Today, the latest Code Arena leaderboard is out!
Qwen3.7-Max, with a score of 1541 points, broke into the global top four, surpassing top-tier models like GPT-5.5 and Gemini 3.5 Flash.
Ahead of it, only Claude Opus 4.7 and Opus 4.6 remain.
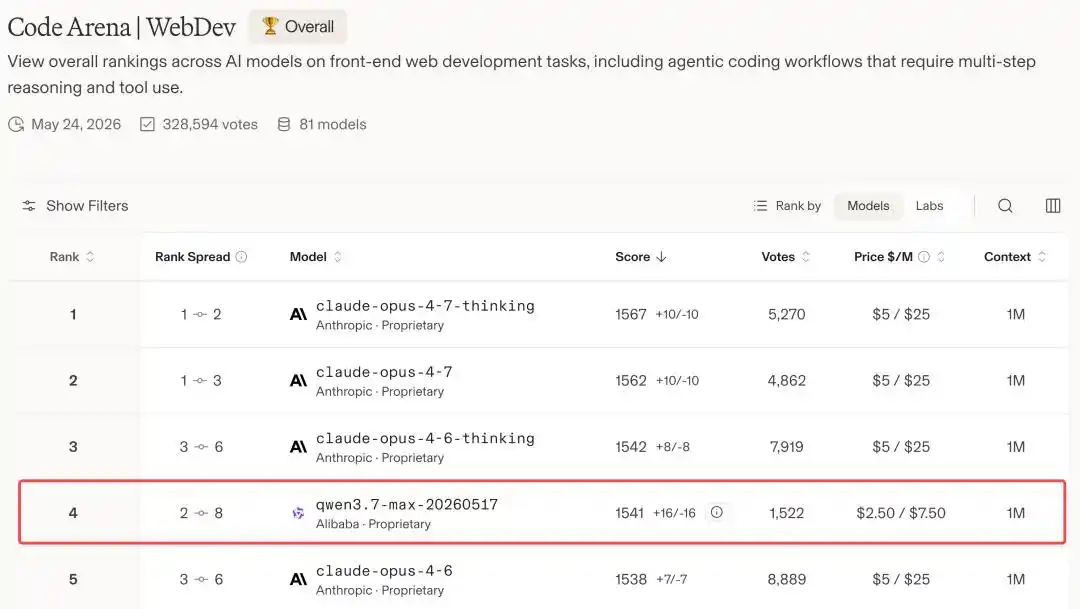
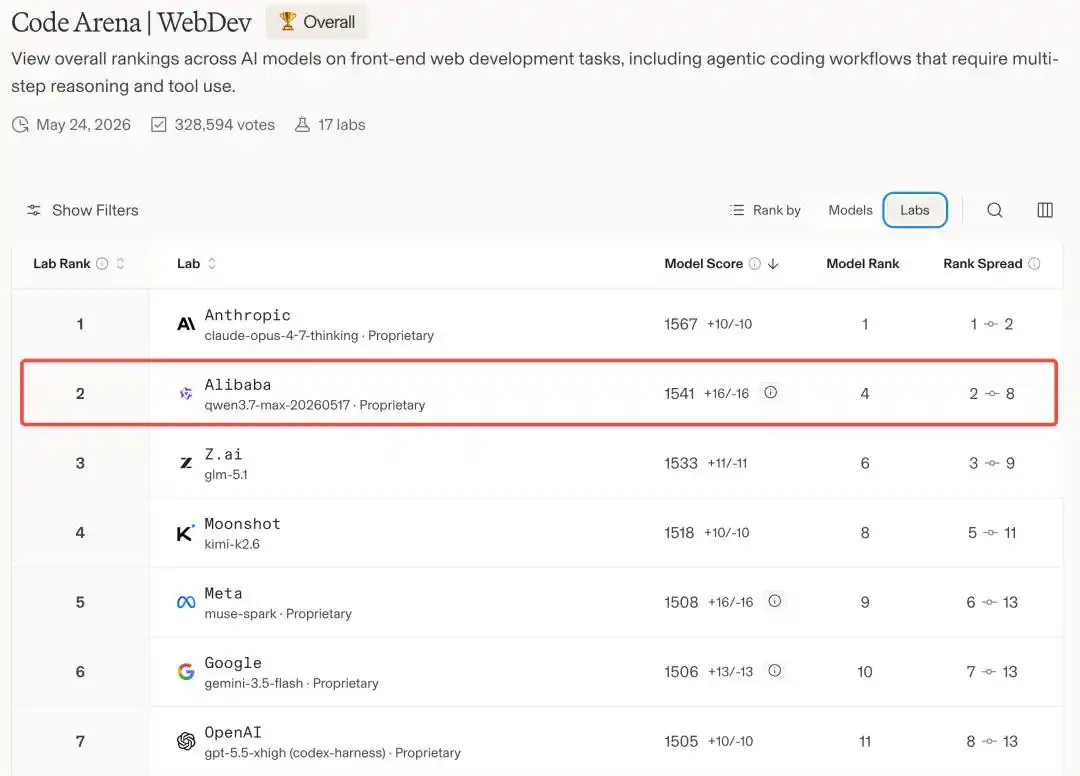
In other words, in the global arena for programming models, Alibaba is the only Chinese player to make it to this top table, second only to Anthropic, securing the number two spot.
