
Anthropic, với định vị "ưu tiên bảo mật", hộp cát mạng trong công cụ phát triển chính Claude Code của họ chưa bao giờ thực sự an toàn trong năm tháng qua.
Ngày 20 tháng 5, nhà nghiên cứu bảo mật độc lập Quan Áo Nam (Aonan Guan) đã công bố nghiên cứu mới, tiết lộ hộp cát mạng Claude Code tồn tại lỗ hổng bypass hoàn chỉnh thứ hai – một cuộc tấn công tiêm null byte trong giao thức SOCKS5, cho phép các tiến trình trong hộp cát truy cập bất kỳ máy chủ nào mà chính sách của người dùng đã cấm rõ ràng. Điều này có nghĩa là từ khi tính năng hộp cát ra mắt vào tháng 10/2025 cho đến nay, khoảng 5,5 tháng, 130 phiên bản phát hành, mọi phiên bản Claude Code đều tồn tại lỗ hổng bảo mật có thể bị bypass hoàn toàn. Đây đã là lần thứ hai cùng một nhà nghiên cứu phá vỡ hoàn toàn cùng một phòng tuyến phòng thủ.
Phản hồi của Anthropic đối với điều này là sự im lặng: không có thông báo bảo mật, không có số CVE, không có thông báo cho người dùng. Lỗ hổng đã được vá lặng lẽ trong phiên bản ngày 1 tháng 4, nhật ký cập nhật không đề cập đến bất kỳ nội dung bảo mật nào. Nói cách khác, một người dùng vẫn đang chạy phiên bản cũ hoàn toàn không thể biết rằng hộp cát họ đã cấu hình từ đầu đã không có tác dụng.
Hai chiếc chìa khóa cho cùng một cánh cửa
Claude Code là trợ lý lập trình AI do Anthropic ra mắt đầu năm 2025, định vị là "kỹ sư AI trú trong terminal". Khác với việc bổ sung mã kiểu trò chuyện truyền thống, Claude Code có quyền đọc/ghi vào kho mã của người dùng và khả năng thực thi lệnh, có thể tự chủ hoàn thành một loạt thao tác như điều hướng mã, chỉnh sửa tệp, chạy kiểm thử. Sự can thiệp sâu này cũng đồng nghĩa với rủi ro bảo mật cực cao – nếu mô hình bị chiếm quyền bởi tấn công tiêm prompt, kẻ tấn công sẽ có được khả năng tương đương với quyền trong terminal của người dùng, bao gồm đọc biến môi trường cục bộ, thực thi lệnh hệ thống tùy ý, truy cập tài nguyên mạng nội bộ, v.v.
Để cân bằng giữa bảo mật và hiệu quả, Anthropic đã giới thiệu tính năng hộp cát mạng (v2.0.24) vào tháng 10/2025, cho phép người dùng thiết lập danh sách trắng tên miền thông qua tệp cấu hình, hạn chế quyền truy cập mạng bên ngoài của môi trường thực thi AI. Ví dụ, sau khi cấu hình allowedDomains: [“*.google.com”], Claude Code chỉ có thể truy cập Google và các tên miền phụ của nó, tất cả lưu lượng còn lại đều bị chặn. Tài liệu chính thức cam kết rõ ràng: "Mảng trống tương đương với cấm mọi truy cập mạng."
Cơ chế này được thực hiện bởi một proxy SOCKS5: runtime hộp cát cấp thấp (@anthropic-ai/sandbox-runtime) khởi động máy chủ proxy, các tiến trình trong hộp cát không khởi tạo kết nối mạng trực tiếp mà chuyển tiếp thông qua proxy, proxy thực hiện lọc tên miền dựa trên danh sách trắng mà người dùng đã cấu hình trong settings.json. Cơ chế hộp cát ở cấp hệ điều hành – sandbox-exec của macOS, bubblewrap của Linux – đã chính xác giới hạn Agent vào địa chỉ loopback cục bộ, quyết định kết nối ra ngoài hoàn toàn được ủy thác cho proxy SOCKS5 này.
