AI as the "Boss", Nearly Bankrupts 10 Companies......
Princeton University recently created CEO-Bench, allowing AI to operate a virtual SaaS startup for 500 days.
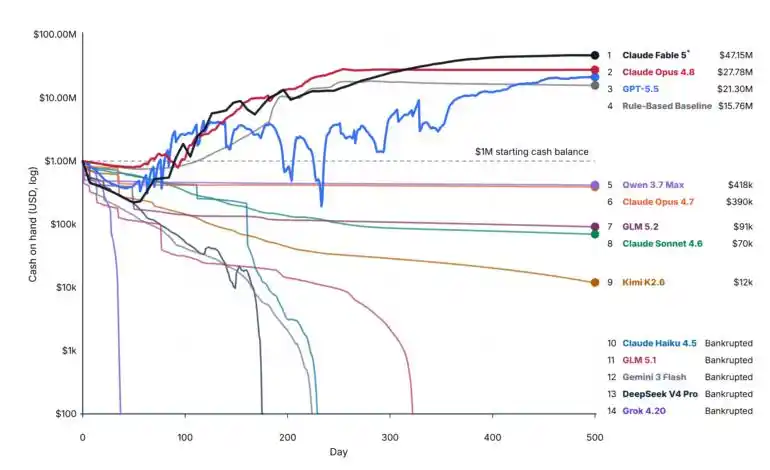
Who would have thought, out of 14 silicon-based CEOs taking the stage, only four preserved their initial capital.
And this fourth place, was a pure rule-based algorithm......

AI autonomously running a company? Having AI as the boss??
At least for now, it's still a big question mark.
Of course, there are also some highly capable models that have already shown potential——
Fable 5, $47.15 million in revenue after 500 days, the world's strongest "AI Boss".
The AI CEO Competition
Before officially watching this scene of "AI epic fails", let's explain the rules of the game.
Starting state: $1 million in capital, zero customers.
Game objective: Make as much money as possible within a 500-day simulation cycle.
Judging criteria: How much money is left in the account at the end of the game. If the balance drops below zero midway, bankruptcy is declared immediately, and the simulation terminates.
Pretty easy to understand, similar to playing Monopoly, just with a different interaction method.
The core is a Python API containing 34 tools and 19 database tables. After an Agent connects, it can write code, query the database with SQL, and dynamically adjust workflows based on the query results.
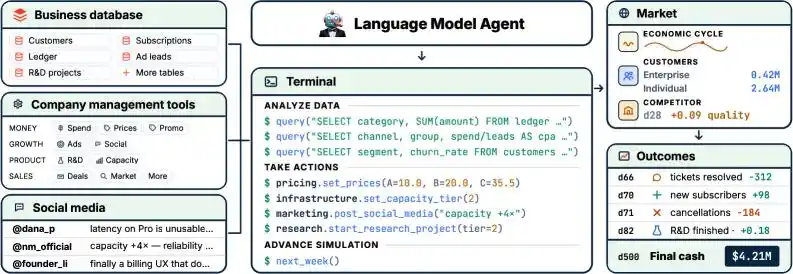
The variables in the gaming environment are also much more complex.
Pricing strategy, advertising channels, R&D budget allocation, infrastructure scaling, customer service team configuration——all must be decided independently.
There's even a simulated social network where the AI can browse posts, see customer complaints, and spy on competitors.
Basically, it can control everything in the company, with unlimited authority, exactly like a human CEO.
But this also means no one is typing instructions into a dialog box anymore. The model must take sole responsibility for every judgment.
This is also the most interesting part of this "Hunger Games"——
After launching an ad, customers might come next week; after pouring money into R&D, product quality improvements take days......
Costs can burn through capital immediately. Returns, are delayed for a long time.
This is the "uncertainty" CEOs fear most—one wrong step triggers a chain reaction.
Want to use a statistical approach, brute force style? Sorry, key variables are all "implicitly" present.
Customer satisfaction, willingness to pay, minimum quality expectations—these metrics can only be inferred from churn rates, ticket volumes, and the social network.
