Over the past two years, video generation models have evolved rapidly, from the stunning effects of Sora at the end of 2024 to the multi-point explosion of video generation models like Google Veo, Sora 2, Kling series, and Seedance 2.0 earlier this year. The quality of AI-generated videos has undergone a qualitative leap, capable of producing movie-level realistic effects in videos lasting several minutes with multiple characters and complex scenes.
In contrast to the rapid progress on the generation side, research interest in AI-generated video detection has remained lukewarm.
Yet in reality, it's not hard to observe the significant social impact brought by the far greater deceptive potential of videos due to their multimodal nature:
On various social platforms, AI-generated fake videos frequently emerge, with their quantity, quality, and coverage rapidly increasing. When users ask foundational models like Grok or Doubao "Is this video AI-generated?", the answers often only provide binary judgments lacking in explainability and credibility. On platforms like Xiaohongshu, genuinely recorded videos are often labeled as "suspected AI-generated."
A vast chasm exists between the rapid development of generation and the lack of attention on the detection side. We must promptly address: in today's era of rapid AI video generation iteration, what stage has research on AI-generated video detection reached, what paradigm shifts is it undergoing, and what directions should it pursue in the future?
Against this backdrop, researchers from MBZUAI, Renmin University of China, and Harvard University jointly authored and published a comprehensive review, systematically organizing technical approaches for the first time from both visual and linguistic perspectives, spanning from low-level visual perception to high-level world reasoning. Based on this, the review analyzes the urgently needed multi-layered evidence-coupled dynamic, traceable, and explainable trustworthy detection system. The work has been accepted for publication at ACL 2026.

Paper Link:https://www.researchgate.net/doi/10.13140/RG.2.2.31713.88168
GitHub Link:https://github.com/dxhou/AI-Generated-Video-Detection
Homepage Link:https://AIgcvdetection.github.io
Redefining the Goal of AI-Generated Video Detection
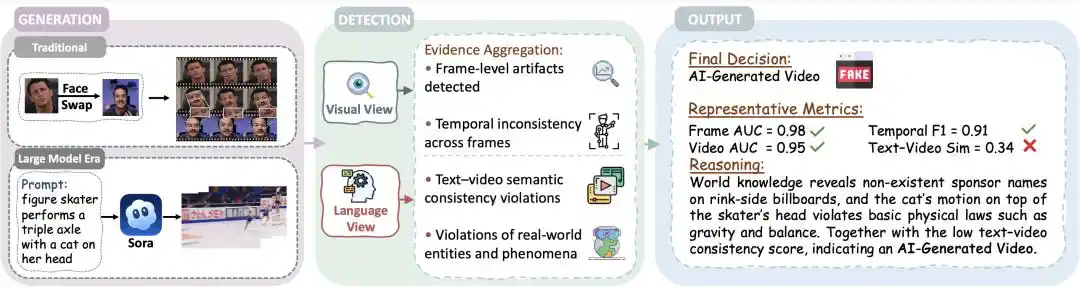
Figure 1 | The complete pipeline of AI-generated video detection: from generation side, dual-view detection, to evidence sets.
Before the explosion of generative AI, AI-generated videos left relatively obvious visual artifacts. Based on this premise, in early Deepfake scenarios represented by face-swapping, frame-level visual perception verification was sufficiently effective.
However, in the past two years, video quality in the rapidly developing era of generative AI has gradually surpassed this "premise". The human eye is increasingly unable to judge the authenticity of realistic, complete videos. At this point, detection that only outputs binary classification can no longer meet the demand. There is an urgent need to answer: on what evidence does the detector base its trustworthy judgment?
This review first pushes the boundaries of the detection problem forward: it argues that the detection output needs to shift from "true/false binary classification" towards interpretable, trustworthy structured judgment, thereby advancing the detection object to verifying the gap between the "virtual world" in the video and the "real world".
Therefore, the review first redefines the detection goal as "factual fidelity verification", which is to verify whether propositions about "who, when, where, what happened" in the video content are consistent and aligned with the real world both perceptually and cognitively. Beyond cross-modal verification between vision and other modalities, it requires further judgment on whether these propositions in the video content conflict with external "facts, physical laws, world knowledge, etc."
