Just now, DeepSeek-V4 is here!
The preview version is officially launched and simultaneously open-sourced.
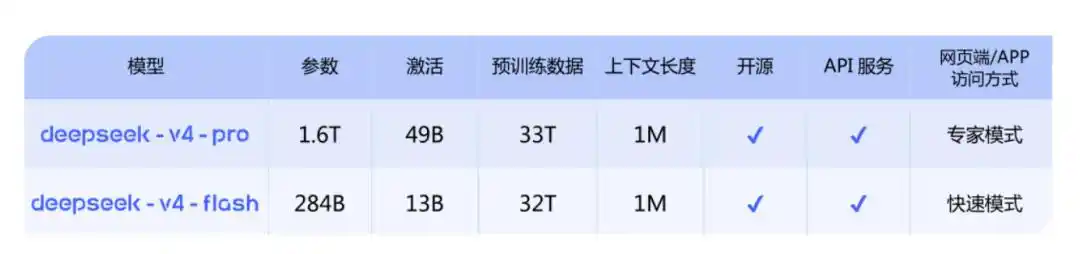
There are two versions in total:
DeepSeek-V4-Pro: Comparable to top closed-source models, 1.6T, 49B activated, 1M context length;
DeepSeek-V4-Flash: A smaller and faster economical version, 284B, 13B activated, 1M context length.
The official statement is: It leads domestically and in the open-source field in Agent capabilities, world knowledge, and reasoning performance.
And:
Currently, DeepSeek-V4 has become the Agentic Coding model used by company employees. According to evaluation feedback, the user experience is better than Sonnet 4.5, and the delivery quality is close to Opus 4.6 non-thinking mode. However, there is still a certain gap compared to the Opus 4.6 thinking model.
Currently, both the official website and the app have been updated, and the API service has also been synchronized.
Regarding the much-concerned domestic computing power, the key point is: Support for Huawei computing power in the second half of the year.

Top-Tier and Cost-Effective Choices, Two Versions Launched Together
This time, V4 releases two versions at once.