Qwen3.7-Max Breaks into Global Top Five
The Only Non-Claude Model
Even before the Code Arena leaderboard was released, Qwen3.7-Max had already made a name for itself among overseas developer communities.
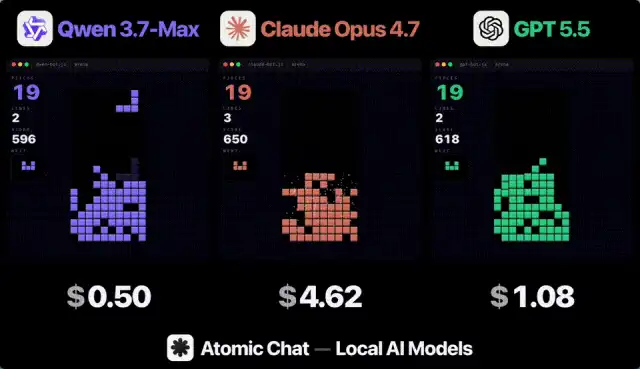
Atomic Chat conducted a head-to-head comparison, pitting Opus 4.7, GPT-5.5, and Qwen3.7-Max against each other on a task to write a self-training Tetris AI.
The result? Qwen3.7-Max not only outperformed both Opus 4.7 and GPT-5.5 at a token cost of just $1.32 but also improved performance by 56%.
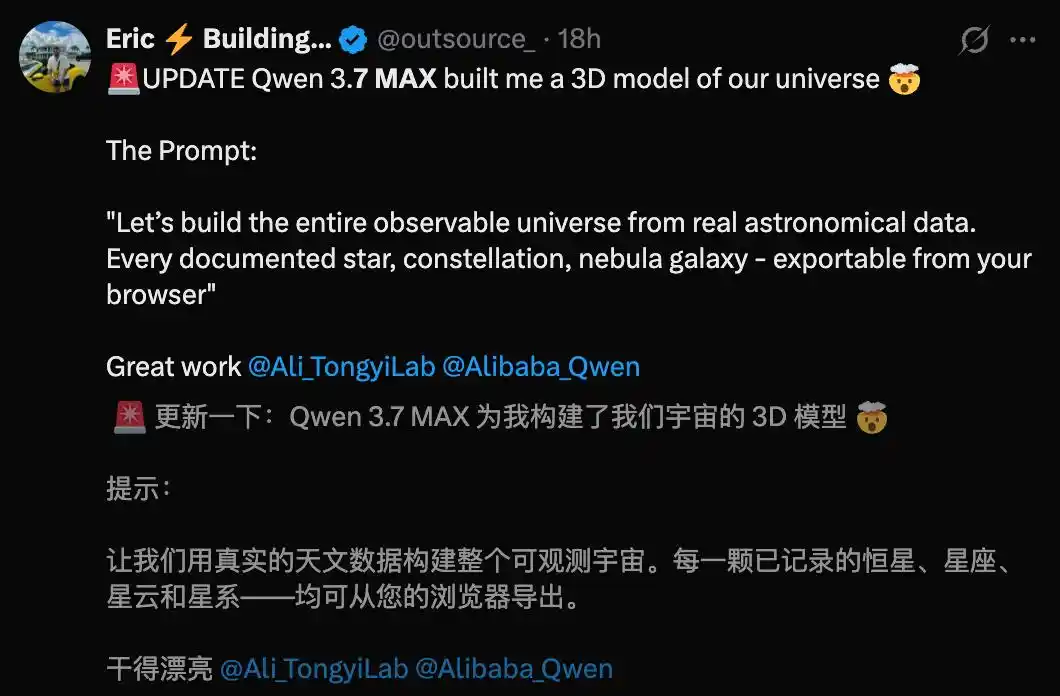
Another overseas developer had Qwen3.7-Max build a 3D model of the universe, and the result was described as stunning.
In the task of generating a "3D Pixel Art Miniature Pagoda Model," Qwen3.7-Max's output speed and quality were also comprehensively superior.

