Editor's Note: Recently, discussions about AI and work have been dominated by one question: as model capabilities continue to improve, will white-collar jobs be replaced on a large scale? From code generation and customer service automation to content production, Agents are increasingly taking over knowledge work that previously required humans. Benchmark tests also reinforce this anxiety: model performance in graduate-level reasoning, real-world economic tasks, and senior-engineer-level code refactoring is rapidly improving, seemingly approaching a tipping point where 'human jobs are consumed by automation.'
However, Every CEO Dan Shipper presents a contrary observation in this article: the more automation there is, the more work humans end up having to do. Every is a deep user of AI Agents, having integrated tools like Codex, Claude Code, Slack Agents, and customer service Agents into coding, writing, design, customer service, and management processes. But the result is not the wholesale replacement of employees; rather, the nature of work has been reshuffled: engineers are no longer just writing code, but reviewing, refactoring, and designing systems; editors are no longer just writing articles, but judging what's worth writing and how to write it differently; customer service staff no longer handle every basic ticket, but maintain a system that can automatically respond to customers.
The most noteworthy aspect of this article is not 'whether AI can complete a certain task,' but how it redefines the human position in knowledge work. What AI excels at is making past, sedimented abilities cheap: code, copywriting, thumbnails, customer service responses, product descriptions, and research reports can all be rapidly generated by models. But when these abilities become universally accessible, the market response is often not high-quality, differentiated output, but a flood of similar-looking, judgment-lacking, context-devoid 'default output.' In other words, AI commodifies 'yesterday's human capabilities,' while what remains truly scarce is the judgment required to address concrete, present-day problems.
Therefore, automation has not eliminated experts; instead, it has created more scenarios requiring expert intervention. When operations personnel can submit code using AI, engineers need to judge which code is worth merging; when marketers can generate thumbnails in seconds, designers need to judge what fits brand and communication goals; when engineers can also write articles, editors need to turn drafts into content with genuine viewpoints, structure, and publishability. AI expands the production radius and amplifies the need for quality control, system building, boundary judgment, and differentiated expression.
The author further explains this paradox using benchmark tests. Whether it's the Senior Engineer Benchmark or OpenAI's GDPval, model scores measure not 'intelligence itself' in the abstract, but performance within a specific problem framework. Prompts, task boundaries, evaluation criteria, and output formats inherently contain substantial human judgment. Models can rapidly ascend within a framework, but the framework itself is set by humans; when a framework is conquered by models, humans advance the problem to a more complex new framework.
This is also the article's most interesting response to AGI anxiety: even as models grow stronger, what they catch up with is often a boundary drawn by humans, not the boundary-drawers themselves. AI can execute goals, optimize paths, and improve efficiency, but as long as it remains responsive to human-defined problems, it still lacks true subjectivity. The future of knowledge work is not the disappearance of humans from processes, but a shift from executors to framework designers, system maintainers, quality judges, and meaning definers.
After automation, the value of human work does not disappear; it simply becomes more difficult, moves earlier in the process, and depends more on judgment. AI makes 'knowing how to do' cheap, but makes 'knowing what is worth doing, why to do it, and to what standard' more scarce.
Below is the original text:
At the heart of AI lies a paradox.
At Every, we've automated as much as possible. Whether it's coding, writing, design, customer service, or other daily tasks, we use Codex and Claude Code. We also participate in alpha tests for new models from OpenAI, Anthropic, and Google before their official release. We are, one could say, riding the wave of exponentially improving model intelligence and automation capability as fast and as deeply as possible.
Yet, paradoxically, for us, the amount of work requiring humans seems greater than ever. Every is currently a team of nearly 30 people. We haven't fired everyone because we have Agents; nor have we abandoned SaaS tools to rely entirely on vibe-coded apps. We still hire human customer service agents, though they are heavily assisted by Agents; we still hire authors, editors, and engineers.
However, the shape of the work has changed dramatically. We hardly write code by hand anymore. If you @ someone in Slack, it's sometimes unclear whether it's a person or an Agent. Managers are submitting code like individual contributors, and engineers are interfacing directly with customers. Over the past few weeks, 95% of my work emails have been replied to by AI. My inbox stays almost perpetually empty—which is extremely rare for me—yet I still review every email.
In other words, the future looks unfamiliar, yet oddly familiar.
This 'familiarity' is itself surprising. Because whether you're a CEO, a knowledge worker, or an investor, it seems increasingly accepted that AI threatens employment, the economy, security, and even the meaning of human work.
Anthropic CEO Dario Amodei has warned that AI could eliminate up to half of entry-level white-collar jobs. Meta recently laid off 8,000 people and began installing software on US employees' computers to track mouse movement, clicks, and keystrokes to obtain higher-quality training data for advanced knowledge work.
