In the telegraph era where charges were per word, ink and paper were money. People were accustomed to condensing thousands of words to the extreme; "Return quickly" was worth more than a long letter, and "All is well" carried the heaviest嘱咐.
Later, telephones entered homes, but long-distance calls were charged by the minute. Parents' long-distance calls were always concise, hanging up promptly after the main point was made. Once the conversation started to extend slightly, the thought of the phone bill would cut short any budding small talk.
Then, broadband came home, and internet access was charged by the hour. People stared at the timer on the screen, opening and closing web pages instantly, only daring to download videos—streaming was a奢侈 verb back then. At the end of every download progress bar lay people's渴望 for "connecting to the world" and their忌惮 of "insufficient balance."
The unit of billing changed again and again, but the instinct to save money remained eternal.
Today, the Token has become the currency of the AI era. However, most people have yet to learn how to be thrifty in this age because we haven't learned how to calculate gains and losses within the invisible algorithms.
When ChatGPT first emerged in 2022, almost no one cared what a Token was. It was the era of AI's "communal pot," where you paid $20 a month and could chat as much as you wanted.
But ever since AI Agents recently became popular, Token expenditure has become something every AI Agent user must pay attention to.
Unlike simple Q&A dialogues, behind a task flow are hundreds or thousands of API calls. An Agent's independent thinking comes at a cost; every self-correction, every tool call, corresponds to a跳动数字 on the bill. Then you'll find that the money you topped up suddenly isn't enough, and you don't even know what the Agent has been doing.
In real life, everyone knows how to save money. When buying groceries at the market, we know to remove the muddy, rotten leaves before weighing; when taking a taxi to the airport, experienced drivers know to avoid the elevated highway during the morning rush hour.
The logic of saving money in the digital world is actually the same; it's just that the billing unit has changed from "jin" and "kilometers" to Tokens.
In the past, saving was due to scarcity; in the AI era, saving is for precision.
We hope that through this article, we can help you梳理出一套 money-saving methodology for the AI era, allowing you to spend every penny where it counts.
Before Weighing, Remove the Rotten Leaves
In the AI era, the value of information is no longer determined by its scope but by its purity.
AI's billing logic charges based on the number of words it reads. Whether you feed it profound insights or meaningless formatting nonsense, as long as it reads it, you have to pay.
Therefore, the first mindset for saving Tokens is to刻进潜意识 the "signal-to-noise ratio."
Every word, every image, every line of code you feed to AI costs money. So before handing anything over to AI, remember to ask yourself: How much of this does AI actually need? How much of it is muddy, rotten leaves?
For example,冗长的开场白 like "Hello, please help me...", repeated background introductions, and code comments that weren't cleaned up properly are all muddy, rotten leaves.
Beyond that, the most common waste is throwing a PDF or webpage screenshot directly to AI. This确实 saves you effort, but "saving effort" in the AI era often means "expensive."
A fully formatted PDF contains, besides the main text, headers, footers, chart labels, hidden watermarks, and a large amount of formatting code for typesetting. These things are utterly useless for AI to understand your question, but they are all billed.
Next time, remember to convert the PDF into clean Markdown text before feeding it to AI. When you turn a 10MB PDF into a 10KB clean text, you not only save 99% of the money but also make AI's brain run much faster than before.
Images are another gold sink.
In the logic of visual models, AI doesn't care how beautifully your photo is taken; it only cares how many pixels you occupy.
Taking Claude's official calculation logic as an example: Image Token consumption = width in pixels × height in pixels ÷ 750.
A 1000×1000 pixel image consumes about 1334 Tokens. Calculated at Claude Sonnet 4.6's pricing, that's about $0.004 per image.
But if you compress the same image to 200×200 pixels, it only consumes 54 Tokens, costing $0.00016, a full 25 times cheaper.
Many people throw high-definition photos taken with their phones or 4K screenshots directly to AI, unaware that the Tokens consumed by these images could be enough for AI to read most of a novella. If the task is merely to recognize text in an image or make a simple visual judgment, like asking AI to识别发票上的金额, read text in an instruction manual, or judge if there is a traffic light in the picture, then 4K resolution is pure waste. Compressing the image to the minimum usable resolution is sufficient.
But the biggest reason for wasted Tokens on the input side isn't actually file format, but inefficient ways of speaking.
Many people treat AI like a real-life neighbor,习惯用 social-style碎碎念 to communicate, first tossing out a "Help me write a webpage," waiting for AI to spit out a半成品, then补充细节, and反复拉扯. This挤牙膏式的 dialogue forces AI to generate content repeatedly, with each round of modification叠加 Token consumption.