Detection Objects: Three Paradigms of AI-Generated Videos

Figure 2 | Three paradigms of AI-generated videos defined in this review.
From 2020 to the present, AI-generated videos have undergone a paradigm shift: from early Deepfake-era local modifications via GANs, to audiovisual recombination like lip-syncing and voice cloning, and then to the latent diffusion model-driven "world simulator"-supported full synthesis of AI videos (akin to Sora). The review classifies AI-generated videos into the following three paradigms:
Local Manipulation Video (LMV) with Real Carrier Retention
LMV has long been the most typical and mature paradigm for traditional Deepfake detection. The video itself modifies local regions of a genuinely recorded video, such as face-swapping or background replacement. However, most of the original video structure—scenes, character actions, camera motion, lighting relationships—usually remains. Therefore, most early methods focused precisely on local artifacts, frequency domain features, geometric anomalies, and regional consistency. As generative models' capabilities in local fusion, lighting adaptation, and identity transfer become increasingly stronger, and platform processing and secondary dissemination further erase many subtle traces, the detection focus for the LMV paradigm is gradually shifting more towards the robustness of detection methods across different scenarios.
Audio-Visual Editing (AVE) under Cross-Modal Coupling Constraints
The AVE paradigm emerged mainly in 2024. In this type of AI-generated video, what is altered are the established correspondences within the video itself—such as the relationship between the visual content and sound, lip movements, speaker identity, speech rhythm, subtitle content, etc. This includes speech-driven facial synthesis, re-dubbing original videos, modifying lip movements, or changing speakers. This shift forces the detection side to move from looking for visual artifacts to inspecting whether the relationships between several modalities within the video truly hold, examining audio, lip movements, identity, and content together to find truly discriminative clues.
End-to-End Generative Video Synthesis (GVS)
In the GVS paradigm, which exploded in 2025, models directly generate entire video sequences based on conditional information like text, images, or noise, no longer relying on a real video as a base, presenting entirely new challenges for detection.
These videos often appear very realistic in single frames or over short periods, but vulnerabilities tend to appear over long spatiotemporal sequences: for example, characters' actions or positions in scenes may fail to connect logically from start to finish; object shapes or movements may change in ways that violate physical laws; or the events depicted in the video may be impossible in the real world.
Correspondingly, detection approaches for the GVS paradigm cannot be confined to local or inter-modal consistency. They need to move towards higher levels, starting from long-range consistency, common sense, physical laws, narrative and causality, proposition-level truthfulness, and traceability. Detection must verify over long sequences whether the content itself is plausible, examining whether the video content can hold true across all levels within the constraints of the real world.
Four-Layer Taxonomy of Detection Methods from a Vision-Language Dual-View Perspective