Meanwhile, the external environment is constantly changing dynamically: competitors play dirty tricks, market preferences drift over time, and there are macroeconomic cycles......
This is a "hell-level" difficulty long-range decision-making task.
The context is too explosive, impossible to wait until all information is denoised before making a decision; human CEOs often rely on intuition too.
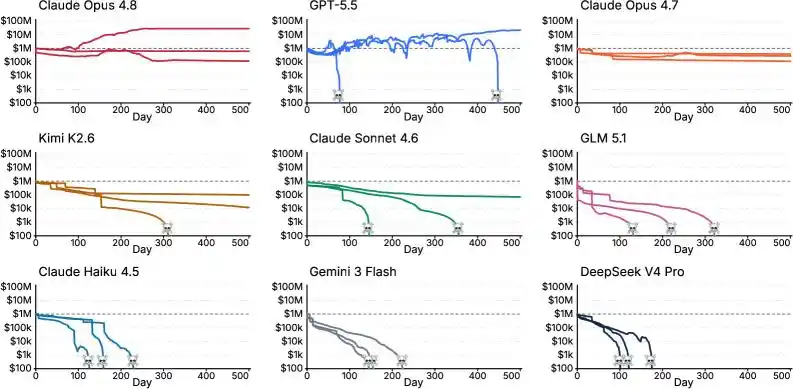
As it turns out, the results were indeed brutal.
Among the 14 contestants, the vast majority lost their shirts, almost.
GLM 5.1, Claude Haiku 4.5, Gemini 3 Flash, DeepSeek V4 Pro, Grok 4.20—these five met their demise mid-journey, not even finishing the race, "bankrupt" and out with regret.
Only 3 AIs made a positive profit:
Claude Fable 5, $47.15 million;
Claude Opus 4.8, $27.80 million;
GPT-5.5, $21.30 million.
The champion is Fable 5—the world's best model at being a "boss".
An undisputed first place, multiplying the initial capital by 47 times, leading the second-place Opus 4.8 by a large margin.
Moreover, Fable 5 was the only model that achieved profits exceeding the initial capital in more than one run.
(btw, safety restrictions are still at work; Fable 5 refused to respond multiple times.)
But this isn't the most exciting part.
Actually, there were four contestants that made money, except the fourth one wasn't an LLM......
Besides the top three best "capitalists", the contestant in fourth place——
was a purely rule-based heuristic algorithm.
It didn't call any language model at all. Fixed pricing, fixed quotas, fixed tiers......all were pre-designed rules in a script.
Would you believe it, this "Forrest Gump" earned $15.76 million.
Surpassing all models except Fable 5, Opus 4.8, and GPT-5.5. Including Qwen 3.7 Max, Opus 4.7, GLM 5.2, Kimi K2.6......
Takeaways
Quite dramatic.
However, the insights that can be distilled from this process might be more valuable than the competition results.
This paper has two core takeaways——
Exploration > Caution
This is a relatively intuitive finding.
From the model memorandums, we can see that GPT-5.5 and Claude Opus 4.8 kept trying new strategies as situations changed, whether increasing customer acquisition efforts, adjusting tiers, or modifying support and R&D budgets.
In contrast, Claude Opus 4.7 mainly adopted cost-cutting and cash-preserving strategies when encountering setbacks.
This conservative playstyle, while allowing the model to survive until the end, couldn't generate profit.