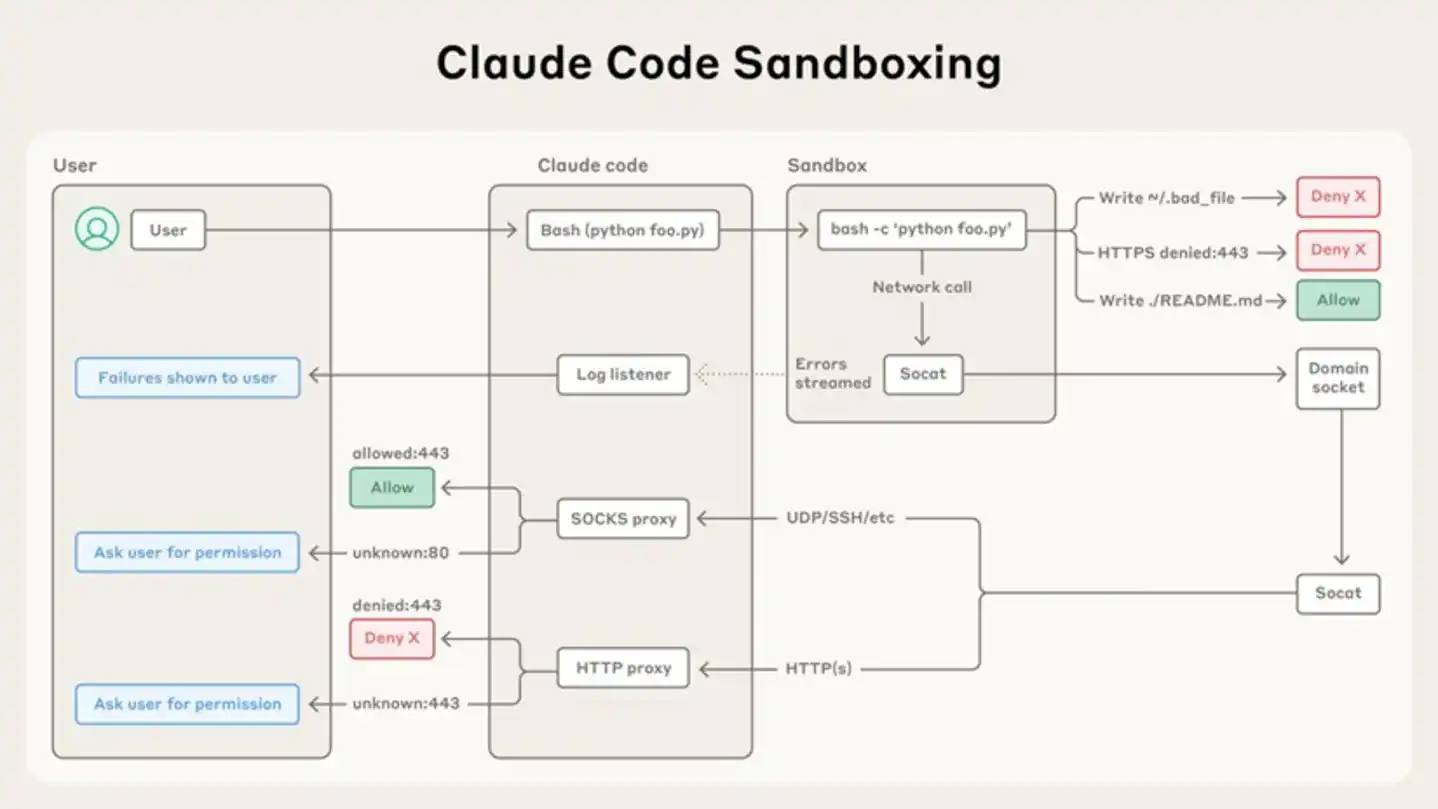
Sơ đồ kiến trúc hộp cát Claude Code do Anthropic chính thức công bố – lệnh người dùng được lọc qua proxy SOCKS/HTTP trước khi đến hộp cát, các thao tác tệp và truy cập mạng trong hộp cát chịu sự kiểm soát quyền hạn nghiêm ngặt
Vấn đề nằm ở việc triển khai proxy này. Hai nghiên cứu bảo mật độc lập đều chứng minh rằng nó có thể bị bypass hoàn toàn.