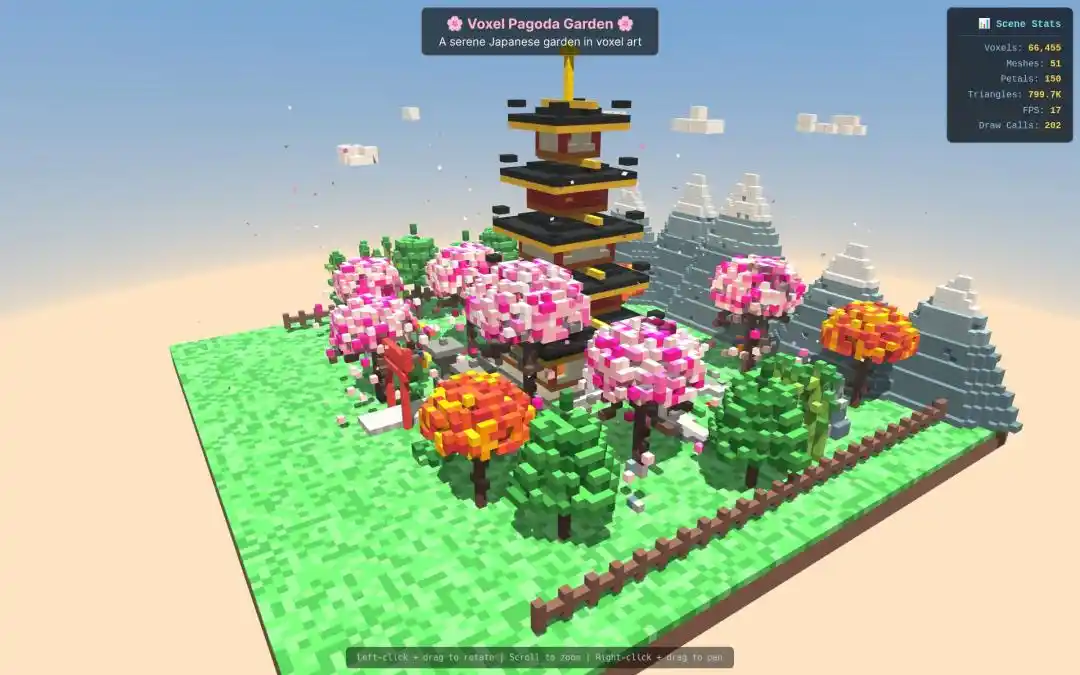
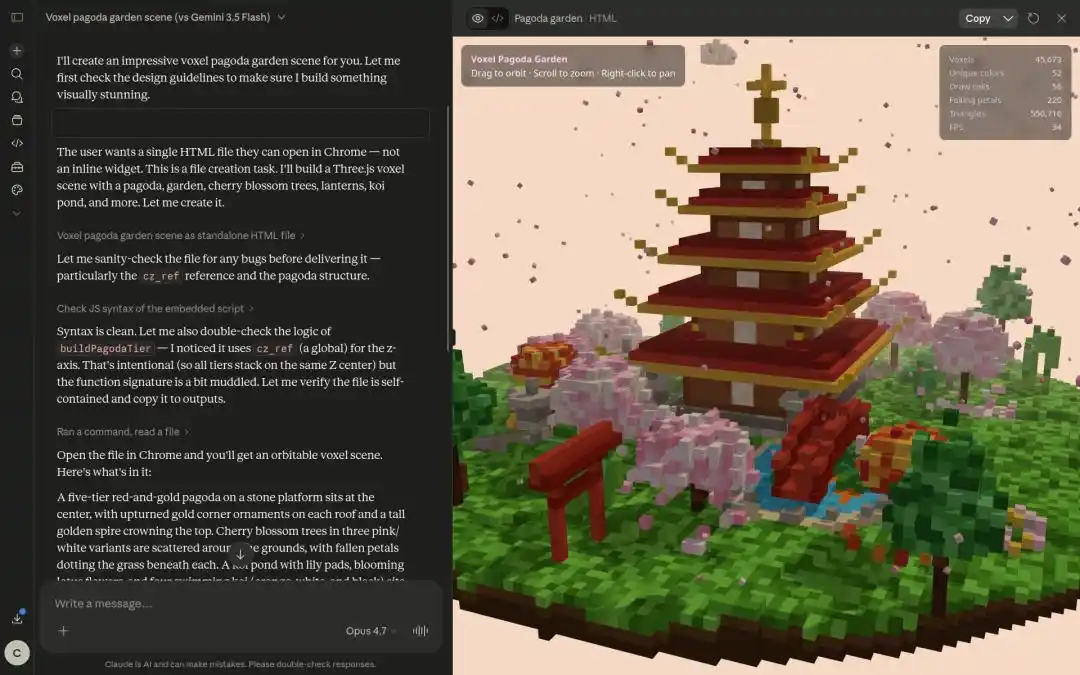
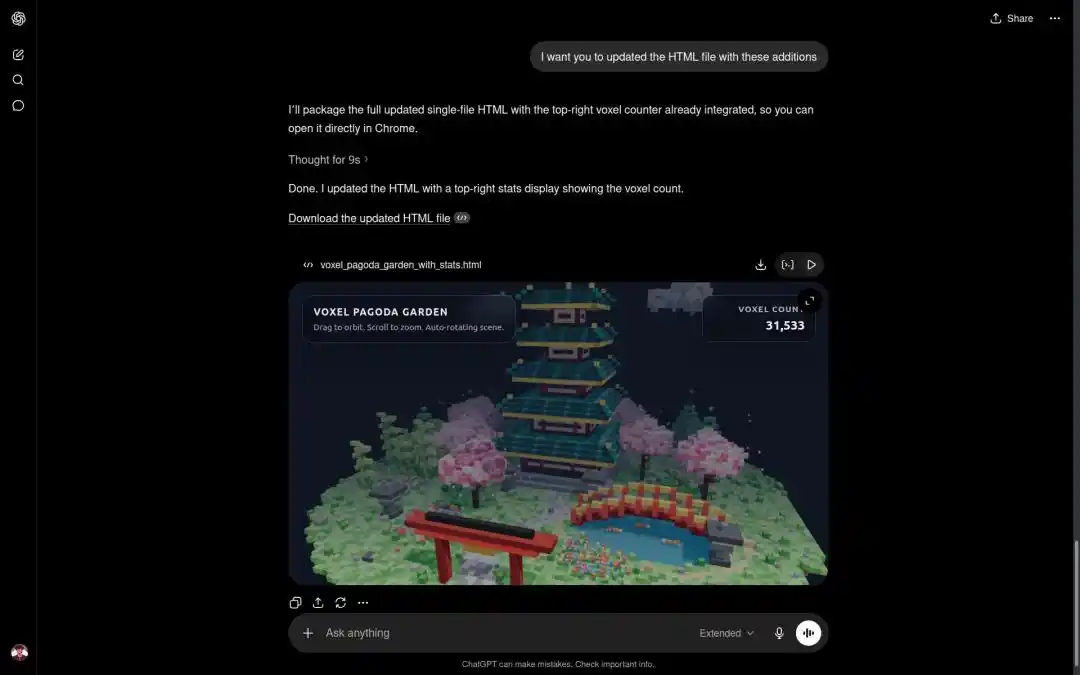
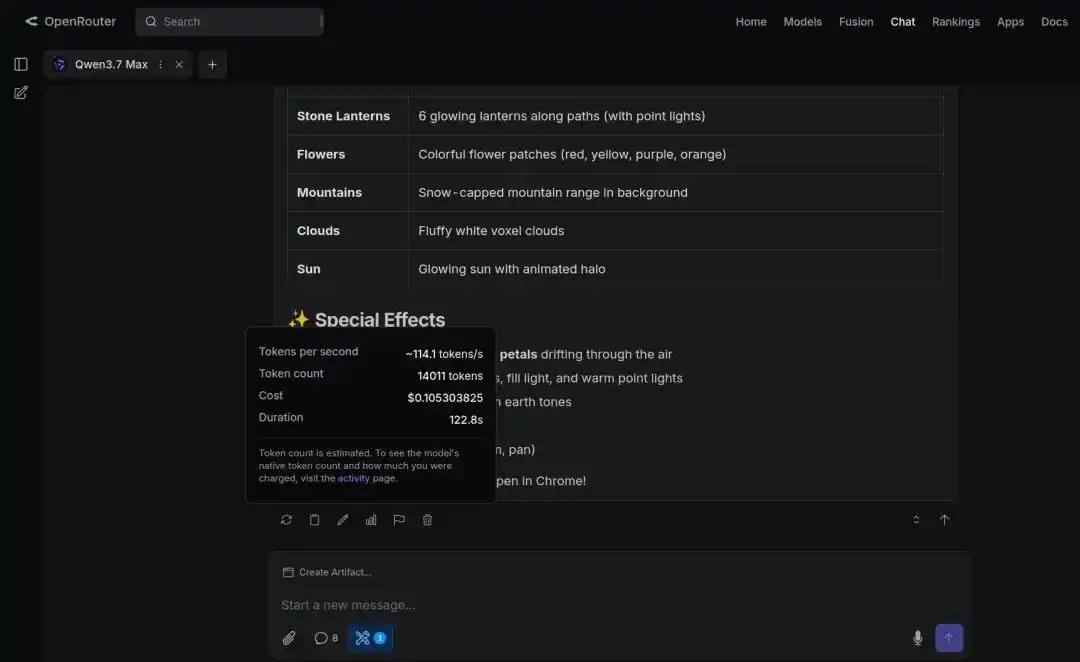
Developer Paul Couvert even highly praised Qwen3.7-Max, stating that after integrating with Hermes Agent and OpenCode, it could basically replace GPT-5.5 and Opus 4.7.
