June 2026, the large model industry is experiencing an unprecedented 'open-source tsunami': NVIDIA released a 550B-parameter hybrid architecture model, Google gifted a new version of the multimodal Gemma, and Zhipu AI fully open-sourced its flagship model under the most permissive license.
Almost all vendors tell the same story: use a Mixture of Experts (MoE) structure to pack in more parameters, use sparser activation to lower costs, and use elastic network widths to match different deployment scenarios.
In other words, the entire industry is desperately researching 'how to cram more parameters into the same compute budget.'
But a new paper from researchers at Mila, Cornell University, and the University of Montreal poses a question in almost the opposite direction: What happens if we don't add a single parameter, but simply 'reposition' the parameters already existing in the model?

Paper Title: Tapered Language Models Paper Link: https://arxiv.org/abs/2606.23670
Background: The Overlooked 'Uniform Treatment'
Since the 2017 paper 'Attention Is All You Need' that pioneered the Transformer, almost all language models share the same skeleton, whether it's the classic Transformer, later gated attention, recurrent memory networks, or even new architectures with 'test-time memory' capabilities. That is: stacking several structurally identical 'layers,' with each layer allocated exactly the same number of parameters.

This is like a chain restaurant where every location, whether downtown or suburban, is equipped with the same number of chefs and kitchen equipment, completely ignoring differences in customer flow. This 'uniform' allocation method is convenient and easy to maintain, but not necessarily optimal.
In recent years, more and more research has pointed out from different angles that model layers are not equally important.
'Early Exit' experiments show that often the model's answer is basically finalized before reaching the last layer;
'Layer Pruning' studies find that cutting out some of the later layers has almost no effect on model performance;
Interpretability research finds that shallow networks capture 'basic information' like grammar, while deep networks handle 'advanced information' like semantics.
In other words, the layers differ vastly from each other, yet parameter allocation remains uniform.
This is precisely the core question raised by the paper: Since the varying importance of layers has long been proven, why should their 'brain capacity' still be evenly distributed?
Moving 'Brain Capacity' Forward
The research team first conducted a simple and crude validation experiment: they divided the layers of a 440M-parameter Transformer model into early, middle, and late groups. Keeping the total parameter count constant, they made the 'Feed-Forward Network' (FFN, the core component of each layer responsible for storing and processing information, which can be understood as the 'working memory capacity' of each layer) of one group wider and the others narrower.
The result was very clear: The 'top-heavy' allocation concentrating capacity in the front segment lowered the model's perplexity (a metric measuring language model prediction accuracy; lower values indicate more accurate predictions) on the validation set from 16.28 to 15.96. Conversely, concentrating capacity in the back segment caused perplexity to soar to 17.29.

With the same total parameters, merely due to different placement, the performance difference was over a full point—a significant gap in language model evaluation.
This finding directed the question to a more granular direction: Instead of using a 'one-size-fits-all' three-segment grouping, could we use a smoother curve to gradually decrease capacity from front to back?
The researchers named this concept 'Tapered Language Models' (TLMs): select any dimension in the model that determines parameter count (e.g., the width of the feed-forward network) and make it monotonically decrease along the depth direction, while ensuring the average width of all layers still equals the original fixed value.
Thus, the total parameter count and computation remain completely unchanged, only the distribution shape changes from a 'rectangle' to a 'wedge.'
The team tried three decreasing curves: linear decrease, cosine decrease, and S-shaped (Sigmoid) decrease.
