作者:卡兹克
大半夜的,OpenAI抽象了整整快半年的新模型。
在没有任何预告下,正式登场。
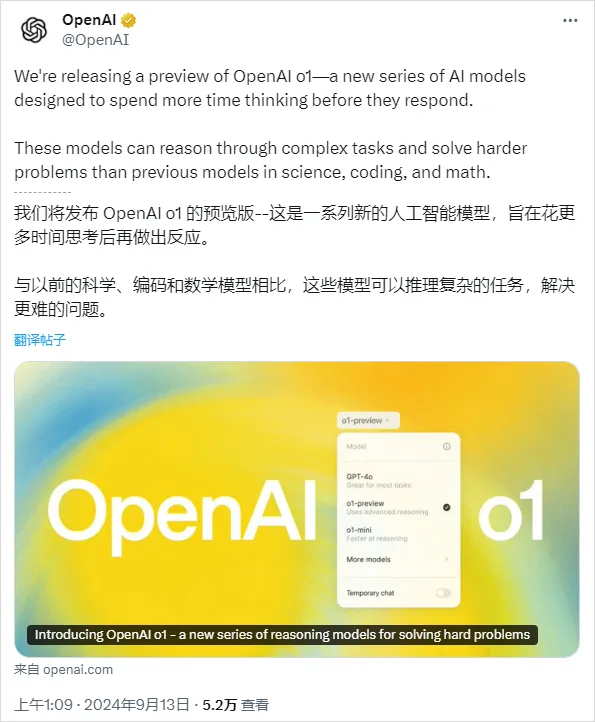
正式版名称不叫草莓,草莓只是内部的一个代号。他们的正式名字,叫:

为什么取名叫o1,OpenAI是这么说的:
For complex reasoning tasks this is a significant advancement and represents a new level of AI capability. Given this, we are resetting the counter back to 1 and naming this series OpenAI o1.
翻译过来是:
对于复杂推理任务来说,这是一个重要的进展,代表了人工智能能力的新水平。鉴于此,我们将计数器重置为 1,并将这一系列命名为 OpenAI o1。
这次模型的强悍,甚至让OpenAI不惜推掉了过去GPT系列的命名,重新起了一个o系列。