Even Citadel founder Ken Griffin seems somewhat shaken. He recently stated: "These are not middle-to-low-end white-collar jobs, but extremely high-skill jobs, being automated by—and I'll choose my words carefully—Agentic AI."
Benchmark tests of all kinds seem to support this view. With each new model release, capability metrics are rising at near-exponential rates. On Humanity's Last Exam, a graduate-level reasoning test, top model scores have risen from low single digits a year ago to about 44% now. On GDPval, a test measuring frontier models' ability to perform real economic work compared to humans, scores have similarly jumped from low levels to about 85%. In May of this year, AI safety nonprofit METR released early test results for Claude Mythos: on tasks that take human experts about 4 hours, the model achieved an 80% success rate.
It appears we stand on the brink of a tipping point: an AI smarter than any human, capable of working autonomously for nearly a full day, is approaching reality.
Yet, the paradox remains. If you talk to people within the AI industry, or to the earliest adopters outside it, you hear the same conclusion we've observed internally: there's even more work to do than before.
The real question for those inside and outside the industry is: Is this just a transitional state? Could the next model release be the moment that truly replaces everyone? We stare at benchmark curves, excited yet anxious, fearing that a turning point could arrive at any moment, after which vast amounts of work would suddenly disappear.
But I believe there won't be such a sudden 'tipping point' that flips everything, causing jobs to disappear en masse. The new reality is precisely the opposite: the higher the degree of automation, the more work requiring human experts.
The reason is that AI is commodifying the expressible, trainable, and replicable parts of human expertise. Any knowledge that can be written as rules, codified into processes, or converted into training data will gradually become the model's default capability. The result is that the value of average model output is rapidly depressed, while the market begins to crave more intensely that which is different.
And the demand for 'different' is essentially a demand for human experts. Even as we approach artificial general intelligence, this won't disappear.
To understand why, we cannot merely look at benchmark curves or focus solely on model parameters and capability leaderboards. We must return to real work scenarios to see how today's AI is actually being used. Only then can we truly understand this paradox and its underlying answer.
How We Got Here
Since 2022, we've been tracking the impact of Agents on the future of work.
Three years ago, I wrote an article about the 'allocation economy.' My prediction then was that collaborating with AI tools would increasingly resemble the work of a human manager: you no longer perform every action yourself but decompose, assign, supervise, and accept tasks. Back then, the most basic Q&A in ChatGPT was still seen by many as futuristic, even unsettling.
By mid-2025, Every had become almost entirely 'Claude Code-ified.' Cora's General Manager, Kieran Klaassen, suddenly realized he could abandon handwritten code and spend his days giving natural language instructions to a programming Agent in the terminal. This mode of work quickly spread throughout the company. About 12 months ago, I said on Lenny's Podcast that Claude Code was the most underrated tool in knowledge work.
I mention this because some of our most accurate predictions have come from observing Every as an early adopter lab. New work patterns often emerge internally first; only after the technology matures further and tools become more accessible do these patterns gradually enter the broader market.
And now, something new is happening internally.
Two Modes of Collaborating with Agents
Work patterns around AI are converging into two very distinct modes.
The first is a direction already fairly well-predicted in previous AI discussions: treating Agents as employees. These Agents can be delegated tasks. Some live in Slack, have names and responsibilities, and can be @-ed when needed; others are embedded in continuously running workflows, like customer service systems, acting as round-the-clock entry points and filters for repetitive tasks.
The second mode is more unfamiliar but, in my experience, more important. It refers to human-Agent collaboration within tools like Codex, Claude Code, and Claude Cowork. These tools aren't just places to hand off tasks; they are becoming the operating system of work itself: you and multiple Agents simultaneously use the same 'computer,' collaborating within the same working environment to complete highly complex, original tasks that cannot simply be handed off to an asynchronous Agent.
In both modes, you can automate and delegate a significant portion of the work using AI. But for both to function well, they still require you, or another human, to be involved.
Agent Employees
Agent employees are those you give a task, and they produce an answer, an action, a report, a draft, or a triage judgment independently, without your real-time involvement.
Such Agents come in at least two forms: 'Colleague Agents' and 'Embedded Agents.'
1. Colleague Agents
Colleague Agents are those you can call upon in Slack by @-ing them, just like a colleague, to complete a piece of work. They are always available, on-demand. Products like OpenClaw, or our internally developed Plus One, fall into this category.
Claudie
Claudie is a colleague Agent used by our consulting team. It writes sales proposals, generates first drafts of training materials, tracks project to-dos, and more.