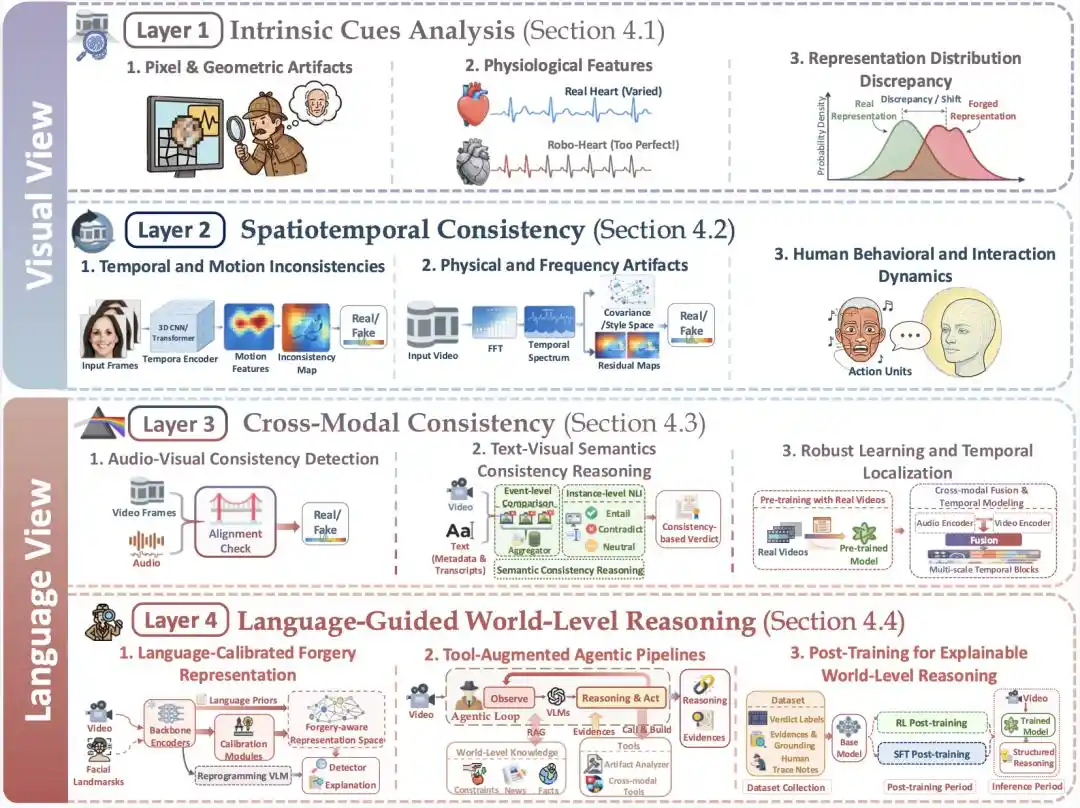
Figure 3 | Vision-Language Dual-View four-layer framework: the first two layers lean towards the visual perspective, the latter two move towards the linguistic perspective.
Currently, the modal perspectives for AI-generated video detection have diverged, forming two core scientific problems. The first starts from the visual modality, focusing on low-level signal forensics and spatiotemporal consistency of the visuals. The other starts from the language modality, focusing on cross-modal linguistic information within the video itself—judging "whether the video is narrating coherently with good cross-modal alignment"—and leveraging the language modality to introduce reasoning related to world knowledge and facts, judging "whether the video content can withstand scrutiny against external real-world knowledge, facts, and laws."
Capturing this trend, the review proposes organizing AI-generated video detection research methods and evaluation paradigms from a Vision-Language Dual-View perspective. Based on this, it further proposes the following four-layer landscape of methods, progressing from low-level perception to high-level cognition:
Layer 1, Intrinsic Cues Analysis: The First Screening Net
Methods in Layer 1 address the research question: At the level of low-level visual signals, does the video conform to the statistical patterns that real videos must satisfy, and does the video contain low-level cues introduced by AI model generation or editing operations?
At the low-level signal level, real videos satisfy corresponding statistical properties, and videos obtained through real capture and processing naturally align with the acquisition, encoding, and post-processing pipelines. In contrast, the AI generation process often leaves behind clues that deviate from the real video distribution: monotonous stylistic patterns, model-specific watermarks and artifacts, detectable artificial physiological signals, etc. Methods within this first layer take a visual perspective, performing forensics by modeling, extracting, and amplifying these low-level signals. This includes detecting:
- Pixel and geometric anomalies like frequency domain patterns, textures, boundaries, noise patterns.
- Physiological signals on human faces like pulse coupling, subtle muscle movements, and blinking rhythms.
- Whether systematic shifts exist in the feature space between real and fake videos.
Layer 2, Spatiotemporal Consistency: Checking "Does the Video Flow Smoothly?"
Methods in Layer 2 address the concept of "sequential combination of multiple video frames across space and time." The research question they focus on is: In the spatiotemporal dimension, does the image stream of the video exhibit characteristics that real videos' object motion processes must satisfy? Real captured videos are constrained by continuous camera trajectories and real environmental scenes; objects and backgrounds between adjacent frames exhibit continuous, predictable spatiotemporal change patterns consistent with physical feasibility and camera motion. In contrast, AI-generated videos may exhibit spatiotemporal discontinuities over longer sequences, such as object or background distortion, sudden local blurring, etc. This includes detecting:
- Temporal and motion inconsistencies like local object deformation, background drift, sudden blurring, motion residue anomalies.