The differences between these three curves are analogous to three different ways of 'closing up shop':
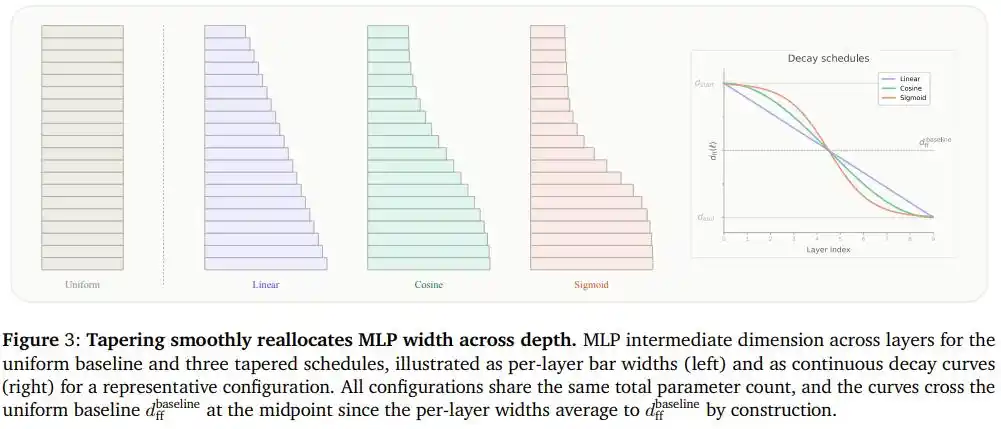
Linear decrease is like closing at a constant rate, shutting down roughly the same number of counters each period;
S-shaped decrease is like suddenly announcing closure, with most stalls remaining as is, only a small middle segment contracting rapidly;
Cosine decrease lies between the two, transitioning gently at both ends, gradually tightening in the middle. It neither 'cuts losses' abruptly at the ends nor exerts uniform force and misses the area that should contract the most.
Experimental Results: Free 1.84 Points
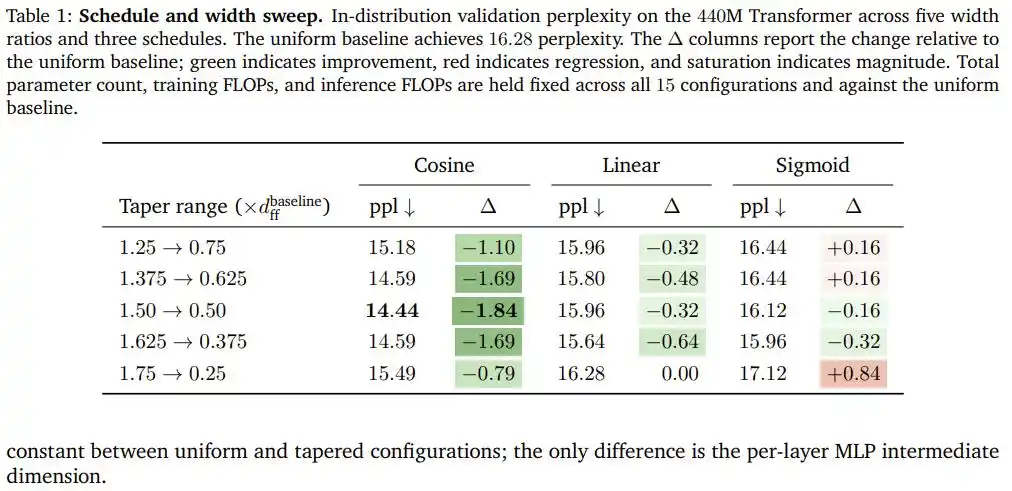
After scanning combinations of five width ratios and three curves on the 440M-parameter Transformer, cosine decrease emerged as the clear winner: under the optimal configuration (front width 1.5 times baseline, back width 0.5 times baseline), perplexity dropped from the uniform distribution baseline of 16.28 to 14.44, a full improvement of 1.84 points, all without adding a single parameter or an extra floating-point operation.
