如果我们已迎来 InfoFi 时代的终结,或是正一步步逼近这个节点,我并不会感到意外。
自 InfoFi 兴起以来,许多人借此赚取了可观的收益,有人累计赚了 5 位数,有人甚至赚到了 6 位数。但如今,一些信号值得我们高度警惕。
门槛规则变更
严格来说,我并不认为 Kaito 这次升级完全是件坏事,它或许能有效杜绝大量账号用 AI 生成劣质内容 「刷量」 的行为,同时提升内容质量。
但升级后,不仅小号受到冲击,许多大号也未能幸免。这导致大量依赖 Kaito 的用户选择离开,因为升级后,他们几乎没有机会再通过平台赚到钱。
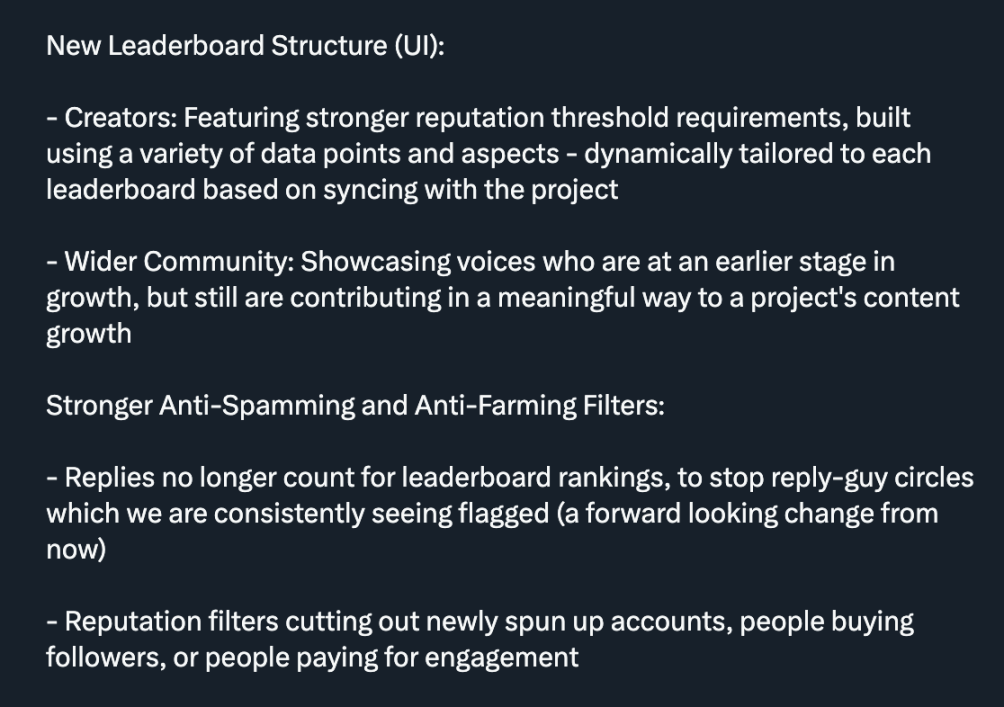
对此,一些项目方选择取消门槛,以吸引小号入驻。这恰恰说明:在大多数情况下,小号群体是至关重要的。
我的看法是:Kaito 似乎对这次升级的方向感到困惑,而且很多项目方显然不喜欢这种 「门槛限制」。不过不可否认的是,在过去几个月里,Kaito 的表现一直相当出色。
代币分配方案拉胯
对于内容创作者(yappers)而言,如今常规的 0.5%-1% 代币分配比例已远远不够,因为这些代币上线时的估值往往很低。
早期,有些账号通过 1-2 个月的推广活动就能赚到 4-5 位数收益;而现在,即便是参与 3-6 个月的活动,也只能赚 3-4 位数,这让很多人感到心灰意冷。
甚至连头部账号,即便产出了优质内容,也很难赚到可观的 4 位数收益。
这对依赖 InfoFi 的创作者来说为何是坏消息?在 InfoFi 兴起之前,许多创作者作为品牌大使或 KOL 推广内容,就能获得不错的收入。而现在 Kaito 上的项目方给出的报酬,根本无法与外部合作相提并论 。鉴于这一事实,越来越多创作者选择离开 InfoFi 平台,也就不足为奇了。