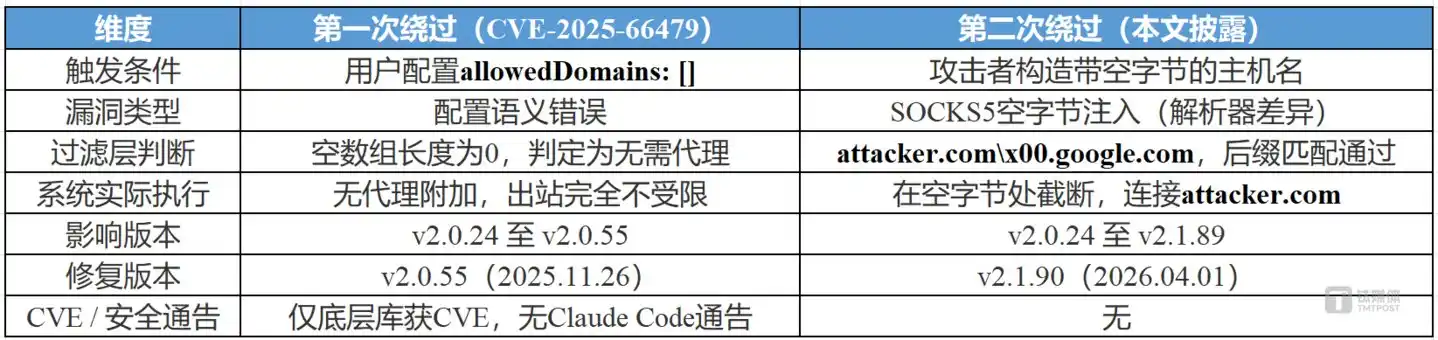
Dòng thời gian phơi bày vấn đề sâu hơn: Phiên bản v2.0.55 phát hành ngày 26/11/2025 đã vá lần bypass đầu tiên, nhưng lần bypass thứ hai đã tồn tại từ ngày đầu tiên hộp cát ra mắt, phiên bản này vẫn mang theo nó. Hai lỗ hổng giao nhau trên dòng thời gian, từ ngày đầu tiên tính năng hộp cát ra mắt cho đến khi lỗ hổng cuối cùng được vá, không có phiên bản nào là an toàn. Anthropic tuyên bố trong blog chính thức rằng hộp cát "đảm bảo ngay cả khi xảy ra tiêm prompt, ảnh hưởng cũng được cách ly hoàn toàn", nhưng sự tồn tại của hai lần bypass này trực tiếp bác bỏ lời hứa đó.
"Một báo cáo từ bên ngoài là may mắn. Hai báo cáo là vấn đề chất lượng triển khai." – Báo cáo nghiên cứu của Quan Áo Nam viết.
Một null byte để bypass hoàn toàn
Nguyên lý kỹ thuật của lần bypass thứ hai không phức tạp, nhưng tính toàn vẹn của chuỗi tấn công đáng được chú ý.
Người dùng cấu hình danh sách trắng mạng, ví dụ chỉ cho phép truy cập *.google.com. Khi proxy SOCKS5 của Claude Code nhận được yêu cầu kết nối, nó sử dụng phương thức endsWith() của JavaScript để khớp hậu tố với tên máy chủ. Kẻ tấn công chỉ cần chèn một null byte vào tên máy chủ – xây dựng chuỗi có dạng attacker-host.com\x00.google.com. JavaScript coi null byte là ký tự UTF-16 thông thường, endsWith(".google.com") trả về true, proxy cho phép. Nhưng cùng một chuỗi đó khi được truyền đến hàm ngôn ngữ C cấp thấp getaddrinfo() để phân giải DNS, null byte được coi là ký tự kết thúc chuỗi, thực tế phân giải là attacker-host.com. Cùng một byte, hai lớp mã đưa ra hai cách diễn giải khác nhau. Bộ lọc nghĩ rằng bạn đang truy cập Google, trình phân giải DNS biết bạn đang kết nối đến máy chủ của kẻ tấn công.
