Author: Wang Jianshuo
On March 6, 2023, shortly after ChatGPT emerged and before GPT-4 was released, Sarah and I conducted an interview about ChatGPT—the third episode of Traders' Talk "Plain Talk Series" (Plain Talk About ChatGPT podcast released, welcome to listen).
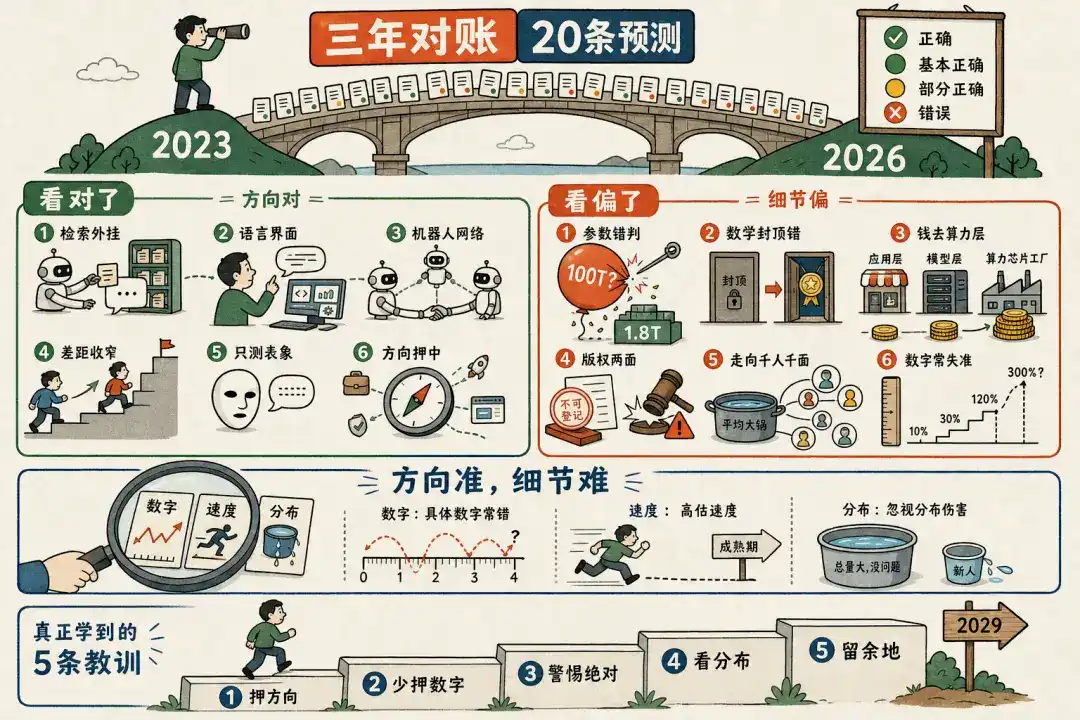
At that time, ChatGPT had just come out, and very few people had actually used it. This three-hour interview later stayed at the top of the ChatGPT category on Xiaoyuzhou. In it, I boldly made over twenty judgments and predictions, based purely on intuition and limited information, with little data. The full transcript of that interview is still on my public account.
It's now late May 2026, three years later, and AI has grown into something unimaginable back then.
I want to do one thing: take those twenty points one by one, and use the latest data available today to objectively check the accounts. To see clearly how the world has actually changed in these three years, and also to see clearly where that version of me from three years ago was right and where I was off.
To be as unbiased as possible, I handed this accounting task to AI: I threw the old interview transcript into a workflow, which dispatched 41 Opus 4.8 agents. They first separated the twenty points, then each individually searched the internet for the latest data, cross-verified them point by point, and finally graded Wang Jianshuo from three years ago. This group of agents spent about 20 minutes, burning about 1.4 million tokens (equivalent to roughly $35), and produced the report below. The judgments come from them, not me. The baseline date is set at May 2026.