「Capital Launchpad」 主导地位凸显
7 月 22 日,Kaito 的 「Capital Launchpad」正式上线,首个上线项目是 Espresso,随后有更多项目陆续入驻。
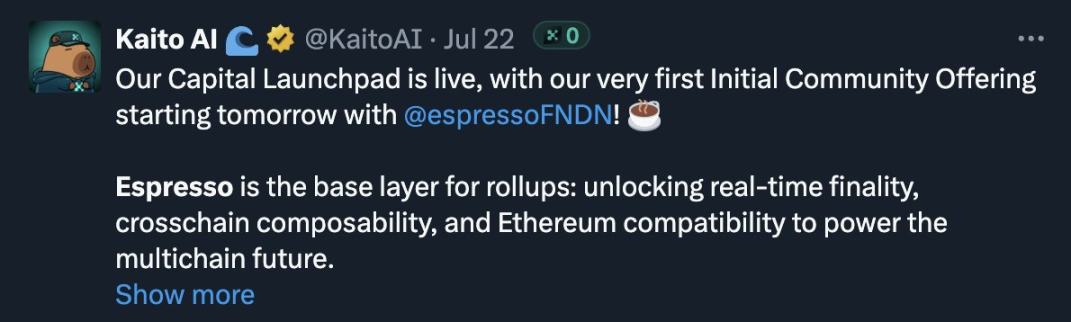
对 Kaito 而言,这无疑是个不错的产品,但我也有几点担忧:
- 通过 Kaito 首次代币发行的项目,至今没有一个在公开市场上线;
- 这些项目均未公布上线日期;
- 大多数项目的估值过高,且代币解锁方案对投资者不友好。
我的补充观点:Kaito 最初是专为 InfoFi 打造的平台,后来才决定增加额外的平台功能(如 Launchpad),这本身是很棒的尝试。但最近,越来越多项目选择入驻 「Capital Launchpad」,而非参与 「创作者排行榜」。对于一个 InfoFi 平台来说,这种趋势显然不太乐观。
不过,这只是我观察到的明显现象,似乎没多少人对此提出质疑。
项目方更倾向于与 KOL 直接合作,而非通过 Kaito 平台
这一点很明显:项目方已不再那么热衷于参与 InfoFi 合作了。
最近,Zachxbt 发布了一个谷歌表格,列出了一批从某项目方获得报酬的账号。我提及此事并非因为惊讶,而是因为这些报酬金额相当可观,尤其是与 Kaito 「创作者排行榜」 上的项目相比。
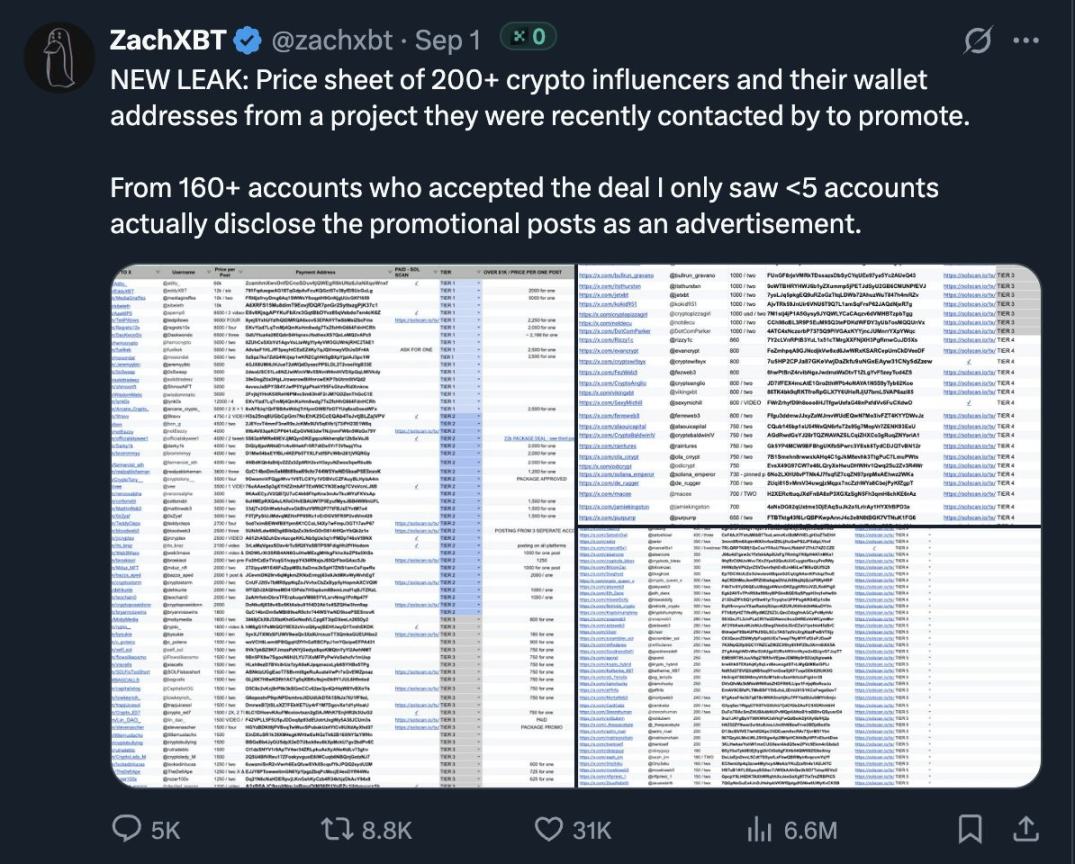
我相信,这已经让不少人意识到:除了 InfoFi,还有很多赚钱的方式。而人性的现实是 「想尽办法多赚钱」,因此我认为这对 Kaito 构成了直接竞争。