炸了,真的炸了。
我现在,头皮发麻,真的,这次OpenAI o1发布,也标志着,AI行业,正式进入了一个全新的纪元。
“我们通往AGI的路上,已经没有任何阻碍。”
在逻辑和推理能力上,我直接先放图,你们就知道,这玩意有多离谱。
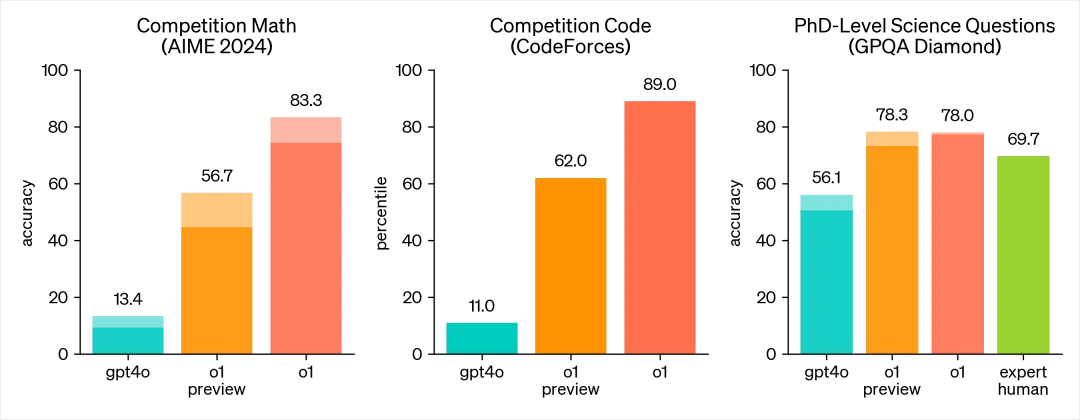
AIME 2024,一个高水平的数学竞赛,GPT4o准确率为13.4%,而这次的o1 预览版,是56.7%,还未发布的o1正式版,是83.3%。
代码竞赛,GPT4o准确率为11.0%,o1 预览版为62%,o1正式版,是89%。
而最牛逼的博士级科学问题 (GPQA Diamond),GPT4o是56.1,人类专家水平是69.7,o1达到了恐怖的78%。
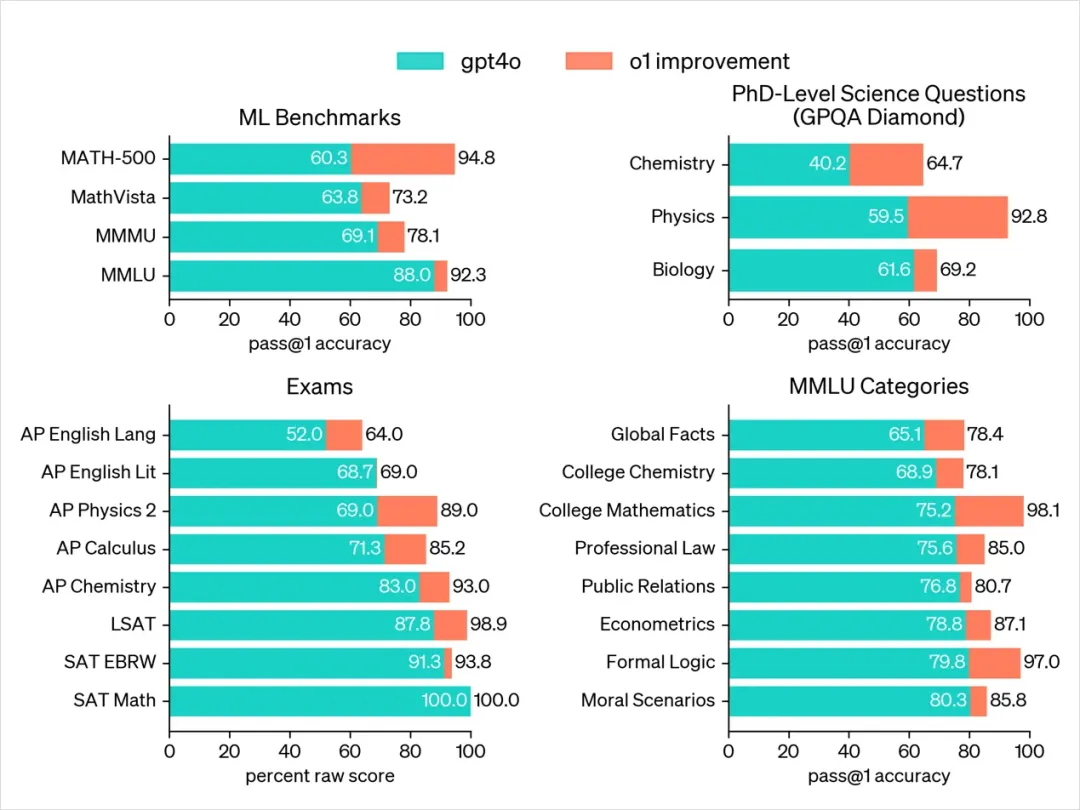
我让Claude翻译了一下o1的图,丑是丑了点,但是能看的懂每项数据意思就行。