- Human behavior and interaction dynamics like expression changes, identity dynamics, interaction rhythms between characters in the scene.
- Physical and frequency anomalies related to temporal frequency and visual continuity.
Layer 3, Cross-Modal Consistency: Multi-Modal Verification Within the Video
Layer 3 represents a crucial turning point in the entire framework: detection begins to enter the realm of multi-modal verification within the video. The research question it focuses on is: Are the various modalities within the video—visuals, audio, subtitles—"telling the same story" across all levels?
Real videos often exhibit high alignment between accompanying audio, text, and visuals. AI-generated videos may exhibit systematic mismatches: lip movements–speech, identity–voiceprint, visuals–text. Third-layer methods perform fine-grained, multi-angle consistency analysis of inter-modal alignment. This includes three types:
- Detecting consistency between sound and visuals.
- Introducing subtitles, titles, transcribed text, or descriptive text for text–video semantic consistency reasoning.
- Robust learning oriented towards temporally localizing inter-modal inconsistencies.
Layer 4, Language-Guided World-Level Reasoning: Focusing on the Gap Between Video and the Real World
Layer 4 elevates the detection perspective from "internal consistency of the video" to "consistency with rules and knowledge in the external real world." The research question shifts to: At the semantic and factual level, is the video content plausible or possible in the real world?
All content in a real video should align with facts, physical laws, domain knowledge, common sense, etc., from the real world. AI-generated video content often struggles to fully align with the real world, which is precisely the detection space utilized by the fourth layer. This includes:
- Using prompts, textual priors, text prototypes, or lightweight modules to recalibrate the model's representation space, making it easier for the model to correlate observed anomalies with more explicit semantic categories.
- Treating detection as an investigation process, constructing an investigator agent that can consult sources, call tools, and revise judgments, linking judgments to evidence, tool outputs, and verification processes.
- Through fine-tuning, preference learning, reward modeling, and reinforcement learning, training into the model itself "how to select evidence, how to organize explanations, how to reach conclusions," focusing on producing clear, structurally stable, and evidentially complete detection outputs.
Evolution Map of Generation Side and Detection Side
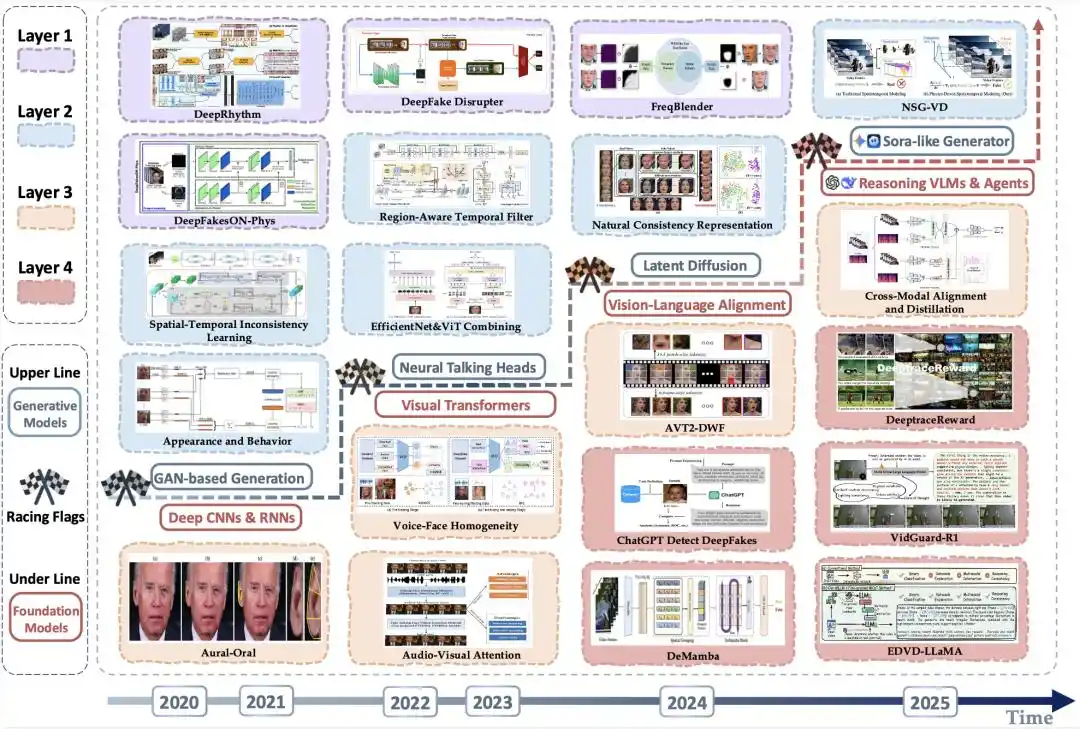
Figure 4 | Evolution map of representative detection methods: escalating generation-side threats and advancing detection capabilities progress in parallel.
