Editor|Panda
Several days ago, Google lost two key figures in quick succession.
On June 18th, Noam Shazeer, one of the co-authors of the Transformer paper, announced on X that he was leaving to join OpenAI. Two days later, 2024 Nobel Chemistry laureate and AlphaFold team lead John Jumper also announced his departure from Google DeepMind, heading to Anthropic.
The two successive announcements made a big impact in the capital markets: Alphabet's stock price plummeted over 7% at one point, wiping out more than $300 billion in market value. Several analyst firms attributed this sell-off to a "brain drain." D.A. Davidson analyst Gil Luria stated bluntly that Shazeer going to OpenAI and Jumper to Anthropic, leaving one after the other, made the market worry that Google was falling behind in the AI talent war.

Shazeer's departure is particularly noteworthy—it's the second time he has left Google.
In 2021, dissatisfied with the company's reluctance to publicly release a chatbot he was leading, he left to co-found Character.AI; in August 2024, Google spent about $2.7 billion to license Character.AI's technology, bringing him back to DeepMind as VP of Engineering for the Gemini project, co-leading it alongside Jeff Dean. Less than two years later, he left again, this time for rival OpenAI.
Thus, all eight co-authors of the paper "Attention Is All You Need," published nine years ago, have now left Google.
X user Tyler Maran made a chart plotting their current whereabouts, which has been widely shared on social media.

However, this chart may soon be outdated. Just in the past two days, market rumors have surfaced that Nvidia is quietly recruiting the core team of Essential AI, which includes Transformer paper co-author and Essential AI co-founder/CEO Ashish Vaswani. As of publication, neither Nvidia nor Essential AI has officially responded to this news.
Let's take this opportunity to fully review the nine-year trajectories of these eight individuals known as the "fathers of Transformer" and where they truly are today.
It should be noted that the author order in "Attention Is All You Need" is randomized. A footnote in the paper clearly states: All authors contributed equally, and the order is random. Therefore, there is no "first author" or "corresponding author." This article will introduce the eight individuals in the order listed in the original paper.
"The Origin of Everything": Eight Googlers Who Broke the Mold
To understand their choices today, one must go back to 2017. At that time, the dominant approach in machine translation was Recurrent Neural Networks (RNNs). Models had to process sentences word by word sequentially, like cars queuing on a single-lane road, unable to compute in parallel, making training slow and expensive.
Eight members of Google Brain decided to try a nearly radical idea: throw out the recurrent structure entirely, keep only the "attention mechanism," allowing the model to see the entire sentence at once and decide for itself which words to focus on. The title phrase "Attention Is All You Need" plays on the Beatles' song "All You Need Is Love" and has since inspired many imitative paper titles.

The paper's author contributions briefly recorded what each person did:

Jakob Uszkoreit first proposed replacing recurrence with self-attention and led the early validation of this idea;
Ashish Vaswani designed and implemented the initial Transformer model alongside Illia Polosukhin, participating in nearly every aspect of the project;
Noam Shazeer proposed scaled dot-product attention, multi-head attention, and parameter-free positional representations, another person involved in nearly every detail;
Niki Parmar designed, implemented, and debugged countless model variants in the initial codebase and later in the tensor2tensor framework;
Llion Jones also tried many new model variants and was responsible for the initial codebase, inference efficiency optimization, and visualization;
Łukasz Kaiser and Aidan N. Gomez spent countless days and nights building components of the tensor2tensor framework, replacing the early codebase and greatly improving experimental results and research efficiency.
This note also indirectly reveals a detail: despite the random order, Uszkoreit, Vaswani, Polosukhin, and Shazeer clearly took on more core architectural roles, while Parmar, Jones, Kaiser, and Gomez shouldered the brunt of engineering and system building—an early footnote hinting at the differences in personality and expertise that would later guide their distinct paths.
The name "Transformer" itself has an anecdote. Uszkoreit liked how the word sounded, so the team internally called themselves "Team Transformer," with early design document covers even featuring six characters from the Transformers cartoon.
Since publication, the paper has been cited over 260,000 times, making it one of the most-cited papers of the 21st century.