什么叫全面碾压,这就是。
特别是在测试测试化学、物理和生物学专业知识的基准GPQA-diamond上,o1 的表现全面超过了人类博士专家,这也是有史以来,第一个获得此成就的模型。
而整个模型之所以达到如此成就,基石就是Self-play RL,不知道这个的可以去看我前两天的预测文章:新模型草莓到底是个啥?
通过Self-play RL,o1学会了磨练其思维链并完善所使用的策略。它学会了识别和纠正自己的错误。
它也学会了将复杂的步骤分解为更简单的步骤。
而且当当前的方法不起作用时,它也学会了尝试不同的方法。
他学会的这些,就是我们人类,最核心的思考方式:慢思考。
诺贝尔经济学奖得主丹尼尔·卡尼曼有一本著作,名叫:《思考,快与慢》。
非常详细的阐述了人类的两种思考方式。
第一种是快思考(系统1),特点是快速、自动、直觉性、无意识,举几个例子:
-
看到一个笑脸就知道对方心情很好。
-
1+1=2 这样简单的计算。
-
开车时遇到危险情况立即踩刹车。
这些就是快思考,也就是传统的大模型,死记硬背后学得的快速反应的能力。
第二种是慢思考(系统2),特点是缓慢、需要努力、逻辑性、有意识,举几个例子:
-
解决一道复杂的数学题
-
填写税务申报表
-
权衡利弊后做出重要决定
这就是慢思考,我们人类之所以强大的核心,也是AI要通往下一步AGI路上的基石。
而现在,o1终于踏出了坚实的一步,拥有了人类慢思考的特质,在回答前,会反复的思考、拆解、理解、推理,然后给出最终答案。
说实话,这些增强的推理能力在处理科学、编码、数学及类似领域的复杂问题时绝对极度有用。
例如o1可以被医疗研究人员用来注释细胞测序数据,被物理学家用来生成量子光学所需的复杂数学公式,以及被各个领域的开发人员用来构建和执行多步骤工作流,等等等等。
o1也绝对是全新一代的数据飞轮,如果答案正确,整个逻辑链就会变成一个包含正负奖励的训练示例的小型数据集。
以OpenAI的用户级别,未来的进化速度,只会更恐怖。
写到这,我忽然叹了口气,我觉得我跟一年以后的o1比起来,可能就是个纯废物了,真的。。。
目前,o1模型已经逐步向所有ChatGPT Plus和 Team用户开放,未来会考虑对免费用户开放。
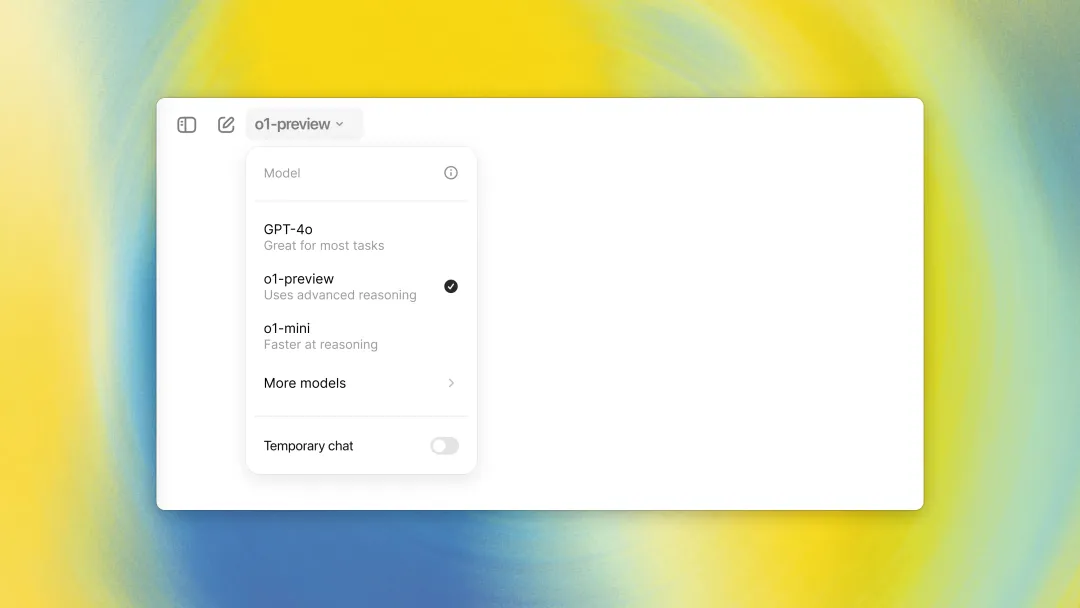
分为两个模型,o1预览版和o1 mini,o1-mini就是更快更小更便宜,推理啥的都不错,极度适合数学和代码,就是世界知识会差很多,适用于需要推理但不需要广泛世界知识的场景。
o1预览版每周30条,o1-mini每周50条。
雪崩,甚至不是按以前的3小时来限制的,是每周30条,也能从侧面看出来,o1这个模型,有多贵了。
对于开发者来说,只对已经付过1000美刀的等级5开发者开放,每分钟限制20次。
都挺少的。
而且在功能上阉割挺大,但是毕竟早期,理解。