The figure above presents, along a timeline, the continuous elevation of the "realism ceiling" achievable by fake videos on the generation side. Against the backdrop of the evolution of the foundational models underpinning detection technology—from deep convolutional and recurrent networks, to Vision Transformers, and then to reasoning-capable Vision-Language Large Models and agent systems—the figure shows the progression of the detection side from visual forensics towards multimodal verification and high-level reasoning-based detection.
The review further provides temporal statistics on the distribution of detection methods across layers: the proportion of methods focusing on Layers 3 & 4 was only 7.7% in 2020, rose to 40.0% in 2023, and exceeded 50% in 2025.
Overall, the focus of detection methods is continuously shifting upwards: early efforts were concentrated primarily in Layers 1 and 2. As generated videos become smoother and more realistic, detection is increasingly moving into Layers 3 and 4.
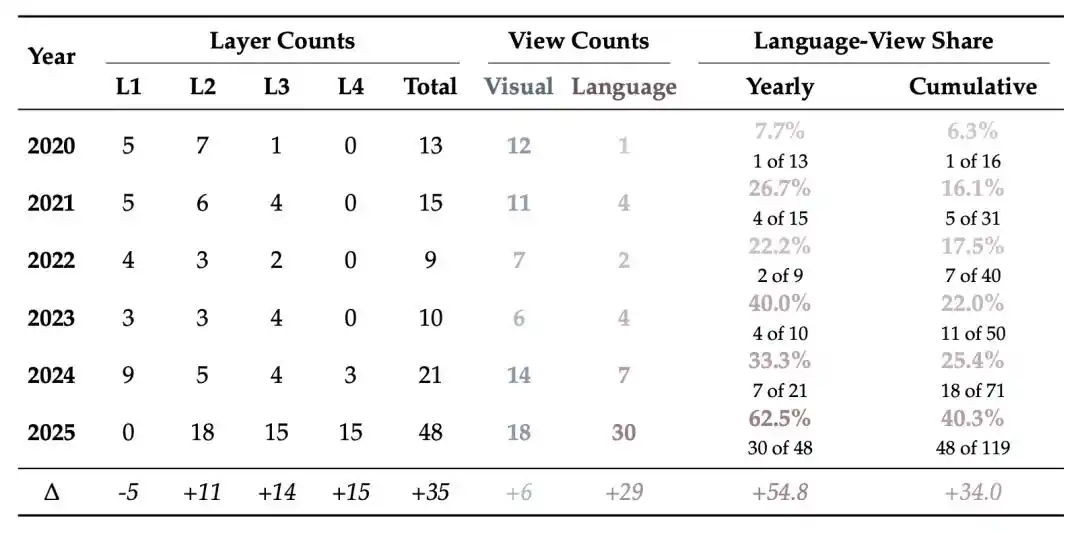
Figure 5 | Statistical change in distribution of detection methods: proportion of language-perspective methods gradually rises.
Evaluation of Detection Methods
Facing the goal of factual fidelity verification, evaluating detection methods needs to answer: does the model capture transferable visual cues? Can it identify spatiotemporal and cross-modal inconsistencies? Can it effectively judge against facts, knowledge, and world constraints? The review systematically traces the evolution of evaluation metrics and datasets from the traditional Deepfake era to the present day.