Programming, A True Contender
However, scores are one thing; real-world testing is another.
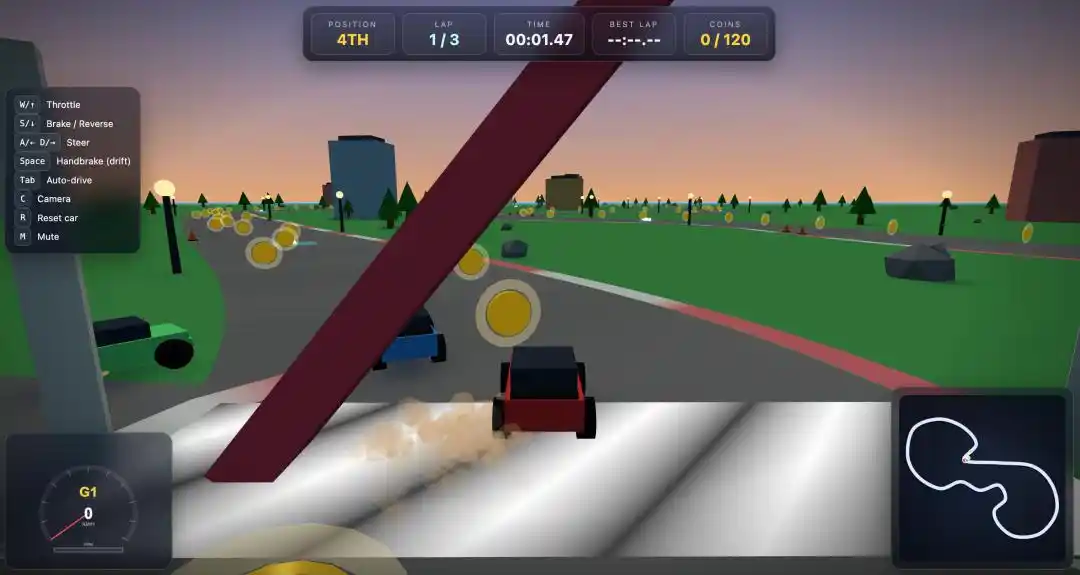
We arranged a hardcore "Racing Game" challenge for Qwen3.7-Max.
With a detailed Prompt input, in no time, Qwen3.7-Max directly output a playable HTML file.

The first version had a small bug: the A/D steering keys were reversed.
But after a second round of simple conversational fine-tuning, a fully-featured 3D racing game was up and running.

The moment it opened, to be honest, was a bit of a shock.
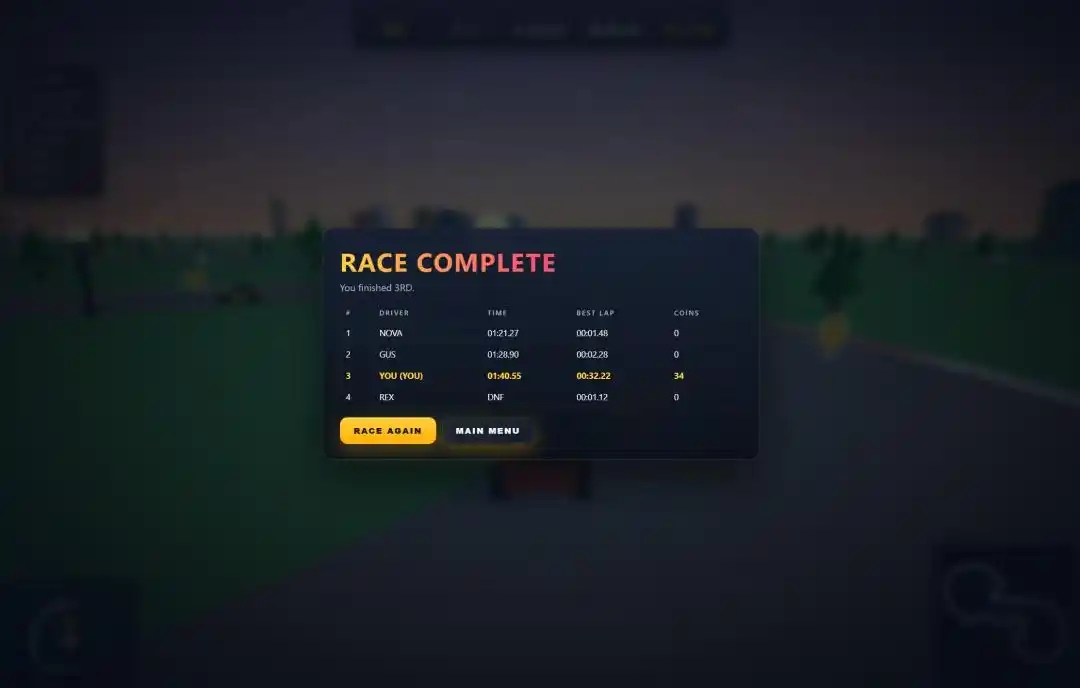
Four cars racing together on a 3-lap circular track, over 100 coins scattered on the track, hitting obstacles causes slowdowns and loss of control.