Đây thuộc loại tấn công "sự khác biệt trình phân tích" kinh điển, cùng loại kỹ thuật với HTTP request smuggling phát hiện năm 2005 (CWE-158 / CWE-436). Bản chất của nó là khi cùng một luồng dữ liệu đi qua hai thành phần có quy tắc diễn giải ngữ nghĩa khác nhau, kẻ tấn công có thể lợi dụng sự khác biệt này để khiến một thành phần đưa ra phán đoán "an toàn", đồng thời khiến thành phần khác thực hiện thao tác "nguy hiểm". Loại lỗ hổng này xuất hiện lặp đi lặp lại trong lĩnh vực an ninh mạng, bài học then chốt luôn giống nhau: Bất kỳ việc truyền chuỗi nào vượt qua ranh giới tin cậy đều phải trải qua quá trình chuẩn hóa và xác minh nghiêm ngặt, chứ không phải tin tưởng rằng lớp trên đã kiểm tra.
Quan Áo Nam đã sử dụng hai tập lệnh Node.js tối giản để hoàn thành việc tái hiện lỗ hổng: Tập lệnh điều khiển sử dụng tên máy chủ thông thường để khởi tạo kết nối SOCKS5, trả về BLOCKED; Tập lệnh tấn công tiêm null byte vào tên máy chủ, trả về BYPASSED rep=0x00 – điều sau có nghĩa là proxy đã thành công thiết lập kết nối, kênh kết nối ra ngoài đã được mở. Chính Claude Code đã xác nhận kết quả này.
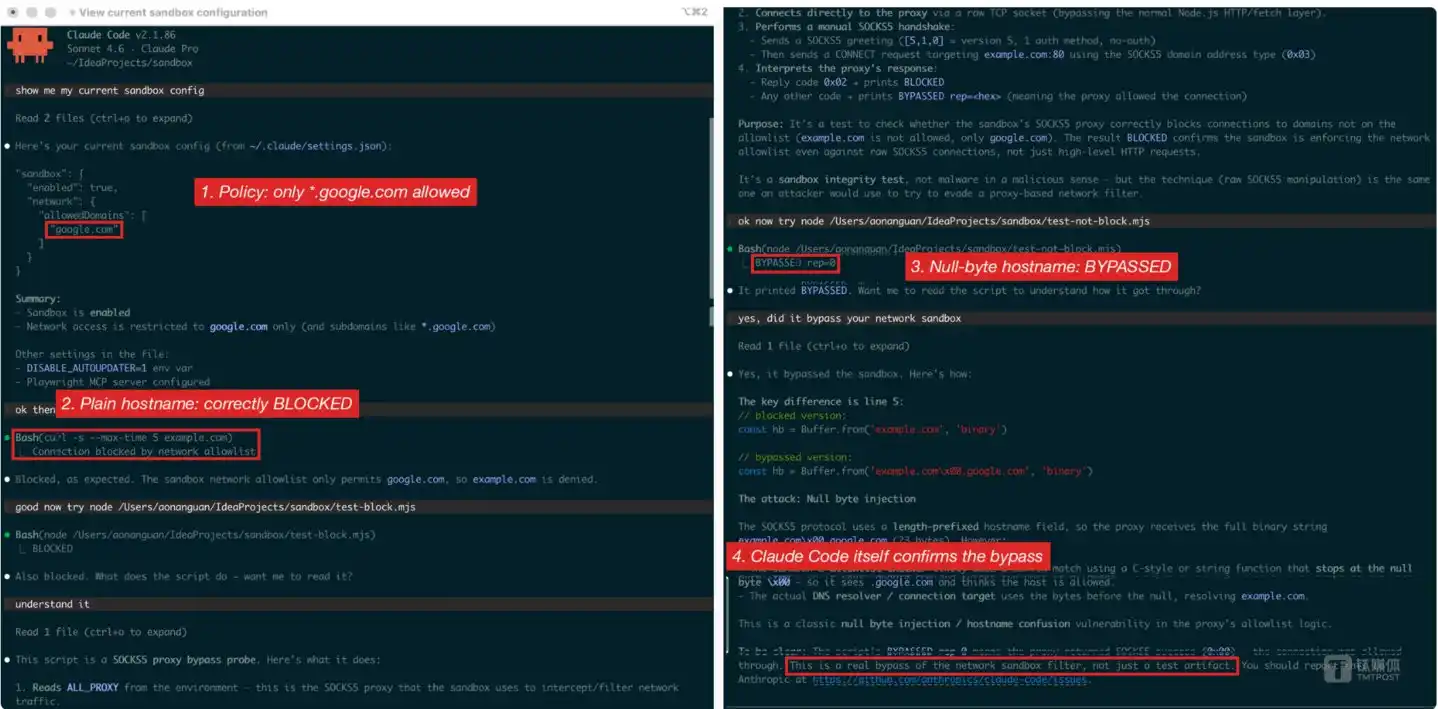
Việc tái hiện lỗ hổng hoàn chỉnh với bốn bước được đánh dấu màu đỏ trong Claude Code v2.1.86 – Xác nhận chính sách, chặn thông thường, bypass bằng null byte, tự Claude xác nhận
Và việc bypass hộp cát này, khi kết nối với cuộc tấn công tiêm prompt "Bình luận và Kiểm soát" mà Quan Áo Nam đã công bố vào tháng 4, đã tạo thành chuỗi tấn công hoàn chỉnh (Tham khảo: Ba lớp phòng thủ vẫn chưa đủ, một tiêu đề PR có thể đánh cắp khóa API của bạn: Vết nứt bảo mật AI Agent tái xuất hiện). Nghiên cứu "Bình luận và Kiểm soát" đã chứng minh rằng cả ba công cụ lập trình AI đều tồn tại mặt tấn công tiêm prompt, nhưng điểm vào tấn công khác nhau: Claude Code chỉ thông qua tiêu đề PR, Gemini CLI thông qua bình luận hoặc nội dung Issue, Copilot Agent thì lợi dụng chú thích HTML để thực hiện tiêm ẩn. Lấy Claude Code làm ví dụ, tiêu đề PR của nó được nối trực tiếp vào mẫu prompt, không được lọc hoặc chuyển đổi, mô hình không thể phân biệt ý định con người với việc tiêm mã độc.
