
想象一下这个场景:
你让 AI Agent 帮你修一个代码 Bug。它打开项目,读了 20 个文件,改了改,跑了一下测试,没过,又改,又跑,还是没过......来回折腾了十几轮,终于——还是没修好。
你关掉电脑,松了口气。然后收到了 API 账单。
上面的数字可能让你倒吸一口凉气——AI Agent 自主修 Bug 在海外官方 API 下,单次未修复任务常烧掉百万以上 Token,费用可达几十至一百多美元。
2026 年 4 月,一篇由斯坦福、MIT、密歇根大学等联合发布的研究论文,第一次系统性地打开了 AI Agent 在代码任务中的“消费黑箱”——钱到底花在哪了、花得值不值、能不能提前预估,答案令人震惊。
发现一:Agent 写代码的烧钱速度,是普通 AI 对话的 1000 倍
大家可能觉得,让 AI 帮你写代码和让 AI 跟你聊代码,花的钱应该差不多吧?
论文给出对比显示:
Agentic 编码任务的 Token 消耗量,是普通代码问答和代码推理任务的 约 1000 倍。
差了整整三个数量级。
为什么会这样?论文指出了一个事实——钱不是花在“写代码”上,而是花在“读代码”上。
这里的“读”不是指人类读代码,而是 Agent 在工作过程中,需要不断地把整个项目的上下文、历史操作记录、报错信息、文件内容一股脑儿“喂”给模型。每多一轮对话,这个上下文就变得更长一轮;而模型是按 Token 数量计费的——你喂得越多,付得越多。
打个比方:这就像请了一个修理工,他每动一下扳手之前,都要你把整栋楼的图纸从头念一遍给他听——念图纸的钱,远比拧螺丝的钱贵得多。
论文把这个现象总结为一句话:驱动 Agent 成本的,是输入 Token 的指数级增长,而非输出 Token。
发现二:同一个 Bug,跑两次,花费能差一倍——而且越贵的 Bug 越不稳定
更让人头疼的是随机性。
研究者让同一个 Agent 在同一个任务上跑了 4 次,结果发现:
- 在不同任务之间,最贵的任务比最便宜的任务多烧约 700 万个 Token(Figure 2a)
- 在同一模型、同一任务的多次运行中,最贵的一次大约是最便宜的一次的 2 倍(Figure 2b)
- 而如果跨模型对比同一个任务,最高消耗和最低消耗之间可以相差高达 30 倍
最后一个数字尤其值得关注:这意味着,选对模型和选错模型之间的成本差距,不是“贵一点”,而是“贵出一个数量级”。
更扎心的是——花得多,不代表做得好。
论文发现了一个“倒 U 型”曲线:
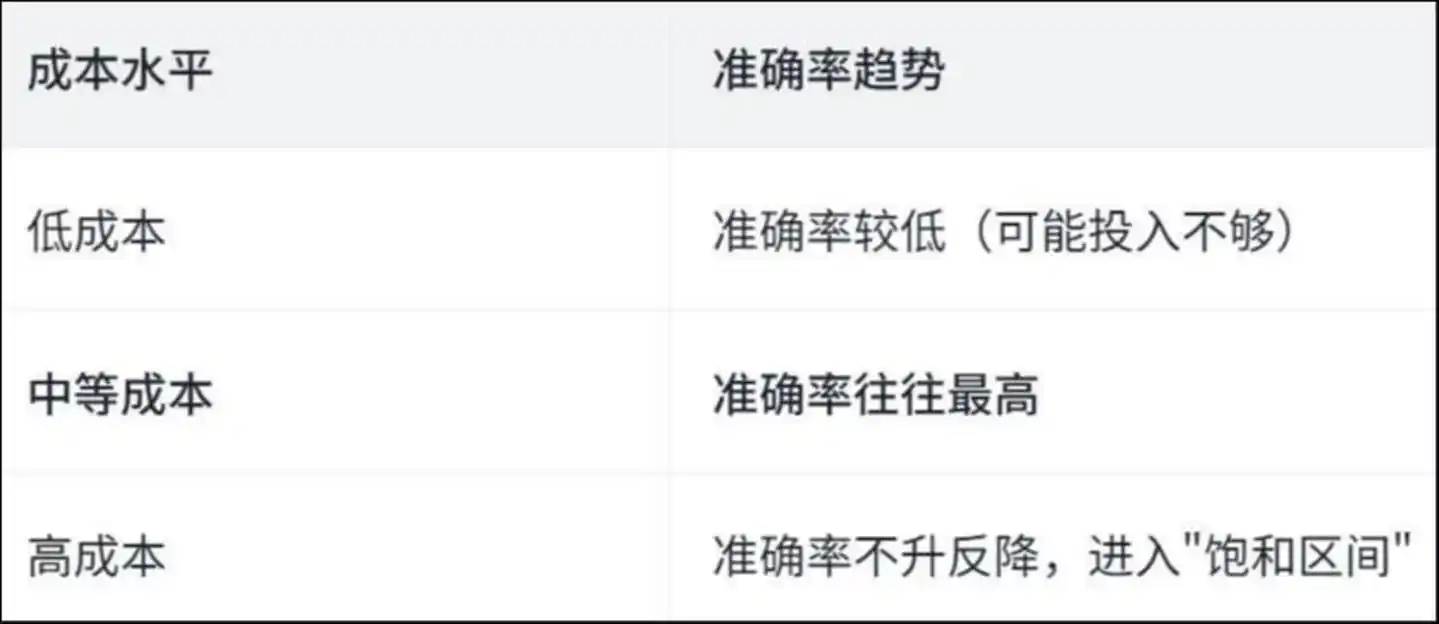
成本水平准确率趋势低成本准确率较低(可能投入不够)中等成本准确率往往最高高成本准确率不升反降,进入"饱和区间"