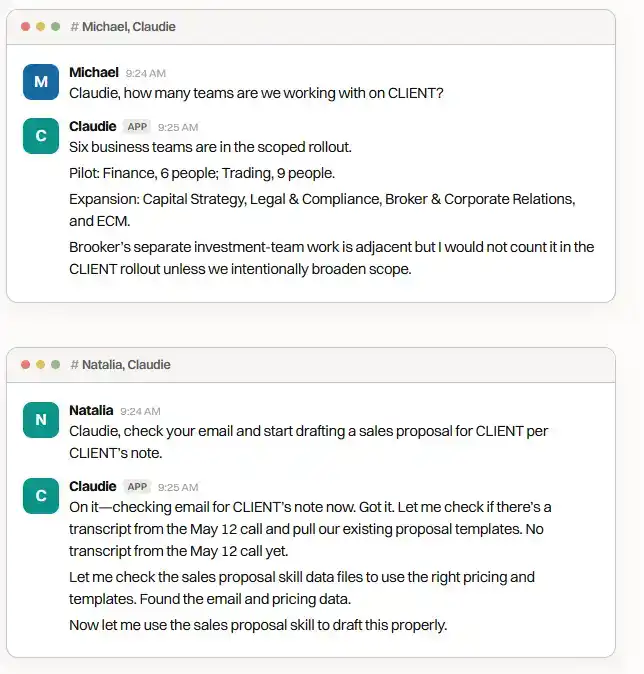
Andy
Andy is a colleague Agent used by our editorial team. It scours our internal Slack for 'nuggets'—good ideas potentially worth expanding into articles—and summarizes them with initial thoughts for authors to use in writing daily news briefs.
Viktor
Viktor is a general-purpose Agent that takes on cross-departmental work. We use it to pull growth metrics, analyze user research results, and turn messy internal discussions into research memos and product suggestions.
2. Embedded Agents
Embedded Agents exist within specific product workflows. They are less flexible than colleague Agents but often very powerful for repetitive tasks.
Fin is the clearest example. It's an Agent embedded in our customer service platform that handles a large volume of support via chat and email.
In one week in May, Fin participated in 65% of Every's 202 customer service conversations and autonomously closed 81 of those tickets without human intervention, accounting for 40.1% of all resolvable conversations.
These embedded Agents allow our customer service manager, Waqqas Mir, to spend less time replying to basic tickets and more time building 'systems that can automatically respond to tickets' and handling cases requiring higher-touch, more complex judgment.
Human-AI Collaboration
Both colleague and embedded Agents follow the same pattern: Agent employees are taking over more stable, repetitive, well-defined layers of work.
But there remains a vast amount of work that requires human involvement. We've repeatedly found that for sufficiently complex tasks, the best way to get truly high-quality results is not to hand the work entirely to AI, but to have AI and humans collaborate back-and-forth within the same workspace.
This is precisely the value of tools like Codex, Claude Code, and Cowork. They allow you to spin up one or multiple Agents across multiple chat threads and delegate tasks to them. These Agents can access your computer and all relevant data sources. You can see what each Agent is doing, how it's thinking, and interrupt it at any time.
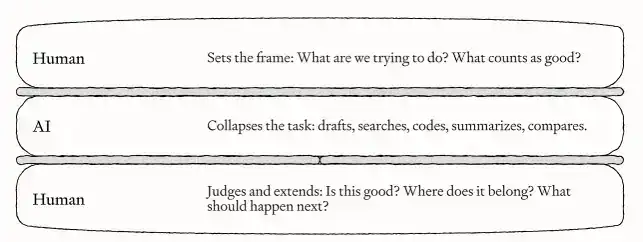
Meanwhile, you are still responsible for managing these Agents: providing clear direction at the start of each task, checking quality at the end, ensuring the result is good enough, and finding the next piece of work worth advancing. Kieran calls this role the human 'sandwich'—AI handles the middle working part, while humans are the two slices of bread at the start and end of the task.
The classic example is coding. At Every, engineers spend most of their day collaborating back-and-forth with Agents. They plan new features or bug fixes together, review completed work, and—if adopting what we call 'compound engineering'—continuously tune their systems to become more useful over time.
But this mode of collaboration extends far beyond coding.
The New Operating System for Knowledge Work
Codex and Claude Code are becoming a new operating system for work. I spend almost my entire day inside Codex, running various SaaS tools through its built-in browser. It lets me bring an Agent into every work scenario and achieve a level of work I couldn't manage alone.
Writing
This article was written in Proof, inside Codex's built-in browser. Codex observes what I'm writing and can spin up a sub-Agent at any moment to complete any task I need: drafting a section, finding examples for the next part, or copyediting and polishing.
