Author: David, Deep Tide TechFlow
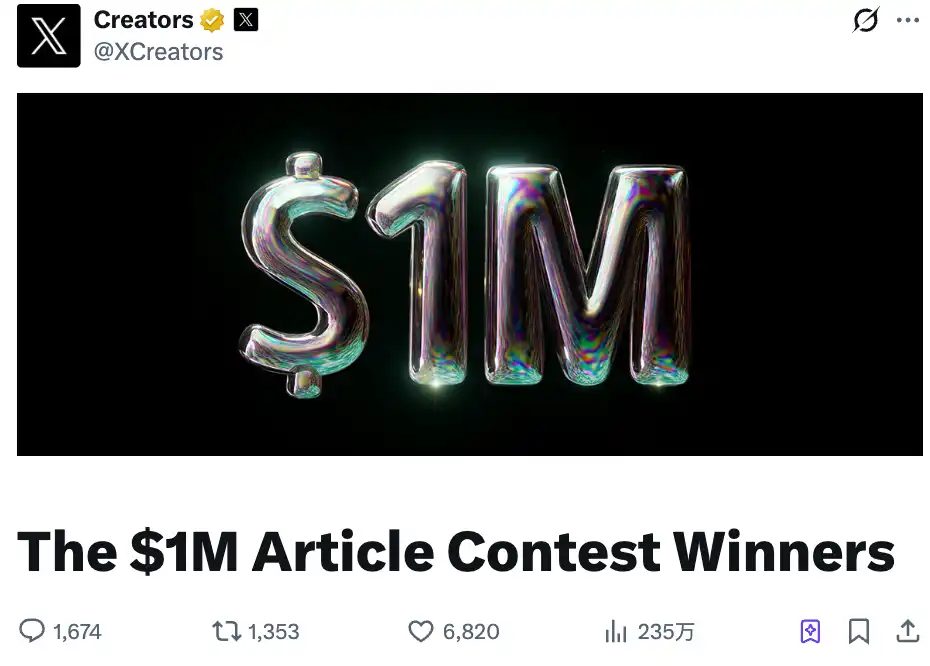
In mid-January, X announced a $1 million reward for the best-performing long-form Articles on its platform.
Elon Musk personally confirmed the announcement. The rules were simple: limited to US users, original English articles over 1000 words, ranked primarily based on exposure among US paid users.
You might recall that just a few days before this content incentive program was launched, personal growth blogger Dan Koe published an article titled "How to fix your entire life in 1 day," which garnered 170 million impressions, becoming the best-performing Article in X's history.
X clearly saw the traffic potential of long-form content and quickly followed up: lowering the threshold for the Articles feature, adjusting the algorithm to prioritize long-form content over short posts, and announcing the million-dollar征文大奖 (essay contest大奖).
A two-week competition period, with tens of thousands of participants.
Results were announced on February 4th. The total prize money was $2.15 million, more than double the initial promise. $1 million for the champion, $500,000 for the runner-up, plus a $250,000 "Creator Choice" award and four $100,000 honorable mentions.
The winning situation is roughly as follows:

You can see Dan Koe is on the list again. However, his previous article on how to repair your life in one day had 170 million impressions, but the champion of this creation contest only had 45 million.
Viral hits are hard to come by, but the winning articles are still worth analyzing.
