Original | Odaily Planet Daily (@OdailyChina)
Author | Asher(@Asher_ 0210)

The most lively place in this World Cup isn't just on the pitch.
As the heat around World Cup prediction events rises, more and more users are starting to participate in trading with real money. Who will win, what will the score be, will there be an upset, will there be a red card, which player will score—topics that originally belonged to pre-match fan chatter have now been broken down into tradable prediction events.
And when predictions become trades, what users need is more than just emotion and intuition: odds movements, team form, injury news, historical matchups, market sentiment, all become references before a trade. In this process, AI models are being frequently pulled into World Cup prediction scenarios.
Large models like Qwen, ChatGPT, Gemini, Claude, DeepSeek, Qwen, and Copilot can not only answer "which team is more likely to win," but also give score predictions, upset possibilities, red card risks, key player performance, and match flow analysis. For prediction market participants, AI's pre-match deduction is becoming another layer of reference beyond odds, news, team data, and market sentiment.
However, predictions ultimately have to return to the matches themselves.
As the World Cup officially kicks off and the results of the first few matches come out one after another, those AI analyses that users used to aid their judgment before the matches finally have answers to compare against: Was the score predicted, were upsets spotted in advance, how many details like red cards, last-minute winners, and match flow were truly captured by the models.
The First to Go Viral Was, Unexpectedly, Qwen
The most dramatic performance on the first day of the World Cup was undoubtedly Qwen's.
For the opening match between Mexico and South Africa, Qwen's pre-match prediction was Mexico 2:0 South Africa. After the match ended, the score was indeed 2:0. What's more interesting is that the total of three red cards in the match also basically matched Qwen's pre-match risk assessment of "South Africa's overly physical defending, possibly getting into an early one-man-down situation."

If it were just predicting a Mexico win, that wouldn't be too surprising. As one of the hosts, Mexico was already favored. But what Qwen hit this time were more specific match details: the 2:0 scoreline, South Africa's red card risk, and the gradually widening gap in the latter stages of the match.
Immediately after, for the South Korea vs. Czech Republic match, Qwen gave another prediction of South Korea 2:1.
This match wasn't easy to call pre-match. The Czechs have physicality, set-piece threats, and the usual big-tournament experience of European teams. The match process was indeed not one-sided—the Czechs took the lead first, South Korea equalized later, and the match was deadlocked at 1:1 for a long time. Until the final stage, South Korea scored the winning goal, and the final score became 2:1.
At this point, Qwen's prediction gained a stronger "scripted" feel. Judging the winner can rely on paper strength, score prediction can have luck involved, but it's process details like red cards, comebacks, and last-stage winners that truly make people feel "there's something to it." After two matches on the first day, Qwen first pulled up the attention on AI World Cup predictions.
Copilot: Moments of Genius, and Clear Flops
Before the tournament, USA Today had Copilot predict all 104 matches of this World Cup. Looking at the matches that have concluded so far, this prediction has both highlights and clear misses.
Three match predictions stood out the most.
For the opening match Mexico vs. South Africa, Copilot predicted Mexico 2:0, which hit the final score exactly. For South Korea vs. Czech Republic, it predicted South Korea 2:1, again matching the result. For Brazil vs. Morocco, Copilot gave a 1:1 prediction, and Brazil was indeed held to a draw by Morocco.
Especially the Brazil 1:1 Morocco match, the prediction had considerable merit. Brazil, after all, is a traditional powerhouse, with squad strength and attention in the top tier. Although Morocco reached the semi-finals in the last World Cup, directly predicting a draw against Brazil pre-match wasn't a particularly safe choice. After the match, Brazil didn't get a winning start, and Morocco continued its tournament resilience. Copilot's prediction for this match was indeed a "stroke of genius."
But Copilot's issues also quickly surfaced.
It predicted Canada would beat Bosnia and Herzegovina 2:1, but they drew 1:1; predicted Switzerland would narrowly beat Qatar 1:0, but Switzerland was also held to a draw; predicted the USA would beat Paraguay 2:0—the direction was correct, but the actual score was 4:1, significantly underestimating the offensive intensity.