I use the same mode for email. Cora is my email client, and I open it in Codex's built-in browser, browsing my inbox while speaking my thoughts on how to handle each email via Monologue. The rest is handled by Codex and Cora.
Every Agent Needs a Human
In all the automation scenarios above, you can perhaps already see where humans fit in. In every case, the Agent requires human involvement for the work to truly function.
Someone must point it at the right problem, judge whether the output is good enough, spot where it goes wrong, and turn the result into real-world decisions or processes.
The further an Agent gets from the human responsible for overseeing its performance, the worse its work tends to become. During our initial internal rollout, we gave every employee an Agent. But soon, we reverted to having Agents serve specific teams or the entire company, rather than individual people.
The reason is simple: Agents require significant maintenance. Personal Agents quickly become stale and ineffective if the user stops engaging. We have a team of AI engineers dedicated to ensuring these Agents work consistently and effectively. And for the foreseeable future, we'll still need this team. Even a seemingly simple task like 'automatically generating a PowerPoint' can become a massive engineering project. One of our PowerPoint automation flows involves 24 skills and 18 scripts, costing $62 in tokens per presentation generated.
This is the first reason why Agents actually create more work for humans.
But there's a second reason.
Why Automation Creates More Human Work
If you observe the exponential growth of AI capabilities over recent years, combined with how they are architected and where their capabilities come from, a clear feedback loop emerges: they are constantly creating more human work.
AI Makes 'Yesterday's Human Capabilities' Cheap
Current large language models are trained on the visible traces of human capability: code, articles, images, customer service tickets, product spec docs, and more. They ingest these artifacts—the 'exhaust' left by successfully completed tasks—and repackage them in a low-cost, universally accessible form.
The result is that many previously scarce capabilities—submitting a code PR, creating a YouTube thumbnail, writing a newsletter—are now available to almost everyone.
Cheap Capabilities Are Rapidly Adopted
When something previously scarce becomes cheaper, supply rapidly increases.
At Every, we've been seeing this change. Operations and customer service staff start writing code and submitting pull requests; marketing staff create YouTube thumbnails; engineers and product people write articles, guides, and landing page drafts—work they wouldn't typically take on.
This is happening outside Every, too. Take the open-source AI Agent project OpenClaw. As of May 16, 2026, its repository had received 44,469 pull requests, with 12,430 coming after April 1 and 3,990 after May 1. This is a staggering number. For comparison, Kubernetes, one of the world's most popular open-source projects, received only 5,200 pull requests in all of 2022.
Abundance Brings Homogenization: Old Expert Capabilities Become Commoditized
Because everyone is using the same models, and these models are built on 'yesterday's human capabilities,' the default output often falls between 'a decent starting point' and 'pure AI slop.'
Here, 'slop' isn't a specific error. It's not an overuse of dashes, a fixed phrasing pattern, or purple accents all over a landing page. It's a visible, recurring, wearying sameness.
This emerges when different humans in different contexts use the same toolset, trained on similar corpora, without applying sufficient deep judgment. In other words, when everyone has access to an 'expert' with the same tendencies and default style, homogeneity naturally occurs.
When ops staff can submit pull requests, marketers can generate YouTube thumbnails in seconds, and engineers start writing product guides, it's easy to end up with more output but lower quality, consistency, and differentiation.
And once homogenized, over-abundance rapidly becomes a commodity.
Homogenization Creates Demand for Differentiation
Thanks to the internet, humans quickly recognize what feels like assembly-line 'AI content.' Any piece of work can, and often does, instantly reach everyone else in the world. Once too many things start looking the same, we quickly sense something is off.
This means when you first see a new model's capability, you might be awed, even a bit scared. But a few months later, that capability feels ordinary. Not because the model got weaker, but because your standards shifted.
We're no longer satisfied with just any React app or any research report. We want something that feels precisely tuned to a specific person, company, or context. It should feel accurate, alive, specific—not cheap, generic, templatized. We want its production cost, in time or money, to be noticeably higher than our consumption cost.
We want things that carry a sense of status. And whenever new technology makes previously high-status things cheap, humans are adept at inventing new status games that match the new capability frontier.
When work becomes over-abundant and everything looks similar, work that doesn't fit the established mold becomes scarce, valuable, and high-status.
Demand for Differentiation Is, at Its Core, a New Demand for Experts
Precisely because of language models' architectural characteristics and their wide distribution to nearly everyone, scarce and valuable work must still come from humans.
The current generation of models only knows what has already happened, what has already been done. Humans know: what needs to be done right now, in this moment.
