Author: AI Product Aying
I read a blog post by the Anthropic team titled "Lessons from building Claude Code: How we use skills." This is probably the most in-depth practical summary I've seen about Skills so far.
Skills aren't that complicated, but doing them well isn't that easy either.
I remember when Skills first became popular, everyone loved making all kinds of writing style Skills, composition Skills. It seemed like as long as you stuffed your writing style into it, the model could consistently output in that style.
But later, after trying a bunch myself, I found it often just didn't work.
Because a writing style Skill might stuff in thousands or even tens of thousands of words. Once the Skill loads, it eats up a big chunk of the context. When the context gets heavy, the model's reasoning ability actually tends to drop.
You often end up with this situation: the style is learned, but the content becomes shallow, and the analytical ability weakens.
There's another common scenario.
When many people write Skills, they love stuffing them with various operation instructions. Step one do this, step two do that, step three do this. When you run it, you'll find the model's execution isn't stable.
Later I slowly understood that a lot of this repetitive execution work is actually more suitable to be solidified into a Script, rather than written as long Instructions.
After reading this Anthropic article, my biggest takeaway is that many people are actually using Skills, but they might not truly understand Skills.
Skill is essentially about Context Engineering. There's a lot of experience involved in deciding when knowledge should go into a Skill, when it should be split into References, when it should be written as a Script, and when Gotchas should be used to constrain the model.
After understanding how Skills work, looking back at those excellent Skills, you'll find they're never solving prompt problems; they're solving problems related to context, experience accumulation, and capability reuse.
If you want to deeply research Skills, I highly recommend reading two articles:
https://claude.com/blog/lessons-from-building-claude-code-how-we-use-skills
https://research.perplexity.ai/articles/designing-refining-and-maintaining-agent-skills-at-perplexity
#01 Don't Write Nonsense
Skills are essentially about accumulating "tacit knowledge" within an organization. So, don't repeat common sense the model already knows in a Skill. What's truly valuable is the information the model fundamentally doesn't know.
Anthropic internally often emphasizes that what Skills really need to document are the Gotchas, the common pitfalls.
For example:
1. This table cannot be sorted by `created_at`
2. Staging returning 200 doesn't mean success
3. `request_id` and `trace_id` are the same thing
Because this kind of information often exists in employees' experience. So you must remember what a Skill essentially is.
Skill = Writing down the experienced master's knowledge.
Through Skills, you accumulate the experience originally scattered in different people's minds.
#02 Skill is Actually Context Engineering
This might be one of Anthropic's most profound points.
A Skill is not a markdown file; it's a folder. For people who have used Skills, this sounds like stating the obvious.
But I've been mulling it over these past few days and slowly realized: they precisely want to use the folder form to express the concept of Context Engineering.
Let's look again at a typical Skill structure:
skill/ ├── SKILL.md ├── references/ - place detailed instructions, API references, edge cases ├── scripts/ - place executable scripts ├── examples/ - place examples ├── assets/ - place templates, images, fixed materials
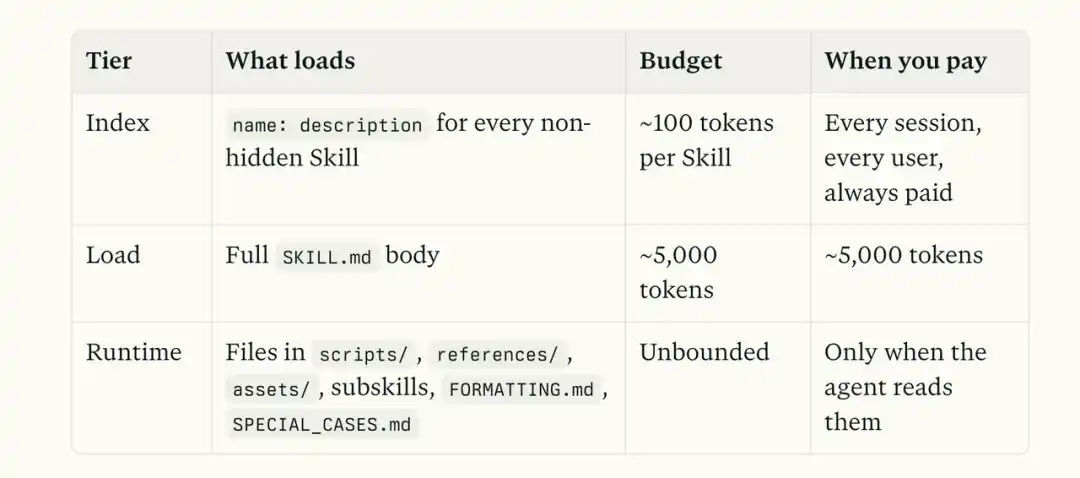
When a Skill is invoked, the model first reads SKILL.md. If we cram all information into this file, context will explode very quickly.