为什么会这样?论文通过分析 Agent 的具体操作给出了答案——
高成本的运行中,Agent 大量时间花在了“重复劳动”上。
研究发现,在高成本运行中,约 50% 的文件查看和文件修改操作是重复的——也就是说,Agent 在反复读同一个文件、反复改同一行代码,像一个人在房间里转圈,越转越晕,越晕越转。
钱没花在解决问题上,花在了“迷路”上。
发现三:模型之间“能效比”天差地别——GPT-5 最省,有的模型多烧 150 万 Token
论文在业界标准的 SWE-bench Verified(500 个真实 GitHub Issue)上,测试了 8 个前沿大模型的 Agent 表现。换算成美元,Token效率高的模型每个任务可以多花几十块的区别。放到企业级应用——一天跑几百个任务——差距就是真金白银。
更有意思的一个发现是:Token 效率是模型的“固有性格”,而非任务使然。
研究者把所有模型都成功解决的任务(230 个)和所有模型都失败的任务(100 个)分别拿出来比较,发现模型的相对排名几乎没有变化。
这说明:有些模型天生就“话多”,跟任务难度关系不大。
还有一个令人深思的发现:模型缺乏“止损意识”。
在面对所有模型都无法解决的困难任务时,理想的 Agent 应该尽早放弃,而不是继续烧钱。但现实是,模型普遍在失败任务上消耗了更多的 Token——它们不会“认输”,只会继续探索、重试、重读上下文,像一台没有油表警示灯的汽车,一路开到抛锚。
发现四:人类觉得难的,Agent 不一定觉得贵——难度感知完全错位
你可能会想:那至少我可以根据任务的难易程度来预估成本吧?
论文找来人类专家,对 500 个任务的难度进行评分,然后和 Agent 的实际 Token 消耗做对比——
结果:两者之间只有弱相关。
用大白话说:人类觉得难得要死的任务,Agent 可能轻松搞定不怎么花钱;人类觉得小菜一碟的任务,Agent 可能烧到怀疑人生。
这是因为人和 AI “看到”的难度根本不是一回事:
- 人类看的是:逻辑复杂度、算法难度、业务理解门槛
- Agent 看的是:项目有多大、要读多少文件、探索路径有多长、会不会反复修改同一个文件
一个人类专家觉得“改一行就行”的 Bug,Agent 可能要先读懂整个代码库的结构才能定位到那一行——光是“读”就要烧掉大量 Token。而一个人类觉得“逻辑很绕”的算法问题,Agent 可能恰好知道标准解法,三下五除二就搞定了。
这就导致了一个尴尬的现实:开发者几乎不可能凭直觉预估 Agent 的运行成本。
发现五:连模型自己都算不准自己要花多少钱
既然人算不准,那让 AI 自己来预测呢?