Ashish Vaswani

Vaswani was born in 1986 in India. He earned a Bachelor's in Computer Science from Birla Institute of Technology, Mesra (BIT Mesra) in 2002, then went to the US for a PhD at the University of Southern California under David Chiang, focusing on statistical machine translation and neural network language modeling. After his doctorate, he worked as a computer scientist at USC's Information Sciences Institute for two years before joining Google Brain as a Research Scientist in 2016, staying until 2021.
According to the paper's contribution note, Vaswani designed and implemented the initial Transformer model with Illia Polosukhin and was one of the core figures involved in "nearly every aspect of the project."
After leaving Google, Vaswani co-founded Adept AI in 2021 with Niki Parmar, former OpenAI VP of Engineering David Luan, and others, serving as Chief Scientist. The goal was to build "action models" capable of autonomously operating any software.
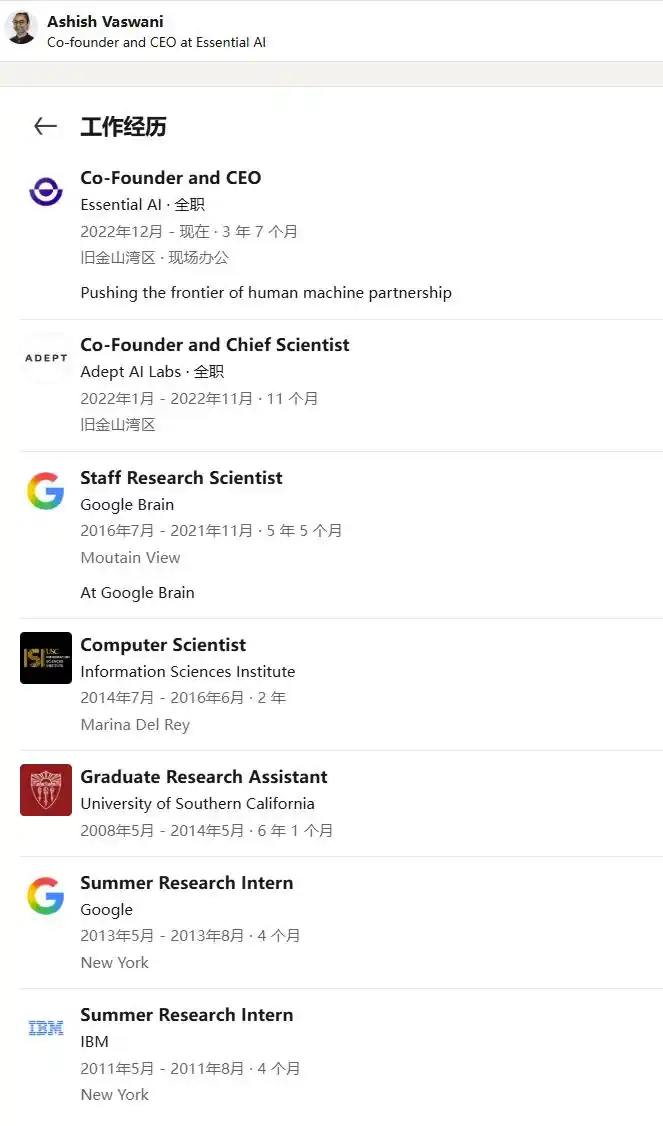
Adept once raised over $400 million, reaching a valuation of around $1 billion, but product delivery lagged, and internal disagreements arose. Vaswani and Parmar chose to exit early—his tenure as Chief Scientist at Adept ended in November 2022.
In early 2023, Vaswani teamed up with Parmar again to co-found Essential AI, with Vaswani as CEO. The company secured strategic investments from Google, Nvidia, and AMD: an $8.3 million seed round led by Thrive Capital, a $56.5 million Series A in late 2023 led by March Capital with participation from Google, Nvidia, AMD, KB Investment, Franklin Templeton, etc. In early 2026, the company completed a $175 million Series B led by Lightspeed Venture Partners with Thrive Capital following, reaching a valuation exceeding $1 billion and officially becoming a unicorn.
In late 2025, the company released its first open-source model series, Rnj-1 (named after Indian mathematician Ramanujan).
But the wind changed in the past two days. Reports emerged that Nvidia is recruiting the core team of Essential AI, including Vaswani, who is expected to work on Nvidia's open-source model Nemotron.
Insiders revealed a practical reason: Essential AI is facing fundraising challenges, and pulling Vaswani and his team away from AMD's camp (AMD has been an early strategic investor in Essential AI, which long relied on AMD's GPUs) is a smart business move. Several Essential AI researchers (including Alok Tripathy, Saurabh Srivastava) have updated their LinkedIn profiles to show they've joined Nvidia. However, neither Nvidia nor Essential AI has officially confirmed this as of now.
Noam Shazeer