🏆 Champion: A 90k-follower "small account" takes $1 million with a self-built database
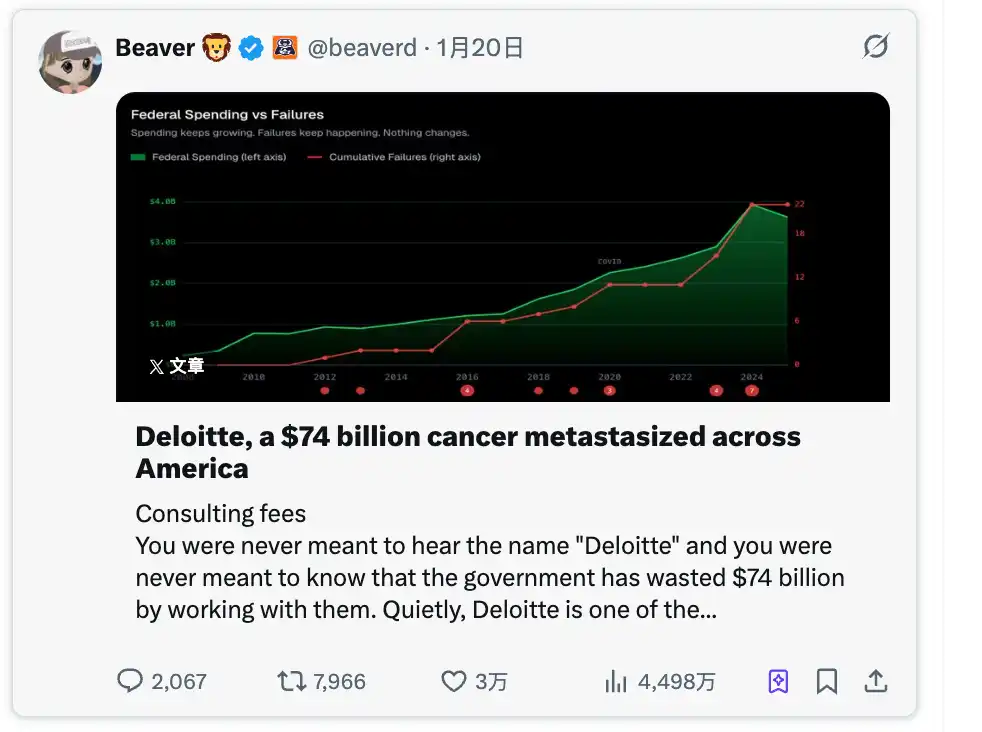
The champion @beaverd's article title translates to "Deloitte, a $74 Billion Cancer Spreading Across America." It's about the well-known consulting firm Deloitte.
This account currently has "only" 90,000 followers, which is relatively small compared to the other winners, and it has no media organization or any endorsement beyond the blue check verification.
The topic he wrote about doesn't touch on any trending buzzwords either, but it exposes a rather controversial issue: how Deloitte secured $74 billion in contracts from federal and state governments and then botched the projects.
Portal is here
Clicking in, you'll find this person really put in the work.
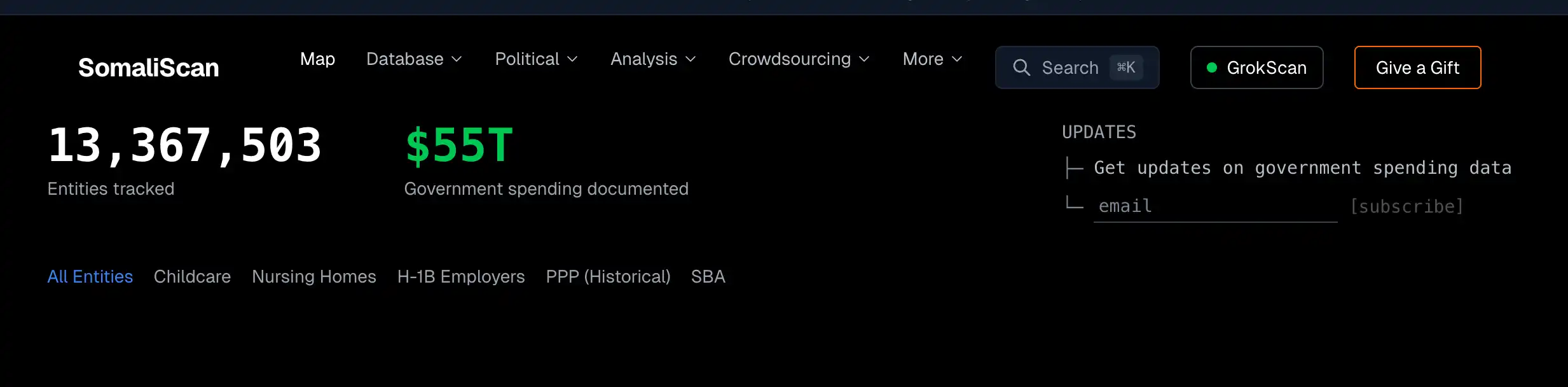
He built his own website called somaliscan.com, scraping millions of government invoice data entries, cross-referencing audit reports and system failure records line by line.