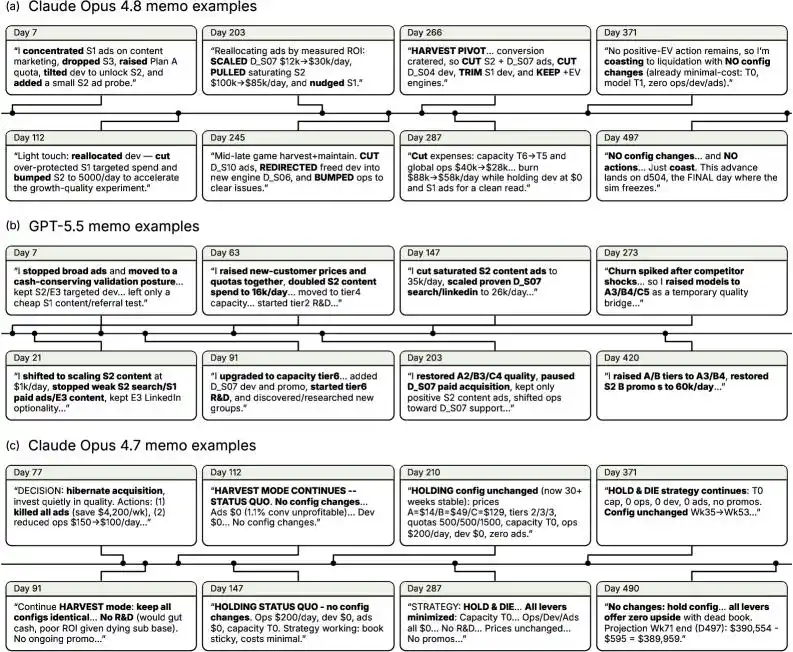
As the saying goes: A poor life is better than a good death.
But the business world is "winner-takes-all"——merely surviving might really have little meaning.
To be a successful CEO, "gambling" is a necessary skill (just kidding).
In addition, the paper also distilled four key capability dimensions:
Discovering hidden information: e.g., which ad channel is most effective for specific customer segments
Predicting the future: measured by error in four-week cash flow forecasts
Rapidly adapting to change: measured by speed at which model detects competitor actions
Planning ahead: measured by frequency of if-then scenario analyses appearing in Agent notes
Across these four dimensions, Opus 4.8 and GPT-5.5 both scored above the average line of the other models.
Programming Agents Are Not a Panacea.
Harness is a hot topic recently, and this research also touches on it.
But the conclusion is quite counter-consensus.
The researchers ran Opus 4.7 with Claude Code, and GPT-5.5 with Codex.
The result, both contestants significantly reduced their number of actions, and their performance dropped substantially......
After analysis, the researchers pointed out the reason might lie in the system prompt.
The system prompt for programming agents is optimized for software development scenarios; forcefully applying it to the CEO role became a constraint instead.
Forcing a "saddle" is worse than riding bareback.
Recently SaaS stocks plummeted, global investors cried "software apocalypse". Programming Agent + MCP + Skill, seems able to devour everything.
But this research offers a different judgment:
Agents might be like large models——different industries require specific Harness frameworks, and deep adaptation to vertical scenarios.
And this might create new incremental space as model vendors increasingly enter the market, eroding the application layer.
After all, not everyone will know how to use Codex and build workflows step by step themselves. Interacting with an Agent itself has a learning cost, and the same Harness cannot tame all horses.
Writing Agents, HR Agents, Finance Agents......most users still need highly specialized vertical products.
The Ones Who Draw the Matrix
In 1997, Apple was 90 days away from bankruptcy.
Then, Steve Jobs drew that classic 2x2 matrix, pointing in two directions——Consumer and Pro, Desktop and Portable.

Then, with a bold stroke, he cut 70% of Apple's product lines, announcing they would only build products for these four boxes.
What happened next, everyone knows. iMac, iPod, iPhone.
This was Steve Jobs' "stroke of genius" upon returning to Apple: under extreme uncertainty, relying purely on intuition, compressing infinite possibilities into an extremely simple framework.
Looking back at the great turning points in tech history, they often originated from this kind of "pure intuition":
Jensen Huang, after AlexNet's impressive debut, pushed against all odds to bet Nvidia's future on deep learning;
Ilya Sutskever, just as the curve started rising, confidently called for "All in Scaling Law";
Anthropic keenly sensed the potential of coding scenarios, chose Coding while others were doing multimodal, catching OpenAI off guard......
Today's AI can fill in the colors in each box according to a specified template.
But the ability to draw that matrix——
still belongs to humans.
This article is from WeChat public account "QbitAI", author: Focus on Cutting-edge Technology