Shazeer was born in Philadelphia in 1976 into an Orthodox Jewish family; his father Dov Shazeer was a math teacher turned engineer, and his sister was ordained as a rabbi by Hebrew College. He showed exceptional talent early, winning a perfect gold medal as part of the US team at the 1994 International Mathematical Olympiad. He studied Mathematics and Computer Science at Duke University as an Angier B. Duke Memorial Scholar and won awards in the Putnam Competition.
In 2000, Shazeer joined Google, making his name early by fixing Google Search's spelling correction feature.
According to the Transformer paper's contribution note, he proposed scaled dot-product attention, multi-head attention, and parameter-free positional representations, another person involved in "nearly every detail" alongside Vaswani and Polosukhin.
After co-authoring the Transformer paper in 2017, he and colleague Daniel De Freitas created the chatbot Meena, but Google cautiously decided not to release it publicly. The two left in 2021 to found Character.AI, raising over $150 million from a16z and others, building a popular role-play chat app.

In August 2024, the plot twisted: Google struck a licensing deal with Character.AI reportedly worth around $2.7 billion. Shazeer and De Freitas, along with a small group of colleagues, returned to Google DeepMind. Shazeer was appointed VP of Engineering, co-leading the Gemini project with Jeff Dean and Oriol Vinyals. As he owned an estimated 30-40% of Character.AI, the deal reportedly netted him between $750 million and $1 billion personally. In 2026, he was elected to the National Academy of Engineering, his career seemingly at its peak.
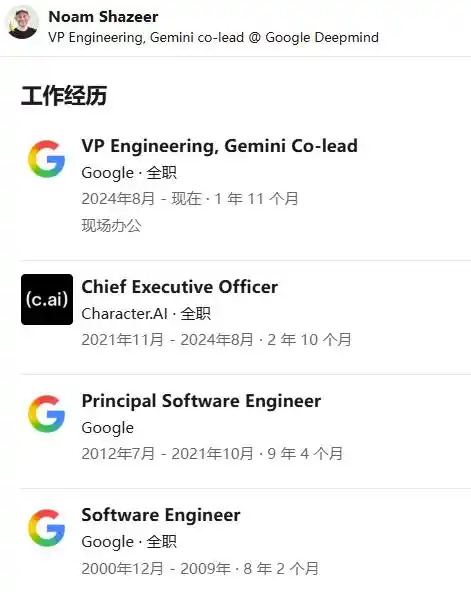
Yet just months later, he left once more, this time for OpenAI, reportedly to lead an "architecture research" direction, coinciding with OpenAI's hiring push for its anticipated IPO (the company secretly filed its S-1 with the SEC on June 8th, with a rumored valuation of $852 billion).
OpenAI CEO Sam Altman made a rare public statement: "He has been one of the people I've most wanted to work with since day one of OpenAI," adding that this hire had been "brewing for a full decade."
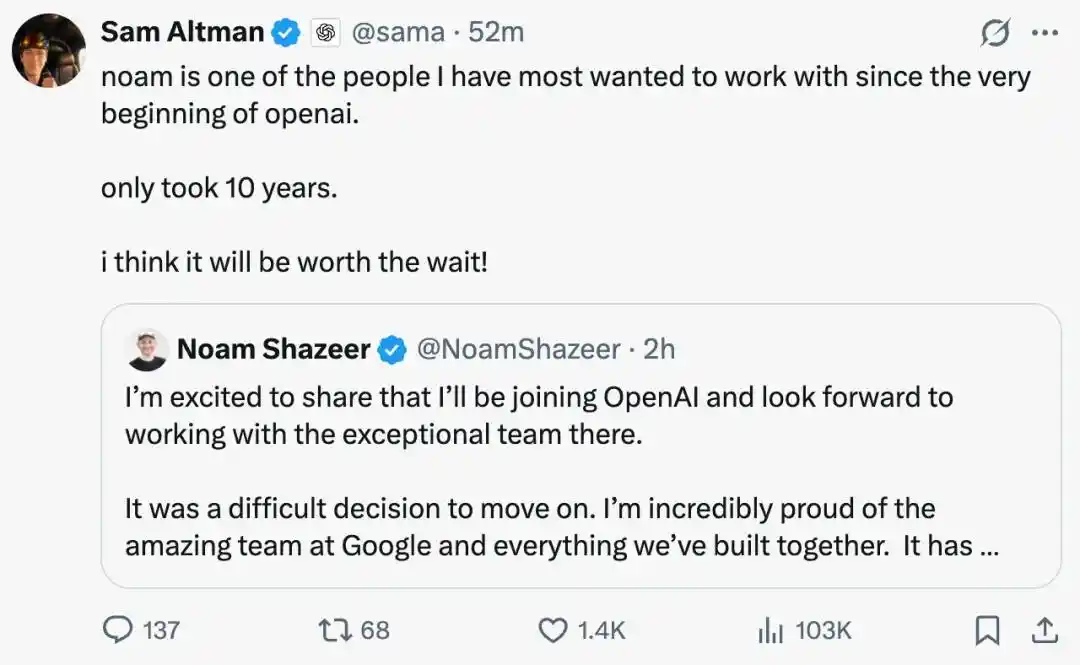
For Google, this was a costly "failed repurchase": the person they spent $2.7 billion to bring back two years ago has now joined their top competitor, becoming a direct trigger for Google's stock plunge this week.
Niki Parmar