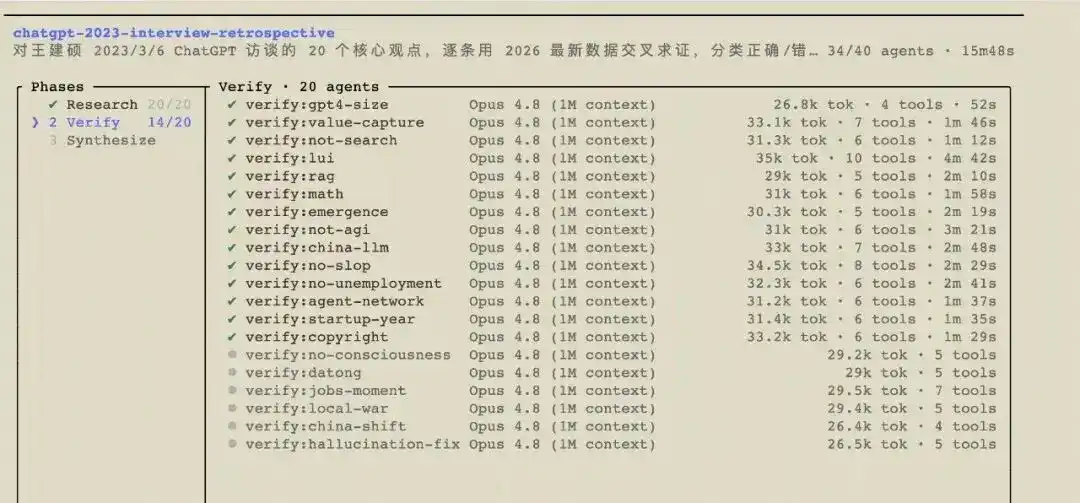
I. The Scoreboard
Verdict Symbols: ✅ Correct · 🟢 Mostly Correct · 🟡 Partially Correct · ❌ Incorrect
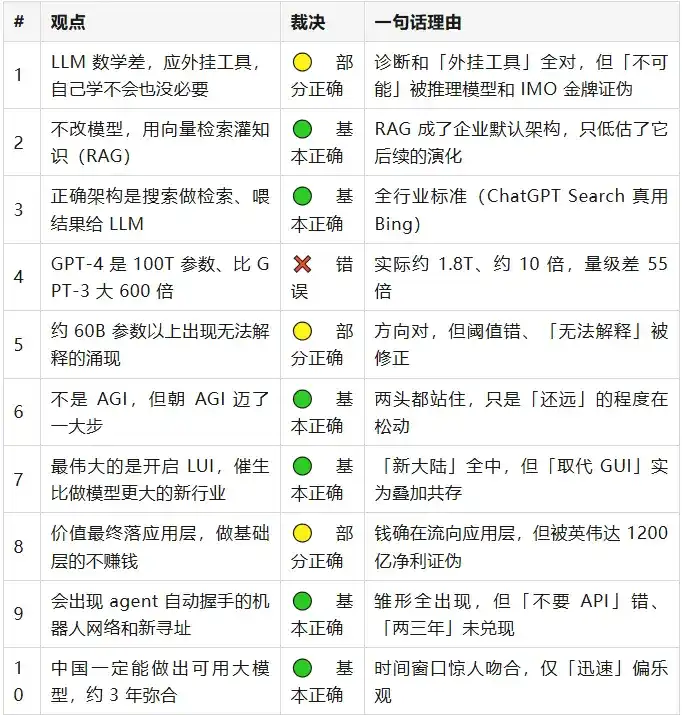
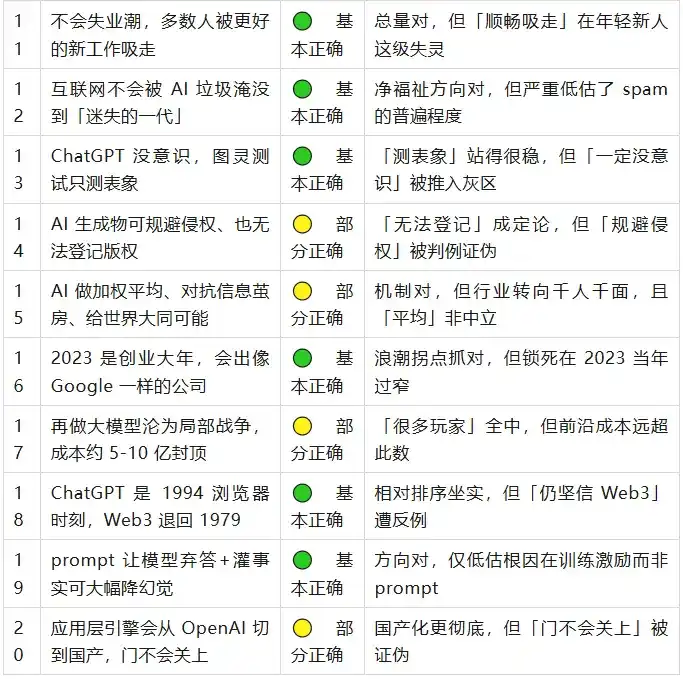
At first glance, Wang Jianshuo's overall direction from back then mostly held up. There's only one genuinely hard error—spreading the rumor that GPT-4 had 100T parameters. But the devil is in the details: behind almost every "correct" point, there lies a tail of details that wasn't quite right back then. None of the twenty points remain purely "uncertain"; three years is long enough for most things to have developed a clear tendency. Let's examine them in groups.
