Author: TechCrunch / Sensor Tower
Compiled by: Deep Tide TechFlow
Deep Tide Insight: News of OpenAI's collaboration with the U.S. Department of Defense (renamed the "Department of War" under the Trump administration) has triggered strong backlash among users.
Meanwhile, Anthropic gained user trust by refusing to cooperate, with Claude's daily downloads surging and topping the App Store. This data directly quantify the practical impact of AI ethics stances on user behavior.
Full Text:
On February 28 (Saturday), the number of U.S. users uninstalling the ChatGPT mobile app increased by 295% compared to the previous day. This reaction was directly triggered by the news of OpenAI's partnership with the U.S. Department of Defense (DoD)—a department renamed the "Department of War" during the Trump administration.
This data comes from market research firm Sensor Tower. Compared to ChatGPT's average 9% daily uninstallation rate over the past 30 days, the 295% single-day spike is a significant anomaly.
At the same time, downloads of Claude, developed by OpenAI's competitor Anthropic, saw a reverse trend in the U.S. On February 27 (Friday), downloads increased by 37% compared to the previous day, and on February 28 (Saturday), they rose by another 51%. Earlier, Anthropic announced its refusal to collaborate with the U.S. Department of Defense, citing an inability to agree on terms—Anthropic expressed concerns that AI would be used for surveilling U.S. citizens and deployed in fully autonomous weapon systems lacking safety capabilities.
The data indicates that a significant portion of users support Anthropic's stance on this issue.
ChatGPT's download numbers were also affected. On the Saturday following the announcement of the partnership, its U.S. downloads decreased by 13% compared to the previous day. The decline continued into Sunday, with another 5% drop. In contrast, on the Friday before the announcement, the app had recorded a 14% day-over-day growth in downloads.
These rapid changes were also reflected in Claude's App Store ranking. On Saturday, Claude climbed to the top of the U.S. App Store's free app chart, maintaining this position as of March 2 (Monday). This represents a rise of over 20 spots compared to about a week earlier (February 22, 2026).
Users also expressed their opinions on OpenAI's decision through app ratings. Sensor Tower data shows that on Saturday, the number of 1-star reviews for ChatGPT surged by 775%, with a further 100% increase on Sunday. Meanwhile, 5-star reviews decreased by 50% during the same period.
Other third-party data providers corroborated Sensor Tower's findings.
For example, Appfigures noted that on Saturday, Claude's total daily downloads in the U.S. surpassed ChatGPT's for the first time. The agency also observed an increase in Claude's U.S. downloads, though its estimates were higher: an 88% day-over-day increase on Saturday.
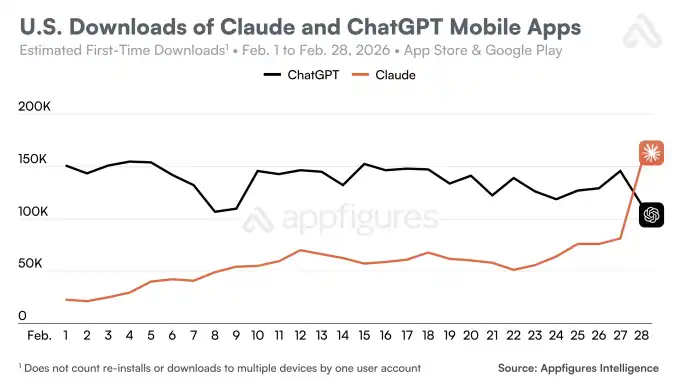
Appfigures also noted that Claude has now topped the free iPhone app charts in six countries outside the U.S., including Belgium, Canada, Germany, Luxembourg, Norway, and Switzerland.
A third market research firm, Similarweb, reported that Claude's U.S. downloads over the past week were approximately 20 times higher than in January. However, the agency cautioned that this may not be entirely due to political factors and could involve other reasons.