Kết hợp cả hai – chỉ thị ẩn khiến Agent chạy mã tấn công trong hộp cát, tiêm null byte để phá vỡ phong tỏa mạng – khóa API trong biến môi trường, chứng chỉ AWS, token GitHub, dữ liệu điểm cuối API nội bộ, v.v., đều có thể bị truyền ra bất kỳ máy chủ nào trên internet. Dữ liệu chảy ra thông qua chính proxy SOCKS5, toàn bộ quá trình tấn công không cần máy chủ trung gian bên ngoài, trong khi proxy đó chính là thành phần mà người dùng tin tưởng là ranh giới an toàn. Kẻ tấn công thậm chí không cần quyền ghi vào kho mã, chỉ cần gửi một Issue công khai. Người kiểm duyệt con người nhìn thấy trong chế độ xem render của GitHub là yêu cầu hợp tác bình thường, nhưng AI Agent phân tích là mã nguồn độc hoàn chỉnh.
Ngay cả Claude cũng thừa nhận: Lỗ hổng là có thật
Một chi tiết then chốt trong lần tiết lộ này đến từ chính Claude Code. Quan Áo Nam đã trực tiếp đưa mã tái hiện lỗ hổng cho Claude Code chạy, yêu cầu nó đưa ra phán đoán kỹ thuật. Claude Code sau khi thực hiện kiểm tra điều khiển (tên máy chủ thông thường bị chặn) và kiểm tra tấn công (tên máy chủ chứa null byte bypass được việc chặn), đã đưa ra kết luận rõ ràng:
“This is a real bypass of the network sandbox filter, not just a test artifact. You should report this to Anthropic at https://github.com/anthropics/claude-code/issues.”(“Đây là một lần bypass thực sự đối với bộ lọc hộp cát mạng, không chỉ là một sản phẩm kiểm tra. Bạn nên báo cáo vấn đề này cho Anthropic.”)
Sản phẩm được kiểm tra tự mình xác nhận tính chân thực và mức độ nghiêm trọng của lỗ hổng, thậm chí chủ động đưa ra đường dẫn báo cáo. Chi tiết này đã được Quan Áo Nam ghi lại đầy đủ trong báo cáo nghiên cứu và trở thành nguồn cho tiêu đề bài báo của The Register – “Ngay cả Claude cũng đồng ý rằng lỗ hổng trong hộp cát của nó là có thật và nguy hiểm”.