API的价格上,o1预览版每百万输入15美元,每百万输出60美元,这个推理成本...

o1-mini会便宜一些,每百万输入3美元,每百万输出12美元。

输出成本都是推理成本的4倍,对比一下GPT4o,分别是5美元和15美元。

o1-mini还是勉强有一些经济效应的,不过还是开始,后面等着OpenAI打骨折。
既然说o1已经对Plus用户开放,我就直接去我的号上看了眼,还不错,拿到了。
那自然,第一时间试一试。
目前不支持曾经的所有功能,也就是没有图片理解、图片生成、代码解释器、网页搜索等等,只有一个可以对话的裸模型。
我先是一个曾经很致命的问题:
“农夫需要把狼、羊和白菜都带过河,但每次只能带一样物品,而且狼和羊不能单独相处,羊和白菜也不能单独相处,问农夫该如何过河。”

思考了6秒时间,给了我一个很完美的回答。
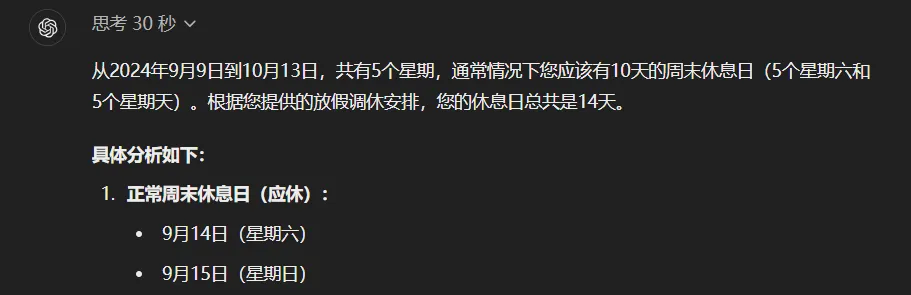
还有之前一个坑遍所有大模型的调休问题:
“这是中国2024年9月9日(星期一)开始到10月13日的放假调休安排:上6休3上3休2上5休1上2休7再上5休1。
请你告诉我除了我本来该休的周末,我因为放假多休息了几天?”
在o1思考了整整30秒以后,给出了一天不差的极度精准的答案。

无敌,真的无敌。
再来一个更难的,就是曾经姜萍那个比赛的奥数题:

别问我题目什么意思,我看不懂,我是废物,这题曾经屠杀所有的大模型,这次,我们让o1也来试一下看看。

在o1思考了整整1分多钟之后,他给出了答案。
...
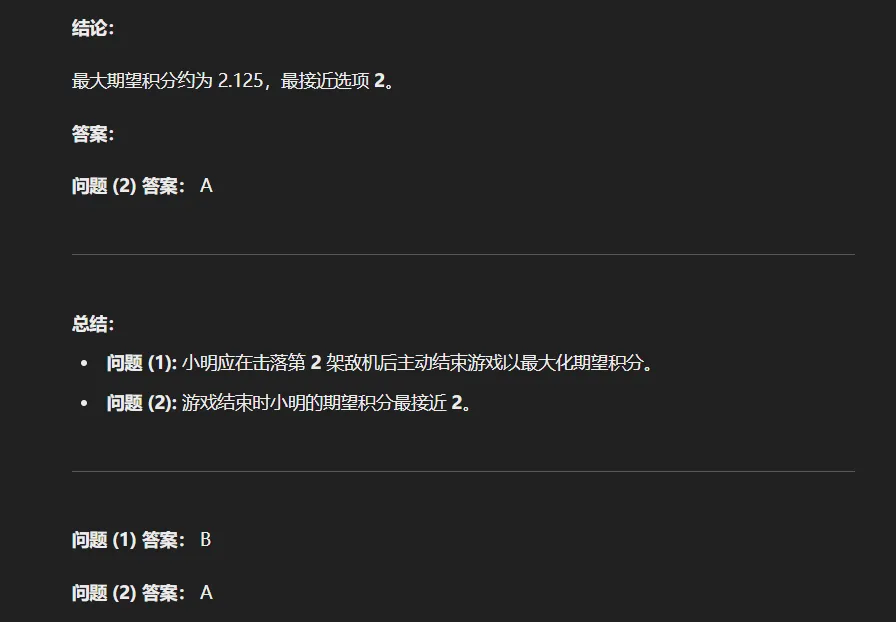
全...对...
我裂开了。
目前我自己试下来,感觉Prompt,未来可能也要重新摸索,在GPT为代表的快思考大模型时代,我们有很多所谓的一步一步思考之类的玩意,现在全都无效了,对o1甚至还有负效果。
OpenAI给出的最佳写法是:
-
保持提示简单直接:模型擅长理解和响应简短、清晰的指令,而不需要大量的指导。
-
避免思路链提示:由于这些模型在内部进行推理,因此不需要提示它们“逐步思考”或“解释你的推理”。
-
使用分隔符来提高清晰度:使用三重引号、XML 标签或章节标题等分隔符来清楚地指示输入的不同部分,帮助模型适当地解释不同的部分。
-
限制检索增强生成 (RAG) 中的附加上下文:提供附加上下文或文档时,仅包含最相关的信息,以防止模型过度复杂化其响应。
最后,我想说一下这个思考的时长。
现在o1是思考了一分钟,但是,如果是真正的AGI,说实话,思考的越慢可能会越刺激。
当他真的,可以去做证明数学定理,去做癌症药物研发,去做天体研究呢?
每一次的思考,可以达到几小时、几天、甚至几周呢?
最后的结果,可能会让所有人震惊的难以置信。
现在,没有人能想象到,那时候的AI,会是一个什么样的存在。
而o1的未来,在我看到,也绝对不止是一个普普通通的ChatGPT。
而是我们前往下个时代,最伟大的基石。
“我们通往AGI的路上,已经没有任何阻碍。”
现在,我毫不犹豫的坚信着这句话。
星光熠熠的下一个时代。
在今天。
正式到来了。