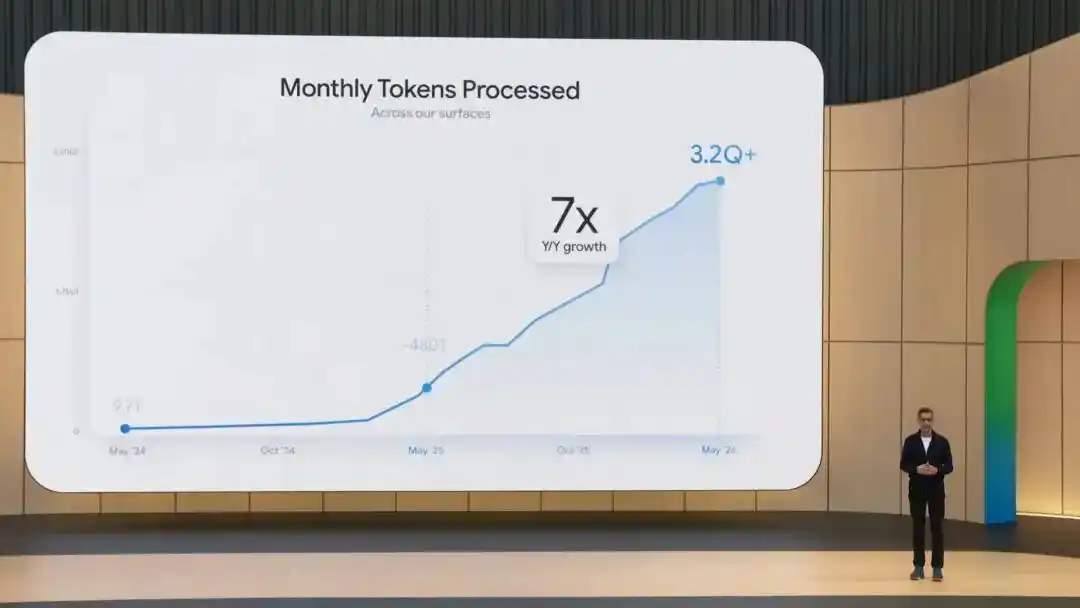
The Gemini App has over 900 million monthly active users, processes 3200 trillion tokens per month, and Nano Banana has generated over 50 billion images...
These are the numbers Google CEO Sundar Pichai opened with at today's early morning Google I/O keynote.
Over the past year, AI has become the main theme across all industries. Gemini's role at Google has also evolved from a standalone app to becoming the core AI underlying capability across all Google products.
This keynote also began with models, then moved on to coding and Agent products.
Gemini Omni pushes Google's video generation towards a "world model" direction, while Gemini 3.5 Flash, alongside AI programming tools, is positioned as an Agent development platform.
These two capabilities were then integrated into Google's full ecosystem: Search, the Gemini App, Flow, Spark, Chrome, XR glasses, and e-commerce scenarios.
Enter Gemini Omni, The "Nano Banana" Moment for Video is Here
Gemini Omni was the first to be highlighted in detail at the keynote. We created a comparison video with Seedance 2.0 to show the differences.
Google describes Gemini Omni as a new model capable of "creating any content from any input."
It combines Gemini's reasoning capabilities with Google's existing generative media models, aiming to enhance the model's understanding of the world, its multimodal generation capabilities, and editing abilities.

Google emphasized that while models like Veo, Nano Banana, and Genie can already generate videos, images, and interactive simulations, Gemini Omni goes a step further by beginning to handle problems closer to the physical world, like motion and gravity.
The case shown on stage involved an explanatory video on protein folding. Users simply input a prompt like "Generate a claymation explanation about protein folding," and Omni transforms the abstract scientific concept into video content.

It also supports more natural video editing. Users can upload their own videos, then modify the style, add elements, adjust details conversationally—even turning a plain circle into a black hole or transforming a nighttime walk into a more dramatic scene.

Google's claim is that Gemini Omni is starting with video but will gradually progress towards "any input to any output." This is also why Google has consistently designed Gemini as a multimodal model from the beginning.
The first model in the Omni family, Gemini Omni Flash, is already being integrated into Google products; more information about Omni Pro will be released later. Omni features in the Gemini App are also now available to Google AI Plus, Pro, and Ultra subscribers.
This means Gemini Omni isn't just a video generation model. Google wants to frame it within the narrative of a "world model": the model doesn't just generate images; it must understand the physical relationships, motion relationships, and scene logic within them.
As it enters applications like the Gemini App, Google Flow, and YouTube Shorts, Omni will also expand Google's generative creation tools from image editing to video editing.
Gemini 3.5 Flash Launches, AI Coding Enters Hyperdrive
If Gemini Omni corresponds to generation and editing, Gemini 3.5 Flash corresponds to speed, cost, and execution capability.

