By Xiang Xianzhi
Luo Fuli posted on X to draw a line under the price cut controversy surrounding Xiaomi's MiMo.
On May 26th, the official Xiaomi MiMo account posted an announcement on X: The MiMo-V2.5 series APIs are now permanently reduced in price, with a maximum discount of 99%. All context lengths are now uniformly priced, and token packages have been upgraded by 5-8 times.
This announcement circulated within China's AI circle for a whole week. The initial industry reaction was divided into several camps. The largest camp called it "another round of price wars"—over the past two years, from Zhipu, DeepSeek, Byte's Doubao to Alibaba's Tongyi, domestic large models have taken turns cutting prices; everyone is competing fiercely.
Another camp took a more pessimistic view: Xiaomi had just announced a halving of profits this year, and now they're still burning 600 billion on AI, slashing API prices by 90%—typical "losing money to grab market share." Others saw it as a continuation of the DeepSeek effect—the latter dragged the entire industry's pricing baseline to the floor, and whoever doesn't follow will be left out.
Therefore, as the head of MiMo, Luo Fuli directly shared a 5000-word technical blog post last night, publicly revealing the engineering calculations behind the price cut to everyone.
"Look, this is genuine engineering capability, not a marketing tactic."
To understand what Luo Fuli is saying, one must first grasp what exactly this 99% discount applies to.
It is not a price cut for the entire model. The 99% discount specifically targets a pricing tier called Input (Cache Hit)—that is, the portion where "users repeatedly read historical context in long conversations." The discount for ordinary new input (No Cache Hit) is much smaller, and the discount for model output (Output) is the smallest.
If you think of the model as a coffee shop, this becomes easier to understand.
You order a half-sugar latte. The coffee shop has two ways to make it: grind the beans, measure the syrup, and pour the milk from scratch each time, paying for ingredients and labor each time; but if the model knows you want the same half-sugar latte every day this week, it can simply make a large pot and store it in the fridge, scooping out a cup next time. What MiMo has done is the latter—changing the user's repeated reads from "calculate on the fly" to "retrieve on the fly," so the real cost of this part is close to 0, naturally allowing for a 99% discount.
To achieve "retrieve on the fly," the technical blog discusses six engineering feats, each indispensable. Let's break them down one by one.
Engineering One: Compress Model "Memory" to 1/7
When the model is conversing with you, it needs to calculate and store an "intermediate state" for each token for the next step. This is called KVCache—think of it as the model's "short-term memory notebook." With each sentence spoken, the model notes a summary of that sentence in its notebook, so next time it can just flip through the notes instead of listening to everything you've said from the beginning.
Traditional models use "Full Attention" at every layer—meaning each token looks at all tokens in the entire conversation segment, making the notebook thicker and thicker. MiMo-V2.5-Pro changed the architecture: Out of 70 layers, 60 layers only look at the most recent 128 tokens (SWA, Sliding Window Attention), leaving only 10 "archivist" layers to see everything.
The result is that the KVCache volume is directly compressed to 1/7 of Full Attention, with computational load also at 1/7.
This is the first foundation for cost reduction. Using an analogy, originally every employee in a company was required to remember all meeting minutes, resulting in everyone's brain being overloaded and inefficient. The new rule reduces the mental burden for 60 employees to 1/7, leaving only 10 archivists to manage all history—the company's overall memory capacity doesn't decrease, but efficiency increases 7-fold.
Engineering Two: Make the Space Saved by SWA Actually Usable
Architecturally compressing the notebook to 1/7 is the first step, but to turn "theoretical 1/7" into "actual 1/7," there is another hurdle.
Traditional KVCache systems allocate video memory (VRAM) uniformly to all layers based on "maximum possible usage." This means: even though the 60 SWA layers only need a small notebook, the system allocates based on the "archivist's large notebook" for all layers—the space saved by SWA is wasted, reserved but not used, equivalent to saving nothing.