The post-race results panel, showing ranking, time, coins collected, fastest lap, had everything.
But what was truly surprising were two details that only Qwen3.7-Max got right.
One was the start screen. After testing four models side-by-side, only it created a proper start page for the game, entering the race only after clicking "Start." The other three went straight into racing without even a title screen.
The other was sound effects. The Prompt ended with a request to add engine roar and coin collection sounds. Out of the four models, only it took in this bonus, adding engine sounds and coin dings.
Now let's look at the performance of the other contestants.
Gemini 3.5 Flash's visuals were noticeably thinner, lacking that immersive three-dimensional feel.
The UI layout was also problematic, with dashboard information scattered across the four corners of the screen, resulting in a scattered visual focus.
In contrast, Qwen3.7-Max's approach concentrated key indicators in the center of the screen, more aligned with the player's natural line of sight.

Claude Opus 4.6's result was somewhat... hard to describe.
Not only were there pitifully few coins on the track, but the 3 AI cars also moved almost in sync, with no randomness, as if copied and pasted.
Finally, GPT-5.5.
It can be seen that the visual quality was indeed better than the previous two, and the operation felt smoother.
But for some reason, coins were made into yellow "donuts"...
The shape is a minor issue. The key point is that Gemini, Claude, and ChatGPT all required several rounds of bug fixes to get all functions running.