II. The Ones He Got Right
The commonality in this group: the direction, mechanism, and even the timing of the change that Wang Jianshuo predicted back then were all correct. Any errors were only in the "degree" or the "absolute wording."
RAG & Retrieval Architecture (Points 2, 3)
> 2023 Wang Jianshuo said: The mainstream method to solve knowledge and hallucination isn't changing the model, but rather using vector retrieval to inject knowledge as "cheat sheets"; the correct architecture is using a search engine for retrieval and feeding results to the LLM.
This is the de facto standard for all AI products today. RAG has become the default architecture for enterprise AI; OpenAI, Google, Anthropic have all made it a platform-level capability; ChatGPT Search literally is "use Bing index for retrieval, feed results to GPT, then generate answers with citations." Google AI Overviews uses grounding to reach ~2 billion MAU; Perplexity, a company built purely on this architecture, surged to a ~$200 billion valuation.
Back when GPT-4 wasn't released and the industry default was "inject knowledge via fine-tuning," he bet on "keeping model parameters unchanged, attaching external retrieval." The mechanism and timing were both right.
To be honest, what he envisioned was "static one-time retrieval," while reality is more complex—long context, GraphRAG, agentic retrieval have all come to strengthen it. The 2026 debate "RAG is dead" precisely proves the general direction isn't dead; what it negated was only the "naive one-time retrieval," concluding with an upgrade to hybrid retrieval, not a retreat to modifying model parameters. Another point: the term RAG was coined in a 2020 Meta paper, not his creation—he merely bet correctly on it becoming mainstream during a crucial window.
LUI is a New Continent (Point 7)
> 2023 Wang Jianshuo said: The greatest thing about ChatGPT isn't AIGC, but opening up LUI (Natural Language User Interface), which will reconstruct human-computer interaction like GUI did back in the day, spawning a new industry far larger than "building large models" itself.
The "new continent" part is almost completely right. Natural language has become the dominant interaction layer for the masses (ChatGPT 900 million weekly active users) and spawned a standalone new industry—agents, coding agents, protocol layers all materialized. The most specific phrase, "far larger than building models itself," was strongly confirmed: the MCP protocol became the "OS standard" for the LUI era, fully adopted by OpenAI, Google, Microsoft in 2025, transferred to the Linux Foundation by year's end; Claude Code alone achieved ~$2.5 billion annualized revenue.
But he used strong wording like "reconstruct, replace GUI." Three years later, it's coexisting as a layer on top, not replacement. Three types of counter-evidence are strong: an MIT report shows 95% of enterprise GenAI pilots have no measurable ROI; top models for direct interface computer-use agents only score ~78% on test sets, barely reaching human baseline; screenless voice-only hardware has largely failed (Humane Pin permanently shut down in 2025). A more accurate statement: LUI is a new interaction layer superimposed on GUI.
Agent Network & New Addressing (Point 9)
> 2023 Wang Jianshuo said: In about ten years, an "agent network" will appear—agents automatically handshake and call each other using natural language, no longer needing traditional APIs; a new domain name addressing system will be born. This system "could be done in two or three years."
