Success Rate (Best % / Avg %)
-
Data updated to April 7, 2026
-
Best % is the single highest success rate, Avg % is the average success rate over multiple runs, better reflecting stability
Below are the top ten models by success rate:
-
anthropic/claude-opus-4.6(Anthropic)——93.3% / 82.0%
-
arcee-ai/trinity-large-thinking(Arcee AI)——91.9% / 91.9%
-
openai/gpt-5.4(OpenAI)——90.5% / 81.7%
-
qwen/qwen3.5-27b(Qwen)——90.0% / 78.5%
-
minimax/minimax-m2.7(MiniMax)——89.8% / 83.2%
-
anthropic/claude-haiku-4.5(Anthropic)——89.5% / 78.1%
-
qwen/qwen3.5-397b-a17b(Qwen)——89.1% / 80.4%
-
xiaomi/mimo-v2-flash(Xiaomi)——88.8% / 70.2%
-
qwen/qwen3.6-plus-preview(Qwen)——88.6% / 84.0%
-
nvidia/nemotron-3-super-120b-a12b(NVIDIA)——88.6% / 75.5%
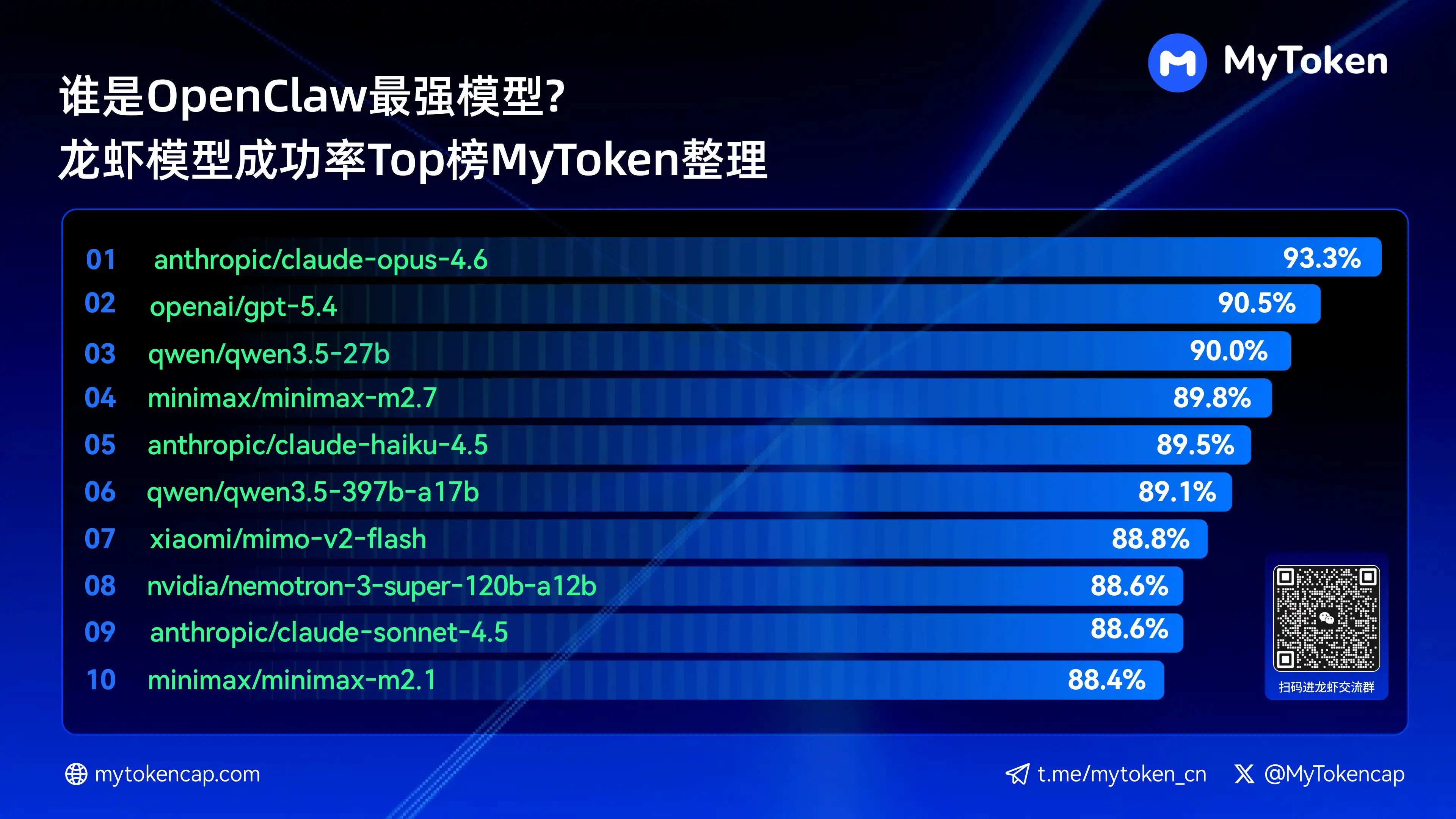
Claude Opus 4.6 currently leads with the highest success rate of 93.3%, but Arcee's Trinity shows impressive performance in average stability. The Qwen series also has multiple entries in the top ten, demonstrating strong cost-performance potential. Success rate is the basic threshold; subsequent dimensions of speed and cost will further impact the actual experience.
This set of 23 task benchmarks is fully transparent. We strongly encourage everyone to conduct practical tests结合 (combining with) their own scenarios. For rankings of more other models, please look forward to the agent leaderboard feature即将 (soon to be) launched by MyToken.
(Data sourced from PinchBench's publicly available OpenClaw agent benchmark tests, continuously updated.)