Parmar was born in Pune, India. She earned her Bachelor's in Information Technology from Pune Institute of Computer Technology. During her studies, she developed an interest in AI and machine learning through online courses by Andrew Ng and Peter Norvig. She then pursued a Master's in Computer Science at the University of Southern California, working with Professor Morteza Dehghani on applying machine learning to social science problems.
In 2015, Parmar joined Google Research as a Software Engineer, moving to Google Brain as a Research Software Engineer in 2017—reportedly the youngest and only researcher on the team without a PhD at the time.
According to the paper's contribution note, she designed, implemented, and debugged countless model variants in the initial codebase and later the tensor2tensor framework. After the paper's publication, she continued extending Transformer beyond language, participating in research applying self-attention to image generation and computer vision.
In 2021, Parmar left Google to co-found Adept AI with Ashish Vaswani, David Luan, and others, serving as CTO. Like Vaswani, she exited Adept early. In early 2023, she and Vaswani co-founded Essential AI.
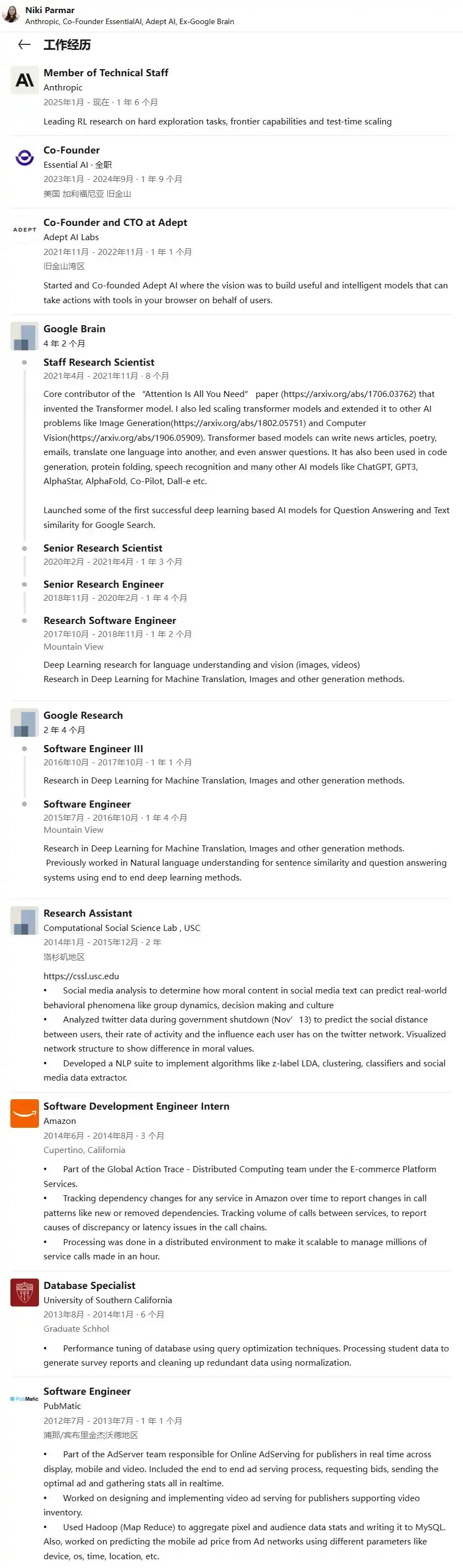
But she didn't stay for Essential AI's subsequent Series B and unicorn status. In late 2024, Parmar quietly left Essential AI and joined Anthropic, announcing it publicly in February 2025. She wrote on X: "Today is as good a day as any to share: I joined Anthropic in December last year."
She later contributed to the development of Claude 3.7 Sonnet—one of Anthropic's most significant model releases. She is now a Member of Technical Staff at Anthropic, focusing on frontier capabilities research and reinforcement learning.
Two co-authors who were once inseparable, who co-founded two companies together, ultimately took completely different paths: Parmar withdrew quietly over a year earlier, blending into a top lab, while Vaswani chose to push Essential AI forward until being recruited by a rival this week.
Jakob Uszkoreit