Engineers at Tencent Cloud found in practice that for the same requirement,挤牙膏式的 multi-turn dialogue最终消耗的 Tokens are often 3 to 5 times that of stating things clearly once.
The true way to save money is to abandon this inefficient social probing and state the requirements, boundary conditions, and reference examples clearly all at once. Spend less effort explaining "what not to do," because negative sentences often consume more comprehension cost than affirmative ones; directly tell it "how to do it" and provide a clear, correct example.
同时, if you know the target, tell AI directly; don't make AI play detective.
When you command AI to "find the user-related code," it must perform large-scale scanning, analysis, and guessing in the background; whereas when you directly tell it "go look at the src/services/user.ts file," the Token consumption is worlds apart. In the digital world, information parity is the greatest saving.
Don't Pay for AI's "Politeness"
There's an潜规则 in large model billing that many people aren't aware of: Output Tokens are typically 3 to 5 times more expensive than Input Tokens.
That is to say, what AI says is much more expensive than what you say to it. Taking Claude Sonnet 4.6's pricing as an example, input costs only $3 per million Tokens, while output jumps sharply to $15 per million Tokens—a full 5 times difference.
Those polite opening remarks like "Okay, I have fully understood your需求, now I will begin to answer for you......" and those客套结尾 like "I hope the above content is helpful to you" are polite social pleasantries in human communication, but on the API bill, these寒暄 with no informational value also cost you your own money.
The most effective way to solve waste on the output side is to set rules for AI. Use system instructions to clearly tell it: No small talk, no explanations, no restating the requirements, just give the answer directly.
These rules only need to be set once and take effect in every subsequent conversation, truly a "one-time investment, permanent benefit" financial management手段. But when establishing rules, many people fall into another trap: using冗长的 natural language to pile up instructions.
Engineers'实测数据 show that the effectiveness of instructions lies not in word count but in density. Compressing a 500-word system prompt to 180 words, by deleting meaningless polite phrases, merging重复指令, and restructuring paragraphs into concise bulleted lists, the output quality remains almost unchanged, but the Token consumption per call can plummet by 64%.
There's an even more proactive control method: limiting the output length. Many people never set an output上限, letting AI run free. This放任 of expression rights often leads to extreme cost失控. You might only need a short sentence that makes the point, but AI, to demonstrate some kind of "intellectual sincerity," unceremoniously generates an 800-word essay for you.
If what you追求 is pure data, you should force AI to return structured formats, not冗长的 natural language descriptions. Carrying the same amount of information, the Token consumption of JSON format is far lower than that of散文-style paragraphs. This is because structured data剔除 all redundant connecting words, modal particles, and explanatory modifiers, retaining only the high-concentration logical core. In the AI era, you should be清醒ly aware that what is worth paying for is the value of the result, not AI's meaningless self-explanation.
Beyond that, AI's "overthinking" is also疯狂蚕食 your account balance.
Some advanced models have an "extended thinking" mode, which performs massive internal reasoning before answering. This reasoning process is also billed, and at the output price, which is very expensive.
This mode is essentially designed for "complex tasks requiring deep logical support." But most people also choose this mode when asking simple questions. For tasks that don't require deep reasoning, explicitly telling AI "no need to explain the思路, just give the answer directly," or manually turning off extended thinking, can also save you a lot of money.
Don't Let AI Dig Up Old History
Large models have no real memory; they are just疯狂地翻旧账.
This is an underlying mechanism many people don't know about. Every time you send a new message in a chat window, AI doesn't start understanding from your new sentence; it re-reads ALL the previous content you've chatted about, including every round of dialogue, every piece of code, every referenced document, and *then* answers you.
In the Token bill, this "reviewing the old to know the new" is by no means free. As dialogue rounds accumulate, even if you are just asking for a simple word, the cost of AI re-reading the entire old history behind the scenes grows exponentially. This mechanism dictates that the heavier the conversation history, the more expensive your every question becomes.
Someone tracked 496 real conversations containing more than 20 messages and found that the 1st message平均读取 14,000 Tokens, costing about 3.6 cents each; by the 50th message, it平均读取 79,000 Tokens, costing about 4.5 cents each—a full 80% more expensive. And the context gets longer and longer; by the 50th message, the context AI has to reprocess is already 5.6 times that of the 1st message.
The simplest habit to solve this problem is: One task, one chat window.