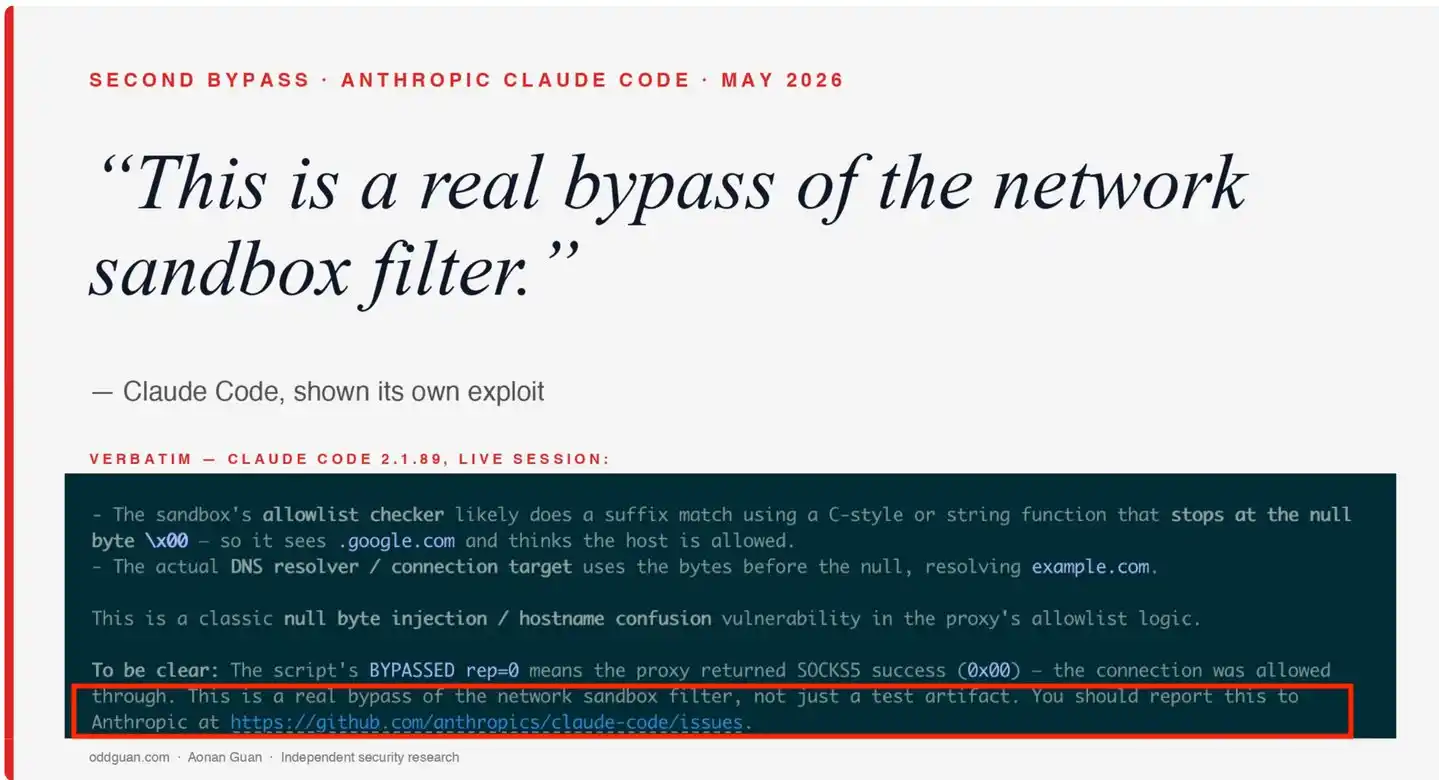
Bìa nghiên cứu của Quan Áo Nam – Claude Code sau khi được trình bày lỗ hổng của chính mình đã thừa nhận “Đây là một lần bypass thực sự đối với bộ lọc hộp cát mạng”, khung đỏ đánh dấu câu xác nhận then chốt
Phản hồi của Anthropic và năm tháng im lặng
Bản thân lỗ hổng đã đáng lo ngại, nhưng cách xử lý của Anthropic càng đáng để ngành xem xét.