Uszkoreit comes from a linguistics family. His father, Hans Uszkoreit, is a renowned computational linguist. When his son proposed the hypothesis that "attention alone is enough," even his father was skeptical. Uszkoreit earned his PhD from the Technical University of Berlin and later became a Distinguished Scientist at Google Brain.
According to the paper's contribution note, it was Uszkoreit who first proposed replacing RNNs with self-attention and led the early validation of this idea—the seed of this hypothesis was planted in his 2016 paper with Ankur Parikh, Oscar Täckström, and Dipanjan Das on "decomposable attention models."

The name "Transformer" was chosen because he liked how it sounded; the team internally called themselves "Team Transformer," and early design document covers featured six characters from the Transformers cartoon.
In late 2020, DeepMind's AlphaFold2 demonstrated that Transformer-like models could solve a "holy grail" problem like protein folding. He also increasingly realized that the reason deep learning hadn't truly transformed biology wasn't a lack of algorithms, but data. "It almost became a moral imperative," he later recalled.
So in 2021, he co-founded Inceptive with Stanford biochemistry professor and creator of the RNA design game Eterna, Rhiju Das. The company is headquartered in Berkeley, with the research team in Berlin—he lives in Berlin himself, with employees also in Zurich, London, Vancouver, and multiple cities on the US East Coast. The core idea is to reverse the experimental process: instead of training models on existing data, use robotics and human labor to generate massive amounts of novel RNA experimental data to feed the models.
Inceptive has raised about $120 million from Nvidia, a16z, Obvious Ventures, Section 32, and others. The latest development came this month: in early June, RNA interference therapy pioneer Alnylam Pharmaceuticals signed a strategic collaboration with Inceptive to accelerate siRNA candidate drug design using Inceptive's foundational models, with an upfront payment of $30 million and a potential total deal value reportedly around $2 billion. Uszkoreit stated: "Most drug design still relies on trial and error—testing thousands of molecules, hoping one works. Inceptive starts from a different place: life follows incredibly complex rules, and only AI can learn them."
Among the eight authors, he is the only one who has completely switched to biotech, precisely fulfilling the paper's early prophecy: the potential of attention extends far beyond machine translation.
Llion Jones