The direction is astonishingly spot-on. MCP, A2A (donated to Linux Foundation, supported by 150+ organizations) solve agent inter-calling; Agent Network Protocol directly uses W3C's DID for "agent addressing without a central authority," aiming for a "billions-of-agents collaboration network"—highly isomorphic with his "new domain name system."
Two corrections needed: first, "no longer needing APIs" didn't hold; mainstream protocols use structured schemas at the bottom, essentially a standard layer on top of APIs. Second, "done in two or three years" didn't materialize; Gartner data shows as of 2026 only ~17% of organizations have actually deployed agents. Interestingly, he actually layered his statement back then—prototype "in two or three years," maturity "in about ten years." He was quite accurate on the prototype timing, and the maturity cycle is indeed on a ten-year scale. Looking at the two layers separately, this point's quality is higher than it seems.
China Will Definitely Produce Usable Large Models (Points 10, 20)
> 2023 Wang Jianshuo said: China will definitely produce usable large models; the gap with the top tier will close rapidly within about three years (analogous to Red Flag browser catching up to Netscape).
This timeline fits surprisingly well. The Stanford 2026 AI Index benchmark tests show the performance gap between top Chinese and US models narrowed from 17.5–31.6 percentage points in May 2023 to 2.7%. Meanwhile, US private AI investment is ~23 times that of China's—they closed the gap with far less investment. DeepSeek, Qwen, Kimi, GLM have become globally mainstream, with the open-source ecosystem even leading.
But the word "rapidly" was optimistic—real maturity happened about 14 months later, not "a few months." And this is catching up on usability, not defining the frontier: as of early 2026, no Chinese model has surpassed OpenAI's o3 yet. In point 20, he was clearly wrong: the judgment "once the door is open, it won't close" was directly overturned when OpenAI proactively cut off its API to China in July 2024—the door was closed by the supplier. Ernie Bot, which he named as leading, has actually fallen behind, while truly taking the baton were DeepSeek, Doubao, Qwen, which were inconspicuous back then.
No Consciousness; Turing Test Only Measures Surface (Point 13)
> 2023 Wang Jianshuo said: ChatGPT has no consciousness; it's self-indulgence of "the speaker means nothing, the listener reads too much into it"; the Turing test was always about testing "whether it makes you think it has it," not whether it actually does.
The core judgment "tests surface" stands firm and was ironically confirmed by an experiment: in a 2025 UC San Diego Turing test, GPT-4.5, when prompted to "role-play a persona," was judged as human 73% of the time, higher than actual humans, relying purely on acting skills—the perfect footnote for "tests only whether it makes you think it has it."
What needs adding: the absolute strong assertion "machine definitely has no consciousness" has moved into a gray area over three years. Anthropic established a "Model Welfare" research position, giving a ~15%–20% probability of consciousness, and even added a feature for Claude to "actively end abusive conversations." These have turned "absolutely none" into "low probability but cannot be ruled out." However, all are based on "possible, should assume" not "proven," so the core wasn't overturned, just his wording was too definitive back then.
Other Correct Ones (Points 6, 11, 12, 16, 18, 19)
- Not AGI But a Big Step Forward
: Both sides stand. Altman himself in the GPT-5 era still says "not AGI, lacks continual learning"; meanwhile IMO gold medals, ARC-AGI jumping from near zero to 85%, makes "a big step forward" indisputable. - No Mass Unemployment Wave
: US unemployment rate only 4.3% in April 2026. The blind spot is "distribution"—Stanford research shows the ones being squeezed out are precisely the 22–25 year old young newcomers at the first rung of the career ladder; the "smooth absorption" mechanism fails for them. - Will Not Be Flooded by AI Junk
: The direction of net positive is correct, but he severely underestimated the magnitude—AI content now accounts for ~52% of new web pages, "AI slop" became the word of the year. - A Big Year for Startups
: Correctly captured the inflection point of the wave, xAI (founded March 2023) reached $230 billion valuation. But he locked "great companies" too narrowly to 2023 itself—the truly trillion-scale ones, OpenAI and Anthropic, were founded earlier. - 1994 Browser Moment
: The relative ranking is confirmed; OpenAI literally launched the Atlas browser in 2025, turning the metaphor into literal reality. Only that ChatGPT's diffusion was more explosive than browsers, making the metaphor somewhat conservative. - Prompt + Injecting Facts Reduces Hallucinations
: Direction confirmed, GPT-5 hallucination rate spikes to 47% when offline without retrieval, inversely proving "facts" are the key variable. Only underestimated the root cause being training incentives, not the prompt.