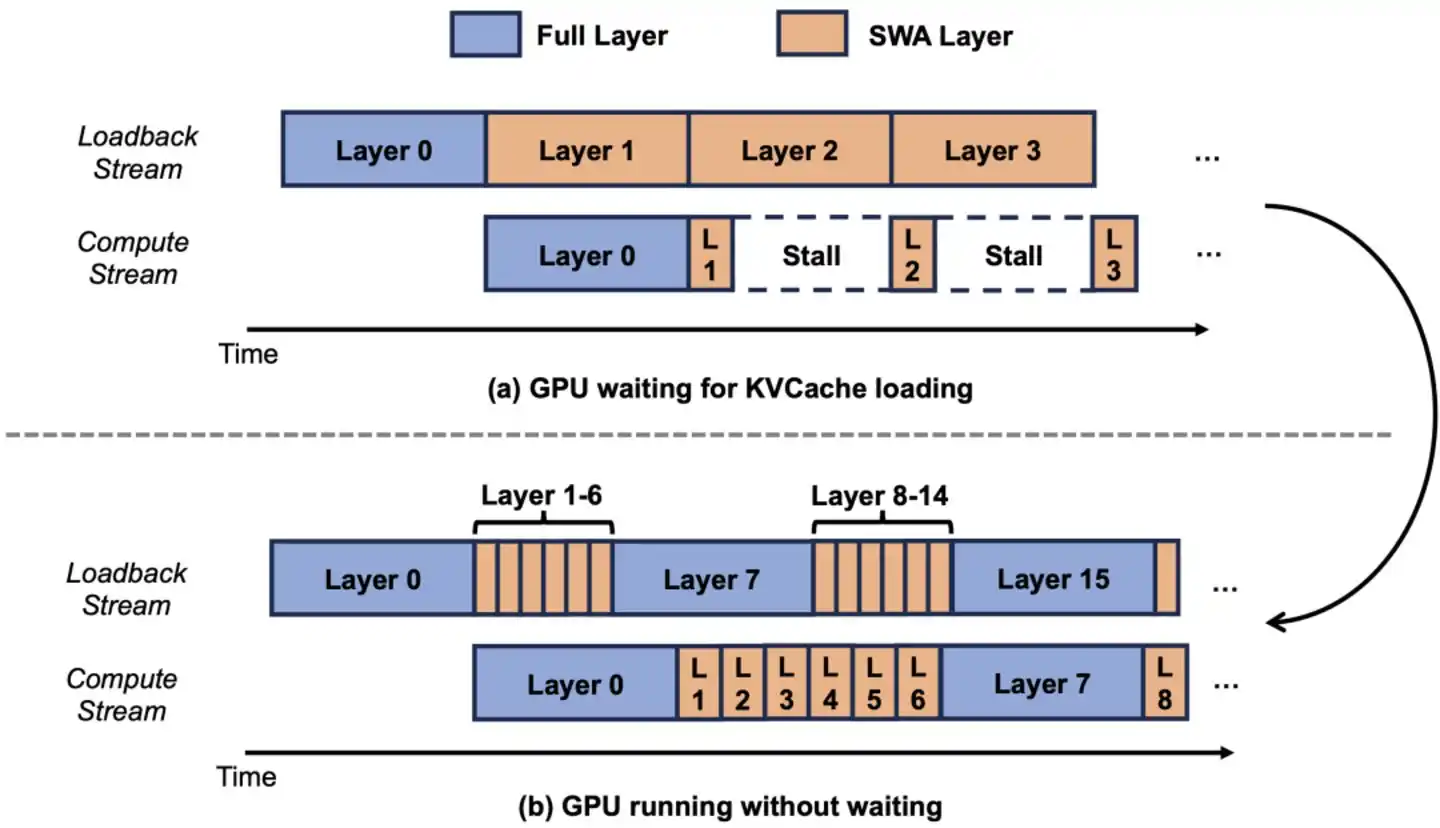
The approach by Luo Fuli's team was to split the KVCache into two independent pools. The 10 Full Attention layers use the "large pool," allocated based on full length; the 60 SWA layers use the "small pool," allocated only based on a 128-token window.