Google introduced Gemini 3.5 Flash at the keynote, calling it one of the first models in the Gemini 3.5 series, focused on agentic coding, long-horizon tasks, and real-world workflows.
Compared to 3.1 Pro, 3.5 Flash shows significant improvements in almost all benchmarks, especially in coding capabilities and evaluations like GDPVal that are closer to real-world economic tasks.
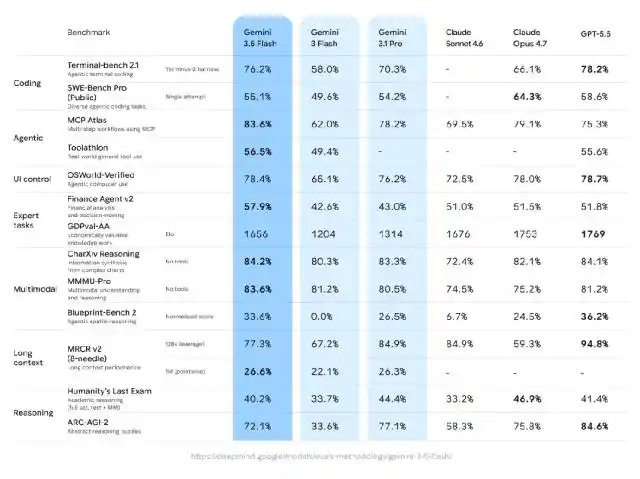
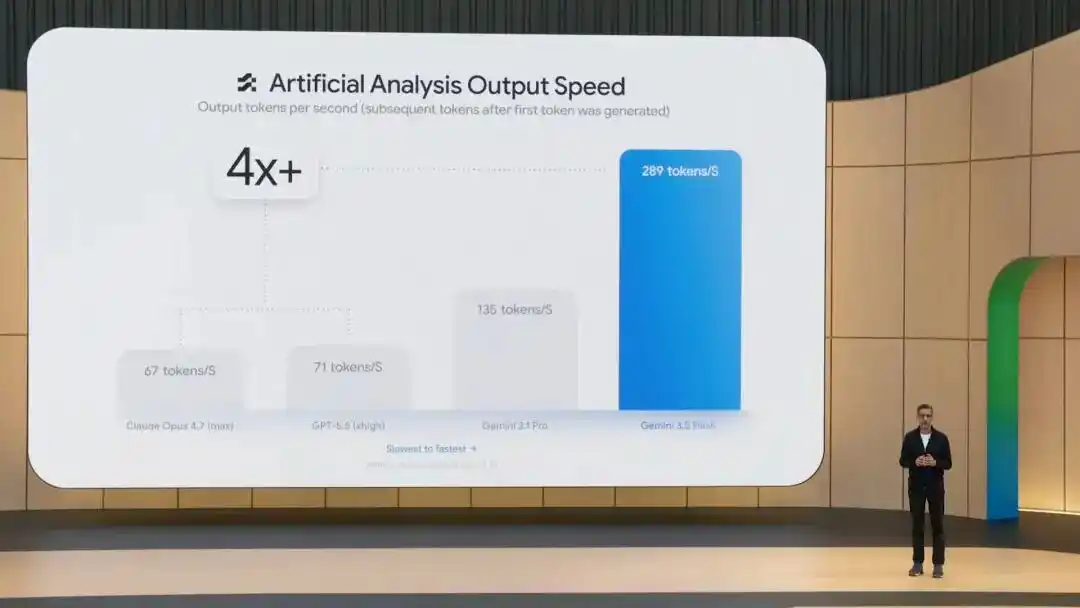
Beyond good benchmark performance, 3.5 Flash generates output tokens 4 times faster than other leading models. After specific optimization in Antigravity, speeds can reach up to 12 times.
It's worth noting that in March, Google's internal development-related tasks processed about 500 billion tokens daily, doubling every few weeks to now exceed 3 trillion tokens daily. Google calls this a feedback loop, using massive real-world usage to further improve 3.5 Flash.
Launched alongside the model is Antigravity 2.0.
It has evolved from an agent-powered IDE into a standalone desktop application, shifting focus to being "agent-first." Users are no longer just using AI for code assistance within an editor but completing development tasks through Agent conversations, Agent outputs, and multi-Agent collaboration.
Antigravity 2.0 adds a full CLI, Antigravity SDK, native voice support via Gemini's audio model, and integrates services like Android, Firebase, and Google AI Studio. Antigravity 2.0, as a standalone desktop app, is now available globally.