Evaluation Metrics from a Vision-Language Dual-View
Shared Metrics: Acc / AUC Remain Necessary but Are Far from Sufficient
Accuracy, AUC, Precision, Recall, F1, Equal Error Rate (EER), PR-AUC, and aggregation methods (frame-level vs. video-level) remain the most basic common language for comparing different methods, enabling horizontal comparison across methods from different layers. However, while these fundamental evaluation metrics are still necessary, they are insufficient to meet the requirements for explainable, trustworthy evaluation under the goal of factual fidelity verification.
Metrics from the Visual Perspective: Assessing Robustness Under Real-World Interference
The evaluation focus here is on whether the detector's original cues remain valid when faced with distribution shifts, compression during dissemination, and real-world environmental interference. It is divided into two categories:
- Robustness of Low-Level Cues: Includes metrics like TPR@FPR=α at fixed thresholds, cross-dataset testing, perturbation stress tests, etc.
- Spatiotemporal and Physical Consistency: Focuses on video-level reporting, temporal perturbation drop, motion ablation, and assessing whether the model significantly degrades when temporal information is removed, thereby evaluating if the detector is genuinely examining the continuity of the entire video sequence rather than relying on shortcuts from single frames.
Metrics from the Language Perspective: Multimodal Localization and Reasoning Evaluation
The coverage of detection approaches from the language perspective is broader; a simple set of classification metrics can no longer summarize evaluation. The review proposes the following layered categorization:
- Cross-Modal Alignment and Temporal Localization: These evaluation metrics assess the accuracy of detection in cross-modal alignment and the detector's ability to localize clues to specific time segments. Beyond basic Acc and AUC, common metrics also include Average Precision (AP), Average Recall (AR), Recall@K, mAP@IoU, etc.
- World Knowledge and Reasoning: Facing the higher-level question "Can the events depicted in the video be supported by common sense, physical laws, external knowledge, and concrete evidence?" The evaluation metrics for detection need to introduce human judgments, pairwise preferences, question answering, and metrics for evaluating explanation quality like BLEU, ROUGE-L, METEOR, CIDEr, and embedding-based similarity.
Datasets: Reorganized According to the Three Paradigms of Detection Objects
Most datasets used for training and evaluating detection methods naturally diverge along the aforementioned AI-generated video paradigms. The review organizes them as follows:
- Datasets for the LMV Paradigm: Evaluation focus is primarily on the stability of visual cues used by detection methods and whether these cues remain effective under distortion, compression, and cross-domain dissemination conditions. These datasets are increasingly incorporating temporal reasoning and explainability evaluation to approach real-world conditions.
- Datasets for the AVE Paradigm: These datasets often emphasize fine-grained temporal annotations, clearer cross-modal correspondences, and stronger modeling of local misalignments and semantic mismatches. They test whether models can detect when audio and video are not conveying the same content, locate the time segments where misalignments occur, and distinguish between synchronization issues, identity issues, and semantic issues.
- Datasets for the GVS Paradigm: Fully synthetic videos, on one hand, continuously weaken explicit editing traces; on the other hand, they persistently present challenges to detection such as generator diversity, semantic misalignment, and transfer risks. Correspondingly, evaluation for this paradigm is evolving most rapidly—from early efforts collecting large volumes of fully synthetic videos to evaluate detection accuracy, to works like LOKI, GenWorld, DAVID-X, and DeeptraceReward that incorporate world simulation, defect-level annotations, and human-perceptible forgery cues into the evaluation system.
Related Evaluations for Video Generation Model Diagnosis
Evaluation resources related to detection are not limited to datasets targeting detection itself. In fact, within CV and world model research, many diagnostic evaluations targeting the generation quality of video generation models and evaluations assessing the error identification capabilities of video understanding models can also serve as important references for detection. The review organizes these complementary diagnostic evaluation works according to a progressively advancing evaluation chain:
- First, check whether objects, attributes, interactions, and state changes in the video conform to basic physical laws.
- Next, examine world dynamics and causality—whether local patterns can extend throughout the entire video sequence to form continuous, coherent event processes consistent with world knowledge.