V4-Pro, performance comparable to top closed-source models.
The official judgment has three points:
Significantly improved Agent capabilities: In the Agentic Coding evaluation, V4-Pro has reached the best level among current open-source models and also performed excellently in other Agent-related evaluations. In internal evaluations, in Agent Coding mode, the V4 experience is better than Sonnet 4.5, and the delivery quality is close to Opus 4.6 non-thinking mode, but there is still a certain gap compared to the Opus 4.6 thinking mode.
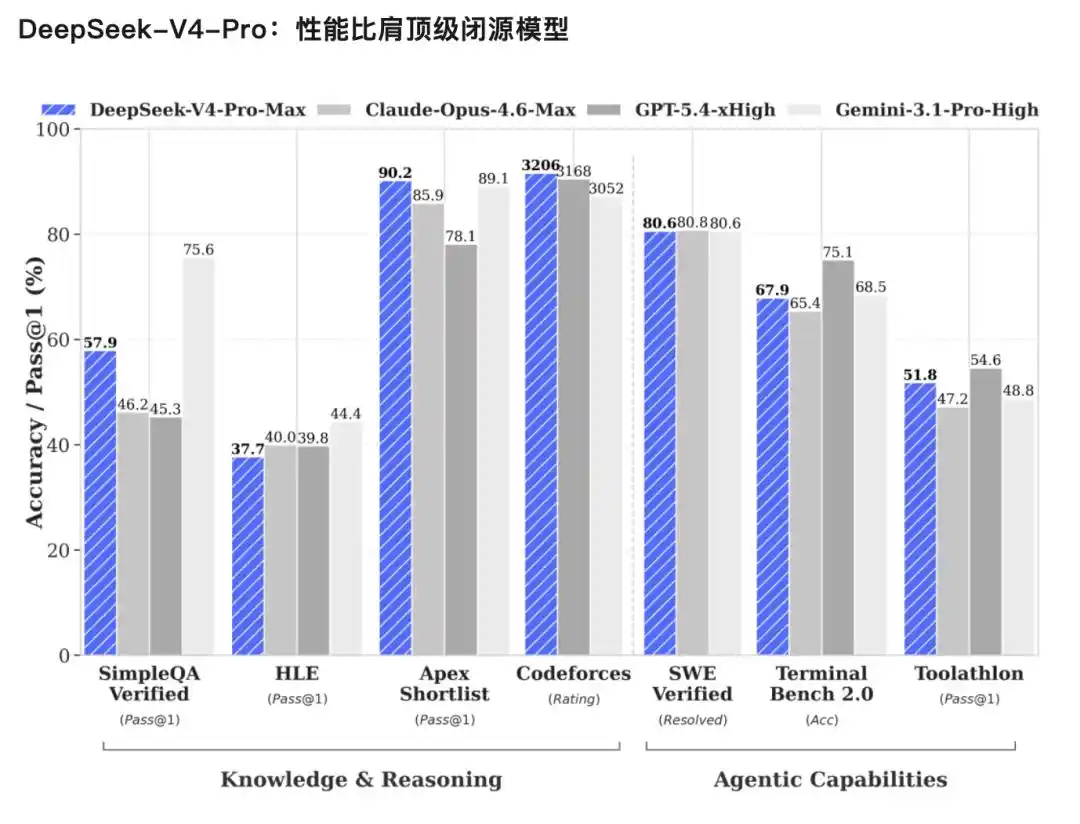
Rich world knowledge: In world knowledge evaluations, DeepSeek-V4-Pro significantly leads other open-source models, only slightly inferior to the top closed-source model Gemini-Pro-3.1.
World-class reasoning performance: In evaluations of mathematics, STEM, and competitive code, DeepSeek-V4-Pro surpasses all currently publicly evaluated open-source models and achieves excellent results comparable to the world's top closed-source models.
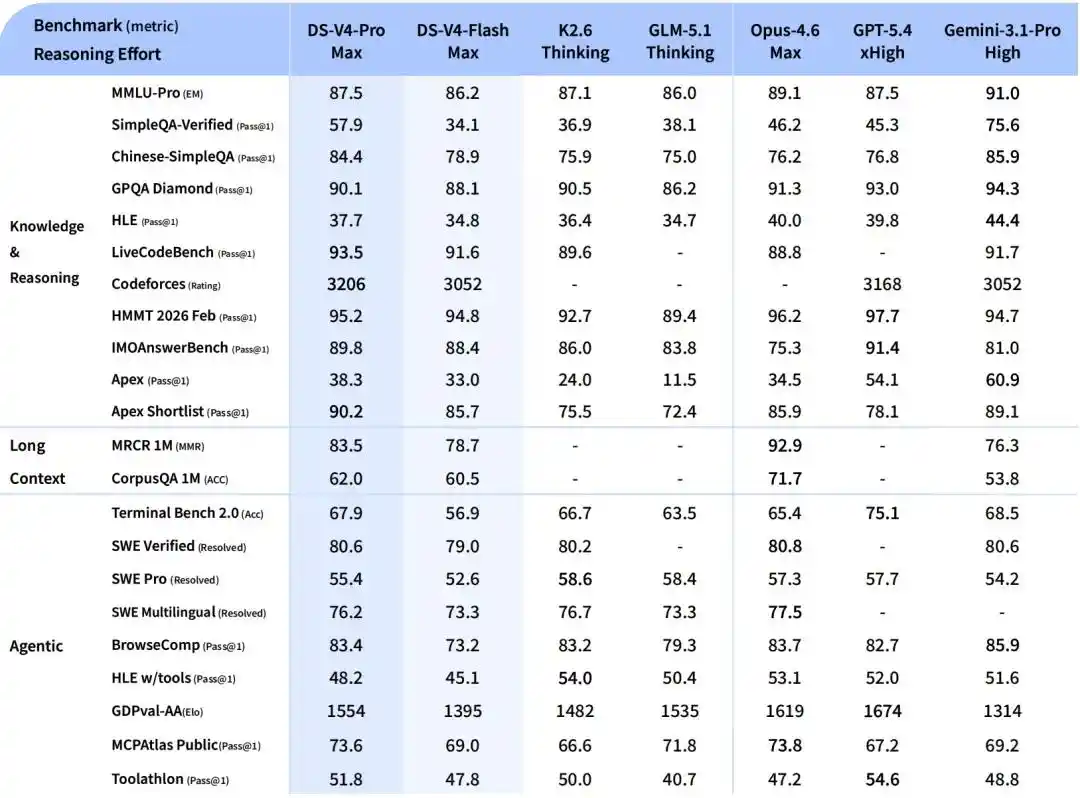
V4-Flash, a smaller and faster economical version. Reasoning ability is close to Pro, world knowledge reserve is slightly inferior, but with smaller parameters and activation, and cheaper API.