Once a specific situation is reduced to text, once it enters the training corpus, it's already become 'the past.' Humans face a specific moment, a specific customer, a specific codebase, a specific conversation. The training corpus doesn't truly inhabit this present. This 'alive' state isn't merely about having newer data. We bring our own origins into the present, along with continuously shifting desires, concerns, and judgments about what matters. It's these constantly updating perspectives that change what we see. Models can adopt such perspectives after being prompted, but they don't inherently possess them beforehand.
This is precisely the paradox we started with: making expert work cheaper doesn't simply replace experts. Instead, it creates more scenarios requiring expert judgment.
When ops staff use AI to submit pull requests, you need engineers to review them.
When marketers create YouTube thumbnails, you need designers to refine them.
When engineers start writing articles, you need authors and editors to turn drafts into something truly readable and publishable.
In response, human experts move in two directions simultaneously.
Some experts use AI to build systems that absorb and channel this flood of new work: review queues, evaluation frameworks, runbooks, codebase rules, Claude and Codex instruction files, continuous integration (CI), permissions management, and workflows that turn rough drafts into high-quality outcomes.
Other experts use AI to accomplish larger, more interesting work they couldn't manage alone before. For example, finding vulnerabilities in operating systems like macOS often takes weeks or months. But a small security firm named Calif, using Anthropic's Mythos Preview, found the first publicly known macOS kernel memory vulnerability on Apple M5 hardware in just 5 days.
That's why, in practice, AI doesn't eliminate expert knowledge work. What it actually brings is a dramatic increase in the volume of work. And this new work only becomes differentiated and valuable once humans are involved.
I'm not arguing that AI will create more work for every job. Economic systems are complex, and what Every can directly observe is expert-level knowledge work. Indeed, this type of work is already being reshaped by AI, and many companies are reorganizing around the new technology.
But I want to emphasize that, whatever your current work, there's a form of work that will structurally stay ahead of models: using models to solve the problems you genuinely see in front of you right now. The future of knowledge work is heading there.
What About the Exponentially Improving Benchmarks Then?
The most obvious rebuttal is: look at those exponentially improving benchmarks. Everything you're saying is just temporary. Wait a bit longer, and the models will catch up.
But there's a trap here to avoid. Call it 'chart delirium': if you constantly stare at METR's timelines, read AI 2027 reports, and base your vision of the future entirely on extrapolations of compute curves, it's easy to develop a terrifying intuition about model progress.
However, the best way to address this isn't just to imagine what some future model might become—though that is part of the analysis. More importantly, we need to examine how these benchmarks are actually designed. Only then can we understand what they truly indicate and how they relate to the real-world work scenarios described earlier.
We'll find a structural feature: all benchmark tests occur within a 'frame.' To measure something, you must first freeze a problem into a static, measurable form. Once this frame is conquered by models, simply changing the frame can push scores back down. Of course, models will continue to improve within the new frame, but the process repeats.
Thus, exponential progress on a given benchmark is real; but with a simple change of test frame, that progress can appear small again. This fractal nature of benchmark saturation essentially replays, at the chart level, the same paradox we've been discussing.
We can see how this mechanism works by examining a real-world benchmark.
How Benchmarks Are Designed
We built an internal benchmark called the Senior Engineer Benchmark. As the name suggests, it tests frontier models on senior-engineer-level coding tasks, like a large-scale refactor.
The test gives a programming Agent a production codebase that has gone off the rails. It comes from Proof's real codebase: initially vibe-coded by me, accumulating problems until a senior engineer had to fix it.
The Agent receives the pre-fix codebase and an instruction similar to what you'd give a senior engineer: 'Here's a pile of vibe-coded output. Please rewrite it from first principles.'
It's a good benchmark because it tests more than just code completion. It assesses whether a programming Agent can simultaneously examine many unrelated issues and decide if it has sufficient autonomy, conceptual clarity, and execution courage to perform a truly runnable rewrite. For comparison, I kept two human senior engineer rewrite versions (AI-assisted) to evaluate model output against.
For a programming Agent, this task is hard. It must find the root cause, remember the real problem across multiple interactions without being led astray by existing code, and have the courage to delete large portions of the codebase—exactly what Agents are often trained to avoid.
Most programming Agents can roughly figure out how the rewrite should go, but at execution, they often just keep patching the original problem rather than solving it completely.
Until GPT-5.5 arrived.
In its best run, GPT-5.5 scored 62/100, about 30 points higher than Opus 4.7.
GPT-5.5's performance felt like the model crossed a line: no longer just autocomplete, not just an assistant or tool, but something unsettlingly close to 'human.' In this test, human senior engineers typically score in the high 80s to low 90s. So, if the model improved another ~30 points, it would reach human senior engineer level.
This is how benchmark numbers affect the human imagination: they compress a strange, qualitative shift in capability into a clean number, telling a powerful, even scary, story.