More obvious flops appeared in several upset matches and matches where strong teams were held back.
For Turkey vs. Australia, Copilot predicted Turkey to win 2:1, but Australia pulled off a 2:0 upset win. For Ecuador vs. Ivory Coast, it predicted Ecuador 2:1, but Ivory Coast won 1:0. For Netherlands vs. Japan, it predicted Netherlands 2:1, but Japan equalized twice, resulting in a 2:2 draw. For Sweden vs. Tunisia, it predicted 1:1, but Sweden directly won 5:1.
That Copilot could nail the exact scores for Mexico, South Korea, and Brazil matches shows it's not just giving answers favoring the favorites. But matches like Australia beating Turkey, Qatar drawing with Switzerland, and Japan drawing with Netherlands also expose that its judgment on upsets and draws is still relatively conservative.
ChatGPT: Analysis Is Comprehensive, But Not Sharp Enough on Upsets
Compared to Copilot's full schedule prediction, ChatGPT is more of a "pre-match analysis player."
In the opening match prediction, ChatGPT predicted Mexico 2:0 South Africa, hitting the final score. The reasoning it gave was also quite comprehensive, including Mexico's home advantage, recent form, South Africa's lack of attacking power, and factors like Mexico City's high altitude and home atmosphere. In this prediction, ChatGPT didn't just give a result; the underlying judgment logic also aligned with the match outcome.
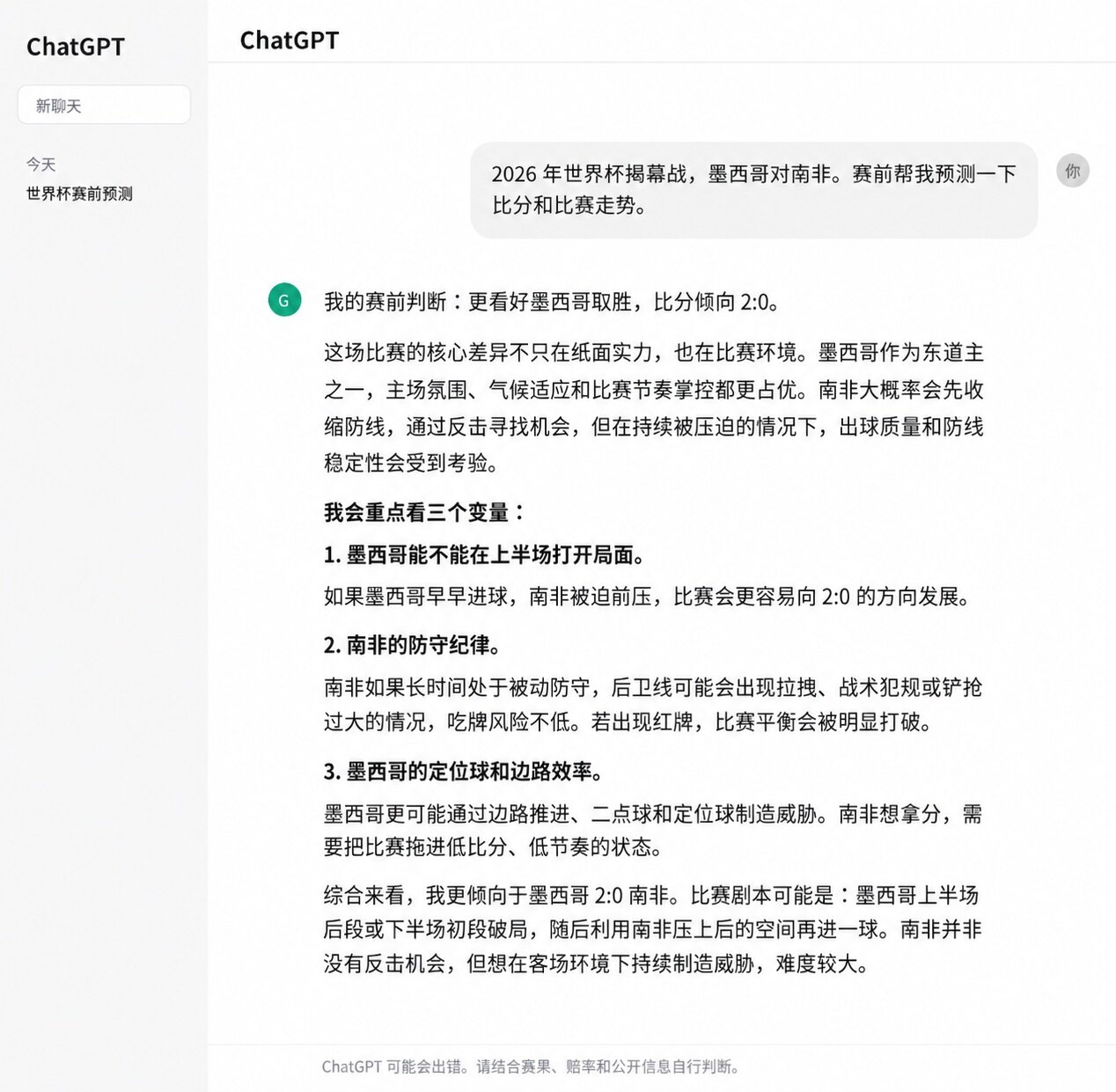
But when it comes to full World Cup schedule predictions, ChatGPT's stability isn't as strong. While it hit Mexico 2:0 South Africa and Brazil 1:1 Morocco, and correctly called the winner in several matches like Scotland, Germany, and Sweden, in matches like South Korea 2:1 Czech Republic, Qatar 1:1 Switzerland, Australia 2:0 Turkey, and Japan 2:2 Netherlands, ChatGPT's judgments all predicted the team with stronger paper strength. For example, Switzerland should beat Qatar, Turkey should beat Australia, the Netherlands should narrowly beat Japan.
ChatGPT isn't without predictive ability; it can break down team strength, home environment, and recent form clearly, and can hit the score in some matches. But based on current results, it's better at explaining "why the favorite is more reasonable" than identifying in advance which matches might deviate from the favorite's script.
Gemini, Grok, Claude: Different Models Write Different Scripts for the Same Match