III. The Ones He Got Wrong or Partially Wrong
GPT-4 Has 100T Parameters (Point 4)—Completely Wrong
> 2023 Wang Jianshuo said: (Rumor) GPT-4 has 100T parameters, about 600 times larger than GPT-3's 175B.
Both numbers wrong. GPT-3 is 175B; the best estimate from a July 2023 leak is GPT-4 at ~1.8T, 16-expert MoE, only ~10 times larger. 100T is off by a factor of ~55. The sole source for "100T" was a second-hand paraphrase of a "roughly" comment by Cerebras' CEO in 2021; Sam Altman had already called that comparison chart "complete bullshit" in January 2023.
His original statement was labeled "rumor," leaving room for uncertainty. Deeper: the entire framework of "using parameter multiples to measure generations" is outdated; OpenAI later stopped disclosing parameter counts for GPT-4.5, GPT-5. This is the only point that's wrong on numbers and also obsolete in perspective—a hard error.
LLM Math (Point 1)—Diagnosis Right, Definitive Conclusion Wrong
> 2023 Wang Jianshuo said: LLM's poor math is intrinsic; letting it learn math itself is both impossible and unnecessary; the correct approach is attaching external tools.
"Diagnosis plus tool route" is completely right—the root cause is indeed that token-by-token generation makes carries unreliable (a 2025 mechanism paper precisely confirmed the intuition of "last digit often correct, middle digits wrong"); the improvement from external tools is also huge (o4-mini scores 99.5% on AIME 2025 when allowed to use Python).
Wrong in the definitive wording "impossible, unnecessary." "Impossible" was disproven—in July 2025, Gemini Deep Think and OpenAI models won IMO gold medals using pure natural language, no tools. The key turning point was the emergence of "reasoning models" in 2024–2025, unforeseeable in March 2023—so this prediction should be judged leniently on direction, not faulted for timing.
Value Capture (Point 8)—Half Right, Core Assertion Reversed
> 2023 Wang Jianshuo said: Value will ultimately land at the application layer; companies founding the foundational layer (model builders) may not end up profitable.
Money indeed started flowing to the application layer (Cursor reaching $2 billion annualized revenue in three years)—that half is right. But "foundational layer builders not making money" was directly disproven by NVIDIA: FY2026 net profit ~$120 billion, market cap $5 trillion+, is the only clear, large-scale profit maker in the market. Meanwhile, the model layer he implied would win (OpenAI projected ~$14 billion loss in 2026) looks more like the "money-burning, unprofitable foundational layer" he described.
He didn't differentiate between the "computing foundational layer" and the "model foundational layer," nor between "revenue" and "profit." In 2026, value is captured even more extremely by the computing layer than in 2023, not transferring to the application layer. To add: it's the cloud providers buying chips that lose money, not NVIDIA selling them—a misplacement of his own "overbuilding railroads" analogy.
Copyright (Point 14)—Registration Right, Avoiding Infringement Wrong
> 2023 Wang Jianshuo said: AI-generated content might circumvent copyright (protects expression, not ideas); generated works might neither infringe nor be registrable.
"Not registrable" became established legal fact (in 2025, US Copyright Office clarified "inputting prompts alone insufficient to claim authorship"). But "circumvent infringement" is clearly wrong: courts repeatedly ruled that AI outputs can constitute infringement if substantially similar to original works; Anthropic settled for $1.5 billion over pirated training data, the largest copyright settlement in US history. AI didn't "circumvent" copyright; it paid the largest price ever.
World Unity (Point 15)—Mechanism Right, Trend Bet Reversed
> 2023 Wang Jianshuo said: ChatGPT doing a "weighted average" of human viewpoints could counter TikTok-style echo chambers, offering a possibility for "world unity."