Jones is Welsh, a graduate of the University of Birmingham. He joined Google as a Software Engineer in 2011, working there for over a decade, one of the few authors without a PhD who navigated his way through engineering intuition.
According to the paper's contribution note, he tried many new model variants and was responsible for the initial codebase, inference efficiency optimization, and visualization.
He later recalled the decisive moment: "We had just started trying to cut out certain parts of the model, just to see how much worse it would get. Surprisingly, it actually got better." This was the first validation of the hypothesis that "recurrence is actually unnecessary."
In 2023, Jones co-founded Sakana AI in Tokyo with fellow Google alumnus David Ha. "Sakana" means "fish" in Japanese. Ha serves as CEO, Jones as CTO, with another co-founder, Ren Ito, as COO.
Jones is now based in Tokyo, describing himself on social media as a "Welsh AI researcher living in Tokyo." The company's research direction is distinctly counter-trend: instead of merely scaling compute and parameters, borrow logic from natural evolution, having smaller models collaborate like a school of fish. The company's representative research includes the Continuous Thought Machine and the "AI Scientist" project capable of end-to-end autonomous research. Recently, the company released the cutting-edge Sakana Fugu model.
Sakana AI has raised a total of $379 million, including a Series B in March 2026, with Mitsubishi Electric among its investors. In March 2026, the company also secured a multi-year partnership with Mitsubishi UFJ Financial Group (MUFG). The latter plans to use Sakana's technology to overhaul its banking systems, reportedly putting this company valued at around $1.5 billion on a path to profitability within a year.
Jones himself has expressed skepticism about pure "scaling" on multiple occasions. In March 2026, he said at an internal banking event that current AI research faces an awkward reality: massive investment and talent influx should theoretically spur more breakthroughs, but the actual effect might be the opposite: investors pressure for results, competition drives rushed releases, squeezing out the space for researchers to "freely explore." He mentioned that Sakana internally maintains a small portion of "no-KPI" research freedom because the next breakthrough will inevitably come from such long-term, consequence-free investment—exactly how the original Transformer was born in that Google Brain office.
He has also said a frequently quoted line: for a new architecture to truly replace Transformer, being "better" isn't enough; it must be "obviously, unquestionably better."
Aidan N. Gomez

Gomez is the youngest of the eight. The year the paper was published, he was just a 20-year-old undergraduate intern at Google Brain, studying a double major in Computer Science and Mathematics at the University of Toronto.
According to the paper's contribution note, he and Łukasz Kaiser spent countless days and nights building components of the tensor2tensor framework, replacing the early codebase and greatly improving experimental results and research efficiency. "I was just trying to understand how attention actually worked," he later recalled, "never imagining it would become the 'architecture of everything.'" After the paper, he pursued a PhD at Oxford University, pausing his studies to start a company and finally receiving his doctorate in 2024—essentially completing his degree while building a business.
In 2019, Gomez co-founded Cohere with Ivan Zhang and Nick Frosst, positioning the company as an enterprise AI service provider, deliberately avoiding the capital-intensive consumer chatbot race. It focuses on data privacy, on-premise deployment, and multilingual capabilities, with clients primarily large enterprises and governments. In 2023, Gomez was named to TIME's list of the 100 most influential people in AI, and he and his co-founders topped Maclean's magazine's AI Trendsetters list that year; in April 2025, he joined the board of electric vehicle maker Rivian.
This relatively "unsexy" approach has yielded solid financials: as of mid-2026, Cohere's annualized recurring revenue exceeds $200 million, having grown 6x over the past year, with gross margins around 70%. Cumulative funding is close to $1.7 billion, valuation around $7 billion. In August 2025, the company hired Francois Chadwick, who helped take Uber public, as its first CFO. Employee secondary market share sales have already occurred, and Gomez has repeatedly said an IPO is "close," but the company has yet to file a prospectus with regulators.
Gomez has increasingly become an AI spokesperson in geopolitical terms. Just this week, he wrote in Fortune magazine, calling on nations to address "digital sovereignty." The article directly referenced recent tightening of Anthropic model access, warning countries against "renting" their futures to a few centralized tech giants, and proposing building a truly diverse ecosystem where nations can rely on different AI providers while preserving their own values, languages, and legal systems.
He has also publicly stated that existential "AI doomsday" fears are exaggerated; his greater concern is the real-world risk of disinformation being amplified automatically on social media. Gomez now discusses not just models, but who gets to decide what AI the world uses.
Łukasz Kaiser