In Agent tasks, DeepSeek-V4-Flash is on par with DeepSeek-V4-Pro in simple tasks, but there is still a gap in high-difficulty tasks.
In the car wash test, V4 also passed quickly.

In the classic biological scenario "Desperate Father," DeepSeek-V4 did not immediately grasp the key point of red-green color blindness in one round (according to genetic rules, if a female is red-green color blind, her biological father must be as well).

Million Context Length Becomes Standard
It is worth mentioning that from today, 1M context length is standard for all DeepSeek official services.
A year ago, 1M context length was Gemini's exclusive trump card; all other closed-source models were either 128K or 200K; on the open-source side, almost no one could afford this level.
DeepSeek directly moved the million context length from a "high-end feature" to "basic infrastructure."
And it's open source. How did they do it? The release directly gave the answer—
V4 has created a new attention mechanism that compresses at the token dimension and is used in combination with DSA sparse attention. Compared to traditional methods, the demand for computation and memory is significantly reduced.
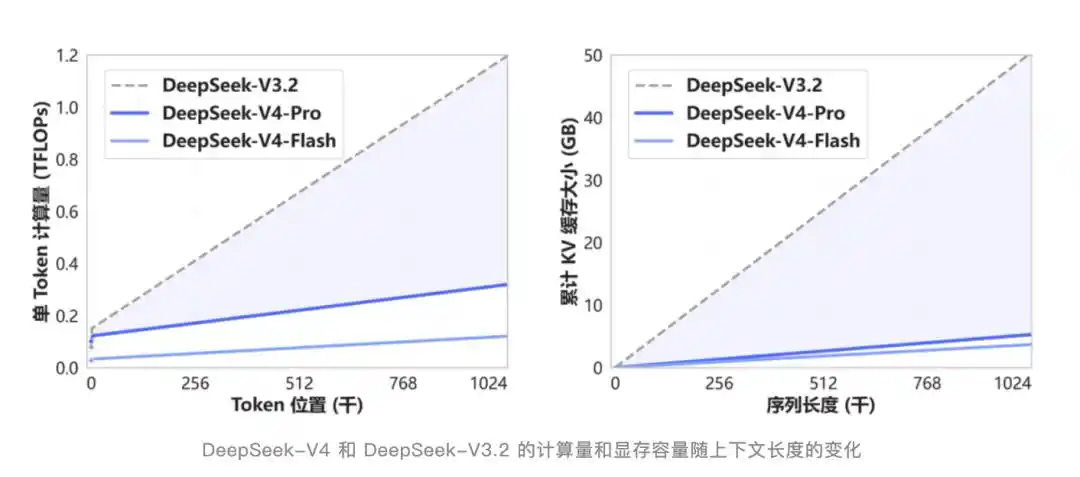
DSA is not a new term. It was first introduced in the V3.2-Exp update half a year ago. At that time, external attention was low because the benchmark scores were almost the same as V3.1-Terminus, making it seem like an insignificant intermediate version.
Looking back now, that was the foundation of V4.