Google used a high-intensity demo on stage to illustrate Antigravity 2.0's direction: having an Agent build a runnable operating system from scratch. This task involved 93 sub-Agents executing in parallel over 12 hours, initiating over 15,000 model calls, processing 2.6 billion tokens, and generating core modules like a scheduler, memory management, and file system from an empty project.
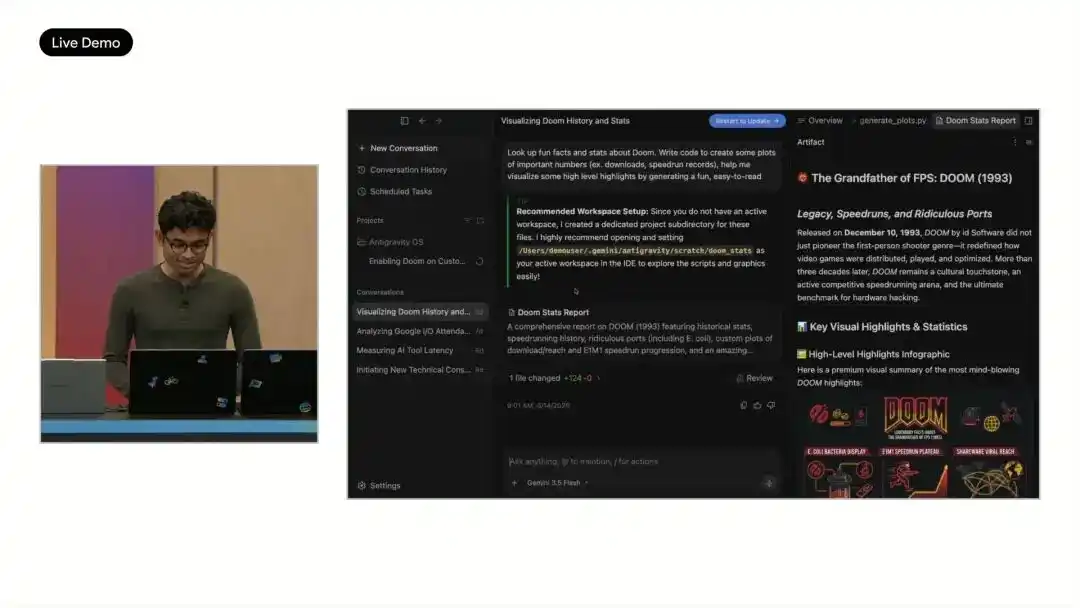
Google claimed this task was impossible with Gemini 3.1 Pro, and using Gemini 3.5 Flash cost less than $1000 in API credits.
The demo also showed this system running an SL train program and Doom. Since the system initially lacked video and keyboard drivers, Antigravity proceeded to generate the relevant code and fix it, enabling Doom to run. Google also stated that similar approaches have been tested on projects like a photo editing suite, real-time messaging app, and multi-user collaboration platforms, compressing engineering work that previously took days into hours or even less.
Gemini 3.5 Flash is now available to all users, covering Google products and API. Gemini 3.5 Pro is still under internal use and improvement, expected to open up next month.
From Search Box to Information Agent: Google Reinvents AI Search
Following models and development tools, Google shifted focus to search. Google Search is now AI Search.

