原文来源:dYdX
原文编译:BlockBeats
在去中心化衍生品平台 dYdX 上,用户可以通过 Ledger 安全地质押 DYDX 并赚取 USDC。
质押 DYDX 并赚取 USDC
dYdX 链上的所有费用(吃单方(Taker)/挂单方(Maker)费用)均由验证者和质押者承担,主要以 USDC 形式分配。这创建了一种奖励机制,不会对原生代币造成通胀压力,并为验证者和利益相关者提供了实用性。
对于协议分配给质押者的任何质押奖励,验证节点都可以设置特定的佣金率,范围从最低 5% 到最高 100% ,并适用于每个验证节点的质押者。该佣金将从协议分配给这些质押者的质押奖励中扣除,并由相关验证人保留。目前,根据Minstcan 的数据,dYdX 链上的平均验证者佣金率为 6.08% 。
详情可参阅 dYdX 基金会关于质押 DYDX 的博客
截至 2024 年 1 月 12 日,质押 DYDX 的年利率从 9% 到 25% 不等。这是因为 dYdX Chain 收到的费用金额取决于当天的市场状况。
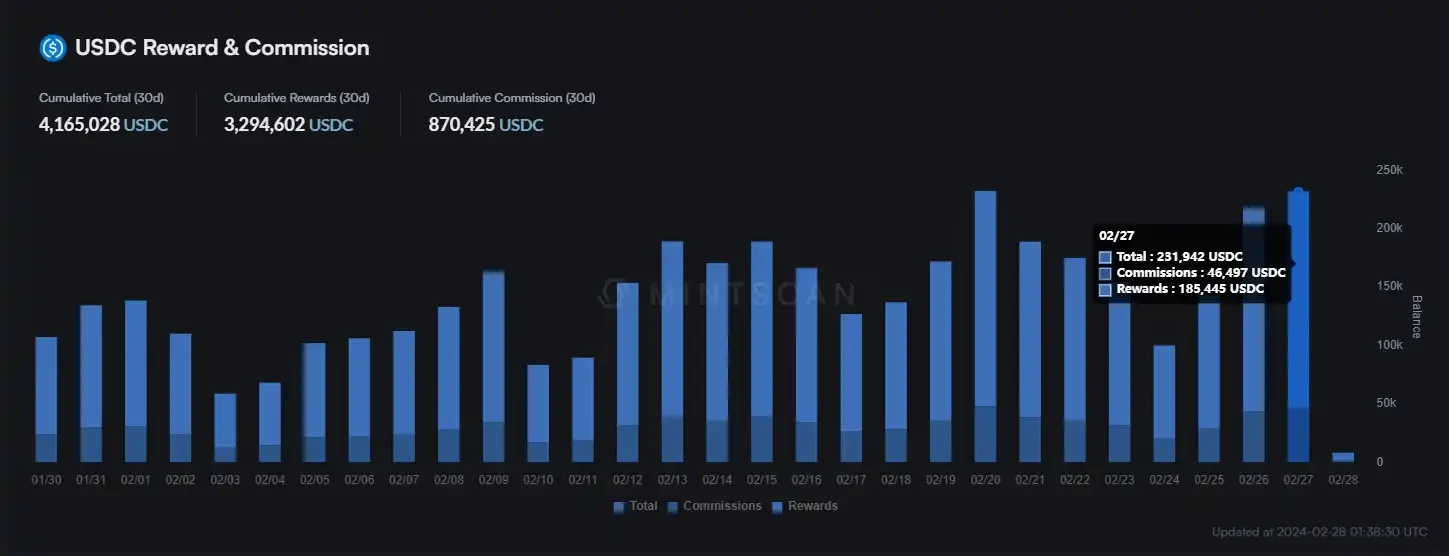
用户可以在此处查看到目前为止向质押者和验证者支付了多少奖励
由于质押者以 USDC 形式获得奖励,因此不必担心 DYDX 的波动性。
由于 dYdX 交易费用是质押奖励的来源,因此质押者不必担心 DYDX 代币的通货膨胀。
DYDX 代币持有者可以通过 Keplr 将 DYDX 质押在任意活跃的验证节点,可参考该链接查询
关于使用 Keplr 质押 DYDX 的可以参考:https://www.dydx.foundation/how-to-stake/keplr-user
截至目前,dYdX Chain 在上线不到 2 个月的时间内,已向超过 7, 500 名质押者发放了超过 200 万枚 USDC 的质押奖励。
使用 Ledger 安全地进行质押
质押意味着用户需要长期持有 DYDX,其中的安全问题非常重要,用户可以通过与 Keplr 集成的 Ledger 轻松质押 DYDX。
以下是有关如何将 Ledger 与 Keplr 集成的说明:https://support.ledger.com/hc/en-us/articles/4411149814417-Set-up-and-use-Keplr-to-access-your-Ledger-Cosmos-Ecosystem-Accounts?docs=true
使用 Stride 进行流动性质押(即将推出)
DYDX 代币持有者可以使用 https://app.stride.zone/ 将其 DYDX 在 Stride 进行流动性质押。作为交换,持有者将收到 stDYDX,这将使他们能够继续获得质押奖励,同时保持代币的流动性。这将使用户能够灵活地同时获得质押奖励并在 DeFi 协议中使用这些代币,或者立即退出头寸,而无需等待 dYdX 的 30 天的质押取消期。
在此处查看更多信息:https://dydx.forum/t/announcing-stdydx-and-stride-s-initial-host-chain-validator-set/1960





