One line of import, fine-tuning of MoE large models accelerated by 3.7x.
NVIDIA's latest research is now open source: NeMo AutoModel, designed specifically for large-scale building and fine-tuning of generative AI models.
Built on top of Hugging Face Transformers v5, NeMo AutoModel achieves faster fine-tuning of MoE models without changing the code API—just by adding one line of import.

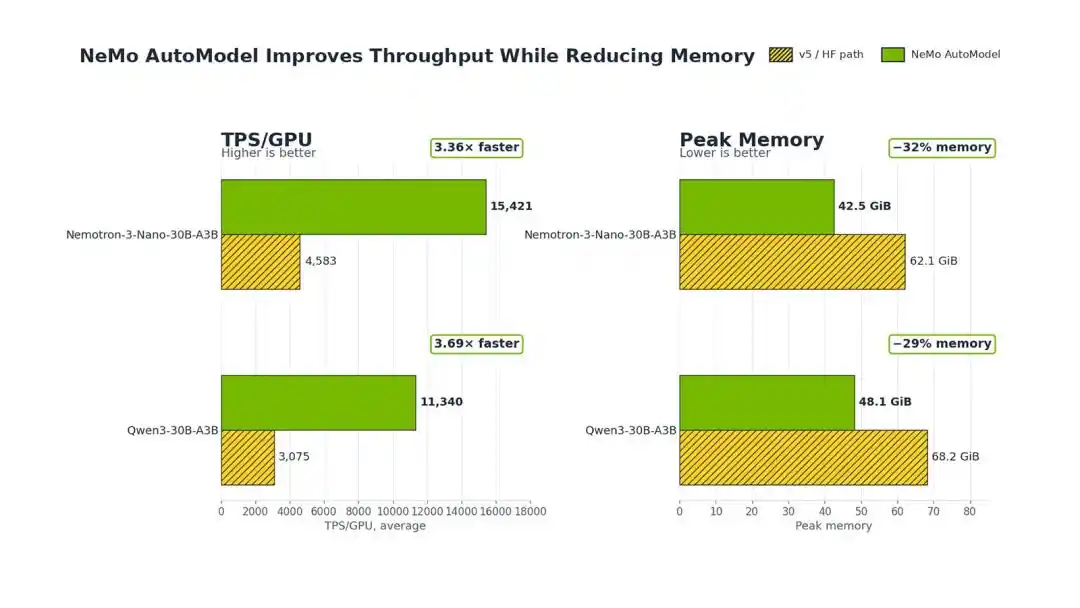
Experiments show that, compared to the original Hugging Face Transformers v5, NVIDIA's NeMo AutoModel can achieve a 3.4-3.7x increase in training throughput and reduce GPU memory usage by 29%-32% during MoE fine-tuning.
On a single node with 8x H100 80GB GPUs, using Qwen3-30B-A3B as an example, NeMo AutoModel directly increased the TPS/GPU (tokens per second per GPU) from 3075 to 11340, achieving a 3.69x improvement.
Core Technology Explained
MoE has become the mainstream architecture for cutting-edge models, but MoE also introduces new challenges for efficient training:
Expert parallelism, communication fusion, kernel optimization... these complex engineering tasks require supporting infrastructure.
HuggingFace's Transformers v5 is currently a widely used "universal base" for MoE training. V5 enhanced native support for MoE, introducing MoE foundational capabilities such as expert backends, dynamic weight loading, and distributed execution.

This time, NVIDIA's approach is to build on the shoulders of predecessors, maintaining compatibility with the HuggingFace Transformers API, allowing users to achieve higher training throughput and lower memory usage in MoE fine-tuning without significant code changes.
Specifically, NeMo AutoModel adds Expert Parallelism (EP), DeepEP, and TransformerEngine on top of Transformers v5.
Expert Parallelism
Expert Parallelism technology is primarily used to reduce memory pressure.
EP distributes expert weights across multiple GPUs; each GPU no longer holds all expert parameters entirely, but only holds a portion of them.
For example, with ep_size=8 across 8 GPUs, expert weights are distributed across 8 GPUs, reducing the MoE memory footprint on each GPU to 1/8 of the original.
Experimental results show that for Qwen3, this technology can reduce peak memory from 68.2 GiB to 48.1 GiB, a 29% reduction.
For the Nemotron Nanomo model, memory usage dropped from 62.1 GiB to 42.5 GiB, a 32% reduction.
The freed-up space can be used to support larger batch sizes and longer sequences.
DeepEP
DeepEP achieves the fusion of computation and communication.
In the traditional approach, there is significant communication cost between token distribution and expert computation. DeepEP integrates the token distribution and composition operations into optimized GPU kernels, overlapping the communication process with expert computation.
TransformerEngine
The TransformerEngine kernel provides acceleration for various core operations.
This technology offers implementations for fused attention mechanisms, linear layers, RMSNorm, etc., accelerating not only MoE layers but also regular Transformer layers.
One Line of Import, 3x Speed Boost
In summary, for those already using Transformers v5, NVIDIA's NeMo AutoModel offers a seamless upgrade path:
Just add one line of import code to achieve a 3x speed boost in MoE fine-tuning.

On Qwen3-30B-A3B and Nemotron 3 Nano 30B-A3B, compared to Transformers v5, this solution achieves a 3.4-3.7x increase in training throughput while reducing memory consumption by 29%-32%.
NVIDIA also demonstrated the results of full-parameter fine-tuning for Nemotron 3 Ultra 550B A55B on 16 H100 nodes with 128 GPUs.
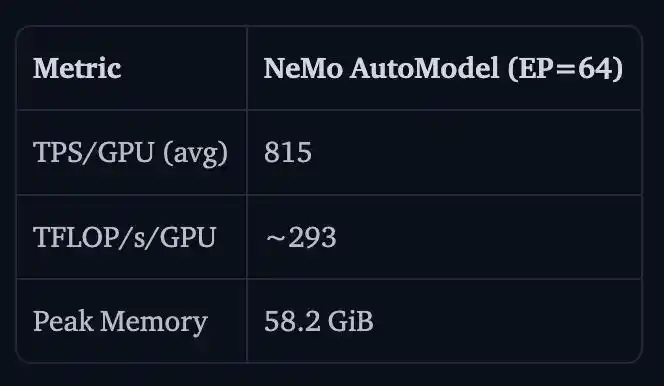
The TPS/GPU was 815, TFLOP/s/GPU was about 293, and peak memory was 58.2 GiB.
The reason for not comparing it with v5 here is that Transformers v5 would simply run out of memory at this scale ̄_(ツ)_/ ̄
If you're interested, NVIDIA has already placed the code, configurations, and benchmark scripts on GitHub: https://github.com/NVIDIA-NeMo/Automodel/tree/blog/transformers-v5-automodel/blog_experiments
The detailed usage guide is here: https://docs.nvidia.com/nemo/automodel/latest/get-started/hf-compatibility
This article is from the WeChat public account "Qubit," author: Yu Yang