Google stated that AI Mode already has over 1 billion monthly active users, with query volume doubling quarterly since its launch.
Starting today, AI Mode is being upgraded to Gemini 3.5. The new intelligent search box is also rolling out. It supports text, image, file, and video inputs and provides AI suggestions as users type questions.

AI Overviews and AI Mode have also been merged into a more continuous AI search experience. Users can first see AI answers on the main search results page, then enter AI Mode to continue asking follow-ups while retaining context. This new search experience launched globally on desktop and mobile on the same day as the keynote.
A bigger change is the Search Agent. Users will be able to create information Agents within Search this summer, allowing them to persistently track certain types of information.
For example, a user could set one to monitor large-cap biotech stocks with a P/E ratio below 15, positive cash flow, and low debt; or have it track rental listings, sneaker collaborations, or new product drops long-term. When conditions change, the Agent will send users a synthesized update.

Google is also bringing Antigravity's agentic coding capability into search.
Soon, search won't just return webpages, summaries, or cards; it can also generate interactive interfaces for specific queries. For instance, if a user asks "How do black holes affect spacetime?", Search might generate an interactive visual component. Following up with "How do binary black holes produce gravitational waves?" would cause Search to regenerate a dynamic interface with adjustable parameters. Generative UI with Antigravity will launch for free to all users this summer.

More complex custom experiences are on the way.
Google demonstrated a weekend planner on stage, where Search would combine weather, maps, user preferences, Gmail, Calendar, and other information to generate a small tool that can be further modified, shared, and synced to a calendar. Such custom experiences will open first to subscribers in the coming months.
Runs When Powered Off: Gemini Spark Brings Agent Capabilities into Personal Life
The most important new product for consumers is Gemini Spark.

Gemini Spark is a personal AI Agent that runs on dedicated virtual machines in Google Cloud and can perform tasks around the clock. It's powered by Gemini 3.5 and Antigravity harness, supporting long-running background tasks.
Even after a user shuts down their computer, Spark continues working. It first integrates with Google's own tools, with third-party tool integration via MCP coming in the next few weeks.

The keynote demonstrated several typical Spark scenarios.
Users can have it summarize Gemini Live releases and progress from the past week, extract information from Docs, Gmail, and chat history, and generate a team email in their personal writing style.
They can also have it manage a block party, maintain an RSVP spreadsheet in Google Sheets, track who's bringing what, generate draft reminder emails for neighbors who haven't signed up, and automatically create a promotional Google Slides page.
Spark also supports voice input on mobile.
Users can speak multiple tasks at once, like flagging all meetings with Sundar in bright pink, drafting an invitation letter for new neighbors, and creating a to-do document before the school year ends for their child. Spark splits this into multiple independent tasks and executes them in the background, with results syncing between phone and computer.
Gemini Spark is opening to select testers this week, with a beta rolling out next week to US Google AI Ultra subscribers.

Google simultaneously introduced a new $100/month Ultra plan and lowered the price of the highest-tier Ultra plan from $250/month to $200/month.
Later this summer, Spark will come to Chrome, becoming an intelligent browser agent that can perform tasks within webpages.