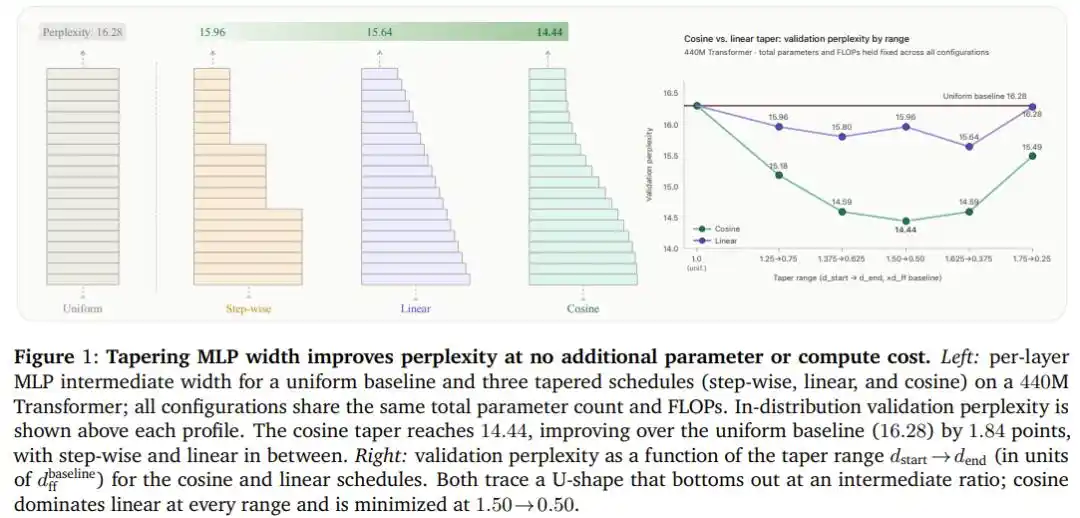
More crucially, this conclusion isn't just luck for one particular architecture.
The research team ported the exact same configuration (cosine decrease, front/back width ratio 1.5/0.5) to three other structurally distinct architectures: a gated attention model, Hope-attention with 'self-modifying memory' capability, and the Titans architecture with neural long-term memory modules. They then re-validated at two larger scales: 760M and 1.3B parameters.
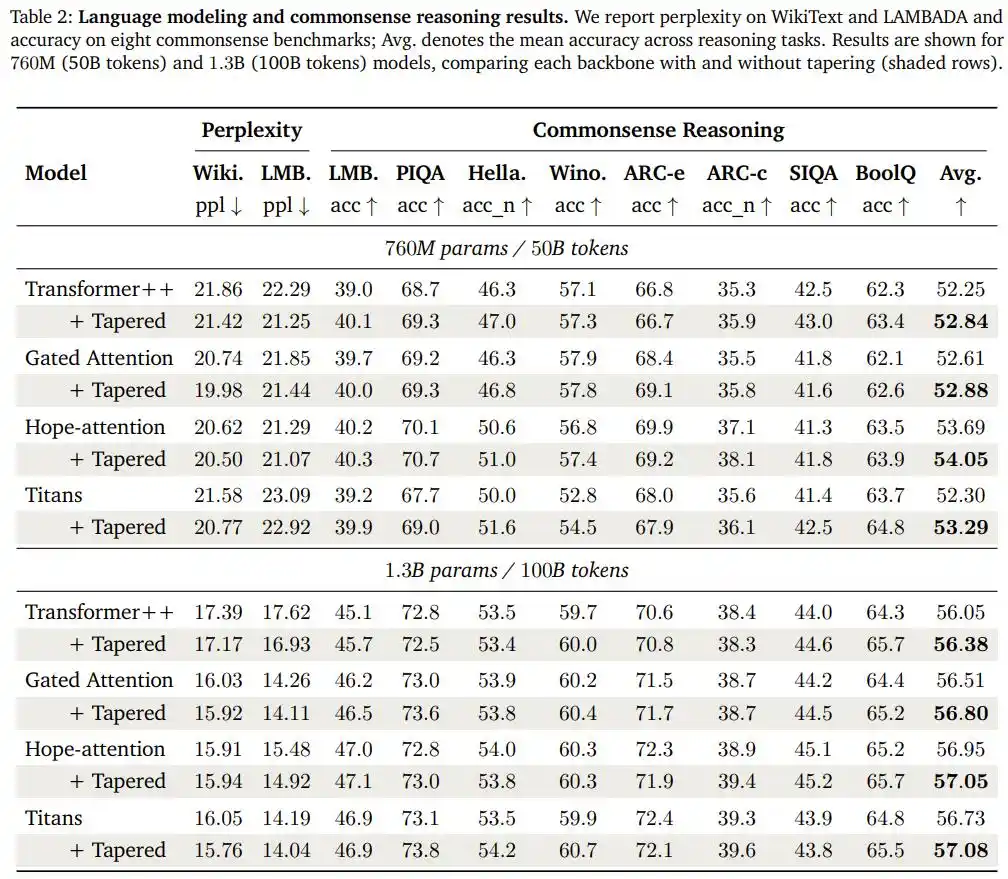
The result: Across all eight comparison sets of the four architectures and two scales, the 'tapered' models showed improved average accuracy on commonsense reasoning benchmarks and improved perplexity on the LAMBADA language prediction task.