When a topic is finished,果断开启 a new conversation. Don't treat AI like a聊天窗口 that is never turned off. This habit sounds simple, but many people just can't do it, always thinking "what if I need the previous content later." In fact, the "what if" you worry about绝大多数时候 will not happen, and for this "what if," you are already paying several times more for every new message.
When the dialogue确实需要延续 but the context has become very long, we can use some tools' compression functions. Claude Code has a /compact command that can condense long-winded conversation history into a brief summary, helping you do a cyber断舍离.
There's also a省钱 logic called Prompt Caching. If you repeatedly use the same system prompt, or need to reference the same document in every conversation, AI will cache this content. The next time it's called, it will only charge a small cache read fee, not the full price every time.
Anthropic's official pricing shows that the Token price for a cache hit is 1/10 of the normal price. OpenAI's Prompt Caching can similarly reduce input costs by about 50%. A paper published on arXiv in January 2026 tested long tasks on multiple AI platforms and found that prompt caching could reduce API costs by 45% to 80%.
That is to say, for the same content, the first time you feed it to AI you pay full price; every subsequent call, you only pay 1/10. For users who need to use the same set of规范文档 or system prompts every day, this feature can save a huge number of Tokens.
But Prompt Caching has one prerequisite: your system prompt and reference document content and order must remain consistent, and it must be placed at the very beginning of the conversation. Once the content is changed in any way, the cache becomes invalid, and it's billed at full price again. So, if you have a fixed set of work规范, write it down and don't modify it随意ly.
The last技巧 for context management is loading on demand. Many people like to stuff all their规范, documents, and precautions into the system prompt at once, again for that "just in case" reason.
But the cost of doing this is that you are明明 only doing a very simple task but are forced to load thousands of words of rules,白白浪费 a bunch of Tokens. Claude Code's official documentation recommends keeping CLAUDE.md under 200 lines, splitting专项规则 for different scenarios into independent skill files, and only loading the rules for the scenario you are using. Keeping the context absolutely pure is the highest form of respect for computing power.
Don't Drive a Porsche to Buy Groceries
Different AI models have vastly different prices.
Claude Opus 4.6 costs $5 per million Tokens input and $25 output, while Claude Haiku 3.5 costs only $0.8 input and $4 output—a difference of nearly 6 times. Using the top-tier model to do杂活 like gathering materials or formatting is not only slow but also very expensive.
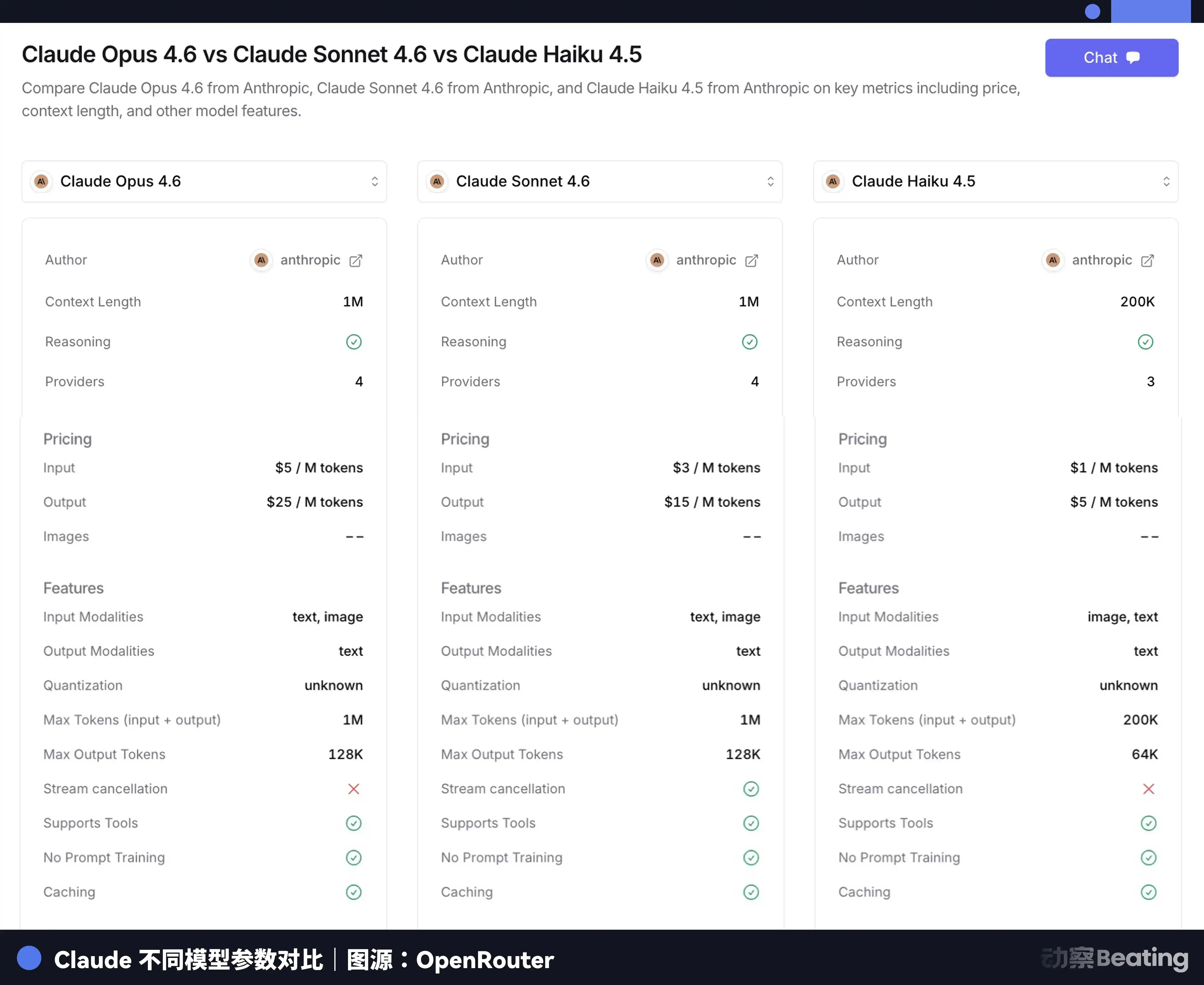
The smart way is to bring the common "class division of labor" thinking from our human society into AI society. Tasks of different difficulties are assigned to models of different price points.