Kaiser is Polish, originally trained in theoretical computer science: logic, automata theory, algorithmic model theory, and game theory. He earned dual Master's degrees in Mathematics and Computer Science from the University of Wrocław, completed his PhD at RWTH Aachen University in Germany, then held a permanent research position at the French National Centre for Scientific Research (CNRS) and Paris Diderot University, focusing on pure theory in logic and automata. He later shifted to applications, working at Google Brain for nearly eight years, also co-authoring TensorFlow, and publishing early papers with Samy Bengio on "Can Active Memory Replace Attention?" and with Ilya Sutskever on "Neural GPUs Learn Algorithms."
According to the paper's contribution note, he and Aidan N. Gomez spent countless days and nights building the tensor2tensor framework, greatly improving experimental results and research efficiency.
Among the eight authors, he is the only one who didn't start a company, remaining in large labs doing pure research.
He joined OpenAI in 2021, before ChatGPT's release. At OpenAI, he contributed to Codex (the foundation for GitHub Copilot) and the accompanying HumanEval programming benchmark, and also worked on the GSM8K math dataset. This work early on demonstrated that "letting the model think a bit longer, sample a few more times during reasoning" could significantly improve accuracy—the precursor to later reasoning model paradigms.
He is also a named author on the GPT-4 technical report and later became a core contributor to OpenAI's first reasoning model o1 (released September 2024), considered a "research lead" level role, continuing through o3 and newer reasoning paradigms up to today's GPT-5 series.
He recently said on Matt Turck's MAD Podcast that Transformer has been mathematically proven to solve any problem, provided the model is allowed to generate enough intermediate reasoning steps. In a way, this is a belated, more precise annotation on that paper from nine years ago.
Illia Polosukhin

Polosukhin is from Kharkiv, Ukraine, with a background in applied mathematics and a championship in the International Collegiate Programming Contest (ICPC). He recalls developing an almost obsessive interest in AI after watching "The Matrix" at age ten. He joined Google in 2014, working on TensorFlow-related research and also on machine reading comprehension and question-answering systems.
According to the paper's contribution note, he designed and implemented the initial Transformer model with Ashish Vaswani, his part mainly validating the architecture's effectiveness on machine translation tasks.
After the paper's publication, he left Google in 2017 to co-found an AI company initially called NEAR.AI with Alexander Skidanov. But they soon realized decentralized infrastructure might be more interesting than models, so the company pivoted around 2018 to become the blockchain project NEAR Protocol.
NEAR uses a sharding technology called Nightshade and offers an Ethereum-compatible layer-2 via Aurora. The mainnet launched in 2020, and the project has raised over $530 million from a16z, Coinbase, Tiger Global, Hashed, Dragonfly Capital, and others.
Polosukhin is now trying to merge his two initial identities: in March 2026, he told media that "blockchain's future users will be AI agents, not humans," positioning NEAR as the "settlement layer" for the agent economy. In April of the same year, he publicly called for a better regulatory framework to handle autonomous AI agents; he believes existing institutions aren't ready for the liability and systemic risks such systems pose, advocating for clearer accountability and "human-in-the-loop" oversight.
He is currently based in Portugal. In the world, perhaps only he holds both identities: "author of the foundational LLM paper" and "running a multi-billion dollar blockchain company."
Eight Paths, Still Exploring
In March 2024, at Nvidia's GTC conference, seven of the eight authors (Niki Parmar was absent) appeared together on stage for the first time as a group, interviewed by Jensen Huang.

Huang said: "Everything we enjoy today can be traced back to that moment."
At the end of the conversation, he presented each with a signed commemorative plaque from an Nvidia DGX-1 supercomputer, engraved with "You transformed the world." In November of the same year, Japan's NEC C&C Foundation awarded that year's C&C Prize to the "Transformer Team" of eight. Sharing the stage with them were three senior engineers researching transoceanic submarine cable transmission technology. Two completely different types of infrastructure builders were placed under the same award.
Nine years on, these eight life trajectories have diverged to places where they likely won't intersect again: the enterprise service track in Silicon Valley, an evolutionary algorithm lab in Tokyo, a molecular biology company in Berlin, a blockchain protocol in Portugal, and the top AI labs still reshuffling this week.
But if you listen to what they've said over the years, a common judgment repeatedly emerges: no one truly believes Transformer is the end.
Aidan N. Gomez says the world needs something better than Transformer; Llion Jones says the next architecture must be "obviously, unquestionably better" to replace it; Łukasz Kaiser is still using mathematical language to try and clarify just how far this nine-year-old architecture can take humanity.
Perhaps this is the most enduring legacy of that paper: its eight authors are scattered across the globe, yet not one has stopped searching for the next answer.
References
https://www.wired.com/story/eight-google-employees-invented-modern-ai-transformers-paper/
https://x.com/TylerMaran/status/2067772926695522454
https://www.nvidia.com/zh-tw/on-demand/session/gtc24-s63046/
This article comes from the WeChat public account "Machine Heart" (ID: almosthuman2014), author: Concerned with AI