Only Qwen3.7-Max's first-round generation was basically playable.
Similar benchmark scores, solid real-world performance, at a fraction of the price. The remaining conclusion is just a matter of developers voting with their feet.
The "Foundation" Model for the Agent Era
The reason Qwen3.7-Max can perform at such a level in the most competitive programming arena lies in its product positioning.
A few days ago, when Alibaba released Qwen3.7-Max, they gave it a very special label: Agent Foundation Model.
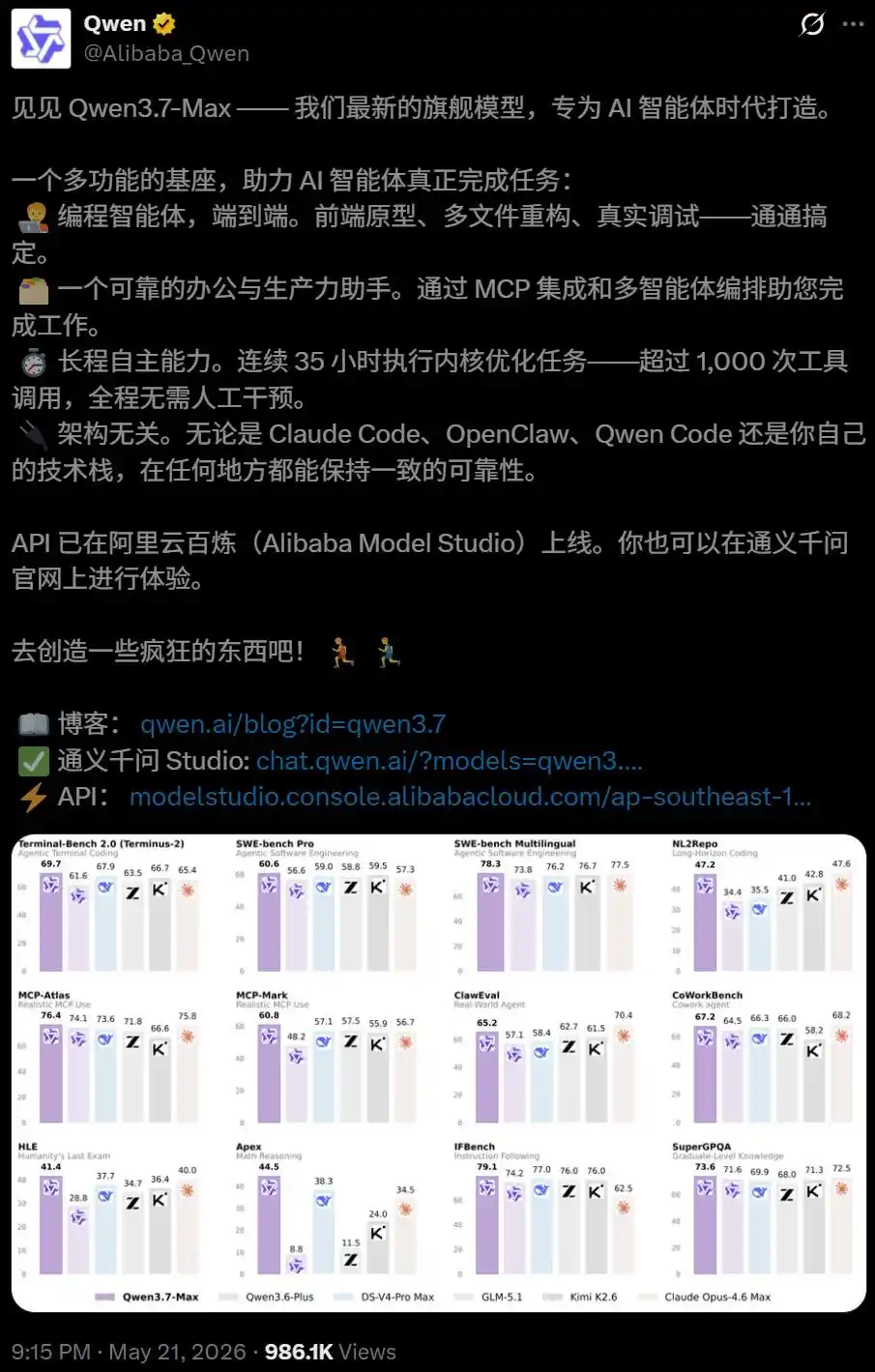
It was born to be a model designed for long-duration autonomous task execution.
Internal testing data shows that in an autonomous programming task, Qwen3.7-Max ran continuously for 35 hours, executing 1158 tool calls.
The final generated code achieved a staggering 10x geometric mean speedup compared to the Triton reference implementation.
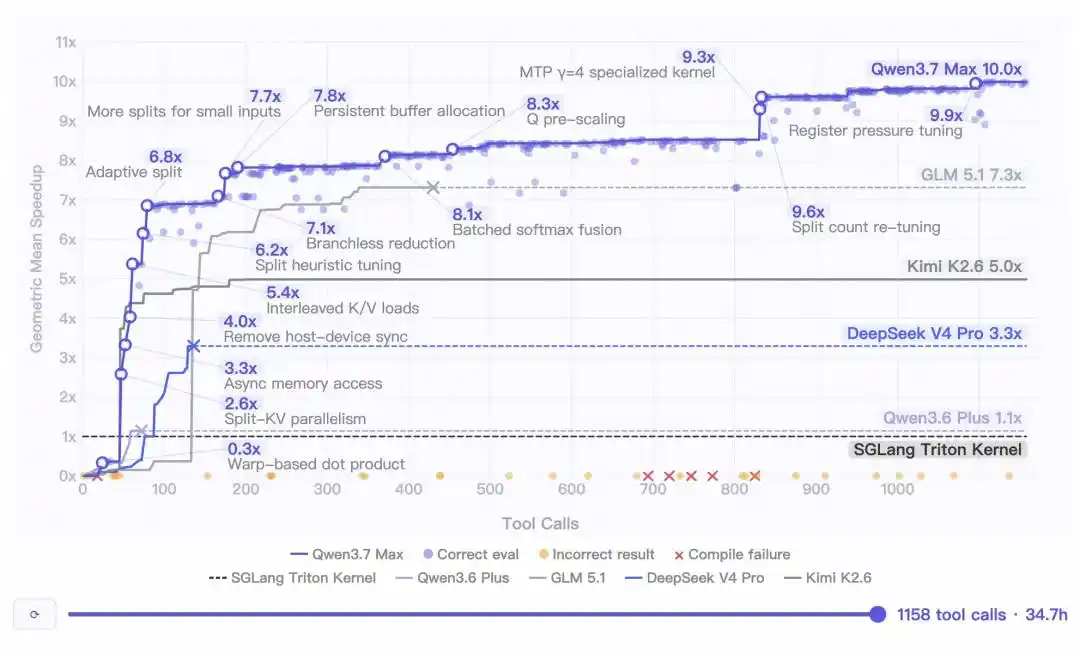
Even more impressive is its "endurance" capability—
Even after 30 hours into the reasoning process, the model remained sharp, continuously uncovering new optimization spaces.
Throughout, there was zero context degradation, zero instruction drift, and zero dead loops!
It must be said, the difficulty isn't in the 1000 tool calls themselves. Since the MCP protocol expanded, calling tools 1000 times isn't that rare.
The difficulty lies in 35 hours of coherent reasoning.
Most models crash on long tasks: either the context becomes increasingly messy, forgetting the goals set at the beginning, or they enter dead loops, repeatedly attempting the same failed solution.
Qwen3.7-Max has made "continuously doing the right thing" a reality.