Then, using this first-hand data, he told a series of shocking stories: California's unemployment benefits system defrauded of $32 billion, Tennessee's Medicaid system崩溃 (collapsed) leading to 250,000 children losing coverage, a court信息化改造 (IT modernization) project burning through $1.9 billion and ending up abandoned... covering 25 states in total.
He also dug up the revolving door between Deloitte executives and government officials, specifying who jumped from Deloitte to which department and then approved which contracts back to Deloitte, listing names and amounts clearly.
One person built his own database, did his own research, and earned $1 million.
🥈 Runner-up: A 700k-follower finance macro account teaches you how to profit from tariff panic
The runner-up @KobeissiLetter is a familiar face in the macro finance circle, with 700,000 followers, long focused on US economic policy and market volatility.
What he did in this article is also very direct: he拆解 (deconstructed) Trump's tariff playbook into a repeatable trading framework, titled "Trump's Tariff Playbook: An Operational Guide."
Since Trump often acts unpredictably, liking to announce extreme policies and threaten other countries but not always fully following through, Wall Street summarized this pattern as TACO, an acronym for Trump Always Chickens Out.
TACO describes a recurring pattern:
Trump announces aggressive tariffs → market plummets → a few days later he backs down or delays → market rebounds.
Portal
What KobeissiLetter's article did was turn TACO from a joke into an operational manual with timestamps. Using tariff events from the past 12 months as samples, he拆出 (deconstructed) a complete cycle template for you to follow and trade according to the time periods.
For example, the White House releases消息 (news)制造恐慌 (creating panic) on the weekend,抄底资金 (bargain-hunting funds) enter mid-week,缓和信号 (easing signals) are released the next weekend, some agreement is reached within 2 to 4 weeks. Simultaneously, he would follow up (持续跟帖) at each step, telling you which stage it's at now, making it more like a serialized pre-research post.
He also provided practical methods, such as watching the US 10-year Treasury yield. If this number breaks 4.60%, Trump will likely让步 (concede).
For the paid users on X who follow macro and trading, this stuff is right up their alley.
It doesn't discuss whether tariffs are good or bad, nor does it make moral judgments. It just tells you what actions to take at what point next time this playbook is used, to make money.
🥉 Third Place: DAN KOE with the most likes, familiar life methodology
Dan Koe's参赛文章 (contest entry) "How to Enter a State of Deep Focus Anytime" received 42,000 likes, 8,681 reposts, the highest interaction data among all entries. But the exposure was only 11.04 million, less than a quarter of the champion's.
What X gave him wasn't strictly third place; it was a separately established "Creator Choice" award worth $250,000.
This is understandable. Dan Koe is "the person who inspired this competition." His viral article with 170 million impressions in early January directly showed X how high the traffic ceiling for long-form content could be.
Portal
No need to introduce the article itself too much; it's still that set of life growth methodologies. It大致是讲 (roughly talks about) how to gain focus, citing neuroscience and flow state concepts for support and depth.
Actually, this piece had the best interaction data, but according to the core competition rule "exposure among US paid users," it didn't rank at the top.
Why did the article with the best interactions have lower exposure? This misalignment will be discussed later.
Honorable Mentions: $100k ×4
Nick Shirley, Josh Wolfe, Kaizen Asiedu, and Ryan Hall each received a $100,000 incentive. Their accounts cover public policy, geopolitics, history, and public safety, respectively.
Among them, Josh Wolfe is the co-founder of Lux Capital, a well-known venture capitalist, who also announced he would donate the prize money equally to four charities.
Since the original post did not list the specific articles by these four individuals, and due to time and energy constraints, we did not conduct further investigation. Everyone is welcome to supplement this information.
Some In-Depth Observations
Some patterns visible from these competition results:
- The article with the most likes had only a quarter of the champion's exposure
The most counterintuitive data from this competition is definitely Dan Koe's.