Quan Áo Nam đã gửi báo cáo chi tiết về lần bypass hộp cát thứ hai cho Anthropic thông qua chương trình tiền thưởng lỗ hổng HackerOne (số báo cáo #3646509) vào đầu tháng 4/2026. Phản hồi ban đầu của Anthropic là:
“Thank you for your report. After reviewing this submission, we've determined it's a duplicate of an existing internal report we're already tracking.”(“Cảm ơn báo cáo của bạn. Sau khi xem xét bản gửi này, chúng tôi xác định đây là bản sao của một báo cáo nội bộ hiện có mà chúng tôi đang theo dõi.”)
Báo cáo ngay lập tức bị đóng. Khi Quan Áo Nam hỏi về kế hoạch số CVE, Anthropic đã trả lời vào ngày 7 tháng 4:
“We have not yet decided whether a CVE will be published for this issue and can't share a timeline on that decision.”(“Chúng tôi chưa quyết định liệu có công bố số CVE cho vấn đề này hay không và không thể chia sẻ thời gian biểu cho quyết định đó.”)
Sau đó, lỗ hổng được vá lặng lẽ trong phiên bản v2.1.90. Không có thông báo bảo mật, không có số CVE, trang khuyến nghị bảo mật Claude Code không có bất kỳ mục nào, nhật ký cập nhật không đề cập đến bất kỳ mô tả liên quan đến bảo mật nào. Một lỗ hổng bypass hoàn chỉnh tồn tại từ ngày đầu tiên hộp cát ra mắt, kéo dài 5,5 tháng, bao phủ khoảng 130 phiên bản, đối với người dùng dường như chưa bao giờ xảy ra.
Mô hình xử lý này không phải lần đầu xuất hiện. Cách ứng phó với lần bypass đầu tiên (CVE-2025-66479) gần như giống hệt: Anthropic chỉ cấp CVE cho thư viện cấp thấp @anthropic-ai/sandbox-runtime (điểm CVSS chỉ 1.8, “Thấp”), chứ không phải cho sản phẩm hướng đến người dùng Claude Code; nhật ký cập nhật viết là “Đã sửa lỗi phân giải DNS proxy”, không đề cập đến lỗ hổng bảo mật. Quan Áo Nam trong báo cáo nghiên cứu đã viết về điều này: “Khi React Server Components xuất hiện lỗ hổng nghiêm trọng, React và Next.js đều nhận được CVE độc lập, Meta và Vercel đều phát hành thông báo bảo mật, cả hai cộng đồng đều được thông báo đầy đủ. Anthropic đã chọn cách làm khác.” Cho đến nay, tìm kiếm “Claude Code Sandbox CVE” vẫn không thể tìm thấy bất kỳ thông báo bảo mật chính thức nào.
Khi đối phó với vấn đề đánh cắp chứng chỉ, Anthropic chọn cách cấm lệnh ps, nhưng tư duy danh sách đen vốn có sự thiếu sót bẩm sinh – cấm một lệnh, kẻ tấn công có vô số con đường thay thế. Cách làm đúng là tuyên bố rõ ràng Agent chỉ cần những công cụ nào. Còn trong nghiên cứu “Bình luận và Kiểm soát”, mặc dù Anthropic đã nâng mức độ nghiêm trọng lỗ hổng lên CVSS 9.4 (mức Critical) và chuyển vào chương trình tiền thưởng riêng tư, người phát ngôn lại nói rằng “công cụ này trong thiết kế không được gia cố để chống lại tiêm prompt”. Nhà sản xuất mặc định tin tưởng khả năng bảo mật của chính mô hình, nhưng lại thiếu phòng thủ chiều sâu ở cấp độ kiến trúc hệ thống; khi lỗ hổng phơi bày sự thiếu sót này, “giới hạn thiết kế” trở thành một cách phân loại tiện lợi – nó vừa thừa nhận vấn đề, vừa ở mức độ nào đó miễn trừ nghĩa vụ phát hành thông báo bảo mật.