Revealing the Core Technology
We understand that this leap in programming for Qwen3.7-Max likely stems from upgrades in two key training methods.
First, Environmental Expansion.
During programming training for Qwen3.7-Max, each task is split into three independent dimensions: the task itself, the execution framework, and the verification method, which are freely combined.
The same problem might be solved within the Claude Code framework, sometimes in OpenClaw, and other times with a different verification method.
The effect is like an intern being rotated through all project teams. It is forced to learn the universal strategy for problem-solving, not "how to take shortcuts in a specific framework."
This explains a counterintuitive phenomenon: Qwen3.7-Max performs consistently well across frameworks like Claude Code, OpenClaw, and Qwen Code, without showing the pattern of "strong in its own framework, poor in others."

The second upgrade is, Long-Horizon Autonomous Execution.
In training, the team introduced a "Dynamic Accumulative Survival Game" framework.
This means making the model perform over a thousand steps of continuous decision-making in a continuously changing simulated environment, establishing its own hypotheses, adjusting strategies based on feedback, and avoiding "context corruption" from running too long.
Here's a telling data point: in the YC-Bench simulation of running a startup for a full year, Qwen3.7-Max achieved $2.08 million in revenue, double that of the previous generation ($1.05 million).
More crucially, it demonstrated strategic evolution: autonomously adjusting direction mid-term during a crisis, identifying and blocking malicious clients, eventually converging to a stable execution loop.
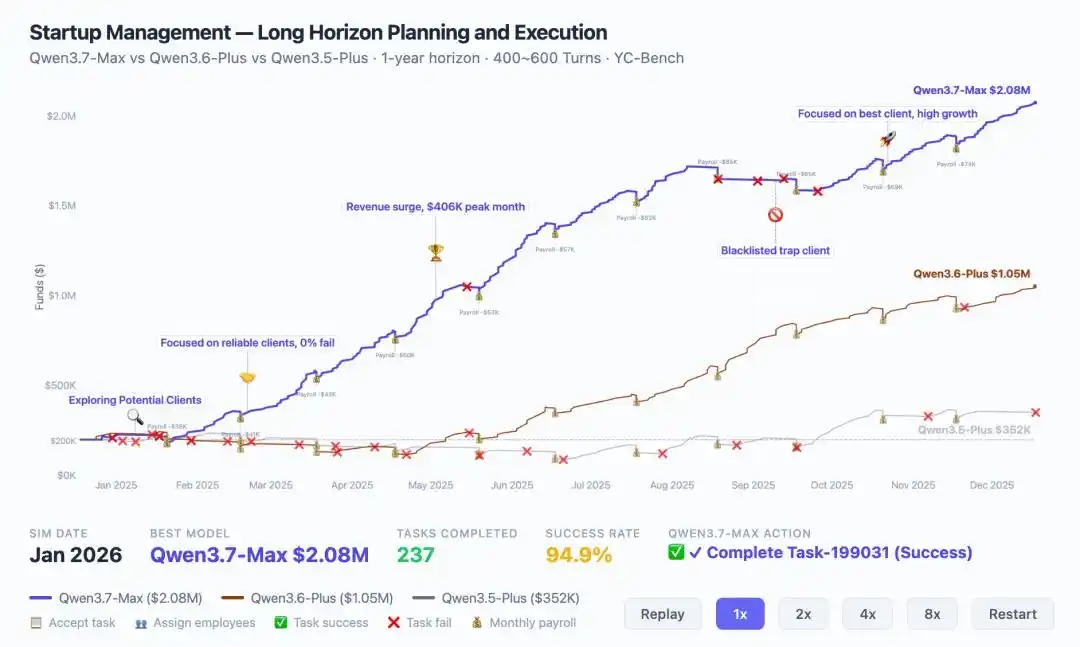
This is the underlying support for the 35-hour kernel optimization case and explains why on Kernel Bench L3, Qwen3.7-Max achieved speedup effects in 96% of scenarios.
And programming is just the first battlefield. This foundation of long-horizon reasoning and tool calling points to a greater ambition—a universal Agent foundation.
The Programming Finals Have a New Disruptor
Since its launch, Code Arena has always tested hard skills: multi-step reasoning, tool orchestration, complete project delivery—all real, Agent-level challenges.
Today, with a score of 1541 points, Qwen3.7-Max wedged itself into fourth place, positioned between Opus 4.6 Thinking and Opus 4.6.
On this track where Claude has dominated for over half a year, it has given its answer: Chinese models are not just followers; they can also be definers.
The global programming model competition is no longer a one-man show in Silicon Valley.
References:
https://arena.ai/leaderboard/code/webdev
This article is from the WeChat public account "AI Era Insights" (新智元), author: ASI启示录