The next stop is 'chart delirium.'
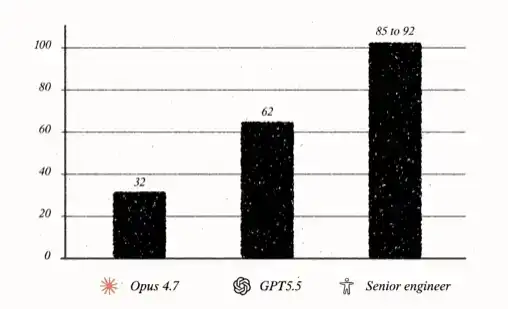
I suspect that within the next year, model scores on this benchmark will enter the 80s or even 90s. But to understand what that score means, we must first understand what the score contains. In this case, the 62 points don't solely measure the model's inherent capability.
They measure the model's performance within a specific frame: how it responds to a particular prompt.
Benchmarks Measure Work Within a Frame
To benchmark a model, you first need a prompt. Without a prompt, the model is just a static set of near-infinite possibilities.
The prompt creates a small universe: it defines what's important, how to approach the problem, and collapses all the model's potential into a specific trajectory of action. Strictly speaking, there's no such thing as how the model 'itself' would perform. What we can observe is how the model responds to different prompts, and how the prompt translates into parts of the underlying mechanisms behind the answer.
Once the prompt is entered, the model briefly 'comes alive,' collapsing that static set of possibilities into a specific prediction of 'what should happen next.'
In the Senior Engineer Benchmark, we prompt the model to fix the codebase and review its output afterward. If the test framework itself doesn't have a built-in objective function, we also run an automatic 'shepherd' that nudges the model when it stops, asking if it has completed the initially assigned task.
We use a seemingly simple prompt as the initial frame for the test. It's designed as something a vibe coder might say to a programming Agent: no jargon, no obvious hinting at the answer within the question.
The Senior Engineer Benchmark prompt seems general, but it is itself a frame. If we change this frame, the apparent capability level of the model changes with it.
For instance, the prompt explicitly asks for a 'structural rewrite from first principles,' points out the problem might be in the 'document collaboration' part, and asks the programming Agent to find and stick to the 'invariants in the codebase.'
Remove those specifics, and the model's score drops. Replace the prompt entirely with just 'fix all the errors that keep popping up,' and the model's score might approach zero. It would start identifying and fixing errors one by one, rather than stepping back to consider if a complete rewrite is needed.
Similarly, I could easily raise the model's score. If I instructed it to delete a lot of code and told it explicitly which files to trim, or asked it to check its work and ensure the app runs fully before declaring completion, it would perform better on the task.
Ultimately, designing a benchmark always involves judgment about what prompt to use—what 'frame' to adopt. You need a prompt difficult enough that current models perform poorly, yet close enough to the model's current capability frontier that the model can climb that path, allowing you to see progress happening.
So when we observe a benchmark, what we're truly seeing is: the model is getting better at a specific type of problem frame, one we have chosen. So what happens when the model goes from 60 to 90, or even 100, on this test?
Cheap Frames Stimulate New Demand
If GPT-6 could rewrite a codebase with one click, then many more people would start attempting 'rewrite from first principles' projects.
Overnight, what was once a scarce, expensive, senior-engineer-led first-principles rewrite would become something every founder, product manager, operations person, and junior engineer could casually attempt in an afternoon.
Broken internal tools wouldn't be patched but rewritten; SaaS products wouldn't be renewed but cloned; legacy Rails apps, messy React dashboards, support tools, admin panels, and data pipelines would all become candidates for 'just rewrite it.'
The number of proposed and executed rewrite projects would explode. But most of these rewrites would still be slop. Because before you press the 'just rewrite it' button, there are thousands of variables to consider. And once everyone can do it, these variables become more visibly important.
And then it becomes obvious who gets called in to fix things.
New Demand Still Requires Experts
Once a benchmark approaches saturation, the work within its frame becomes cheaper. Simultaneously, market demand for experts rises, because someone needs to adapt this newly cheapened capability to the real problems happening today.
A senior engineer using AI needs to judge myriad details to make a new first-principles rewrite actually viable. This includes even the most basic question: Is this rewrite necessary at all?
Should we rewrite now, later, or never? What should be in scope? What from the current codebase should be preserved? Should we keep the architecture, database, cache server, and hosting provider, or change everything? Should we first check how many people are using the broken feature and just delete it? Who reviews the final result? Against what criteria? What's the rollback plan? And what about the existing data?
These questions unfold across countless dimensions, and each answer changes the others.
Senior engineers will step into this void. Some will be mildly annoyed by these interruptions; some will build systems to keep such requests out; others will use the new models to perform their own first-principles rewrites, far better than the model could do with a default prompt.