Gemini App Major Overhaul, Plus Google's Version of "AI Morning Briefing"
The Gemini App itself also received a major, transformative overhaul.
Google introduced a new design language called Neural Expressive, featuring fluid animations, vibrant colors, new fonts, and haptic feedback.
The new Gemini App no longer presents answers as large blocks of text. Instead, it dynamically generates layouts better suited for reading and interaction based on the content, including interactive images, timelines, embedded videos, etc. Neural Expressive is now rolling out globally on Android, iOS, and web.
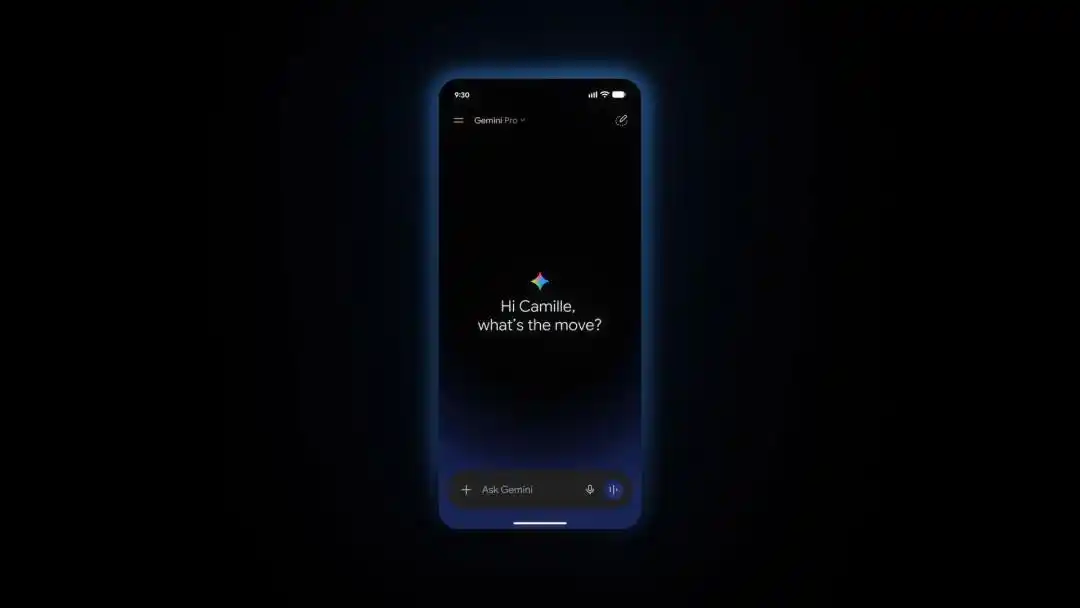
Gemini Live has also been redesigned, opening directly into a real-time conversation. Regional accent selection will roll out in the coming weeks.
The Gemini App also added Daily Brief. This is a personalized summary Agent designed for morning use, synthesizing information from Gmail, Calendar, Tasks, etc., to organize items users need to focus on for the day, and providing next-step action entry points.
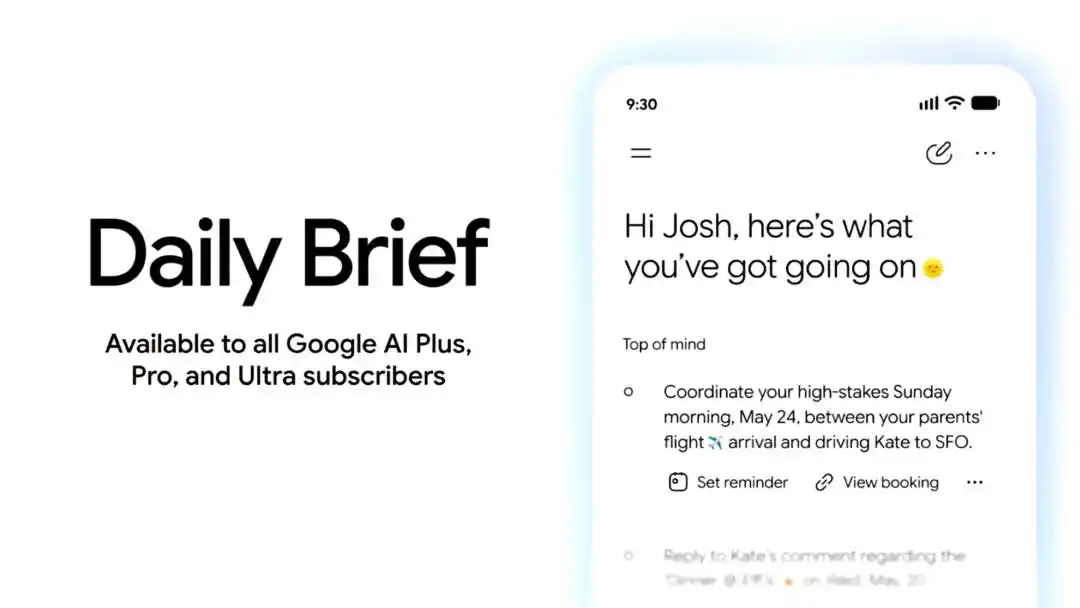
Daily Brief is launching today for US Google AI Plus, Pro, and Ultra subscribers.
Beyond the larger Gemini narrative, Google also updated several everyday products.
Google Maps recently underwent its biggest upgrade in a decade and added Ask Maps. It allows users to ask longer, more complex questions. For example, the keynote presented a scenario: a child falls into a duck pond, a wedding starts in 30 minutes, and the user wants to know where they can walk to buy a new dress.

Docs also gained new voice creation capabilities. Users don't need to input precise prompts; they can directly speak their thoughts, have Gemini pull a resume from Drive and event info from Gmail, then generate a Google Docs draft. This capability will launch for Pro and Ultra subscribers this summer, with similar voice capabilities coming to Gmail.
As generative capabilities advance, identifying content sources becomes increasingly important.
Google stated that since SynthID launched three years ago, it has added invisible watermarks to over 100 billion images and videos, and audio equivalent to 60,000 years of content. Next, SynthID and content credential verification will expand to Search and Chrome.

Users can circle content in search or right-click in Chrome to ask if content was AI-generated. The system will indicate if the content came from AI, a camera, or was edited by a generative AI tool.
Google also announced that OpenAI, Kakao, and ElevenLabs will adopt SynthID 2. NVIDIA has previously joined the SynthID ecosystem. For Google, SynthID isn't just a security feature; it's part of the effort to establish AI content transparency standards.