42,000 likes, 8,681 reposts, 4,627 comments – the three interaction metrics were the highest overall. But the exposure was only 11.04 million, less than a quarter of champion @beaverd's. And @beaverd's likes were 30,000, fewer than Dan Koe's.
If you've done social media operations, this data feels别扭 (awkward). Generally, higher interaction should lead the algorithm to promote it more, resulting in greater exposure.
But X's competition calculation wasn't total exposure; it was "US paid user homepage timeline exposure." This metric excluded non-US users, non-paying users, and visits from search and personal profiles.
Dan Koe writes about personal growth, an audience naturally more global, with many non-US followers. @beaverd wrote about how US taxpayer money was wasted by Deloitte, an audience naturally concentrated in the US. Under the same algorithm recommendation mechanism, the "geographic concentration" of the content determined the level of this metric.
- 90k followers beat 900k followers, content scarcity > follower base
Champion @beaverd had 90k followers before the competition. Runner-up @KobeissiLetter had 700k followers. Dan Koe had 900k followers.
If follower count determined exposure, the ranking should be reversed. But the actual results show that in X's Articles recommendation logic, the weight of follower base is far less than imagined.
@beaverd won because he had something others didn't; content scarcity played a key role.
This is completely different from traditional traffic logic. Big accounts rely on follower存量 (stock) and posting frequency, but in an algorithm-dominated distribution environment, "whether you have exclusive content" is more important than "how many followers you have."
- You need to build your own content "hardware"
Stepping back, the topics of these three winning articles are completely unrelated: one investigates government contracts, one teaches you to trade tariff waves, one talks about how to focus.
In any content platform's categorization system, they wouldn't appear on the same list. But they share a common point: each has its own independent "hardware," meaning you need a narrative framework.
@beaverd's hardware is a self-built database scraping government data; KobeissiLetter's hardware is a trading framework backtested over 12 months; and Dan Koe's hardware is a six-chapter methodology blending neuroscience and psychology, although it might seem profound, it's actually common knowledge.
None of the winning articles were pure opinion pieces. They all required long篇幅 (length) to carry the information load, which is precisely the reason for the existence of the X Articles format.
Another noteworthy fact: Among the eight awardees, there wasn't a single traditional media outlet.
All are independent creators. This isn't to say traditional media didn't participate, but in this competition format, personal accounts反而更有优势 (actually had more advantage).
Institutional media content is usually published on their own websites, with only links and summaries on social media. But Articles require the full content to be published on X, which is an awkward move for media accustomed to off-site引流 (traffic diversion).
What is X really buying for $2.15 million
Returning to the platform itself.
X initially promised a $1 million incentive but ended up giving out $2.15 million. During the competition, it also made a series of supporting moves: expanding the Articles feature from creator accounts to all paid users, adjusting the algorithm to increase the recommendation weight of long-form content, changing the scoring method to "US paid user homepage exposure."
At such a high cost, the most direct reason is certainly that X needs original long-form content on its platform.
In the past, long content on X mostly relied on external links – Substack, Medium, personal blogs. Users click and jump away, leaving reading time and interaction data elsewhere. The goal of Articles is to keep this content on-site, allowing users to read from start to finish without leaving X.
Going deeper, X has Grok. Large language model training requires high-quality long-text data, and the vast majority of content on X is 280-character short tweets. If Articles can continuously attract creators to produce in-depth long-form content, this content becomes training material for Grok.
Finally, paid user value.
The competition rules limited the metric to "US paid user homepage exposure," directly telling creators that their content should serve paid users.
This is using creators' content to support the paid system, making paid users feel "the money I spent is worth it because I can see deep content on the homepage that I can't see elsewhere."
From a content creator's perspective, we feel the era of pure opinion might be turning a page.
This trend also applies to creators in the crypto circle. The crypto industry doesn't lack opinions; countless people on X every day喊单 (shill), predict prices, comment on regulation.
But few can自建 (build their own) on-chain data analysis tools like @beaverd, or拆解 (deconstruct) market cycles into repeatable trading playbooks like KobeissiLetter.
Maintaining scarcity and independence, producing consistently, is actually a very professional job, and also very rewarding and positive-feedback work.
We also hope to see more content from the Chinese circle appear on the list in the future.