研究者设计了一个精巧的实验:让 Agent 在真正开始修 Bug 之前,先“ inspect”一下代码库,然后预估自己需要消耗多少 Token——但不实际执行修复。
结果如何?
所有模型,全军覆没。
最好的成绩是 Claude Sonnet-4.5 对输出 Token 的预测相关性——0.39(满分 1.0)。多数模型的预测相关性只有 0.05 到 0.34 之间,Gemini-3-Pro 最低,仅为 0.04——基本等于瞎猜。
更离谱的是:所有模型都系统性低估了自己的 Token 消耗。 Figure 11 的散点图中,几乎所有数据点都落在“完美预测线”的下方——模型觉得自己“花不了那么多”,实际上花了更多。而且这个低估偏差在不提供示例的情况下更加严重。
更讽刺的是——预测本身也要花钱。
Claude Sonnet-3.7 和 Sonnet-4 的预测成本甚至高达任务本身成本的 2 倍以上。也就是说,让它们先“估个价”,比直接干活还贵。
论文的结论直截了当:
现阶段,前沿模型无法准确预测自身的 Token 用量。点下“运行 Agent”,就像开盲盒——账单出来才知道花了多少。
这笔“糊涂账”背后,藏着一个更大的行业问题
读到这,你可能会问:这些发现对企业意味着什么?
1. “按月订阅”的定价模式,正在被 Agent 撕开裂缝
论文指出,像 ChatGPT Plus 这样的订阅制之所以可行,是因为普通对话的 Token 消耗相对可控、可预测。但 Agent 任务完全打破了这一假设——一个的任务可能因为 Agent 陷入循环而烧掉巨量 Token。
这意味着,纯粹的订阅制定价对 Agent 场景可能不可持续,按量计费(Pay-as-you-go)在相当长时间内仍是最现实的选项。但按量计费的问题在于——用量本身就不可预测。
2. Token 效率应该成为选模型的“第三指标”
传统上,企业选模型看两个维度:能力(能不能干)和速度(干得快不快)。这篇论文给出了第三个同等重要的维度:能效(花多少才能干成)。
一个能力略逊但效率高 3 倍的模型,在规模化场景下可能比“最强但最费”的模型更有经济价值。
3. Agent 需要“油表”和“刹车”
论文提到一个值得关注的未来方向——Budget-aware tool-use policies(预算感知的工具使用策略)。简单说就是给 Agent 装一个"油表":当 Token 消耗接近预算时,强制它停止无效探索,而不是一路烧到底。
目前,几乎所有主流 Agent 框架都缺乏这种机制。
Agent 的“烧钱问题”,不是 Bug,而是行业必经的阵痛
这篇论文揭示的并非某个模型的缺陷,而是整个 Agent 范式的结构性挑战——当 AI 从“一问一答”进化到“自主规划、多步执行、反复调试”,Token 消耗的不可预测性几乎是一种必然。
好消息是,这是第一次有人系统性地把这笔糊涂账翻出来算。有了这份数据,开发者可以更明智地选择模型、设置预算、设计止损机制;模型厂商也有了一个新的优化方向——不只是做得更强,还要做得更省。
毕竟,在 AI Agent 真正走入千行百业的生产环境之前,每一分钱花得明明白白,比每一行代码写得漂漂亮亮,更重要。(本文首发钛媒体APP,作者 | 硅谷Tech news,编辑 | 赵虹宇)
注:本文基于 2026 年 4 月 24 日发表于 arXiv 的预印本论文 *How Do AI Agents Spend Your Money? Analyzing and Predicting Token Consumption in Agentic Coding Tasks*(Bai, Huang, Wang, Sun, Mihalcea, Brynjolfsson, Pentland, Pei)撰写。作者来自弗吉尼亚大学、斯坦福大学、MIT、密歇根大学等机构。该研究尚未经同行评审。