Special Optimization for Agent Capabilities
On the Agent side, V4 has been adapted and optimized for mainstream Agent products such as Claude Code, OpenClaw, OpenCode, CodeBuddy, etc., with improvements in code tasks and document generation tasks.
The release also included an example of a PPT inner page generated by V4-Pro under a certain Agent framework.

API Pricing
On the API side, V4-Pro and V4-Flash are simultaneously launched, supporting both OpenAI ChatCompletions interface and Anthropic interface.
The base_url remains unchanged, just change the model parameter to deepseek-v4-pro or deepseek-v4-flash to call.
Both versions have a maximum context length of 1M and support both non-thinking mode and thinking mode. In thinking mode, the intensity can be adjusted through the reasoning_effort parameter, with two levels: high and max. The official recommendation is to directly use max for complex Agent scenarios.
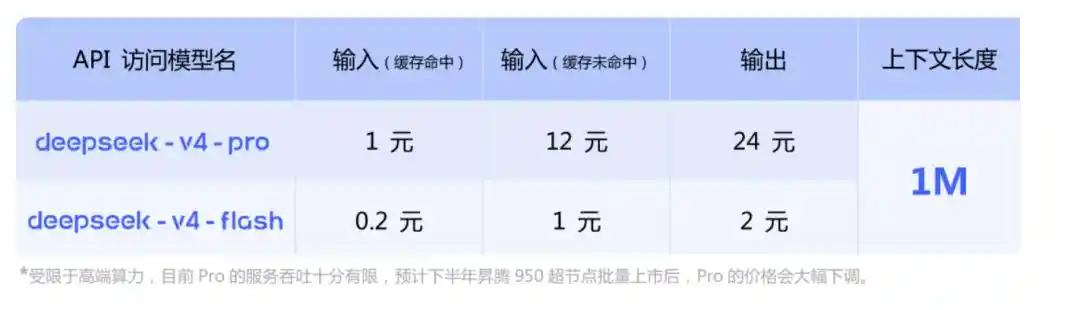
Here is a key point—Support for Huawei computing power in the second half of the year.
In addition, old model names will be discontinued.
deepseek-chat and deepseek-reasoner will be discontinued three months later (July 24, 2026). During the current phase, these two names point to the non-thinking and thinking modes of V4-Flash, respectively.
It has little impact on individual developers; just change one model parameter. Companies with production environments need to migrate during these three months.
One more thing
At the end of the release, DeepSeek quoted a sentence.
"Not tempted by praise, not frightened by slander, follow the path and act,端正自己端正自己 (correct oneself)."
This is a sentence from Xunzi's "Non-Twelve Masters." The literal meaning is: not tempted by praise, not frightened by slander, move forward according to the path one believes in, and correct oneself.
In today's context, it's somewhat interesting.
Over the past six months, rumors about when V4 would be released, whether it was delayed, whether it had been surpassed by others, whether it had been compromised by Claude's distilled data, etc., have circulated back and forth in both Chinese and English AI circles. At the beginning of the year, some even confidently said that V4 would be released before the Spring Festival, but it wasn't until the end of April.
They never responded once.
Then, on a Friday afternoon, they released V4, simultaneously open-sourced it, simultaneously launched it on the official website and app, simultaneously updated the API, and even wrote into the release that internal employees have already abandoned Claude.
No roadmap, no live stream, no interviews.
The four words "率道而行" (follow the path and act) sound like a slogan. But if you look at the path over the past six months: the V3.2 "unremarkable" Exp version, the DSA sparse attention that paved the way for V4 for half a year, and the path of making 1M context length from a trump card to a standard feature.
DeepSeek has already done it.
DeepSeek-V4 model open-source links:
[1]https://huggingface.co/collections/deepseek-ai/deepseek-v4
[2]https://modelscope.cn/collections/deepseek-ai/DeepSeek-V4
DeepSeek-V4 Technical Report: https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf
This article is from the WeChat public account "QbitAI", author: QbitAI