Using an analogy, originally the company gave every employee a "filing cabinet capable of holding 100 years of documents"—but 60 employees actually only need a "small cabinet holding one week's documents," leaving 99% of the space in those large cabinets empty. The new approach allocates cabinets based on actual needs. As a result, the entire office can fit over 5 times more colleagues to work—concurrent users served by the same GPU increases 5-fold.
This step seems simple, but without it, the advantage of the previous SWA architecture would be in vain.
Engineering Three: Ensure "Returning Users Re-reading" Can Actually Hit the Cache
With the notebook compressed to 1/7 and the space truly usable, the next step is to solve an old problem: prefix cache hit rate.
Many user conversations share the same beginning—the same system prompt, the same codebase, the same long document. The system stores the computed results, and the next time a match occurs, it reuses them directly. This mechanism is called prefix caching.
But a pitfall arises in SWA mode: two requests having the same tokens does not guarantee the KV is still there. The prefix might have been computed, but parts outside the SWA window might have been evicted long ago. If the system still follows the old rule of "same tokens equals a hit" for reuse, it might read invalid or overwritten data, causing the model's performance to crash.
Luo Fuli's team upgraded the rule to "window-safe length"—only guaranteeing the portion "you can completely borrow."
Using an analogy, a library has 1 million books. You want to borrow the complete three-volume set of "The Three-Body Problem." The original architecture would tell you "the book is here," you go over only to find the shelf has only the cover and the first volume, the latter two have been borrowed. This "false hit" wastes your trip and requires re-borrowing. The new system's rule changes to only guarantee the portion you can completely borrow—first give you the first volume, then fetch the next two for you.
It sounds stricter, as if the hit rate would drop. But the opposite is true: because SWA compresses KVCache volume to 1/7, the same storage space can hold several times more content, significantly increasing the real hit rate.
Luo Fuli's blog provides actual online test numbers: Under mainstream harness frameworks, server-side cache hit rate averages 93%, and for high-frequency, long-cycle users, it can reach over 95%.
Translating this number's meaning: 95% of "re-read" requests don't need GPU computation at all; they're fetched directly from the cache. This is the physical basis for the 99% discount.
Engineering Four: Store "Cache" in the GPU's Built-in SSD
With the hit rate up, the next question is: where to store this cache.
Video memory (HBM memory on the GPU) is expensive and limited—an eight-card H100 machine has only 640GB VRAM, but the KVCache MiMo needs to store could be on the scale of tens of terabytes. Therefore, tiered storage is necessary: recently used data stays in VRAM (L1), slightly older data goes to CPU memory (L2), and cold data is stored in distributed cache (L3).
It's like managing money. Cash in your wallet is VRAM—immediately accessible but can't hold much. Bank account balance is CPU memory—takes 30 seconds to access but can hold a lot. Term deposits are L3 distributed cache—takes 2 minutes to access but is much cheaper.
The industry's common practice is to build a separate storage cluster for L3, with dedicated machines, dedicated data centers, paying rent monthly.
Xiaomi's storage team did it differently. They developed their own distributed cache system called GCache, deployed directly on the SSDs built into the GPU machines—co-located on the same machines with training tasks and inference tasks.