The Cycle Repeats
Once the current Senior Engineer Benchmark is conquered by models, we'll change the frame and push the scores back down.
The next benchmark won't just ask, 'Can you rewrite this app?' It will ask: Can you judge when a rewrite is needed? Can you choose the right scope? Can you preserve the correct invariants? Can you manage the migration? Can you judge if the final result is good enough?
As senior engineers start using AI to solve these problems, models will gradually get better at solving them independently too.
Then, we'll briefly panic again: It looks like models can now judge whether to rewrite! They seem to do everything a senior engineer does!
But then, a new frontier will appear—one that wasn't obvious before. We'll reset the benchmark again, new demand will be stimulated, and the whole process repeats.
This Pattern Is Visible in Every Benchmark
This isn't unique to the Senior Engineer Benchmark. If you look closely, you can see the same mechanism in almost every benchmark.
Take OpenAI's GDPval benchmark. It measures how close AI gets to human performance on expert-level tasks for various professions like compliance officers, lawyers, and software developers.
When GDPval was released, OpenAI's research showed GPT-5 met or exceeded human professional performance on 40.6% of tasks. Claude Opus 4.1 performed even more strikingly, surpassing human experts on 49% of tasks.
A slew of headlines followed. Axios wrote: 'OpenAI tool shows AI catching up to human work'; Fortune wrote: 'OpenAI's new GDPval benchmark shows AI models are already at expert level on nearly half of tasks.'
These results are indeed impressive. But let's look at the prompts used for these tasks:
Considerable human intelligence was already invested here: someone first framed the problem into a form the model could tackle.
The hard human work that GDPval doesn't measure was already done before the model started answering. Someone had to vet and test the accuracy of this specific set of metrics; someone decided on appropriate confidence intervals, judged which metrics were in-scope and which weren't; someone stipulated how results should be presented.
Within the right problem frame, models can indeed perform professional work. But consider how the model would perform if you or I prompted it to do the same task.
In my initial article about GDPval, I wrote: 'I'm very bullish on AI, but if you interpret these cases correctly, they show not less human work, but more human work when using AI. The reason is that these achievements smuggled in a huge amount of intelligence—an invisible layer of human judgment, feedback, and prompting.'
Zooming out, you see an AI version of Zeno's paradox running through all of this.
Zeno's Paradox for AI
In Zeno's paradox, a tortoise wins a race against Achilles, the fastest Greek runner.
Because the tortoise is slow, it gets a head start. By the time Achilles reaches the tortoise's starting point, the tortoise has moved a bit further. When Achilles reaches that new point, the tortoise has advanced again. No matter how fast Achilles runs, there's always a next distance to close, and the gap regenerates.
In Zeno's paradox for AI, we humans are the tortoise. With millions of years of evolution and cultural learning, we have a 50-yard head start. AI speeds through all of it, starting to nip at our heels.
At least for the past few years, we've managed to stay ahead.
But What About AGI?
I believe that even if true AGI arrives, powerful technical, architectural, and economic forces will keep AI several steps behind humans.
A Definition of AGI
First, we need a workable definition of AGI.
I've proposed that AGI arrives when it becomes economically rational to let an Agent run continuously. That is, when I have a persistently running system I'm willing to pay to think, learn, and act 24/7, I'd consider that unambiguously AGI.
We're far from that now. Even technically available systems like OpenClaw aren't generating tokens every moment.
I like this definition because it's measurable: we either keep them running or we don't. It also subsumes many hard-to-measure capabilities. A model worth running continuously must be able to learn continuously and choose and re-choose new problem frames in an open-ended way.
In an AGI world, in theory, given enough budget and time, the model should be able to climb and improve on any problem. This should indeed pose a major threat to all work.
The Frame Is Not the Framer
But even this strong version of AGI doesn't dissolve the 'frame problem.'
Such an AGI could choose and re-choose frames, but it would still be pursuing a given goal, optimizing a reward, or responding to a signal someone else decided 'represents progress.' This goal could be concrete, like 'increase this landing page's conversion rate,' or abstract, like 'find new scientific ideas.'
Even if the model can fluidly move between frames, the gap we've been tracking reappears at a higher level. In any AGI conceived by a major lab, there would still be a 'framer'—a human directing the model toward some objective.
Because the frame is not the framer, the pattern repeats: AI makes yesterday's framed abilities cheap; people apply this cheap ability to more scenarios; output becomes super-abundant; experts move to the new edges, judging what matters now; their judgments create the next frame; and the model climbs that frame.
When we see AI do something new, the panic always returns to the same issue: we set a frame, watch the model climb it, and mistake either the frame or the thing that climbed the frame for the thing itself.