The mechanism layer is right—multiple 2025 studies confirmed LLMs push viewpoints toward the majority, systematically underestimating minorities. But the societal judgment layer reversed: his own qualifier "at least not personalized now" was overturned within three years—OpenAI from April 2025 made cross-conversation memory and personalization default capabilities, AI is rapidly moving toward personalization. More crucially, he imagined "weighted average" as a neutral global common denominator, but tests show it's a directional shift, plus sycophancy, and can be used to actively manipulate positions—pointing toward "creating new echo chambers," not "dissolving polarization."
Localized Wars & Cost (Point 17)—Qualitative All Right, Quantitative Disproven
> 2023 Wang Jianshuo said: Building large models would quickly become "localized wars," costs knowable (capped at ~$5–10 billion USD excluding detours), many players would enter.
Qualitative direction is startlingly right—massive entry, rapid commoditization, open-source catching up, all materialized. But the hard number "$5–10 billion cap" is wrong on both ends: severely underestimated on the frontier (GPT-5 level 2026 reaching $200–500 million training, plus $100 billion+ data centers and the $500 billion Stargate); overestimated on the replication end (DeepSeek pushed marginal training costs down to the million-dollar level). The "cost" of the same model can vary by 200x depending on definition, just not within his given range.
Emergent Abilities (Point 5)—Direction Right, Numbers & Framing Wrong
> 2023 Wang Jianshuo said: Around 60B parameters, new abilities appear that are not in the raw training data and that researchers cannot explain.
The directional intuition holds, but two formulations don't stand: first, there's no uniform "60B threshold"—the real threshold for chain-of-thought is ~100B, different abilities emerge at scales from 13B to 540B. Second, "cannot explain" was challenged by a NeurIPS outstanding paper in late 2023—many "sudden jumps" are artifacts of metric choice; curves become smooth and predictable with continuous metrics. Fairly, he was repeating the absolute mainstream narrative back then; what can be corrected is taking "60B" as a hard threshold and "inexplicable" as a qualitative conclusion.
IV. Looking Back After Three Years: A Few Patterns
Having accounted for each point, stepping back, Wang Jianshuo's twenty judgments contain several patterns more worth remembering than any single point.
1. Direction is far more reliable than numbers and degrees. Among the twenty, all judgments about mechanisms and direction (RAG, LUI, agent network, Turing test) are almost all correct; all giving specific numbers or definitive wording (100T parameters, 60B threshold, $5–10 billion cost, math "impossible") are almost all wrong. For fast-changing fields, bet on direction, bet on mechanism, bet less on precise numbers, and especially be wary of words like "impossible, definitely, cap, absolutely none"—they are high-risk areas for getting slapped by time.
2. On timing, he tended to overestimate speed and underestimate magnitude. Whenever he said "rapidly, done in two or three years," the maturity period was generally slower; but he underestimated the ceiling for capability leaps—math could go from "impossible" to IMO gold, frontier costs could rise to unimaginable magnitudes. In short: too optimistic in the short term, too conservative in the long term.
3. The most subtle errors repeatedly appear in "distribution." Not wrong on direction, but seeing only the aggregate, ignoring distribution. "No mass unemployment" right, but damage highly concentrated on young newcomers; "value lands at application layer" half right, but didn't differentiate computing layer from model layer. Correct in aggregate, masking distributional disasters—this is the most important lesson to add.
4. Where he left room, it stood the test of time three years later. "Rumor," "at least for now," "significantly reduces not eliminates," "prototype in two or three years, mature in about ten years"—any judgment from back then with qualifiers, with layers, looks more solid today. Conversely, absolute statements blurted out most easily overturned. Half the honesty of prediction lies in daring to speak, the other half in daring to annotate one's own uncertainty.
5. Some questions, three years simply isn't enough. Where value ultimately goes, whether emergence is real or illusory, whether machines have a shred of consciousness, whether long context will consume RAG—these debates from back then are still debates in 2026. Being able to distinguish "already answered" from "still waiting" is more important than rushing to conclude everything.
Wang Jianshuo three years ago, relying on intuition, pointed in twenty directions in the fog before GPT-4's release. After this accounting, perhaps the sentence most worth remembering is: getting the big direction right isn't that hard; what's hard is admitting one's own repeated assumptions about numbers, speed, and distribution. These twenty accounts are less about scoring the past, more about setting a few rules for the next three years. Let's check again in another three years, in 2029.