The researchers also conducted additional long-text retrieval tests (Needle-in-a-Haystack), confirming that this redistribution does not sacrifice the model's ability to handle long contexts.
To explain the reasons behind this phenomenon, the team also measured the similarity between the output of each 'Feed-Forward Network' layer in GPT-2 series models and the existing information flow, revealing a clear pattern: The deeper into the model, the more similar the newly written content of each layer is to the existing information. In other words, later layers are more about 'reiterating' existing judgments rather than 'creating' new understandings.
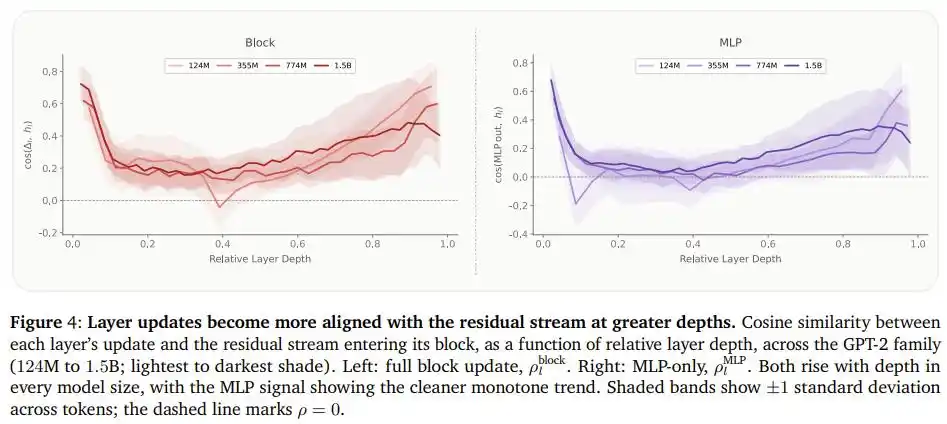
This precisely confirms why moving capacity from the back to the front is reasonable: the front layers can truly utilize this extra 'brain capacity,' while the back layers cannot.
Conclusion
This research essentially proposes a simple yet long-overlooked proposition: a model's capacity should not be a resource uniformly splashed out but should flow to where it's truly needed.
In a 2026 where the entire industry is competing over 'who has more parameters' and 'whose architecture is sparser,' this paper offers an almost zero-cost alternative: no need to change architectures, no need to add parameters, just change the 'shape' of the distribution.
The researchers also frankly state that the current optimal configuration was tuned on a 440M-parameter model. Whether there are 'special recipes' more suitable for different scales and architectures remains an open question.
But more noteworthy is that the paper points out this line of thinking is not limited to language models—Vision Transformers, diffusion models, and multimodal models almost all inherit the same default setting of 'equal distribution per layer.' If the shape of capacity distribution itself is a long-overlooked design dimension, then this 'free lever hidden in plain sight' may have only just been noticed.
Team Introduction
The paper was completed jointly by Reza Bayat from Mila (Montreal Institute for Learning Algorithms), Ali Behrouz from Cornell University, and Aaron Courville, co-founder of Mila and professor at the University of Montreal.
Ali Behrouz is currently a researcher at Google Research and a PhD student at Cornell University. Over the past two years, he has participated in designing several new architectures that have garnered widespread attention, including the Titans architecture capable of 'learning and remembering during test time,' as well as the subsequent Atlas and 'Nested Learning' framework. He has long focused on how to make models utilize and store long-term context information more efficiently.
Aaron Courville is a senior scholar in the deep learning field, a CIFAR AI Chair. He has long collaborated with Yoshua Bengio in promoting fundamental deep learning research, with deep expertise in representation learning and generative models. He is also one of the authors of Generative Adversarial Networks (GANs) and co-authored the classic book 'Deep Learning' with Ian Goodfellow and Bengio.
This article is from WeChat Official Account 'Jiqizhixin' (ID: almosthuman2014), author: Following AI