Assume this is a payment troubleshooting Skill, containing Stripe error code explanations, historical failure cases, troubleshooting scripts, and final report templates.
If all this content is piled into SKILL.md, every time the Skill is invoked, Claude has to read it all again.
Even if the user just wants to confirm the meaning of one error code, even if they just want to check why a payment status hasn't updated. A large amount of completely unnecessary information also gets shoved into the context.
Anthropic's approach is completely different.
SKILL.md is more like a navigation page. Its job is to tell the model, when encountering a Stripe error, go to `references` to find the corresponding explanation.
When needing to reference historical cases, go to `examples` to check similar issues; when needing to actually execute troubleshooting actions, run the script in `scripts`; finally, when generating the troubleshooting report, use the template in `assets`.
The whole process is a gradual exposure.
I strongly suggest you save the image below.
#03 Use Scripts Whenever Possible
Don't let the model waste its limited context and reasoning power on repetitive labor. Hand these tasks over to scripts.
For example. When many people write Skills, they write like this:
1. Query registration data; 2. Query payment data; 3. Calculate conversion rate; 4. Analyze root causes.
This way of writing is fine, of course. The model can complete it. But every time it executes, it has to run through the entire analysis process from the beginning.
Querying data, organizing data, handling various edge cases — this work is all repetitive.
Since these capabilities have been verified countless times. Why make the model reinvent it each time? Just provide the concrete scripts directly.
And through scripts, Skill execution becomes more accurate and also saves tokens.
From this perspective, the Scripts in a Skill are actually solidifying organizational capability. Behind each script is often the best practice summarized by the team after countless past pitfalls.
After solidifying these capabilities, Claude can work based on this accumulated experience every time, instead of starting from scratch again and again.
So I increasingly feel that within a Skill, Instructions and Scripts solve problems at two different levels.
Instructions provide experience and judgment; Scripts provide capability and execution.
For example, a payment troubleshooting Skill might have this line:
If Stripe returns 200, don't assume payment success directly; you need to further check the `payment_events` table.
This belongs to Instructions. Because it's experience. Whereas `check_payment_events()` belongs to Script, because it's execution capability.
If you only have the Script, the model knows *how* to check, but may not know *why* to check.
If you only have Instructions, the model knows it *should* check. But has to re-implement it every time. Both are indispensable.
#04 Description is More Like a Routing Rule
The way many people write Skill Descriptions is inherently wrong.
Because people are used to writing them as feature introductions. For example: PR Management Skill helps users monitor PR status, handle CI issues, automatically complete Merges.
But the problem is, the model doesn't find Skills by their functionality. When Claude Code starts up, it first scans the names and Descriptions of all Skills.
Then, based on the user's current question, it decides which Skill should be loaded.
So the most important information in the Description is not what this Skill can *do*, but under what circumstances it *should* be loaded.
The Description actually handles the routing work for the entire Skill.
In the real world, few people say "help me invoke a PR management tool." People are more likely to say: "help me keep an eye on this PR," "the CI is down again," and so on.
So a good Description should try to describe the user's *intent*, not list features.
I even think you can use a very simple method to check.
After writing the Description, delete the entire Skill, keeping only this one line Description. Then ask yourself: after the model sees the user's question, can it know when to load this Skill?
If it can't, you probably need to keep revising.
#05 Skill Management and Distribution
Another point is about Skill management.
When one person uses Skills, it's pretty simple. Write a few Skills yourself, maintain them yourself, upgrade them yourself. But I believe most teams will eventually face the same problem.
When Skills grow from a few to dozens, or even hundreds, how should these Skills be managed? How should they be upgraded? How should they be distributed to team members?
I think Anthropic's experience in this area is quite worth referencing.
When the team size is relatively small, Skills can travel directly with the code repository. Just put them in the project's .claude/skills directory. Everyone shares the same set of Skills and the same working methods.
But as the number of Skills increases, a new problem appears.
When Claude Code starts up, it scans the names and Descriptions of all Skills, then decides which Skill should be invoked for the current task. The more Skills there are, the higher the routing cost.
This is also why Anthropic later started making a Marketplace. But what's even more interesting is how they manage the Marketplace.
When many companies encounter this problem, their first reaction is often to establish an approval process. Whoever writes a Skill submits an application first; after approval, it enters the official Skill library. We did this internally before too, but it's very heavy. Managing for the sake of management.
I found Anthropic's organization is very lightweight.
Let new Skills spread in a small scope first; let colleagues install and try them themselves.
If more and more people start using it, it shows this Skill truly solves a real problem. At this stage, the author can then submit it to the formal Marketplace.
So they don't first debate whether a Skill is valuable; they first let it be tested in real usage scenarios. If many people use it, it naturally enters the formal system. The Skills that remain this way are basically the ones the team truly needs.