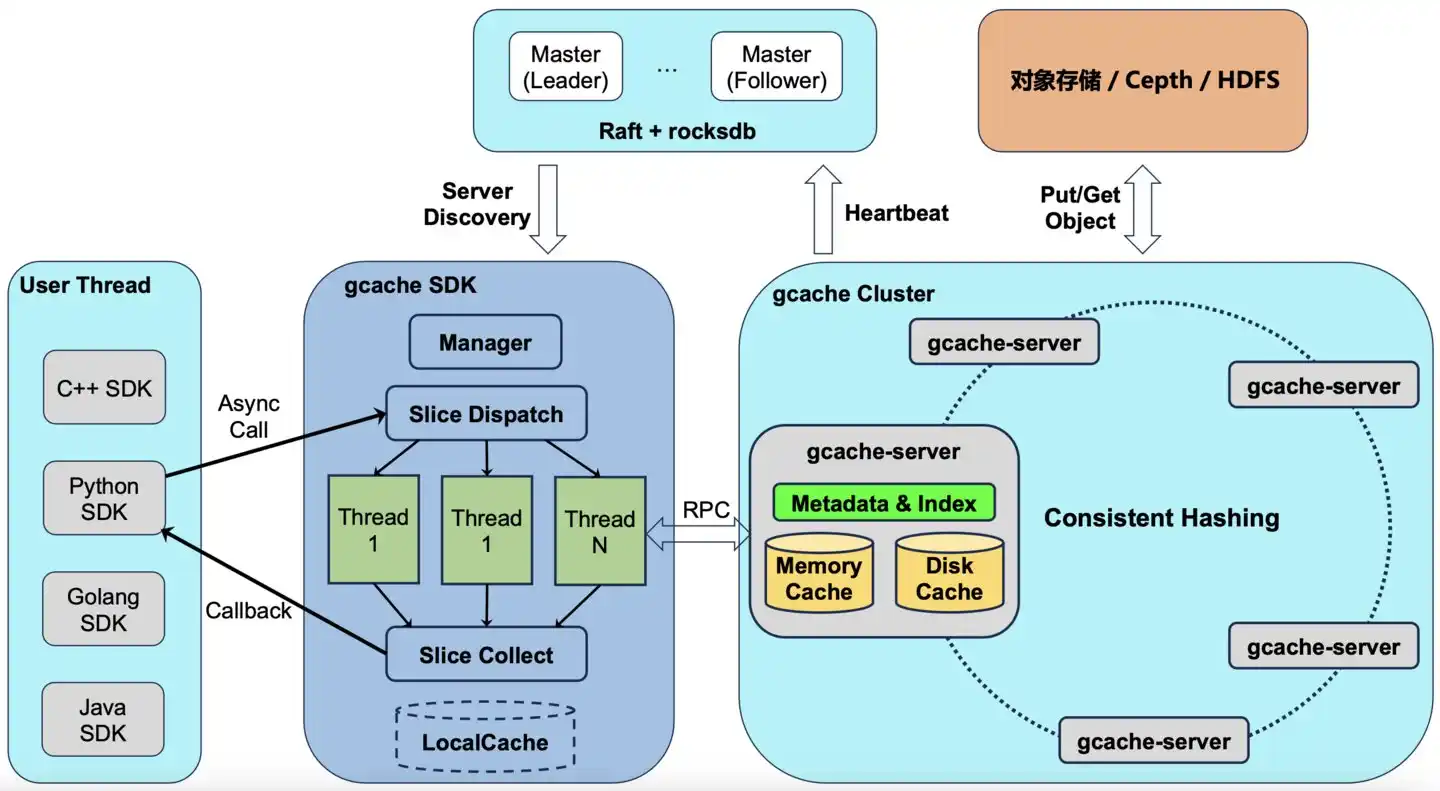
Plain translation: Others rent a separate warehouse to store large amounts of data; Xiaomi found the GPU machine's garage is actually empty and just stored the data there. Monthly rent is saved.
The exact words from the technical blog are: "The additional storage cost is 0."
The impact of this is bigger than it seems. In the conventional "AI company compute cost calculation," storage cost is a fixed expense item—the larger your model and the more users, the longer the storage bill. The GCache approach eliminates this item entirely. Combined with SWA's small size + 93-95% hit rate, the Time-To-Live (TTL) for KVCache in L3 extends from minutes to hours or even days—the longer the TTL, the wider the window for historical context to be hit, the higher the cache hit rate, and the more solid the foundation for that 99% discount.
Engineering Five: Route Cache-Hit Requests Through the Shortest Path
The cache can be stored, queried, and is cheap. The final step is: how to route the correct requests to the correct machines.
Xiaomi developed its own scheduling system called LLM-Router, which does three things:
First, Affinity Scheduling. Routes requests with the same prefix to the same machine, maximizing cache reuse.
Second, Length Bucketing. Separates short requests (0-64K), medium requests (64K-256K), and long requests (256K-1M) into different processing channels, preventing short requests from being delayed by long ones.