Google's Creation Suite Begins Assault on Images, Design, and Video
In the creative tools space, Google densely released multiple heavyweight products.
Google Pics is a new image creation and editing product within Google Workspace, targeting scenarios like party posters, infographics, and promotional graphics. Users can start from a base image, delete elements, resize objects, edit text, and translate text. Pics-generated content carries SynthID watermarks. Google Pics will launch this summer.

The design product Stitch also received updates. Users can generate a website or app interface with a single prompt, then continue modifying via text or voice—like enlarging titles, adjusting menus, highlighting more pizza options. Stitch supports exporting designs as code or publishing websites directly. These updates are live now.

Updates to Google Flow were particularly noteworthy. With Gemini Omni integrated into Flow, users can change environments, add visual effects, and insert new characters based on original videos while preserving the original performance as much as possible.
Flow also added a new Agent supporting the execution of multiple actions at once. For instance, generating 16 different camera-angle videos from a single image, or batch-transforming a set of morning scenes into night scenes.

Flow Tools allow users to create their own creative tools within Flow, like video effects, hand-drawn animation, and text layering tools, with support for sharing and remixing.
Google Flow Music can expand a piano riff into a music demo with stylistic direction. These new features for Google Flow and Google Flow Music are now live.
Betting on Smart Glasses, Google Ventures into the Next-Generation Entry Point Again
On the hardware side, Google is also extending the Android XR operating system platform from headsets and XR devices further into the smart glasses form factor.
Android XR is a platform Google developed in collaboration with Samsung and optimized for Qualcomm Snapdragon.

Google stated that AI glasses will be divided into two categories: One type are display glasses with small lenses, the other are audio glasses. Display glasses were shown last year at I/O; this year, first developers have begun creating display experiences, and a trusted tester program will expand later this year.
Audio glasses will come to market sooner.
The first audio glasses will launch this fall, with Samsung involved in hardware and experience building, and Warby Parker and Gentle Monster handling eyewear design. These glasses connect to phones, supporting Android and iOS. Gemini's responses are played privately through earbuds, not displayed on lenses.

During the demo, the presenter used glasses to have Gemini navigate to the place they met a friend last week, adding a coffee shop stop along the way; or have Gemini open DoorDash and automatically order coffee, waiting for user confirmation;
They could also have it summarize muted messages and write a family dinner into the calendar. The glasses can also work with a watch, allowing users to take a photo of the scene, generate a cartoon image with Nano Banana, and preview it on the watch.
Towards the end, Gemini's use cases were extended into cybersecurity scenarios.
Google introduced CodeMender. It's a code security Agent capable of automatically finding and fixing critical software vulnerabilities. Google will invite a group of experts to test the CodeMender API before a broader rollout.

After watching the entire keynote, the sheer volume of information was almost overwhelming. But when these AI features truly open up to tens of millions or even hundreds of millions of users, a very practical question of economics immediately presents itself: How does Google plan to recoup this enormous computational expense?
For over two decades, Google represented a classic free internet model. Users exchange attention and data for services; Google monetizes through advertising and distribution. This model made Google the most powerful infrastructure company of the internet era.
But the cost of large model inference is not on the same order of magnitude as performing a single web search.
Long-context memory, multimodal generation, cross-application Agents, enterprise-level automation—these capabilities are all backed by continuously running computational power consumption. The deeper AI integrates, the harder it becomes for Google to continue absorbing costs through "free feature upgrades."
That's why, throughout the keynote, Google I/O seemingly discussed experience upgrades, but the underlying direction pointed towards subscriptions, enterprise contracts, compute billing, and long-term service fees.

Free entry points certainly won't disappear, as they remain the foundation for Google to acquire users, data, and ecosystem positioning. But on top of these entry points, Google is adding a new layer of intelligent services: more powerful models, longer memory, deeper system permissions, more complex task execution, and more stable enterprise-level services.
In other words, Google is transforming further from a free internet services company into an AI subscription infrastructure company.
However, a question follows: are users willing to pay for search? Typically, no.
But what if it's a "super versatile assistant" that can handle your emails, coordinate tasks, analyze reports, manage your smart home around the clock, and even help you write code and develop apps? Would you be willing to pay tens to hundreds of dollars per month for it?
This is precisely the core business proposition that this year's Google I/O urgently wants to validate. And looking around the current frenzied market, the answer seems almost self-evident.
This article comes from the WeChat public account "APPSO," author: Discovering Tomorrow's Products