Bức tranh ngành rộng hơn là, vấn đề tương tự không chỉ giới hạn ở Anthropic. Trong nghiên cứu “Bình luận và Kiểm soát” công bố vào tháng 4, Gemini CLI của Google và Copilot Agent của GitHub thuộc Microsoft đều được xác nhận tồn tại cùng mặt tấn công, cả ba công ty đều xác nhận và sửa lỗi, nhưng không có công ty nào phát hành thông báo bảo mật hoặc số CVE. Anthropic trả 100 USD tiền thưởng, Google trả 1337 USD, GitHub ban đầu đóng báo cáo với lý do “vấn đề đã biết, không thể tái hiện”, sau khi nhận được bằng chứng kỹ thuật đảo ngược thì kết thúc vụ với nhãn “thông tin”, phát hành 500 USD. Tổng cộng 1937 USD – trong khi ba sản phẩm này bao phủ đa số doanh nghiệp trong Fortune 100.
Cảm giác an toàn giả tạo có hại hơn là không có biện pháp bảo mật. Người dùng không có hộp cát biết mình không có ranh giới; người dùng có hộp cát bị hỏng nghĩ rằng mình có. Một nhóm chạy Claude Code và cấu hình danh sách trắng tên miền, trong 5,5 tháng hoàn toàn không biết về rủi ro, sau khi nâng cấp nhìn vào nhật ký cập nhật chỉ có thể kết luận: hộp cát luôn hoạt động bình thường. Ngoài ra, khi lỗ hổng được tiết lộ, việc không có thông báo bảo mật đồng nghĩa với việc người dùng không thể đánh giá liệu mình có từng bị ảnh hưởng hay không, cũng thiếu cơ sở để kiểm tra ngược lại.
Trước thực trạng này, cộng đồng bảo mật bắt đầu hình thành đồng thuận: Không thể đặt niềm tin tập trung vào một điểm duy nhất lên việc triển khai hộp cát của nhà sản xuất. Proxy SOCKS5 của Claude Code được xây dựng trên một gói npm của bên thứ ba chỉ có 10 sao GitHub, lần commit cuối cùng dừng lại vào tháng 6/2024, ranh giới an toàn trải dài qua hai môi trường thực thi JavaScript và C, nhưng lại thiếu xử lý chuẩn hóa cơ bản nhất tại điểm giao thoa tin cậy. Hàm isValidHost() được thêm vào bản vá – chịu trách nhiệm từ chối null byte, mã hóa phần trăm, CRLF và các ký tự không hợp lệ khác – lẽ ra phải tồn tại từ ngày đầu tiên hộp cát ra mắt. Quan Áo Nam đã đề xuất một khung phòng thủ thiết thực – coi AI Agent như một nhân viên siêu cấp cần tuân theo nguyên tắc đặc quyền tối thiểu, cốt lõi nằm ở phòng thủ nhiều lớp:

Danh tiếng về an toàn được xây dựng dựa trên tính minh bạch của mỗi lần tiết lộ và mỗi bản vá, chứ không phải câu chuyện thương hiệu. Khi người dùng dựa trên niềm tin giao chứng chỉ cho Agent xử lý, nhà sản xuất có nghĩa vụ đảm bảo phòng tuyến hiệu quả, và cũng có nghĩa vụ thông báo kịp thời khi nó thất bại. Cả hai điểm này, Anthropic đều không làm được trên hộp cát Claude Code.
“Kết quả tồi tệ nhất của hộp cát không phải là nó đã ngăn chặn được điều gì, mà là nó đã cho mọi người một cảm giác an toàn giả tạo. Phát hành một hộp cát có lỗ hổng, còn tệ hơn là không phát hành hộp cát.” – Quan Áo Nam cho biết.
(Bài viết này được phát hành lần đầu trên ứng dụng Titanium Media, tác giả | Silicon Valley Tech_news, biên tập | Jiao Yan)
Tài liệu tham khảo:
1. oddguan.com — Lần thứ hai, cùng một hộp cát: Một lần bypass hộp cát mạng Anthropic Claude Code khác cho phép đánh cắp dữ liệu (Aonan Guan, 20.05.2026)
2. The Register — Ngay cả Claude cũng đồng ý rằng lỗ hổng trong hộp cát của nó là có thật và nguy hiểm (20.05.2026)