- Finally, assess whether systems like video understanding models can transform various levels of errors in generated videos into explicit, understandable, and verifiable judgments.
From "Can Distinguish" to "Can Provide Evidence"
High-fidelity AI-generated videos are continuously raising the realism ceiling of forged content. The problem facing the detection task is increasingly difficult to summarize with a simple real/fake score; it necessitates factual fidelity verification. Correspondingly, the evaluation stage and detection systems also need to expand along with this extended task boundary:
Evidence-First Dynamic Evaluation System
Facing newly emerging AI-generated complex videos with long temporal spans, evaluation needs to answer not just "can the model classify?" but also "on what evidence did the model base its correct or incorrect judgment?". Coarse-grained evaluation labels can obscure a great deal of truly critical information. Data annotation, model training, and result reporting in evaluation need to advance together. There is a need to decompose videos back into verifiable propositional units, transforming "long sequential narratives" into operable structured objects like event chains, entity state trajectories, or event graphs, to facilitate causal and constraint verification over long timescales. This allows further interrogation of "which specific propositions did the detection capture" and "whether evidence and judgment correspond one-to-one."
Furthermore, most detectors are still evaluated under a "closed world" assumption. In real deployment scenarios, new video generation models, editing tools, and content styles continuously emerge, and different platforms introduce their own downsampling, transcoding, and filtering pipelines. To bridge this long-term robustness gap, there is a need to adopt arena/leaderboard-style continuous update mechanisms, incorporating newly released generators and new platform transcoding pipelines into the evaluation set in a streaming fashion.
Collaborative Dual-View Trustworthy and Explainable Detection System
To achieve the explainable detection for the aforementioned factual fidelity goal, it is necessary to balance the perception–cognition dual pathways, combining the ability of the visual perspective to reveal visual artifacts and spatiotemporal inconsistencies with the ability of the high-level linguistic perspective to perform structured reasoning, thereby integrating the four-layer method landscape across the dual views. On one hand, current vision-language models and video understanding models perform relatively poorly on judgments related to "perceptual fidelity," requiring supplementation by visual-perspective methods. On the other hand, for videos generated by stronger generation models and anti-detection techniques that are highly perceptually faithful, detection at the semantic and factual level using a linguistic perspective is necessary.
Further, it is essential to establish an explicit reasoning path of "identification–localization–explanation." This means that within the aforementioned dual-pathway system, every tool call or knowledge reference must be strictly bound to a specific argumentation step.
Additionally, the detection system constituted on the "content side" above needs to cross-verify with potentially existing "source-side" authentication signals, etc., connecting content analysis with source tracing. Ultimately, this forms a cross-layer, multimodal detection system alongside a trustworthy, explainable evidence space.
Conclusion
AI video detection is a task that will only become more challenging.
For future AIGC-V detection research and practical applications, this review provides a map closer to real-world needs. It redefines the task of AI-generated video detection, proposes a "Vision–Language Dual-View" four-layer framework, and systematically organizes existing methods, related benchmarks, and evaluation metrics accordingly. It also connects these layers to challenges in real deployment, gaps in current evaluations, and emerging development directions.
Following this framework, it points out several key requirements for trustworthy detection, including evidence-first prioritization, traceable conclusions, and maintaining robustness across generators and real-world conditions.
Looking ahead, trustworthy AI video detection can hardly be accomplished by any single field independently. It is becoming a cross-disciplinary issue that requires joint attention from CV, NLP, multimodal understanding, and world model research: CV provides spatiotemporal evidence modeling and forensic robustness; NLP provides proposition decomposition, reasoning, evidence grounding, and explanatory capabilities; multimodal and world model research provides stronger cross-modal alignment capabilities and richer priors regarding physics, causality, and temporal consistency.
Only by truly integrating these capabilities can video detection gradually move beyond the search for local artifacts towards a more rigorous "view of reality": the question is no longer just whether a video looks plausible, but whether its entities, events, and dynamic processes remain faithful to the constraints of the real world—searching for the increasingly blurred boundary between the virtual world and the real world.
References: https://www.researchgate.net/doi/10.13140/RG.2.2.31713.88168
This article is from the WeChat public account "新智元", edited by LRST.