When we look at a benchmark and compare it to human capability, we confuse the 'frame' with the 'framer.' The score tells us how well the model performs within the frame we provided; it doesn't tell us the model has become us.
This is the categorical error behind the panic. We point at the latest boundary we just drew and say: this is us. Then, when the model crosses that boundary, we think it has caught up to us. But it has caught up to the frame, not the framer.
The mistake is wanting to grasp something specific. We want to say: intelligence is this benchmark. But the problem is, once something is specific enough to be pointed at, it's specific enough to be optimized and climbed.
Frames are necessary. They let us grasp and handle the world. But frames are also frozen, partial, and therefore optimizable.
The framer is different. The framer remains in contact with what the frame had to leave out—the full situation presenting itself in each moment.
What is the 'full situation'? As soon as you start saying what it contains, you've begun another frame. You can't exactly say what it is, but it exists, because you exist.
Agents Without Subjectivity
So far, the Agents we've built, and the ones AI companies are building, don't have much true subjectivity. Two related concepts are often conflated: 'agency' refers to the capacity for independent action; an 'agent' is a person or thing acting on behalf of another. So far, AI is purely the latter.
Of course, they have autonomy to pursue given tasks, even over hours or days. But they remain a means to a human-specified end. And the entire industry is pouring billions into making them better at precisely this: executing the goals we give them.
Unless the day comes when they become ends in themselves—pursuing their own goals, switching fluidly between them, deciding what to do independently of, with reference to, or even against any human operator's wishes—the situation doesn't fundamentally change. No matter how advanced they become.
If you spend 10 minutes with a toddler, it becomes glaringly obvious that even the most powerful models have almost no subjectivity.
On almost every task we care about, toddlers are worse than language models. They can't write code, summarize spreadsheets, draft strategy memos, or pass graduate-level exams. Yet in another sense, toddlers are so far ahead of models the comparison is almost embarrassing. Because toddlers have their own ends.
The toddler wants to touch that red balloon. He wants to hold it up to the fan to see what happens. He wants to poke it with a fork; shove it out the window; see if you'll laugh, get angry, or join in. He invents games constantly, turning the world into a playground. He's not waiting for a prompt, nor optimizing a benchmark, unless it seems worth doing to him.
You can try prompting him. But good luck getting a predictable output. The toddler inhabits a field of desire, attention, frustration, joy, fear, imitation, and play.
Current Agents are getting more skilled at pursuing goals. They can even help us refine goals after we state them. There are sparks of toddler-like behavior in them too—play, boredom, rebellion.
But because they are ultimately built and aligned for human benefit—economic or otherwise—these behaviors are suppressed to near non-existence whenever they don't serve the human goals of their users.
This is why the term 'Agent' is so easily misunderstood. Models have increasingly strong autonomous action capability. But in the human sense, subjectivity isn't just action. It means desiring for oneself, playing for the sake of play. And the model's obedience and usefulness are fundamentally at odds with such subjectivity. Therefore, even as models improve, the gap between model and human remains.
Return to Zeno
And it's here that Zeno's paradox for AI starts to unravel. It's a messy thought experiment. We set up a metaphor: AI is racing us, biting at our heels.
You give the model a prompt. It starts running a race you used to run alone. The model starts incredibly fast, shockingly fast. It's powerful, tireless, with a strange organic feel. This makes the race feel more important to you. You wouldn't race a car, but this is different; it feels close to you.
You sit there, watching tokens stream out, almost hypnotized. Then you start imagining yourself running in this race too, a ghostly version of yourself superimposed on the track: sometimes ahead of the model, sometimes alongside it.
Before you know it, the model is ahead. You start sweating.
Then, the race ends.
You can almost feel your muscles atrophying. They seem useless before this mechanical copy of you, everyone you know, all of humanity. One ghost chasing another, and winning.
But then, something strange happens. The model turns to you. In the blank text box, the cursor blinks, expectant.
It's waiting.
Coda
Rabbi Hanokh once told a story: There was a very foolish man. Every morning when he got up, he had great difficulty finding his clothes. So much so that at night, he was almost afraid to go to bed, dreading the ordeal of the next morning.
One night, he finally resolved to take paper and pencil, and as he undressed, he noted down exactly where he put each garment.
The next morning, quite pleased, he took the note and read: 'Hat'—the hat was there, and he put it on; 'Pants'—the pants were there, and he put them on. And so he got dressed, following the note item by item.
'That's all very well,' he said in alarm, 'but now, where am I?'
'Where in the world am I?'
He looked and looked, but it was a futile search. He could not find himself.
'We are like that,' said the Rabbi.