Just like hiring people to work in the real world, you wouldn't specifically hire an expert with an annual salary of a million dollars to carry bricks at a construction site. It's the same with AI. Claude Code's official documentation also explicitly recommends: Use Sonnet for most programming tasks, reserve Opus for complex architectural decisions and multi-step reasoning, and assign simple subtasks specifically to Haiku.
A more specific practical solution is to构建 a "two-stage workflow." In the first stage, use free or cheap base models to do the early脏活累活, like data collection, format cleaning, draft generation, simple classification, and summarization. Entering the second stage, feed the refined high-purity essence to the top-tier model for core decision-making and deep polishing.
For example, if you need to analyze a 100-page industry report, you can first use Gemini Flash to extract the key data and conclusions from the report and organize them into a 10-page summary. Then, feed this summary to Claude Opus for in-depth analysis and judgment. This two-stage workflow can大幅压缩 costs while ensuring quality.
More advanced than simple分段处理 is deep division of labor based on task deconstruction. A complex engineering task can be completely broken down into several independent subtasks, each matched with the most suitable model.
For example, for a task requiring code writing, you can have a cheap model write the framework and boilerplate code first, and then only hand over the core logic part to an expensive model to implement. Each subtask has a clean, focused context, resulting in more accurate results and lower costs.
You Didn't Need to Spend Tokens in the First Place
All the previous discussions essentially solve the tactical problem of "how to save money," but a more fundamental logical proposition is overlooked by many: Does this action actually require spending Tokens?
The most extreme saving is not the optimization of algorithms but the断舍离 of decisions. We are accustomed to seeking万能解答 from AI, forgetting that in many scenarios, calling an expensive large model is无异于 using a cannon to kill a mosquito.
For example, letting AI automatically process emails, it will treat every email as an independent task to understand, classify, and reply to, consuming huge amounts of Tokens. But if you first spend 30 seconds glancing through the inbox, manually filtering out those emails that clearly don't require AI processing, and then hand the rest over to AI, the cost immediately drops to a small fraction of the original. Human judgment here is not an obstacle but the best filter.
People in the telegraph era knew how much money each additional word cost, so they would掂量—this was an intuitive perception of resources. It's the same in the AI era. When you truly know how much money it costs to make AI say one more sentence, you will naturally掂量 whether this thing is worth letting AI do, whether this task requires a top-tier model or a cheap one, and whether this piece of context is still useful.
This掂量 is the most money-saving ability. In an era where computing power is becoming increasingly expensive, the smartest usage is not to let AI replace humans, but to let AI and humans do what they are each good at. When this sensitivity to Tokens is internalized as a conditioned reflex, you truly change from being a附庸 of computing power back to being its master.