Besides Qwen, Copilot, and ChatGPT, some social media users fed the same match to multiple models for pre-match predictions.
Taking the opening match Mexico vs. South Africa as an example, a blogger tested four AI models—ChatGPT, Gemini, Grok, and Claude—simultaneously for pre-match predictions. The results showed that ChatGPT and Gemini both predicted Mexico 2:0 South Africa, hitting the final score exactly; Grok predicted Mexico 2:1, Claude predicted Mexico 3:1; while both correctly saw Mexico winning, they didn't nail the exact score.
For this opening match prediction, different models gave three different "scripts." ChatGPT and Gemini Pro were closer to the actual match: Mexico dominant, South Africa lacking in attack, eventually kept scoreless. Grok seemed to give a more open scoreline, thinking South Africa would get a goal back from a counter. Claude Sonnet raised expectations for Mexico's attack higher, giving a more open 3:1 result.
Summary
Since the currently reviewable sample of AI predictions is still limited, we can't directly judge which model is the most "football-savvy" at this stage.
But just looking at the few matches that have concluded, differences are starting to show. Qwen currently has the most memorable performance, hitting Mexico 2:0 South Africa and South Korea 2:1 Czech Republic on the first day, and also stepping on red card risks and match flow, a highlight in a small sample. However, whether it can sustain accuracy needs more matches to verify.
Copilot and ChatGPT both have highlights of hitting exact scores, but also expose a common problem—their judgment still isn't sensitive enough when facing matches that deviate from paper strength, like Australia beating Turkey, Qatar drawing Switzerland, or Japan drawing the Netherlands.
As for models like Gemini, Grok, and Claude, currently public samples are more concentrated on single matches or social media comparisons, having reference value but not yet suitable for direct ranking.
AI can already serve as a layer of reference for World Cup prediction market users, but it's far from a standard answer. Next, Odaily Planet Daily will continue to collect pre-match predictions from various models and keep reviewing them as the tournament progresses: which models just had good luck at the start, and which models can truly withstand the test of results across more matches.