Third, TTFT Optimization. Within the queue waiting for inference, prioritizes scheduling requests with smaller real computation loads (i.e., those with high cache hits)—avoiding them being blocked by "brand-new input" requests that require heavy computation.
For example, in regular airport scheduling, all passengers flying to the same destination are gathered in the same lounge, sharing the baggage claim process—this is Affinity Scheduling. Those with carry-ons and those with 3 large checked bags go through two separate security lines, so the fast aren't slowed by the slow—this is Length Bucketing. During boarding, prioritize passengers with only carry-ons; they board quickly, allowing the plane to depart earlier—this is TTFT Optimization.
This scheduling strategy, in practice, increased L2 cache hit rate by 25%, single-machine input throughput by 30%, and reduced P90 latency for long requests by 30%.
Translated: The same GPU can serve more users. The other half of the price cut logic lies here—effective output per unit of compute is higher, cost per user is lower.
Engineering Six: Make the Model "Type" Faster Too
The first five items optimized the "read" side—reducing the cost of users repeatedly reading historical context to near zero. The sixth item optimizes the "write" side—the process of the model generating the next token.
Traditional models can only generate 1 token at a time. MiMo natively supports 3-layer MTP (Multi-Token Prediction)—predicting the next 3 tokens at once. If the middle predictions are correct, it directly skips the intermediate computations.
Using an analogy, traditional typing is one character at a time—to type "今天天气" (today's weather), you press 4 keys. MTP is like having autocomplete guess your next 1-2 characters—if it guesses correctly, you don't need to press those two keys.
MiMo's MTP, tested in agentic scenarios: decoding the first 128 tokens is accelerated by 2.3x, and tokens 128-256 are accelerated by 1.5x.
The significance of this is that the 99% discount specifically targets Input (Cache Hit), but when the model actually serves a user, input and output occur within the same request—if output isn't saved, the overall request cost is only halved. MTP reduces the output half as well, closing the loop on the entire price cut's profit model.
Stringing the six items together into a cost-reduction chain:
SWA architecture → KVCache 1/7 → Dual pools truly release capacity → Same GPU can handle 5+ times more concurrent users → Prefix cache hit rate 93-95% → 95% of requests almost require no computation → GCache zeroes storage cost → Scheduling prioritizes hit requests → MTP also saves generation → GPU time per request drops by an order of magnitude → Unit cost drops 95%+ → Pricing cut 99%, gross margin remains positive.
If any link is missing, the chain breaks. The 99% price cut is not a marketing figure; it's the cumulative effect of six engineering pillars combined and validated in real online operations.
Looking back at the initial industry interpretations, each had some truth. The price wars among Chinese large model companies over these two years are real; Xiaomi's halved profits while still investing heavily in AI is real; DeepSeek dragging the industry's pricing baseline to the floor is also real.
But by publicly releasing this technical blog and unpacking the detailed technical specifics, Luo Fuli undoubtedly hopes to counter the price war narrative, letting "technical matters belong to technology, and marketing matters belong to marketing."
She wrote in the blog that the inference efficiency of the MiMo-V2.5 series models does not come from a single breakthrough in one area but is the result of multi-dimensional collaborative optimization. Hybrid SWA benefits both prefill and decode, but poorly optimized KVCache implementation can actually increase costs at various stages. To achieve this goal, the MiMo team systematically rebuilt KVCache management, hierarchical caching, and prefix cache trees, tackling the core issues of SWA KVCache, optimizing scheduling strategies and Prefill/Decode pipelines. After validation in real online scenarios, they finally translated its theoretical efficiency advantages into production environments. Only then did Hybrid SWA demonstrate its architectural advantage of both strength and efficiency in long-context reasoning. Combined with MoE configurations and various optimizations for multimodal inference, it significantly improved the performance of online inference services.
This is a systematic approach to AI engineering, and a cost-reduction method worthy of reference and learning for the industry.
A price war doesn't require writing a blog post; engineering delivery does.





